Welcome to duiniwukenaihe's Blog!
这里记录着我的运维学习之路-
2019-11-25-k8s-question2
描述背景:
注:记录各种常见问题
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 创建 Pod 失败,describe pod 看 event 报 no space left on device.集群运行120天左右出现。
可参照https://www.bookstack.cn/read/kubernetes-practice-guide/troubleshooting-problems-errors-no-space-left-on-device.md。出现此问题cgroup泄露问题。最笨方法可以用reboot下,或者删除节点重新添加下。瞄了一眼/var/lib/docker/overlay2 下文件有快70G,/var/log/journal/日志也有4-5G。
journalctl --vacuum-size=20M 设置journal 日志最大为20M不保留不必要日志。prune命令的使用:
看了下文档与资料,对于不再使用的镜像容器,存储以及网络资源 docker采取的是被动清理方式。所以自然而然的,默认文件夹下文件会越来越大。docker 也为此提供了prune的命令。
1. Prune Images
docker image prune 可以用来清理不再使用的docker镜像。执行docker image prune默认会清除”悬空”镜像。“悬空”镜像,就是既没有标签名也没有容器引用的镜像就叫”悬空”镜像。具体操作如下:
$ docker image prune WARNING! This will remove all dangling images. Are you sure you want to continue? [y/N] y 想要清除所有没有容器引用的镜像,增加一个 -a 标志就可以搞定: $ docker image prune -a WARNING! This will remove all images without at least one container associated to them. Are you sure you want to continue? [y/N] y 清除操作会提醒你是否真心想要清除对象,默认是选项会是yes;但是如果你嫌提示麻烦,可以通过-f 或者--force标志来进行强制清除。 更加人性化的是,Docker提供了--filter标志筛选出想要保留的镜像。例如:只清除超过创建时间超过24小时的镜像可以这样来操作: $ docker image prune -a --filter "until=24h" 当然还能够通过其他的表达式来定制我的镜像清理计划。更多的示例参考docker image prune.2. Prune containers
容器启动时没有指定–rm选项,容器停止时是不能够自动清除的。有时候我们无所事事的敲下docker ps -a命令会惊奇的发现,天哪,居然有这么多容器,有运行着的也有停止了的。它们是哪里来的?它们到底还有没有人在关注?这种情况在一个开发环境上尤其常见。即使容器已经停掉了也会占用空间资源。这个时候可以使用docker container prune命令:
$ docker container prune WARNING! This will remove all stopped containers. Are you sure you want to continue? [y/N] 和镜像清理的情况一样,也会有提示信息告诉你是否继续,默认是yes;如果提示信息烦到了你的话就加上 -f 或者 --force标志强制清除就可以了。 默认情况下docker container prune命令会清理掉所有处于stopped状态的容器;如果不想那么残忍统统都删掉,也可以使用--filter标志来筛选出不希望被清理掉的容器。下面是一个筛选的例子,清除掉所有停掉的容器,但24内创建的除外: $ docker container prune --filter "until=24h" 其他的筛选条件的实现可以参考:docker container prune reference, 这里有更多的详细的例子。3. prune volumes
Volumes可被一个或多个容器使用会消耗host端的空间,但它不会自动清理,因为那样就有可能破坏掉有用的数据。
$ docker volume prune WARNING! This will remove all volumes not used by at least one container. Are you sure you want to continue? [y/N] y 和conatiner一样,手动清理Volume时会有提示信息,增加-f 或--force标志可以跳过提示信息直接清理。使用过滤参数--filter来筛选出不希望清理的无用Volume,否则默认会将所有没有使用的volumes都清理掉。下面的例子演示了除lable=keep外的volume外都清理掉(没有引用的volume): $ docker volume prune --filter "label!=keep" 其他的筛选条件的实现可以参考:docker volume prune reference,这里给出了更多参考示例。4. prune networks
虽然Docker networks占用的空间不多,但是它会创建iptable 规则、虚拟网桥设备以及路由表项,有洁癖的你看到这么多”僵尸”对象会不会抓狂?当然,我们还是要用清理神器:docker network prune 来清理没有再被任何容器引用的networks:
$ docker network prune WARNING! This will remove all networks not used by at least one container. Are you sure you want to continue? [y/N] y 可以通过 -f 或者 --force标志跳过提示信息来强制执行该命令。默认情况会清除所有没有再被引用的networks,如果想要过滤一些特定的networks,可以使用--filter来实现。下面这个例子就是通过--filter来清理没有被引用的、创建超过24小时的networks: $ docker network prune --filter "until=24h" 更多关于docker network的--filter的筛选条件可参考示例:docker network prune reference 。5. prune everything
如题,这里要讲的就是清理everything:images ,containers,networks一次性清理操作可以通过docker system prune来搞定。在Docker 17.06.0 以及更早的版本中,这个docker system prune也会将volume一起清理掉;在Docker 17.06.1以及后期的版本中则必须要手动指定–volumes标志才能够清理掉volumes:
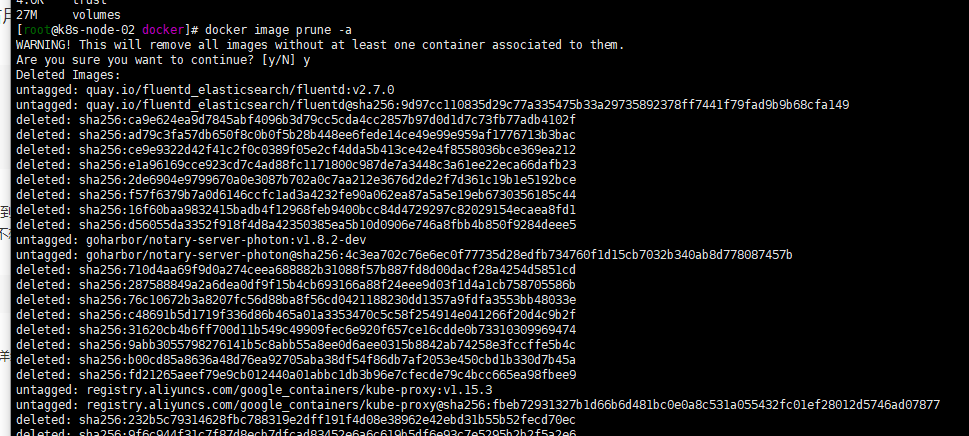
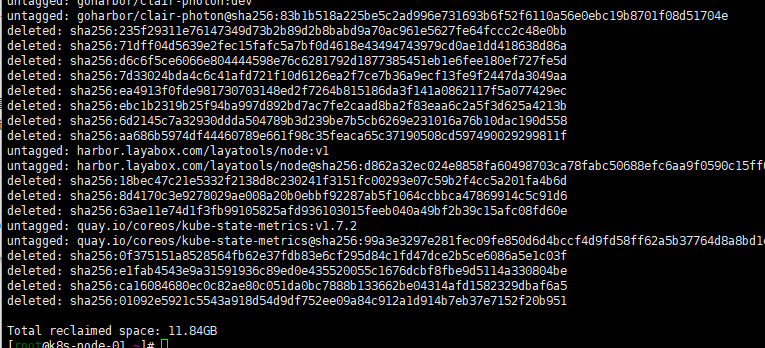
$ docker system prune WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all dangling images - all build cache Are you sure you want to continue? [y/N] y 在Docker 17.06.1或更高版本中添加--volumes标志的情况: $ docker system prune --volumes WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all volumes not used by at least one container - all dangling images - all build cache Are you sure you want to continue? [y/N] y 貌似删除很有限,我的只删除了几百m docker system prune -a WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all volumes not used by at least one container - all dangling images - all build cache Are you sure you want to continue? [y/N] y 这样管用些删除了 12G空间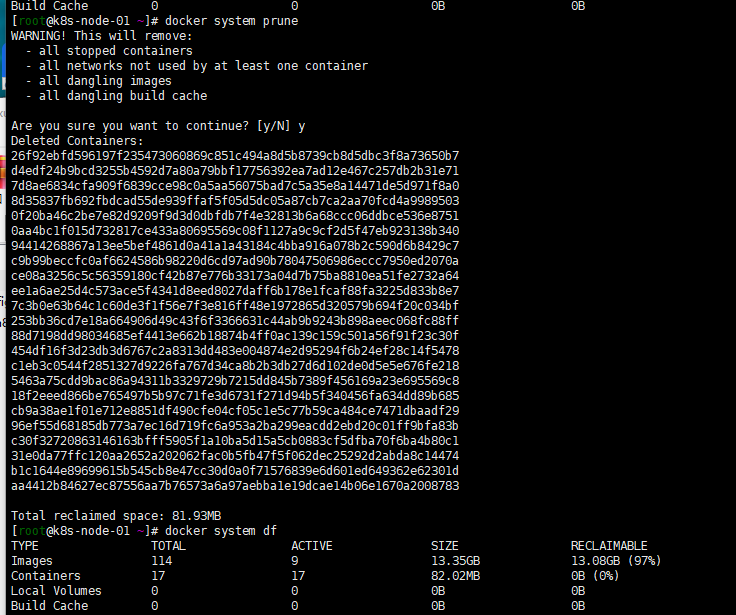
-
k8s-install-jenkins
描述背景:
注:kubernetes基本环境搭建完成,存储rook-ceph,rbd方式。代码仓库gitlab,容器仓库harbor,监控prometheus,负载方式都用了内部clusterip然后 traefik代理的方式。为了完善工具链,容器中搭建jenkins工具。
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 安装jenkins
- 建立命名空间
kubectl create namespace kube-ops 注:后续所有工具类应用程序都创建在此命名空间内。
- 创建ServiceAccount & ClusterRoleBinding
注:都是用的默认的,权限的管理还没有深入进行学习下。 cat <<EOF > rabc.yaml apiVersion: v1 kind: ServiceAccount metadata: name: jenkins2 namespace: kube-ops kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: jenkins2 rules: - apiGroups: ["extensions", "apps"] resources: ["deployments"] verbs: ["create", "delete", "get", "list", "watch", "patch", "update"] - apiGroups: [""] resources: ["services"] verbs: ["create", "delete", "get", "list", "watch", "patch", "update"] - apiGroups: [""] resources: ["pods"] verbs: ["create","delete","get","list","patch","update","watch"] - apiGroups: [""] resources: ["pods/exec"] verbs: ["create","delete","get","list","patch","update","watch"] - apiGroups: [""] resources: ["pods/log"] verbs: ["get","list","watch"] - apiGroups: [""] resources: ["secrets"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: jenkins2 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: jenkins2 subjects: - kind: ServiceAccount name: jenkins2 namespace: kube-ops EOF kubectl apply -f rabc.yaml3.deployment jenkins
cat <<EOF > jenkins.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: opspvc labels: app: jenkins2 namespace: kube-ops spec: storageClassName: rook-ceph-block accessModes: - ReadWriteOnce resources: requests: storage: 20Gi --- apiVersion: apps/v1 kind: Deployment metadata: name: jenkins2 namespace: kube-ops spec: selector: matchLabels: app: jenkins2 template: metadata: labels: app: jenkins2 spec: terminationGracePeriodSeconds: 10 serviceAccountName: jenkins2 containers: - name: jenkins image: jenkins/jenkins:lts imagePullPolicy: IfNotPresent ports: - containerPort: 8080 name: web protocol: TCP - containerPort: 50000 name: agent protocol: TCP resources: limits: cpu: 1000m memory: 1Gi requests: cpu: 500m memory: 512Mi livenessProbe: httpGet: path: /login port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 failureThreshold: 12 readinessProbe: httpGet: path: /login port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 failureThreshold: 12 volumeMounts: - name: jenkinshome subPath: jenkins2 mountPath: /var/jenkins_home env: - name: LIMITS_MEMORY valueFrom: resourceFieldRef: resource: limits.memory divisor: 1Mi - name: JAVA_OPTS value: -Xmx$(LIMITS_MEMORY)m -XshowSettings:vm -Dhudson.slaves.NodeProvisioner.initialDelay=0 -Dhudson.slaves.NodeProvisioner.MARGIN=50 -Dhudson.slaves.NodeProvisioner.MARGIN0=0.85 -Duser.timezone=Asia/Shanghai securityContext: fsGroup: 1000 volumes: - name: jenkinshome persistentVolumeClaim: claimName: opspvc --- apiVersion: v1 kind: Service metadata: name: jenkins2 namespace: kube-ops labels: app: jenkins2 spec: selector: app: jenkins2 ports: - name: web port: 8080 targetPort: web - name: agent port: 50000 targetPort: agent EOF kubectl apply -f jenkins.yaml 注: kubernetes 1.16 取消了extensions/v1beta1 api,使用apps/v1。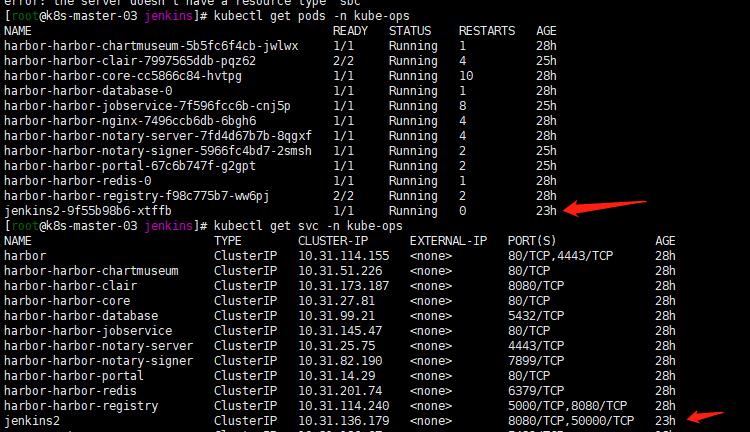
4.traefik对外暴露服务
cat <<EOF > ingress.yaml apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: jenkins2-https spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(\`jenkins.sainaihe.com\`) kind: Rule services: - name: jenkins2 port: 8080 EOF kubectl apply -f ingress.yaml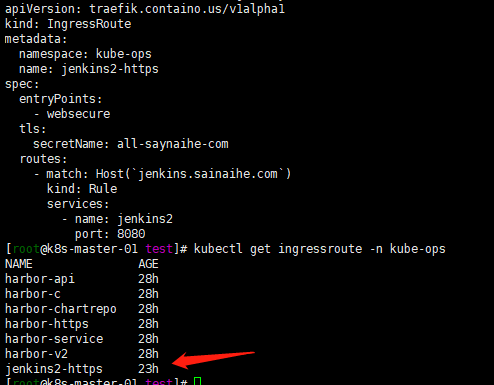
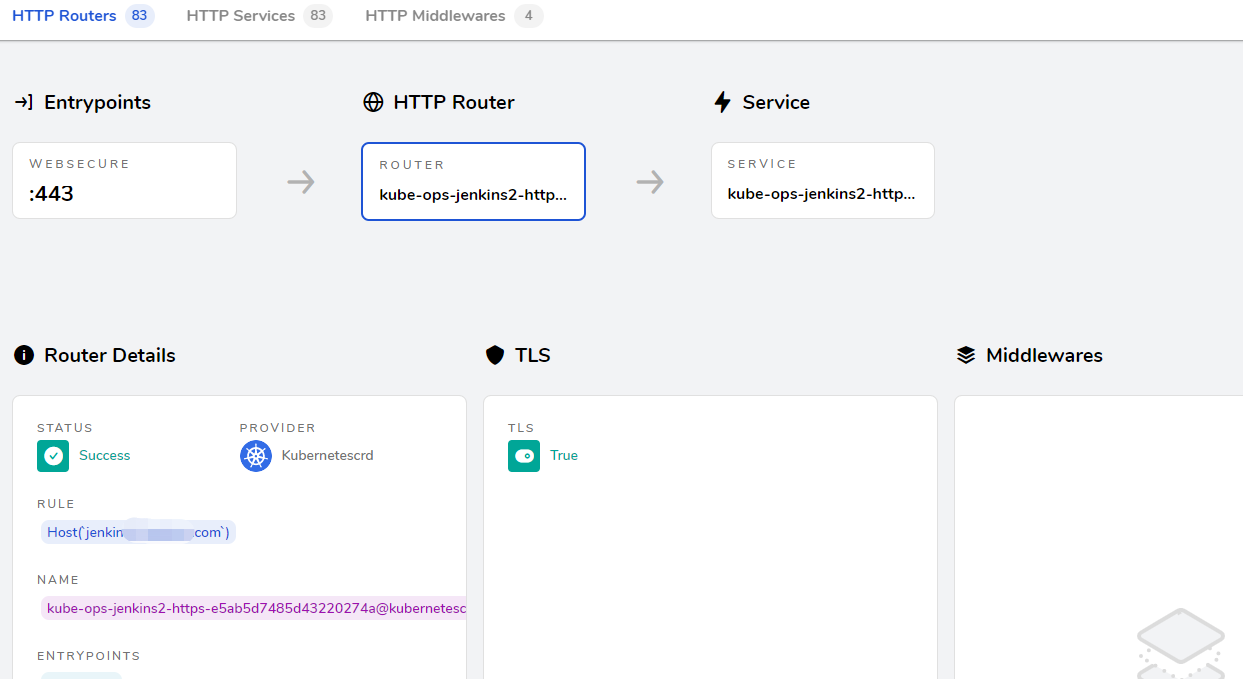
登陆jenkins。初始化配置
- 访问 https://jenkins.saynaihe.com,出现:
 获取初始密码
获取初始密码
kubectl exec -it jenkins2-9f55b98b6-xtffb cat /var/jenkins_home/secrets/initialAdminPassword -n kube-ops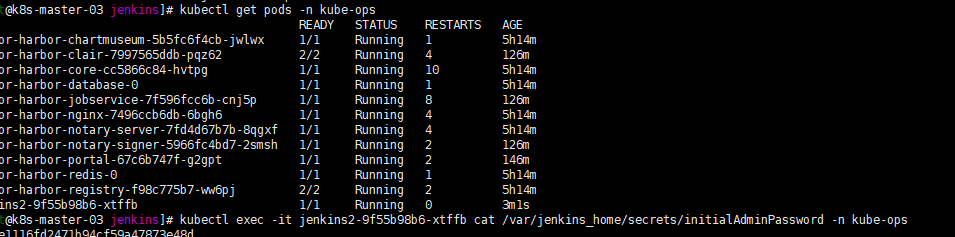
- 设置管理员账号密码,进入登陆界面
- 安装插件,安装了中文插件,pipeline,gitlab,git,github 参数化插件等,看个人需要安装吧。
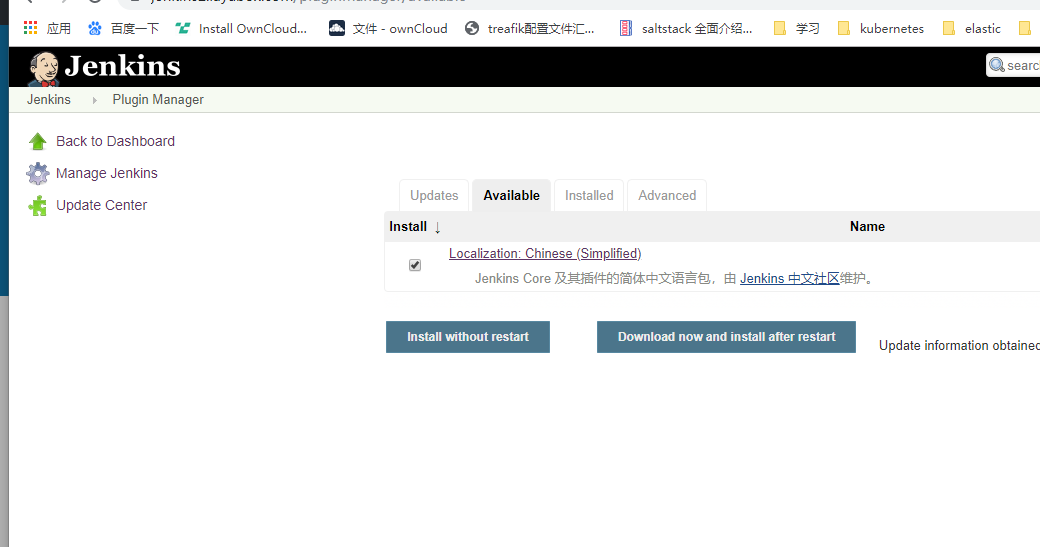
 注:因为国外源不稳定 国内有其他备用源可以切换比如清华的源。jenkins中文社区有篇文章:https://mp.weixin.qq.com/s/rqx93WI0UEvzqaFrt84i8A可以参考。
注:因为国外源不稳定 国内有其他备用源可以切换比如清华的源。jenkins中文社区有篇文章:https://mp.weixin.qq.com/s/rqx93WI0UEvzqaFrt84i8A可以参考。
- 建立命名空间
-
k8s-install-prometheus-operator
- 描述背景:
描述背景:
注:搭建prometheus-operator
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 安装prometheus-operator
先说下自己的流程:
- 克隆prometheus-operator仓库
- 按照官方quickstart进行安装
- treafik代理prometheus grafana alertmanager
- 添加 kubeControllerManager kubeScheduler监控
- 监控集群etcd服务
- 开启服务自动发现,配置可持续存储,修改prometheus Storage Retention参数设置数据保留时间
- grafana添加监控模板,持久化
- 微信报警
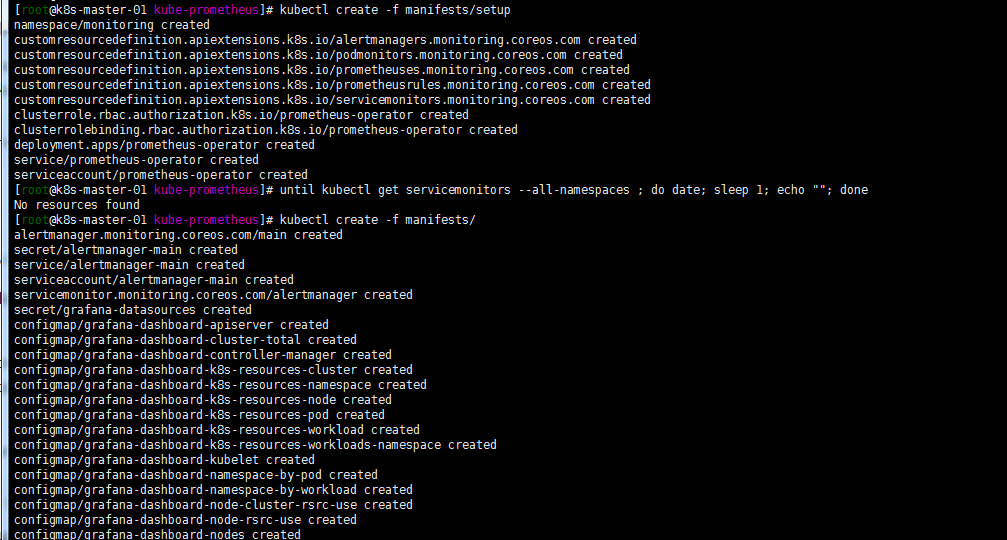
克隆prometheus-operator仓库
注:新版本升级后和旧版本文件结构有些不一样 可以参照github仓库文档quickstart.
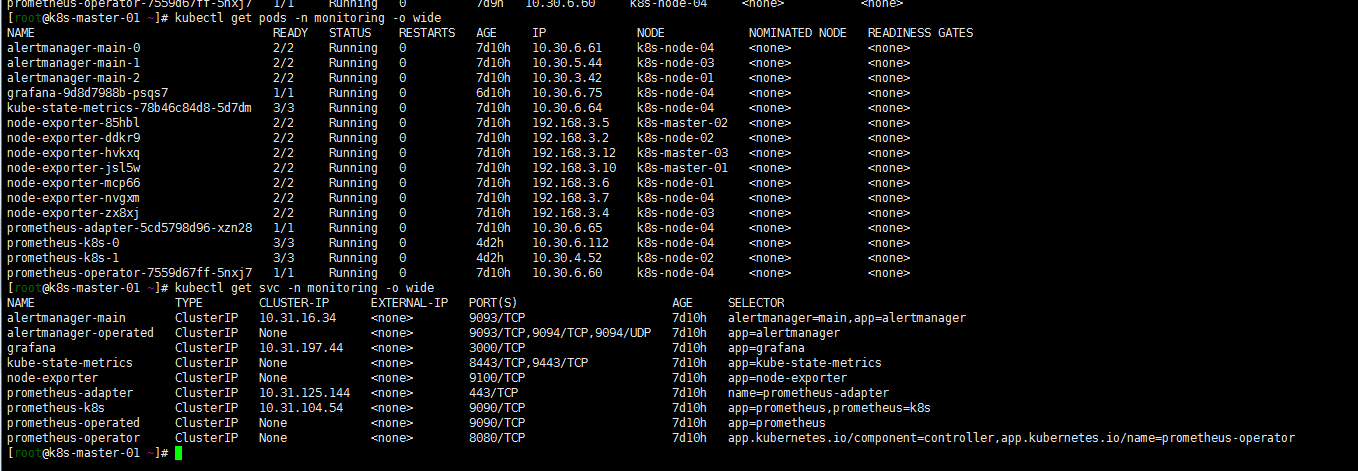
git clone https://github.com/coreos/kube-prometheus cd kube-prometheus ###创建命名空间和crd.保证可用后建立相关资源 kubectl create -f manifests/setup until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done kubectl create -f manifests/ kubectl get pods -n monitoring [root@k8s-master-01 work]# kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE grafana-58dc7468d7-6v86k 1/1 Running 0 9m kube-state-metrics-78b46c84d8-ns7hk 2/3 ImagePullBackOff 0 9m node-exporter-4pr77 2/2 Running 0 9m node-exporter-6jhz5 2/2 Running 0 9m node-exporter-8xv8v 2/2 Running 0 9m node-exporter-ngt9r 2/2 Running 0 9m node-exporter-nlff4 2/2 Running 0 9m node-exporter-pw554 2/2 Running 0 9m node-exporter-rwpfj 2/2 Running 0 9m node-exporter-thz4j 2/2 Running 0 9m prometheus-adapter-5cd5798d96-2jnjl 0/1 ImagePullBackOff 0 9m prometheus-operator-99dccdc56-zr6fw 0/1 ImagePullBackOff 0 9m11s注意:会出现有些镜像下载不下来的问题,可墙外服务器下载镜像修改tag上传到harbor,修改yaml文件中镜像为对应harbor tag解决。最终如下图:
treafik代理prometheus grafana alertmanager
monitoring下创建http证书(ssl证书目录下执行) kubectl create secret tls all-saynaihe-com --key=2_sainaihe.com.key --cert=1_saynaihe.com_bundle.crt -n monitoring cat <<EOF > monitoring.com.yaml apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: monitoring name: alertmanager-main-https spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`alertmanager.saynaihe.com`) kind: Rule services: - name: alertmanager-main port: 9093 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: monitoring name: grafana-https spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`monitoring.saynaihe.com`) kind: Rule services: - name: grafana port: 3000 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: monitoring name: prometheus spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`prometheus.saynaihe.com`) kind: Rule services: - name: prometheus-k8s port: 9090 --- EOF kubectl apply -f monitoring.com.yaml 登录https://monitoring.saynaihe.com/ https://prometheus.saynaihe.com/ https://alertmanager.saynaihe.com/ 查看,如下图:
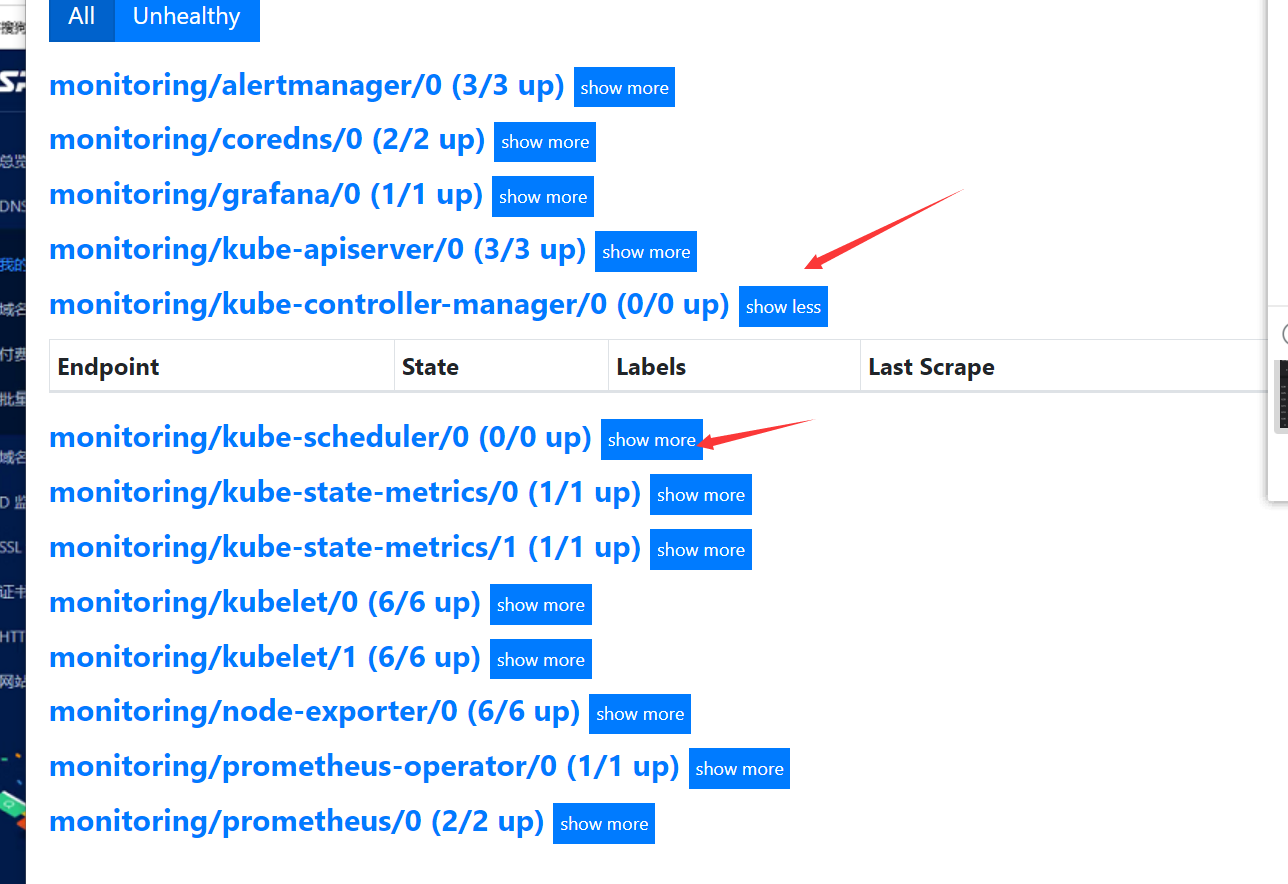
添加 kubeControllerManager kubeScheduler监控
在https://prometheus.saynaihe.com/targets中可以看到, kubeControllerManager kubeScheduler没有能正常监控。
可参照https://www.qikqiak.com/post/first-use-prometheus-operator/ 阳明大佬的文档:
cat <<EOF > prometheus-kubeControllerManagerService.yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: selector: component: kube-controller-manager ports: - name: http-metrics port: 10252 targetPort: 10252 protocol: TCP EOF kubectl apply -f prometheus-kubeControllerManagerService.yaml cat <<EOF > prometheus-kubeSchedulerService.yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: k8s-app: kube-scheduler spec: selector: component: kube-scheduler ports: - name: http-metrics port: 10251 targetPort: 10251 protocol: TCP EOF kubectl apply -f prometheus-kubeSchedulerService.yaml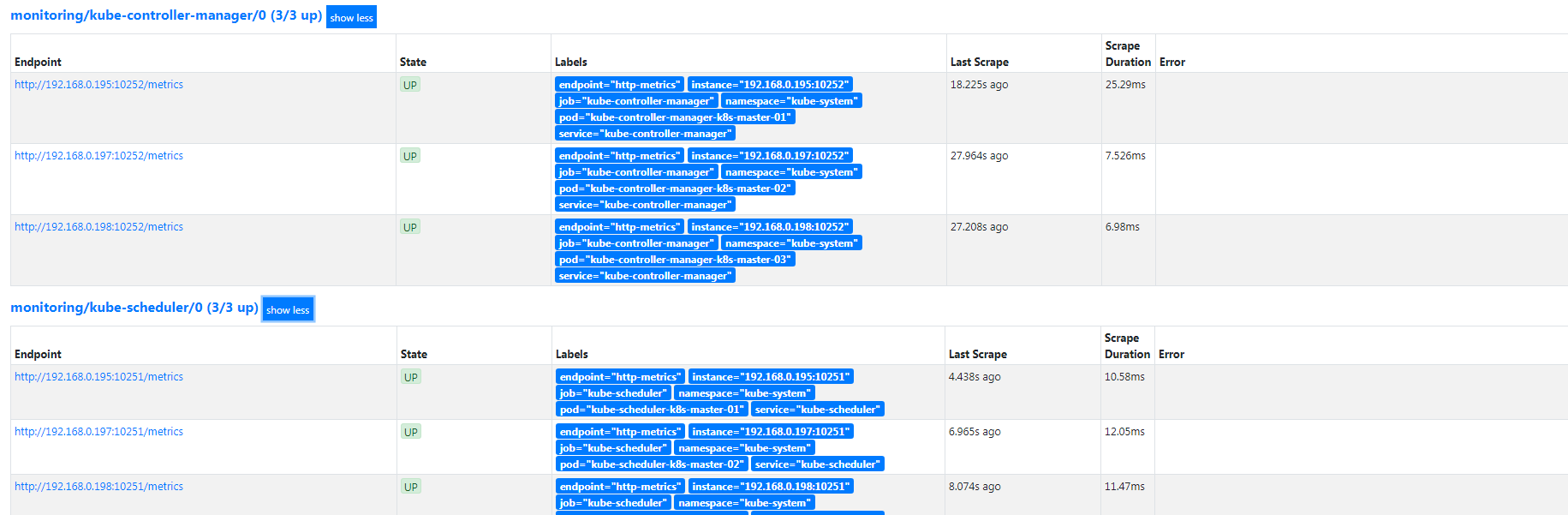
监控集群etcd服务
kubernetes 安装etcd一般常用的是两种 外部搭建etcd和 容器化运行etc两种的方式都写了下。也特别说下既然都用了kubernetes了 都上了容器了 没有必要去外部搭建etd集群。尤其是后期集群升级,etcd的版本 各种的 会有些恶心,安装kubernetes集群还是安装官方的指导的安装比较好,个人觉得很多教程让二进制安装和kubeadm安装还外挂etcd集群的方式很爽反感。除非有良好系统的基础不建议那么的玩了。
kubadm安装集成etcd方式下操作:
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt cat <<EOF > prometheus-serviceMonitorEtcd.yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: etcd-k8s namespace: monitoring labels: k8s-app: etcd-k8s spec: jobLabel: k8s-app endpoints: - port: port interval: 30s scheme: https tlsConfig: caFile: /etc/prometheus/secrets/etcd-certs/ca.crt certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key insecureSkipVerify: true selector: matchLabels: k8s-app: etcd namespaceSelector: matchNames: - kube-system EOF kubectl apply -f prometheus-serviceMonitorEtcd.yamlkubadm安装挂载外部安装etcd方式下操作:
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/etcd/ssl/ca.pem --from-file=/etc/etcd/ssl/server.pem --from-file=/etc/etcd/ssl/server-key.pem cat <<EOF > prometheus-serviceMonitorEtcd.yaml apiVersion: v1 kind: Service metadata: name: etcd-k8s namespace: kube-system labels: k8s-app: etcd spec: type: ClusterIP clusterIP: None ports: - name: api port: 2379 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: name: etcd-k8s namespace: kube-system labels: k8s-app: etcd subsets: - addresses: - ip: 192.168.0.195 nodeName: etcd1 - ip: 192.168.0.197 nodeName: etcd2 - ip: 192.168.0.198 nodeName: etcd3 ports: - name: api port: 2379 protocol: TCP --- apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: etcd-k8s namespace: monitoring labels: k8s-app: etcd-k8s spec: jobLabel: k8s-app endpoints: - port: api interval: 30s scheme: https tlsConfig: caFile: /etc/prometheus/secrets/etcd-certs/ca.pem certFile: /etc/prometheus/secrets/etcd-certs/server.pem keyFile: /etc/prometheus/secrets/etcd-certs/server-key.pem #use insecureSkipVerify only if you cannot use a Subject Alternative Name insecureSkipVerify: true selector: matchLabels: k8s-app: etcd namespaceSelector: matchNames: - kube-system EOF kubectl apply -f prometheus-serviceMonitorEtcd.yaml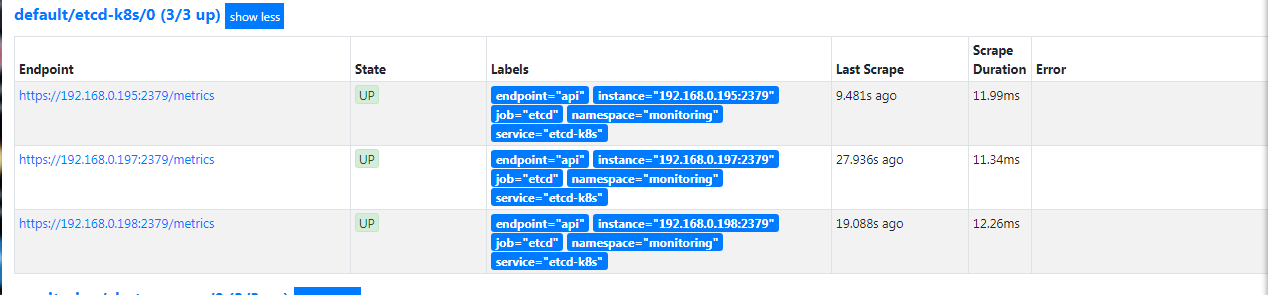
开启服务自动发现,配置可持续存储,修改prometheus Storage Retention参数设置数据保留时间
参照https://www.qikqiak.com/post/prometheus-operator-advance/,自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明,然后通过这个文件创建一个对应的 Secret 对象。由于配置可持续存储和修改retention参数都在同一个配置文件就都写在一起了
cat <<EOF > prometheus-additional.yaml - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name EOF $ kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring secret "additional-configs" created #修改crd文件, cat <<EOF > prometheus-prometheus.yaml apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: labels: prometheus: k8s name: k8s namespace: monitoring spec: alerting: alertmanagers: - name: alertmanager-main namespace: monitoring port: web storage: volumeClaimTemplate: spec: storageClassName: rook-ceph-block resources: requests: storage: 20Gi baseImage: quay.io/prometheus/prometheus nodeSelector: kubernetes.io/os: linux podMonitorSelector: {} replicas: 2 resources: requests: memory: 400Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 additionalScrapeConfigs: name: additional-configs key: prometheus-additional.yaml serviceAccountName: prometheus-k8s retention: 15d serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: v2.11.0 EOF kubectl apply -f prometheus-prometheus.yaml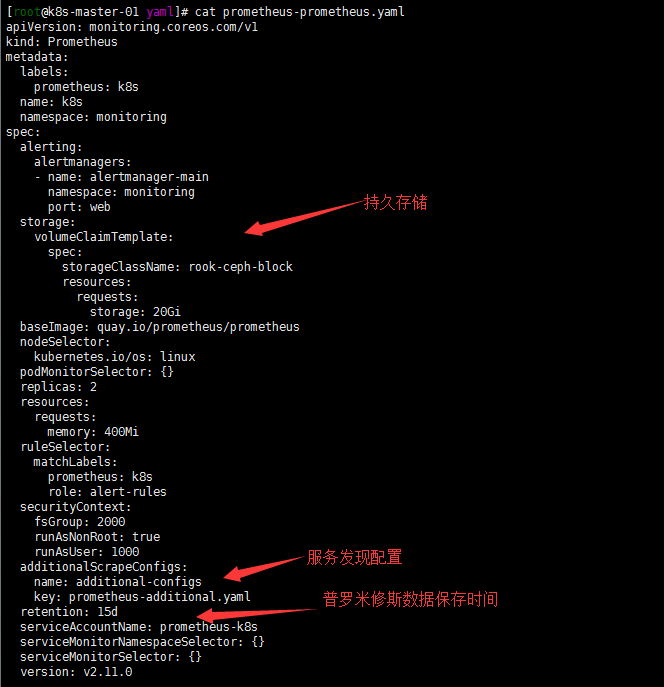
由于RABC权限问题,Prometheus Dashboard 的配置页面下面我们可以看到已经有了对应的的配置信息了,但是我们切换到 targets 页面下面却并没有发现对应的监控任务
cat <<EOF > prometheus-clusterRole.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus-k8s rules: - apiGroups: - "" resources: - nodes - services - endpoints - pods - nodes/proxy verbs: - get - list - watch - apiGroups: - "" resources: - configmaps - nodes/metrics verbs: - get - nonResourceURLs: - /metrics verbs: - get EOF kubectl apply -f rometheus-clusterRole.yaml
grafana添加监控模板,持久化
持久化
cat <<EOF > grafana-pv.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: grafana namespace: monitoring spec: storageClassName: rook-ceph-block accessModes: - ReadWriteOnce resources: requests: storage: 20Gi EOF kubectl apply -f grafana-pv.yaml 修改grafana-deployment.yaml,如下图: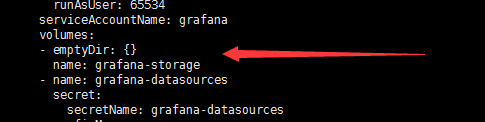
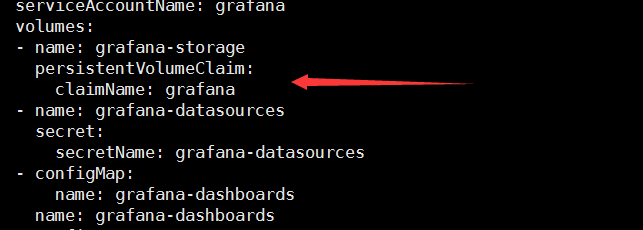
kubectl apply -f grafana-deployment.yaml
grafana添加模板,只添加了treafik2 和etcd模板
登录https://monitoring.saynaihe.com/dashboards import模板号10906 3070. 打开dashboard,有的模板会出现Panel plugin not found: grafana-piechart-panel 。 解决方法:重新构建grafana镜像,/usr/share/grafana/bin/grafana-cli plugins install grafana-piechart-panel安装缺失插件
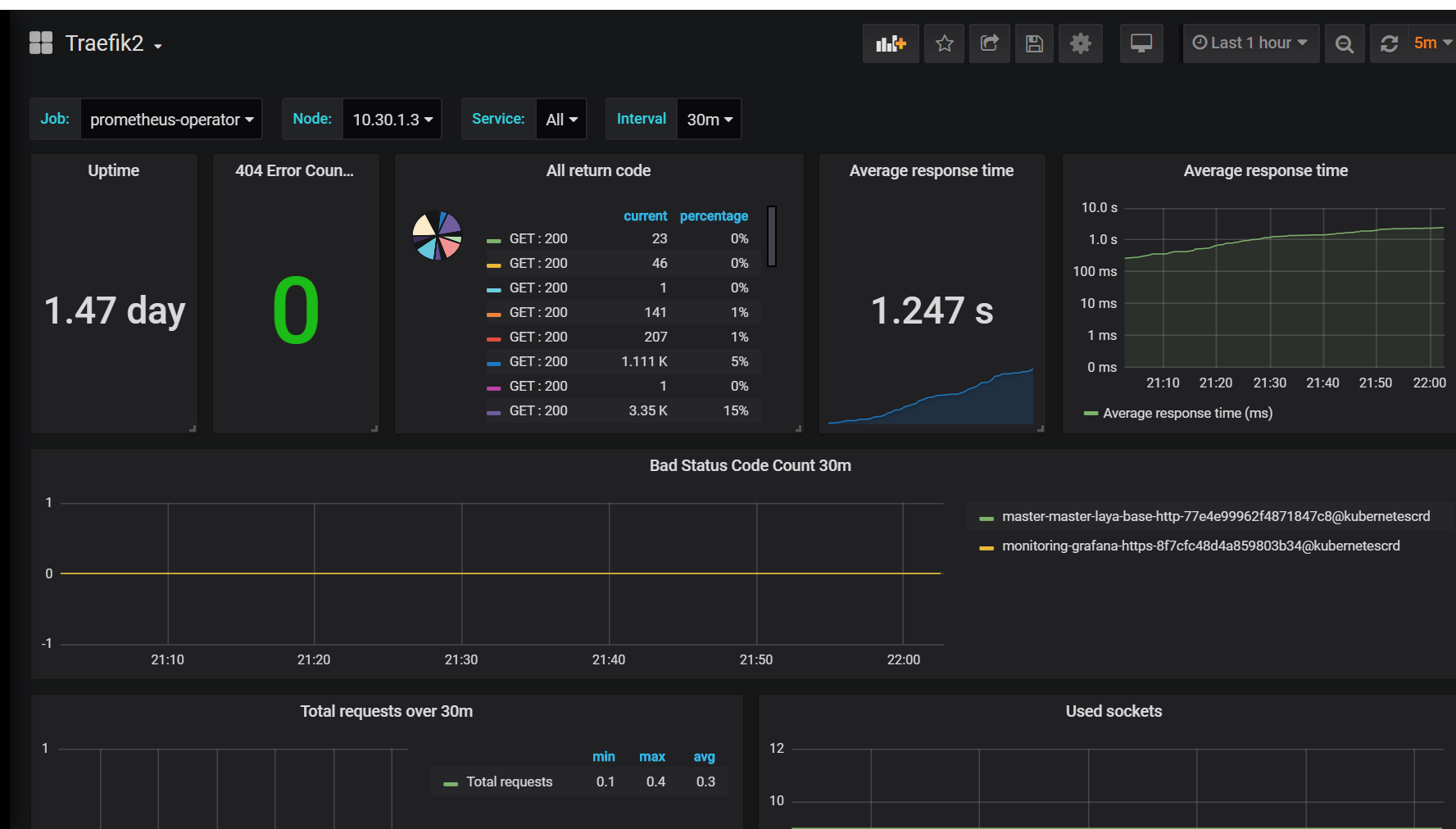
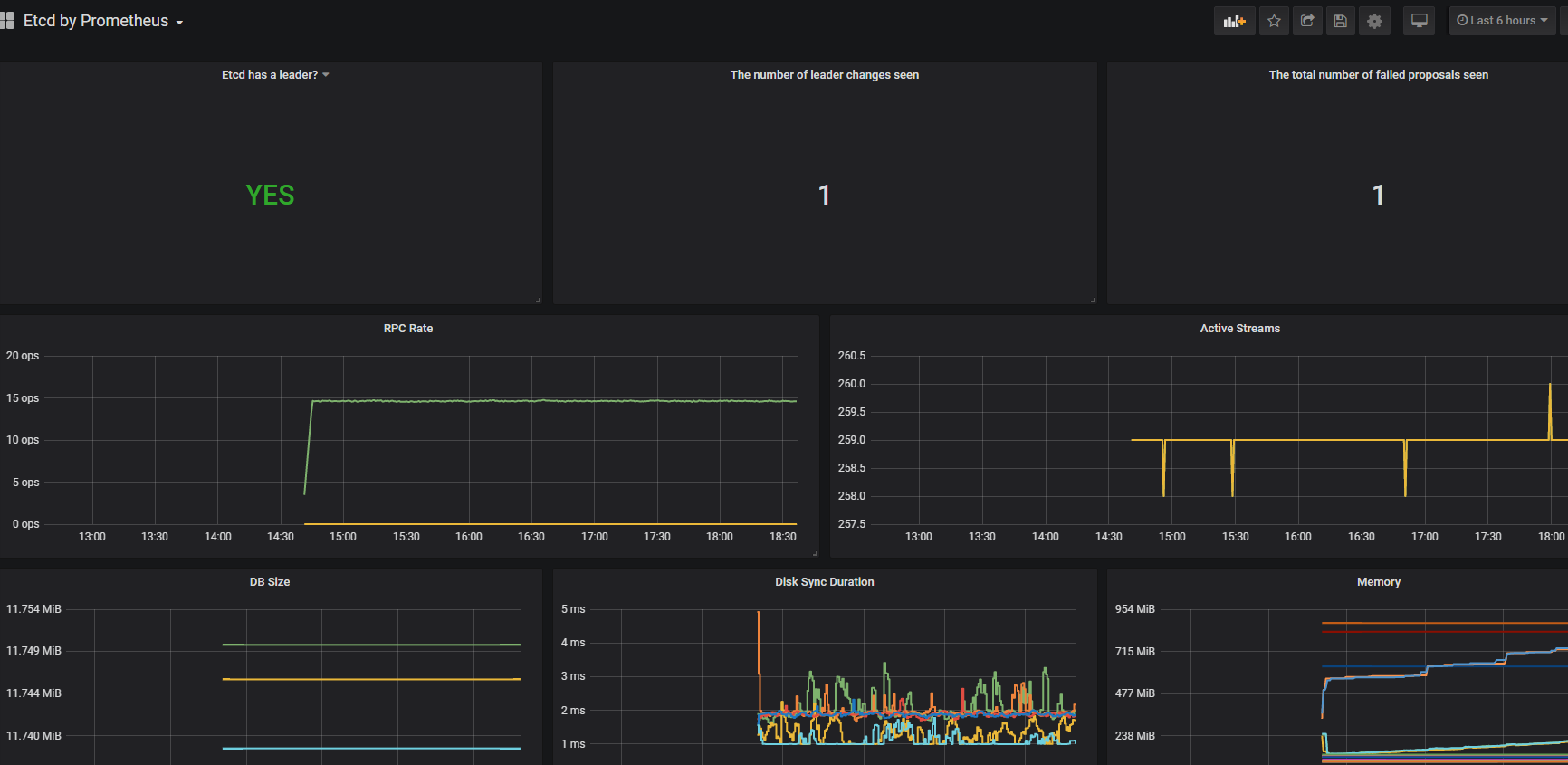
微信报警
将对应参数修改为自己微信企业号相对应参数
cat <<EOF > alertmanager.yaml global: resolve_timeout: 2m wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' route: group_by: ['alert'] group_wait: 10s group_interval: 1m repeat_interval: 1h receiver: wechat receivers: - name: 'wechat' wechat_configs: - api_secret: 'xxxx' send_resolved: true to_user: '@all' to_party: 'xxx' agent_id: 'xxx' corp_id: 'xxxx' templates: - '/etc/config/alert/wechat.tmpl' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] EOF cat <<EOF > wechat.tpl ☸ Alerts Firing ✖️ ‼️ : ☎️ 触发警报 ☔ ☠️ : ☞名称空间: ☞主机: ☞job: ->涉及容器名称: ->Pod名称: 告警级别: 告警详情: 触发时间⏱: 警报链接: ✍️ 备注详情❄️: -------------------->END<-------------------- ☸ Alerts Resolved ✔️: ☎️ 触发警报 ☫ : ♥️ 名称空间 ✝️ : ♥️ ->涉及容器名称: ♥️ ->Pod名称☸: ♥️ 告警级别: ♥️ 告警详情: ♥️ 触发时间 ⏱ : ♥️ 恢复时间 ⏲ : ♥️ 备注详情: -------------------->END<-------------------- EOF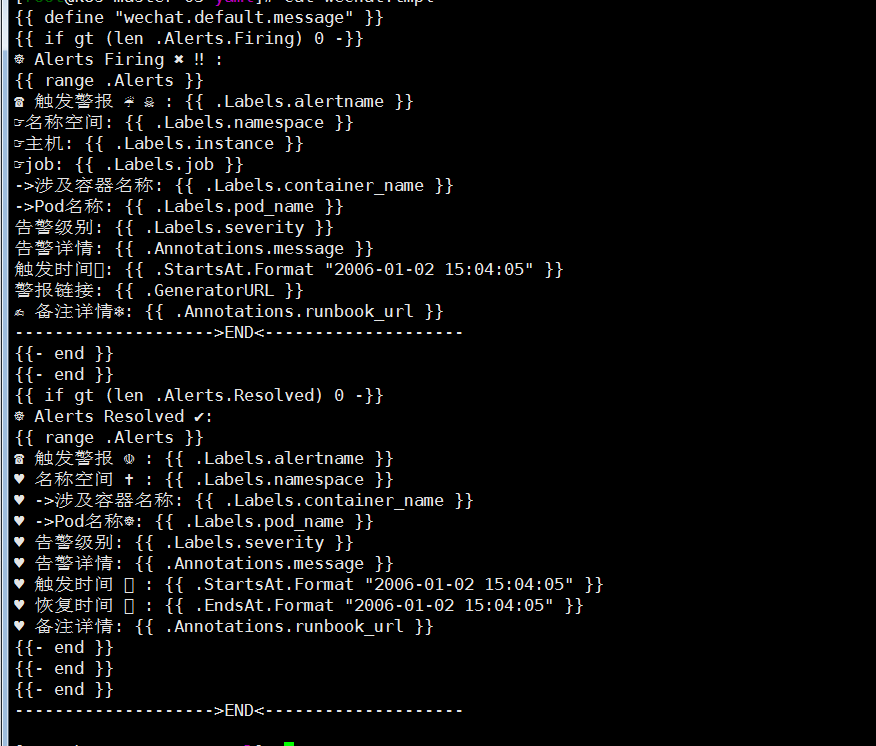
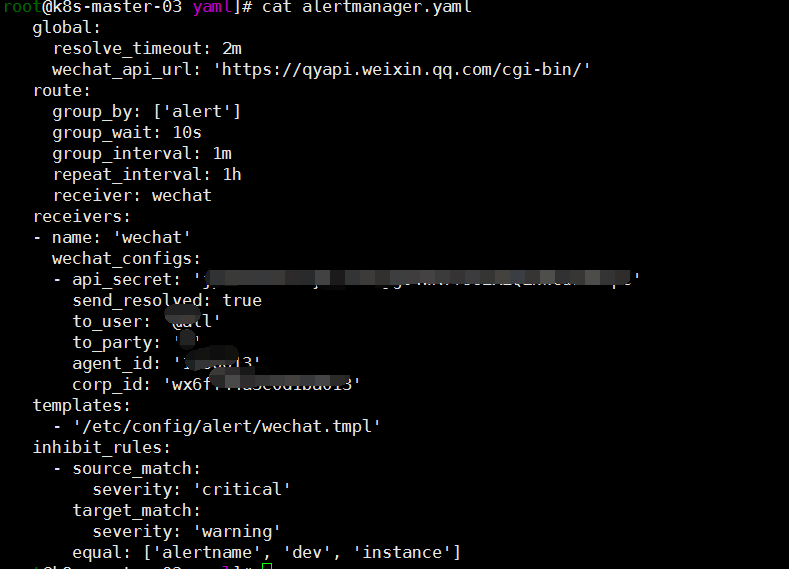
kubectl delete secret alertmanager-main -n monitoring kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --from-file=wechat.tmpl -n monitoring wechat.tpl模板可以根据自己需求自己定制,我这里就找了个网上的例子,格式不太会玩,貌似看不到,如下图
基本完成。具体的修改可参考个人实际。
-
2019-10-28-k8s-helm-install-harbor
描述背景:
注:记录各种常见问题
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 安装harbor
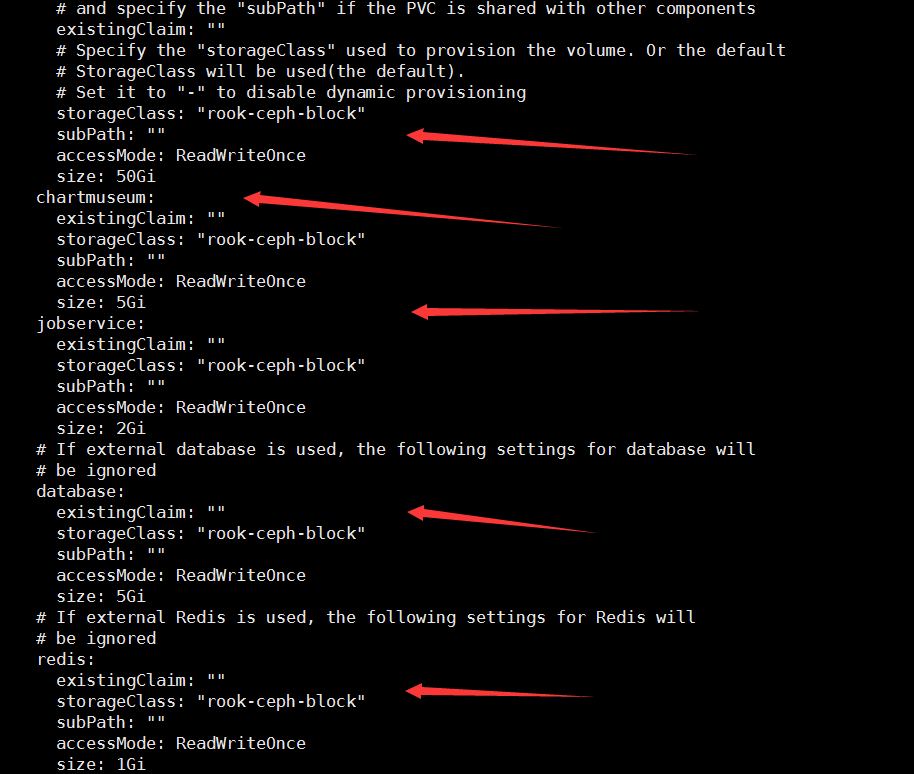
# 下载harbor仓库 git clone https://github.com/goharbor/harbor-helm 注:偶尔会下载了 部署不成功,如有此状况尽量选择稳定分支。 #修改配置文件values.yaml 代理使用了treafik,对外暴露模式没有使用loadBalancer和nodePort,选择了clusterIP,然后使用treafik代理,集群中安装了rook-ceph.存储storageClass: "rook-ceph-block"配置文件就修改了这两个配置。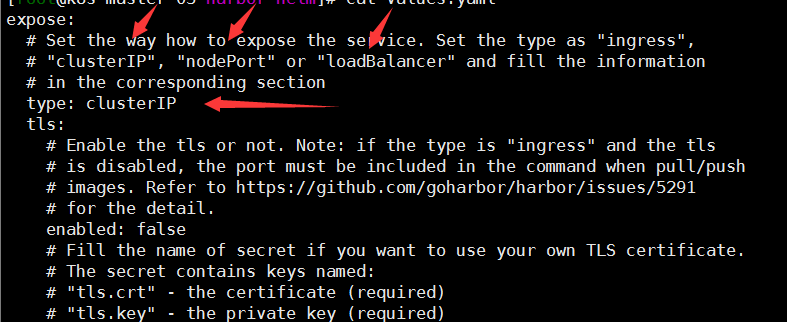
helm安装 harbor
helm install --name harbor -f values.yaml . --namespace kube-ops # 等待pod running kubectl get pods -n kube-ops -w 如果pod一直pending 基本是pv,pvc的问题 查看下自己的storageclass ,pv,pvc配置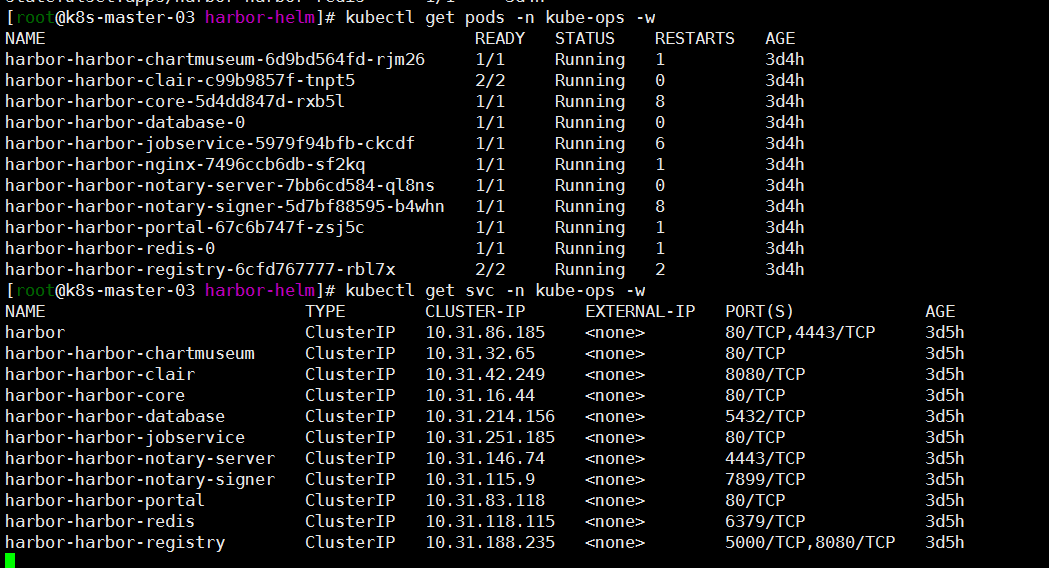
treafik 代理harbor
kube-ops下创建http证书(ssl证书目录下执行) kubectl create secret tls all-saynaihe-com --key=2_sainaihe.com.key --cert=1_saynaihe.com_bundle.crt -n kube-ops cat <<EOF > harbor.saynaihe.com.yaml apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: harbor-https spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`harbor.saynaihe.com`) && PathPrefix(`/`) kind: Rule services: - name: harbor-harbor-portal port: 80 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: harbor-api spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`harbor.saynaihe.com`) && PathPrefix(`/api`) kind: Rule services: - name: harbor-harbor-core port: 80 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: harbor-service spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`harbor.saynaihe.com`) && PathPrefix(`/service`) kind: Rule services: - name: harbor-harbor-core port: 80 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: harbor-v2 spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`harbor.saynaihe.com`) && PathPrefix(`/v2`) kind: Rule services: - name: harbor-harbor-core port: 80 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: harbor-chartrepo spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`harbor.saynaihe.com`) && PathPrefix(`/chartrepo`) kind: Rule services: - name: harbor-harbor-core port: 80 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: harbor-c spec: entryPoints: - websecure tls: secretName: all-saynaihe-com routes: - match: Host(`harbor.saynaihe.com`) && PathPrefix(`/c`) kind: Rule services: - name: harbor-harbor-core port: 80 EOF kubectl apply -f harbor.saynaihe.com.yaml 登录https://traefik.lsaynaihe.com/dashboard/#/http/routers 查看,如下图: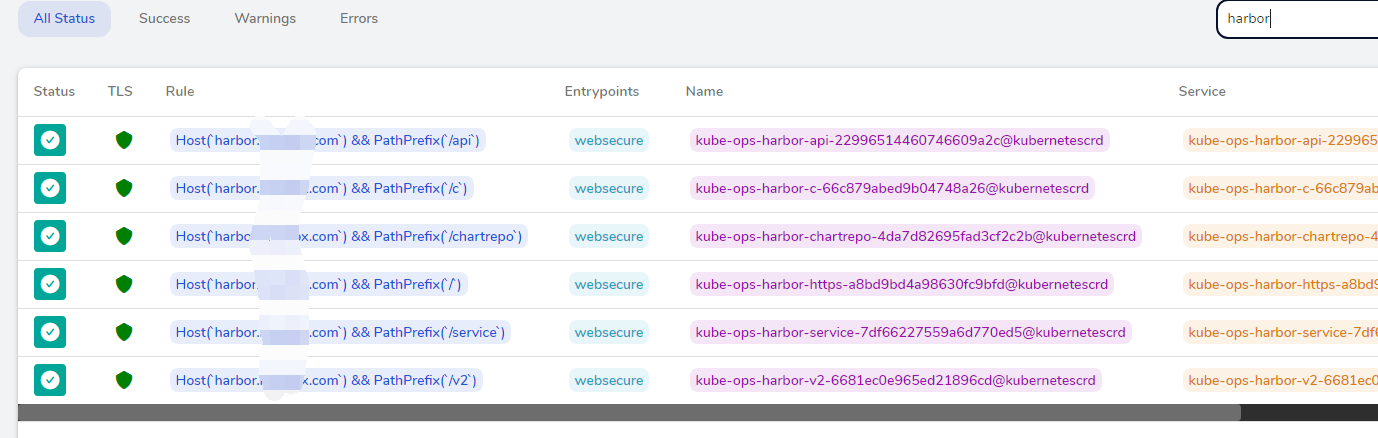
web登录harbor
注:密码为配置文件中默认Harbor12345,在安装前可自定义修改,我选择了登录后自主修改: OK安装完成,harbor还在摸索中,最喜欢的一个功能是同步其他仓库非常方便: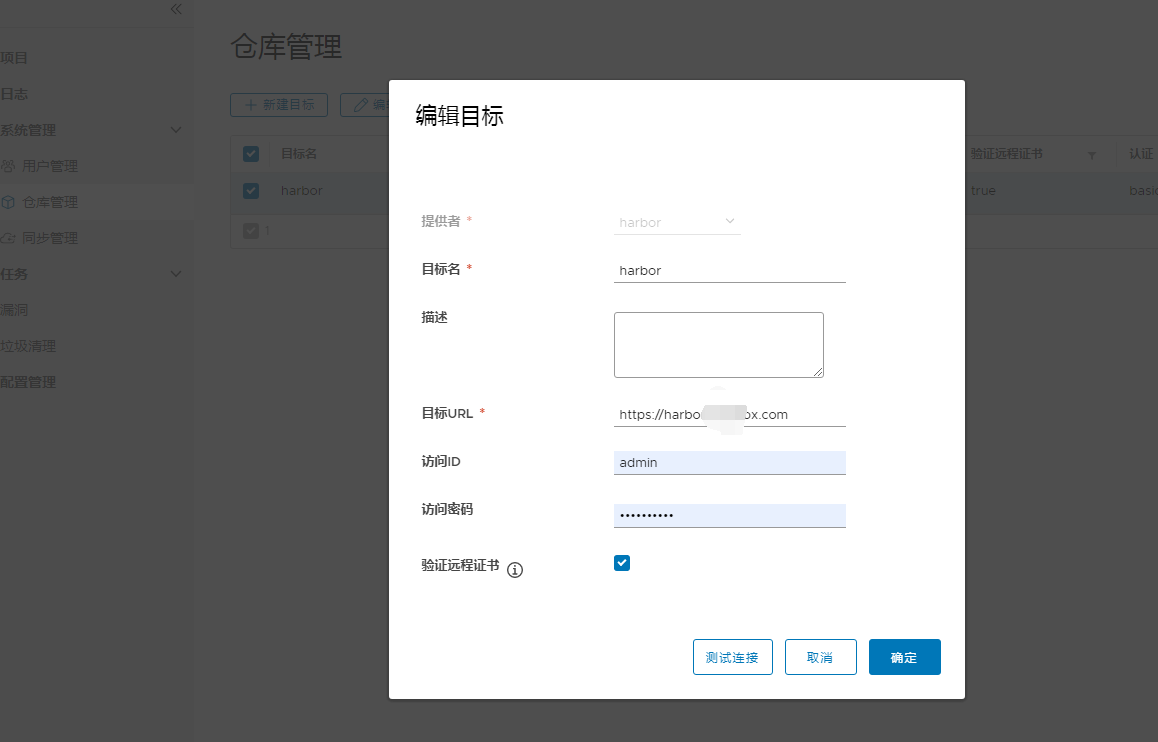
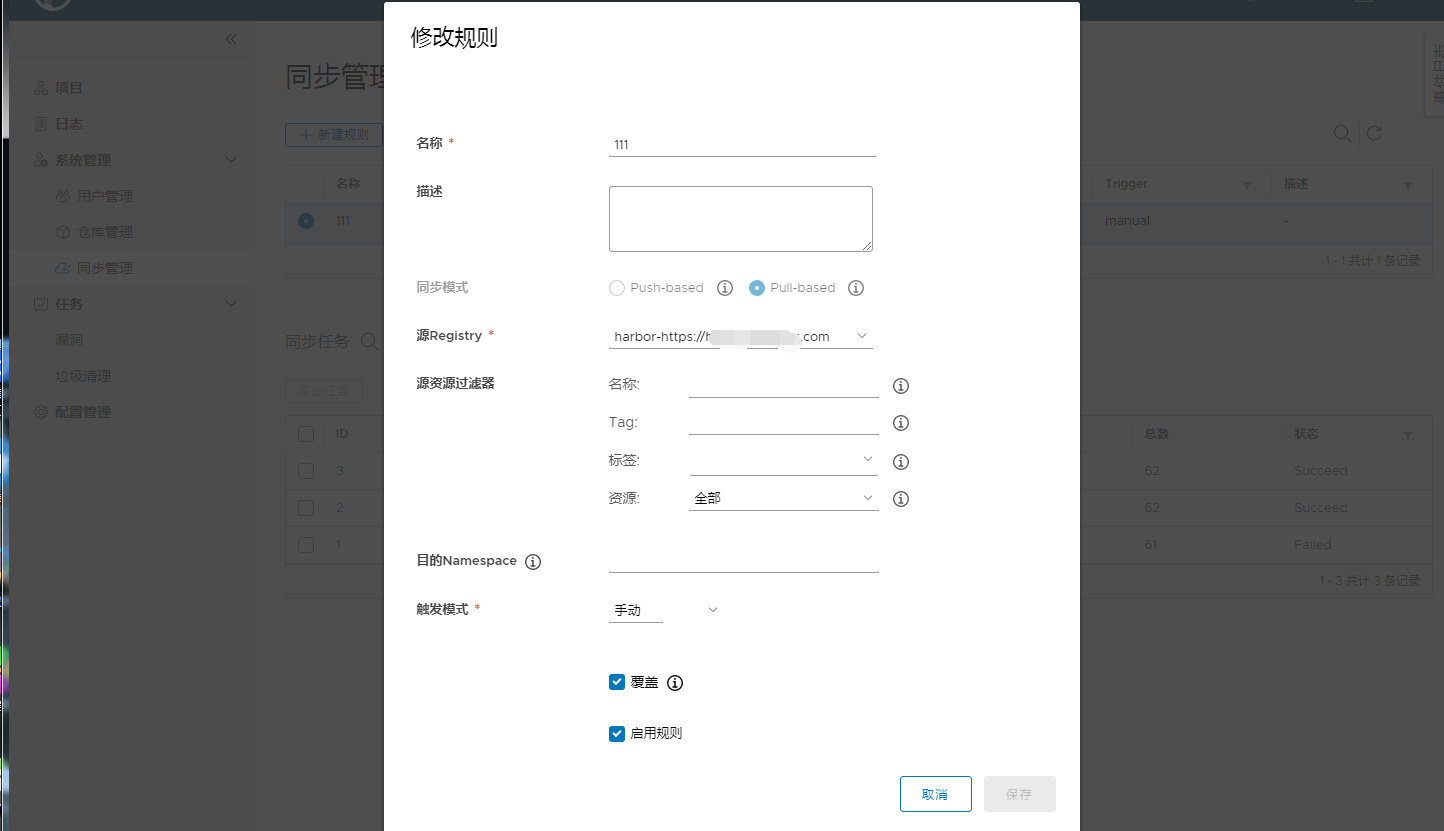
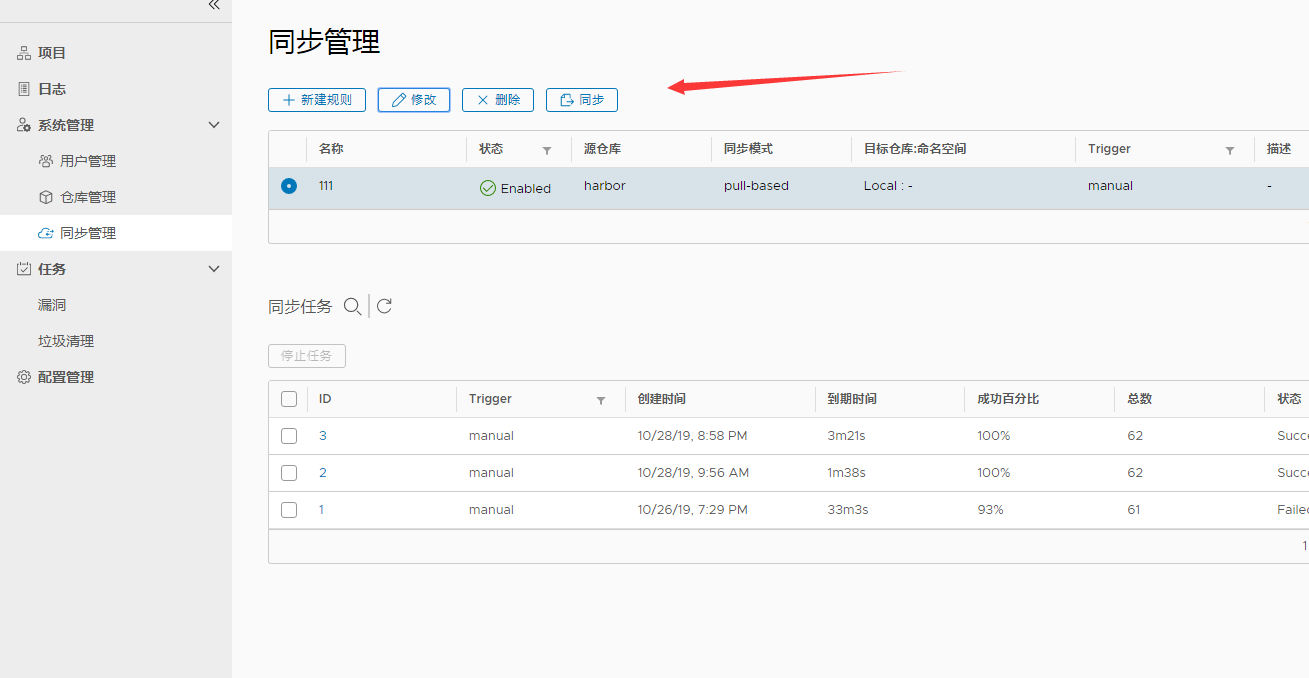
-
2019-10-28-k8s-helm-install
描述背景:
注:记录各种常见问题
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 安装Helm2
helm 现在大版本有2和3两个版本,个人安装了helm2版本的1.15.1 version=v2.15.1 wget https://get.helm.sh/helm-${version}-linux-amd64.tar.gz tar -zxvf helm-*-linux-amd64.tar.gz cp linux-amd64/helm /usr/local/bin/helm #安装tiller helm init --tiller-image=gcr.azk8s.cn/kubernetes-helm/tiller:${version} #查看helm版本 helm version --short Client: v2.15.1+gcf1de4f Server: v2.15.1+gcf1de4f 但是kubernetes 1.16.2安装貌似会有权限问题的,执行以下命令: kubectl -n kube-system create serviceaccount tiller kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller helm init --tiller-image=gcr.azk8s.cn/kubernetes-helm/tiller:${version} --service-account tiller --upgrade [root@k8s-master-03 ~]# kubectl -n kube-system get all | grep tiller pod/tiller-deploy-76858c97cd-sgmf6 1/1 Running 1 2d6h service/tiller-deploy ClusterIP 10.31.70.242 <none> 44134/TCP 2d6h deployment.apps/tiller-deploy 1/1 1 1 2d6h replicaset.apps/tiller-deploy-76858c97cd 1 1 1 2d6h
-
kuberntes1.16 question
描述背景:
注:记录各种常见问题
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 1.网桥配置问题:sd_journal_get_cursor() failed: ‘Cannot assign requested address’ [v8.24.0-34.el7]
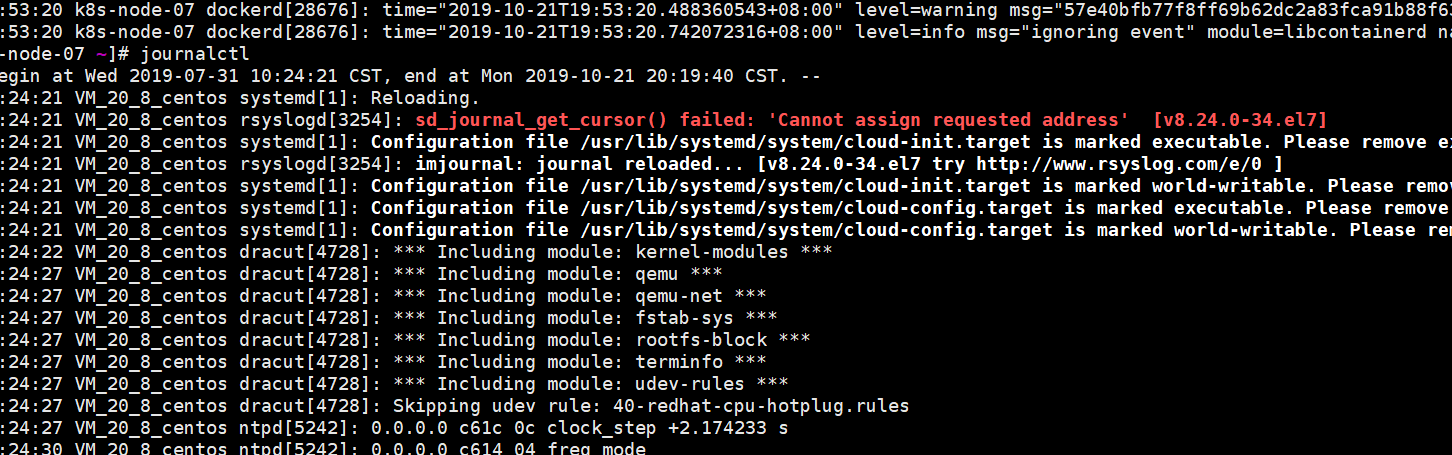
kubernetes 集群中有内部同一namespace下通信用的直接连service的方式有一service下pod访问另外一service无法访问。但是访问其他同一命名空间下都是没有问题的,kubectl get pod -o wide 看到此pod位于node-07.node-07节点执行journalctl 看日志中有sd_journal_get_cursor() failed: 'Cannot assign requested address' [v8.24.0-34.el7],百度了下https://blog.csdn.net/wkb342814892/article/details/79543984应该是没有开启网桥转发: modprobe br_netfilter cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf ls /proc/sys/net/bridgeOK问题解决
-
kuberntes1.16安装efk
2019-10-21duiniwukenaihe- 描述背景:
- 关于Elastic Cloud on Kubernetes
- 安装Elastic Cloud on Kubernetes
- 安装elasticsearch on cluster
- 安装kibana on cluaster
- kibana traefik对外暴露
- 接下来fluent-bit 安装
- 登录kibana 进行相关配置
描述背景:
注: 文章配置文件示例都是拿阳明大佬博客https://www.qikqiak.com/post/elastic-cloud-on-k8s/ 还有elastic官方文档,阳明大佬文档是旧的新版本有所改变尽量参考官方文档,fluent-bit也有必要看下官方文档 —
集群配置: 初始集群环境kubeadm 1.16.1
ip 自定义域名 主机名 192.168.3.8 master.k8s.io k8s-vip 192.168.3.10 master01.k8s.io k8s-master-01 192.168.3.5 master02.k8s.io k8s-master-02 192.168.3.12 master03.k8s.io k8s-master-03 192.168.3.6 node01.k8s.io k8s-node-01 192.168.3.2 node02.k8s.io k8s-node-02 192.168.3.4 node03.k8s.io k8s-node-03 关于Elastic Cloud on Kubernetes
Elastic Cloud on Kubernetes(ECK)是一个 Elasticsearch Operator,elastic推出的一个便于部署管理的项目,而且内部集成了核心安全功能(TLS 加密、基于角色的访问控制,以及文件和原生身份验证)免费提供。
安装Elastic Cloud on Kubernetes
当前最新版本为1.0,参考:https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-quickstart.html。
kubectl apply -f https://download.elastic.co/downloads/eck/1.0.0-beta1/all-in-one.yaml kubectl get pods -n elastic-system kubectl -n elastic-system logs -f statefulset.apps/elastic-operator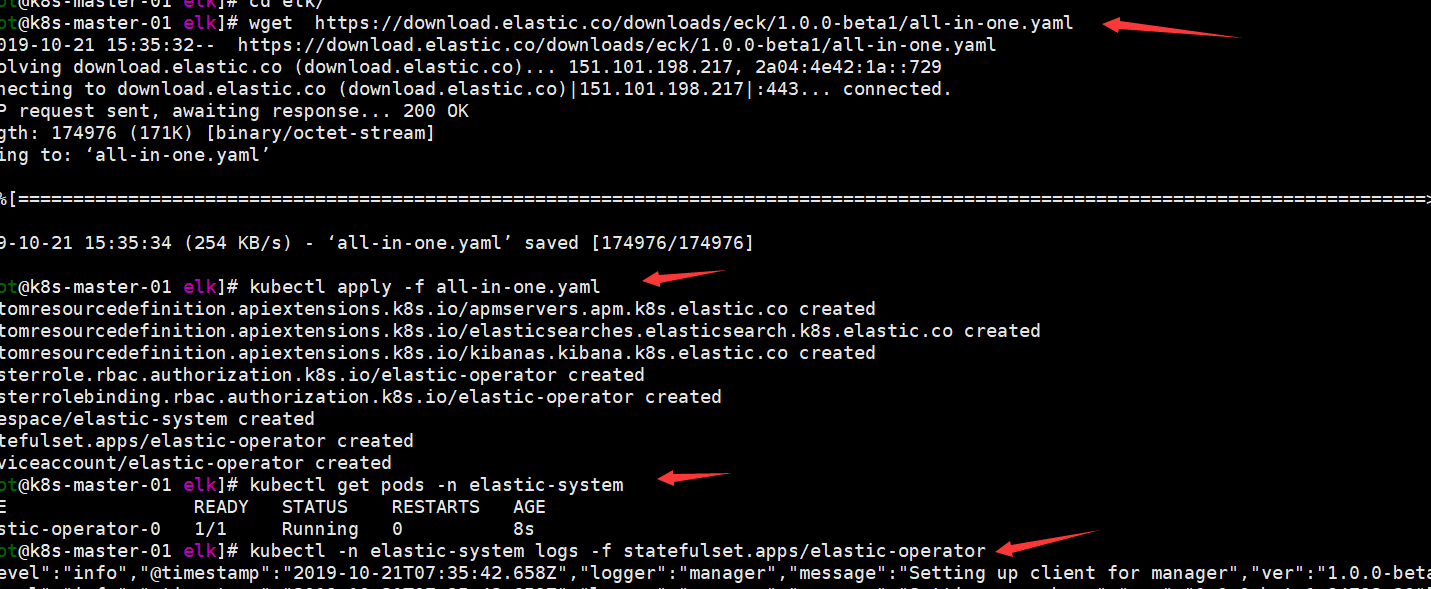
安装elasticsearch on cluster
官方示例 0.8 示例中apiversion还是elasticsearch.k8s.elastic.co/v1alpha1,1.0更新为elasticsearch.k8s.elastic.co/v1beta1。所以最好能看下最新的官方文档。
cat <<EOF | kubectl apply -f - apiVersion: elasticsearch.k8s.elastic.co/v1beta1 kind: Elasticsearch metadata: name: elastic namespace: elastic-system spec: version: 7.4.0 nodeSets: - name: default count: 3 config: node.master: true node.data: true node.ingest: true node.store.allow_mmap: false volumeClaimTemplates: - metadata: name: elasticsearch-data spec: accessModes: - ReadWriteOnce resources: requests: storage: 5Gi storageClassName: rook-ceph-block EOF 注:采用默认官方的了,个人安装了rook ceph 就用了rook-ceph-block,由于是测试storage就设置为5G。另外如果指定运行node节点可以设置lable根据个人需求设置

kubectl get pods -n elastic-system -o wide kubectl -n elastic-system get pods --selector='elasticsearch.k8s.elastic.co/cluster-name=elastic'(官方文档的查看方式,看个人使用习惯了呢) kubectl get elasticsearch -n elastic-system kubectl get service -n elastic-system 获取elastic链接用户密码,默认用户为elastic kubectl -n elastic-system get secret elastic-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode; echo


安装kibana on cluaster
依然官方示例
cat <<EOF | kubectl apply -f - apiVersion: kibana.k8s.elastic.co/v1beta1 kind: Kibana metadata: name: kibana namespace: elastic-system spec: version: 7.4.0 count: 1 elasticsearchRef: name: elastic http: tls: selfSignedCertificate: disabled: true EOF 注意:属性spec.elasticsearchRef.name的值为上面我们创建的 Elasticsearch 对象的 name:elastic。直接添加这个资源对象即可,配置文件下方关于http的配置参照https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-kibana.html#k8s-kibana-http-configuration disable tls为了方便外部traefik负载。 kubectl get kibana -n elastic-system kubectl -n elastic-system get pod --selector='kibana.k8s.elastic.co/name=kibana' kuberctl get svc -n elastic-system
kibana traefik对外暴露
cat <<EOF > ingress.yaml apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: kibana-kb-http namespace: elastic-system spec: entryPoints: - websecure tls: secretName: all-sainaihe-com routes: - match: Host(`kibana123.saynaihe.com`) kind: Rule services: - name: kibana-kb-http port: 5601 EOF kubectl apply -f ingress.yaml kubectl get ingressroute -n elastic-system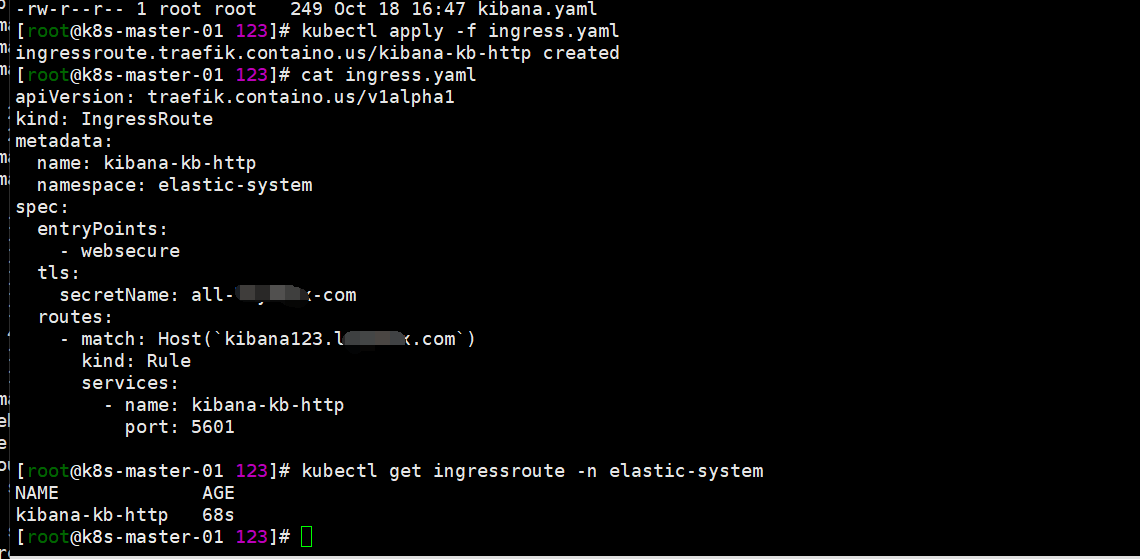
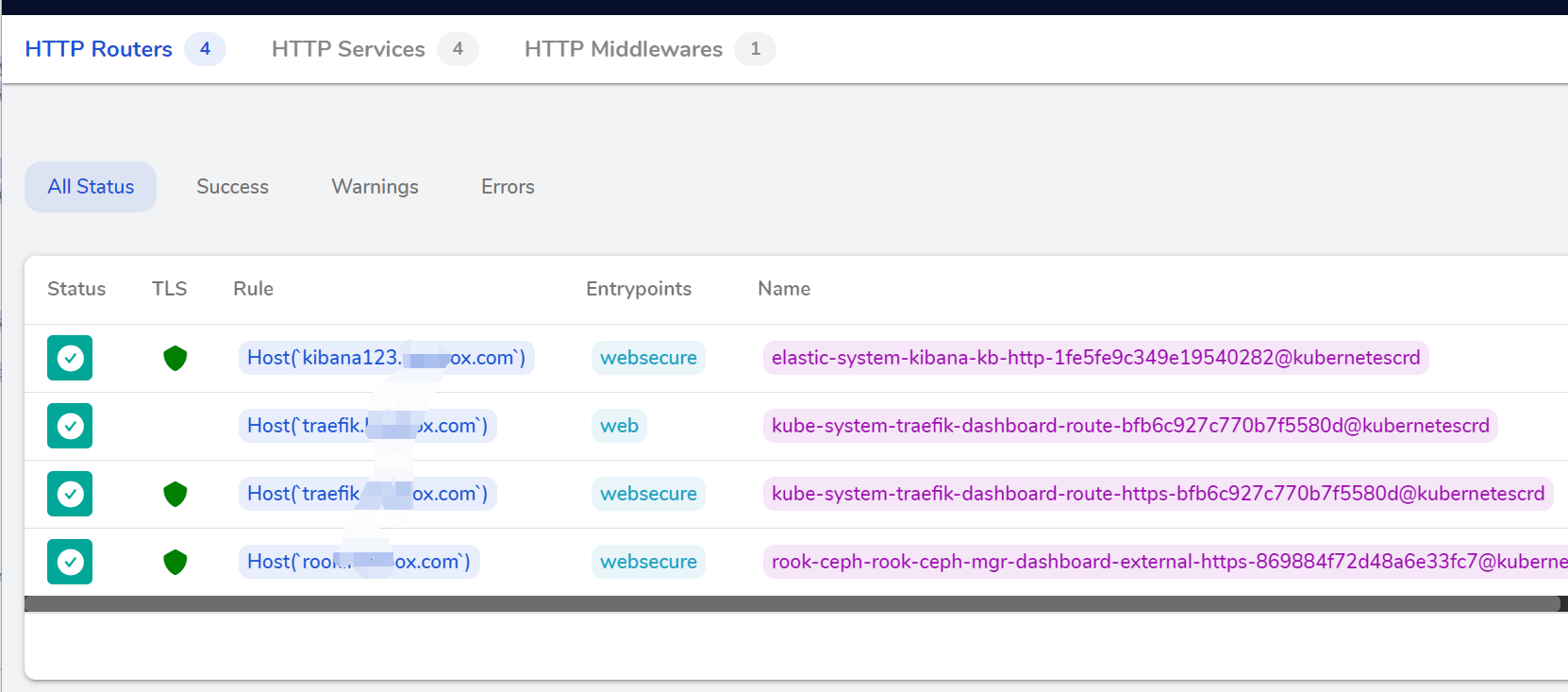
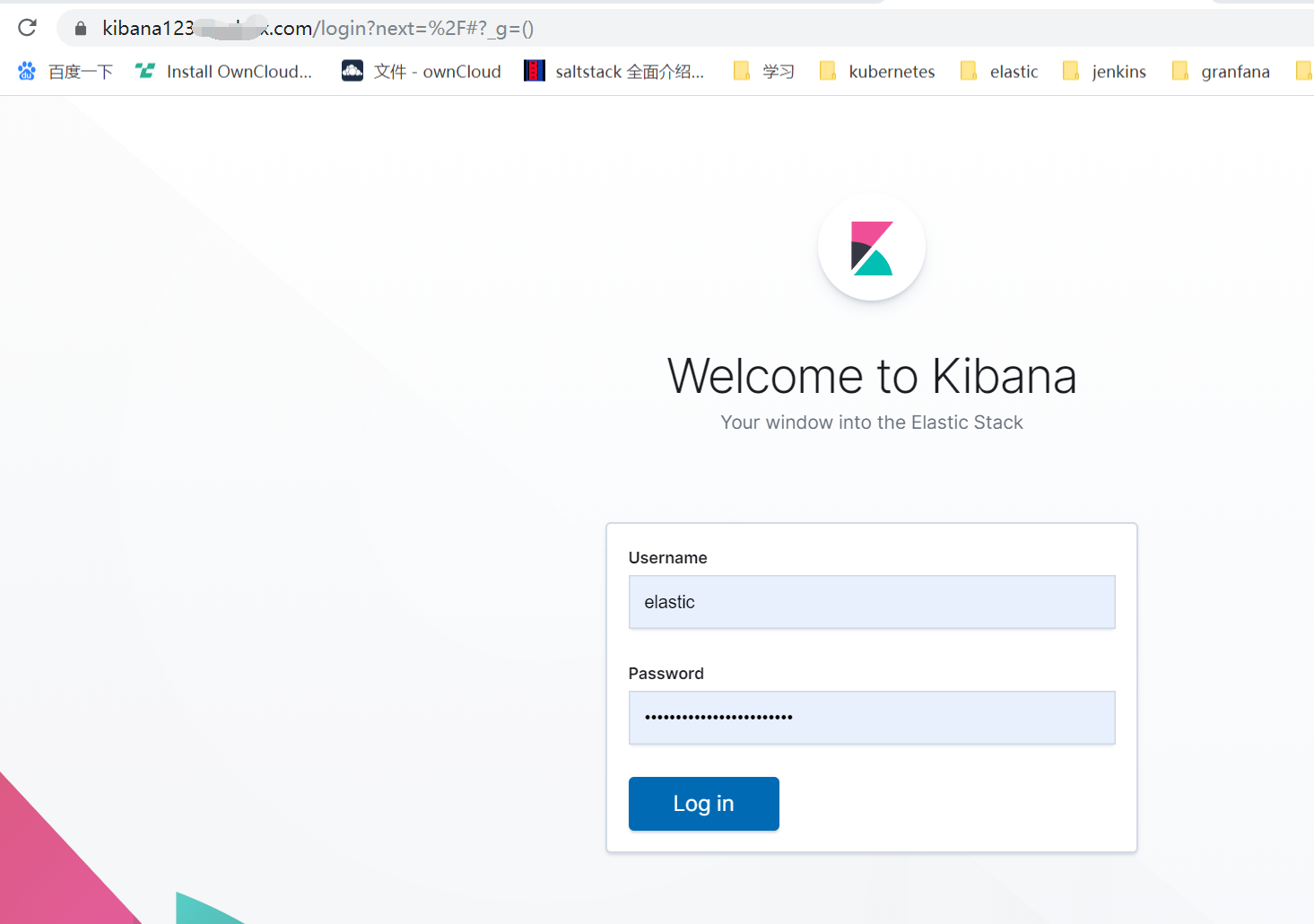
接下来fluent-bit 安装
kubernetes 采集日志比较常用的有很多比如elasitc自己的logstash filebeat , 还有fluent,另外fluent还有专门针对kubernetes的fluent-bit,各种优劣 可以找文档对比,最终我选择了fluent-bit.先按照https://github.com/fluent/fluent-bit-kubernetes-logging。 README.md修改下配置文件。
git clone https://github.com/fluent/fluent-bit-kubernetes-logging cd /fluent/fluent-bit-kubernetes-logging 注: 修改下配置文件将默认的namespace修改下与eck在同一命名空间下 修改后文件如下: ------ cat <<EOF > fluent-bit-service-account.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluent-bit namespace: elastic-system EOF ------ cat <<EOF > fluent-bit-role.yaml apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: fluent-bit-read namespace: elastic-system rules: - apiGroups: [""] resources: - namespaces - pods verbs: ["get", "list", "watch"] EOF ------ cat <<EOF > fluent-bit-role-binding.yaml apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: fluent-bit-read roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: fluent-bit-read subjects: - kind: ServiceAccount name: fluent-bit namespace: elastic-system EOF ------ kubectl apply -f fluent-bit-service-account.yaml kubectl apply -f fluent-bit-role.yaml kubectl apply -f fluent-bit-role-binding.yaml ------ cd output/elasticsearch/ cat <<EOF > fluent-bit-configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: fluent-bit-config namespace: elastic-system labels: k8s-app: fluent-bit data: # Configuration files: server, input, filters and output # ====================================================== fluent-bit.conf: | [SERVICE] Flush 1 Log_Level info Daemon off Parsers_File parsers.conf HTTP_Server On HTTP_Listen 0.0.0.0 HTTP_Port 2020 @INCLUDE input-kubernetes.conf @INCLUDE filter-kubernetes.conf @INCLUDE output-elasticsearch.conf input-kubernetes.conf: | [INPUT] Name tail Tag kube.* Path /var/log/containers/*.log Parser docker DB /var/log/flb_kube.db Mem_Buf_Limit 5MB Skip_Long_Lines On Refresh_Interval 10 filter-kubernetes.conf: | [FILTER] Name kubernetes Match kube.* Kube_URL https://kubernetes.default.svc:443 Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token Kube_Tag_Prefix kube.var.log.containers. Merge_Log On Merge_Log_Key log_processed K8S-Logging.Parser On K8S-Logging.Exclude Off output-elasticsearch.conf: | [OUTPUT] Name es Match * Host elastic-es-http Port 9200 HTTP_User elastic HTTP_Passwd ********* tls on tls.verify off Logstash_Format On Replace_Dots On Retry_Limit False parsers.conf: | [PARSER] Name apache Format regex Regex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$ Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name apache2 Format regex Regex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^ ]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$ Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name apache_error Format regex Regex ^\[[^ ]* (?<time>[^\]]*)\] \[(?<level>[^\]]*)\](?: \[pid (?<pid>[^\]]*)\])?( \[client (?<client>[^\]]*)\])? (?<message>.*)$ [PARSER] Name nginx Format regex Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$ Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name json Format json Time_Key time Time_Format %d/%b/%Y:%H:%M:%S %z [PARSER] Name docker Format json Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On [PARSER] Name syslog Format regex Regex ^\<(?<pri>[0-9]+)\>(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$ Time_Key time Time_Format %b %d %H:%M:%S EOF ------ 注:基本还是默认的就修改了namespace 还有output-elasticsearch.conf中 Host Port HTTP_User HTTP_Passwd tls tls.verify具体参考https://docs.fluentbit.io/manual/configuration 官方文档 ------ cat <<EOF > fluent-bit-ds.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: fluent-bit namespace: elastic-system labels: k8s-app: fluent-bit-logging version: v1 kubernetes.io/cluster-service: "true" spec: selector: matchLabels: k8s-app: fluent-bit-logging template: metadata: labels: k8s-app: fluent-bit-logging version: v1 kubernetes.io/cluster-service: "true" annotations: prometheus.io/scrape: "true" prometheus.io/port: "2020" prometheus.io/path: /api/v1/metrics/prometheus spec: containers: - name: fluent-bit image: fluent/fluent-bit:1.2.1 imagePullPolicy: Always ports: - containerPort: 2020 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elastic-es-http" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: fluent-bit-config mountPath: /fluent-bit/etc/ terminationGracePeriodSeconds: 10 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: fluent-bit-config configMap: name: fluent-bit-config serviceAccountName: fluent-bit tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule - operator: "Exists" effect: "NoExecute" - operator: "Exists" effect: "NoSchedule" EOF ------ 注: 修改了下apiversion 1.16取消了extensions/v1beta1 更改为apps/v1 配置文件增加 selector: 相关配置。FLUENT_ELASTICSEARCH_HOST FLUENT_ELASTICSEARCH_PORT 对应value输入 ------ kubectl apply -f fluent-bit-configmap.yaml kubectl apply -f fluent-bit-ds.yaml kubectl get pods -n elastic-system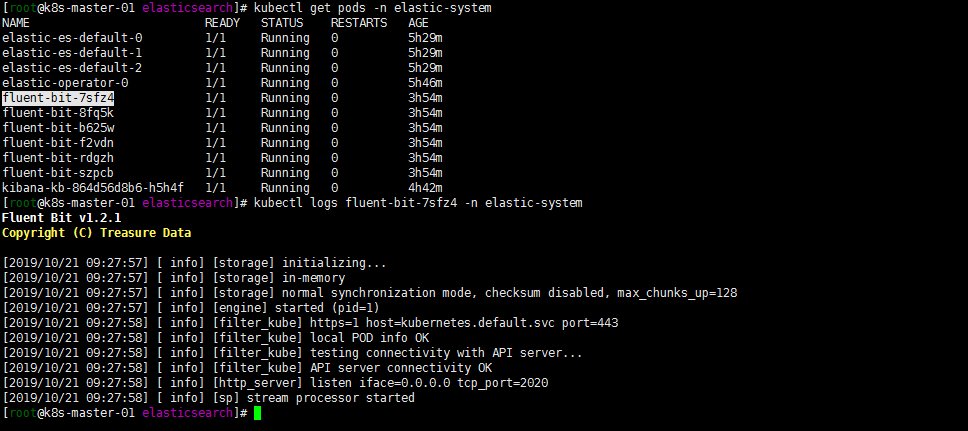
登录kibana 进行相关配置
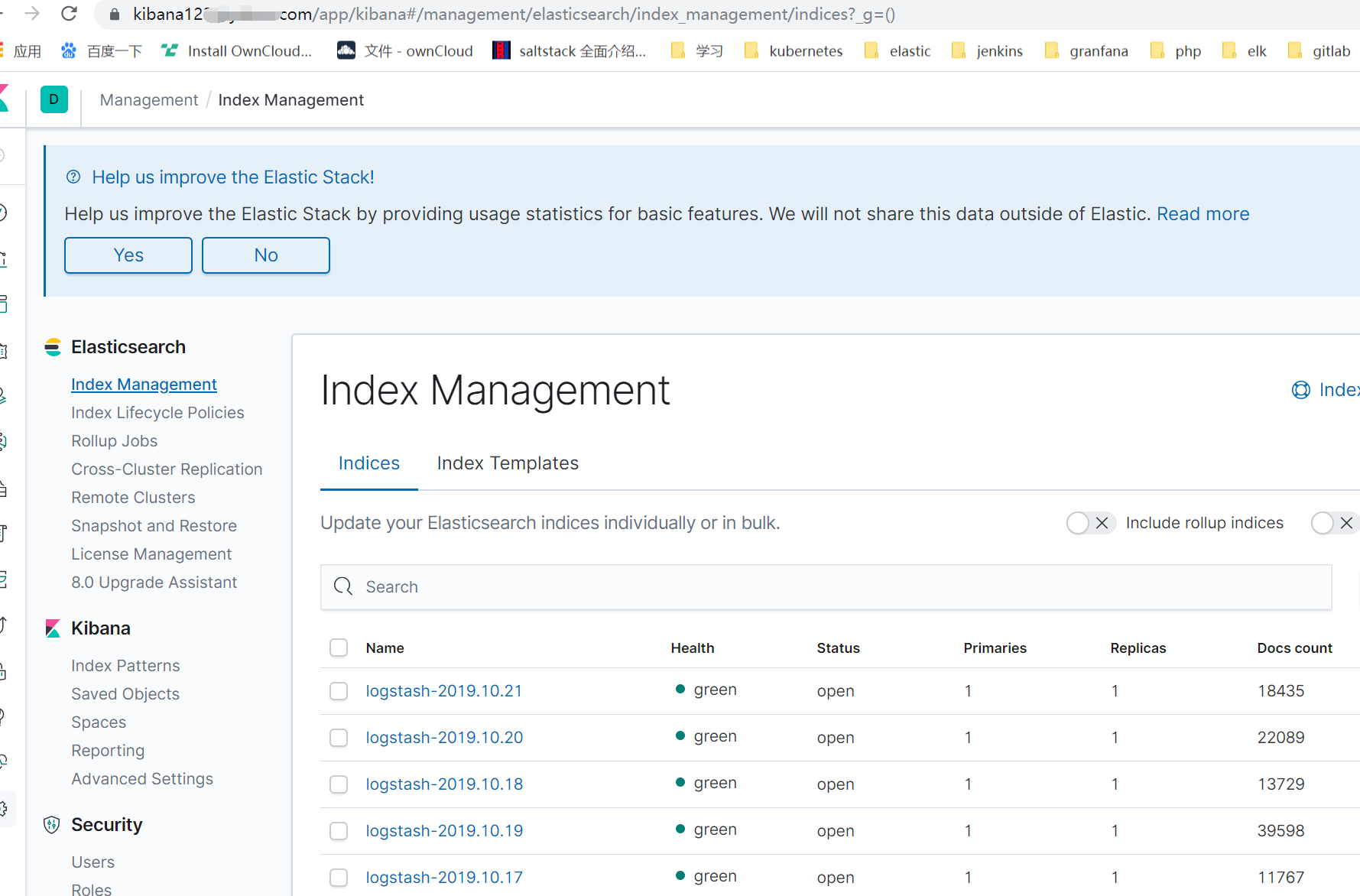
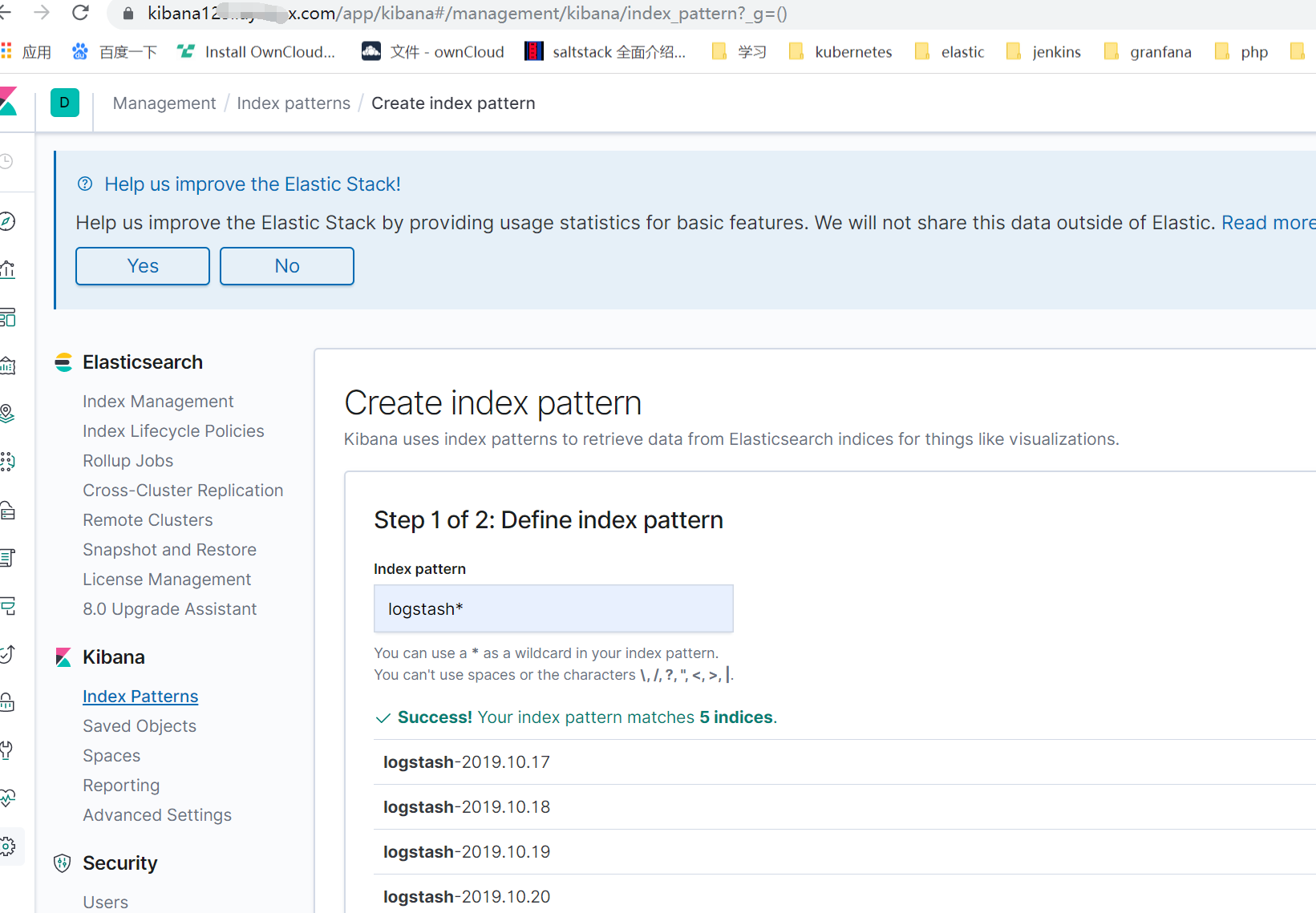
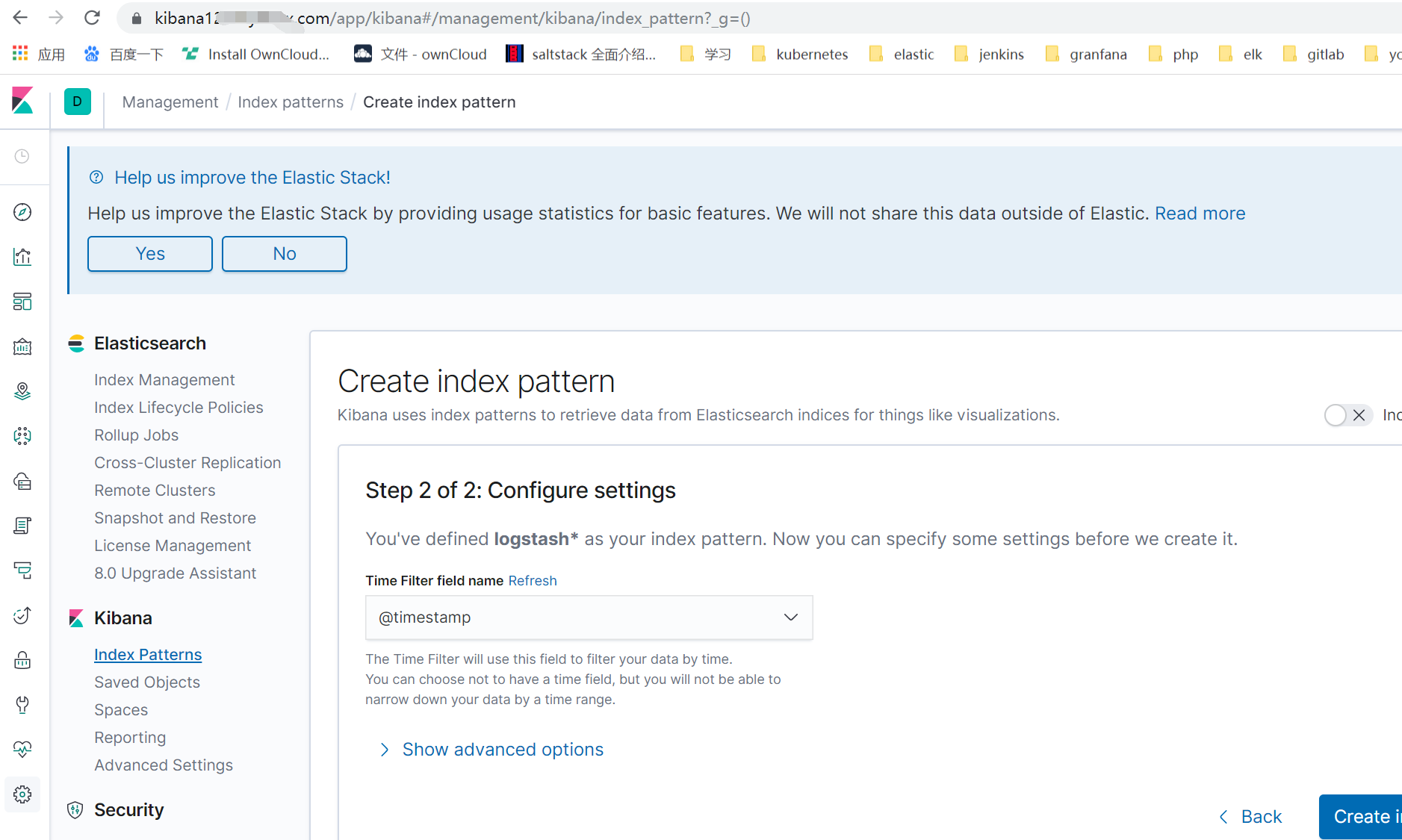
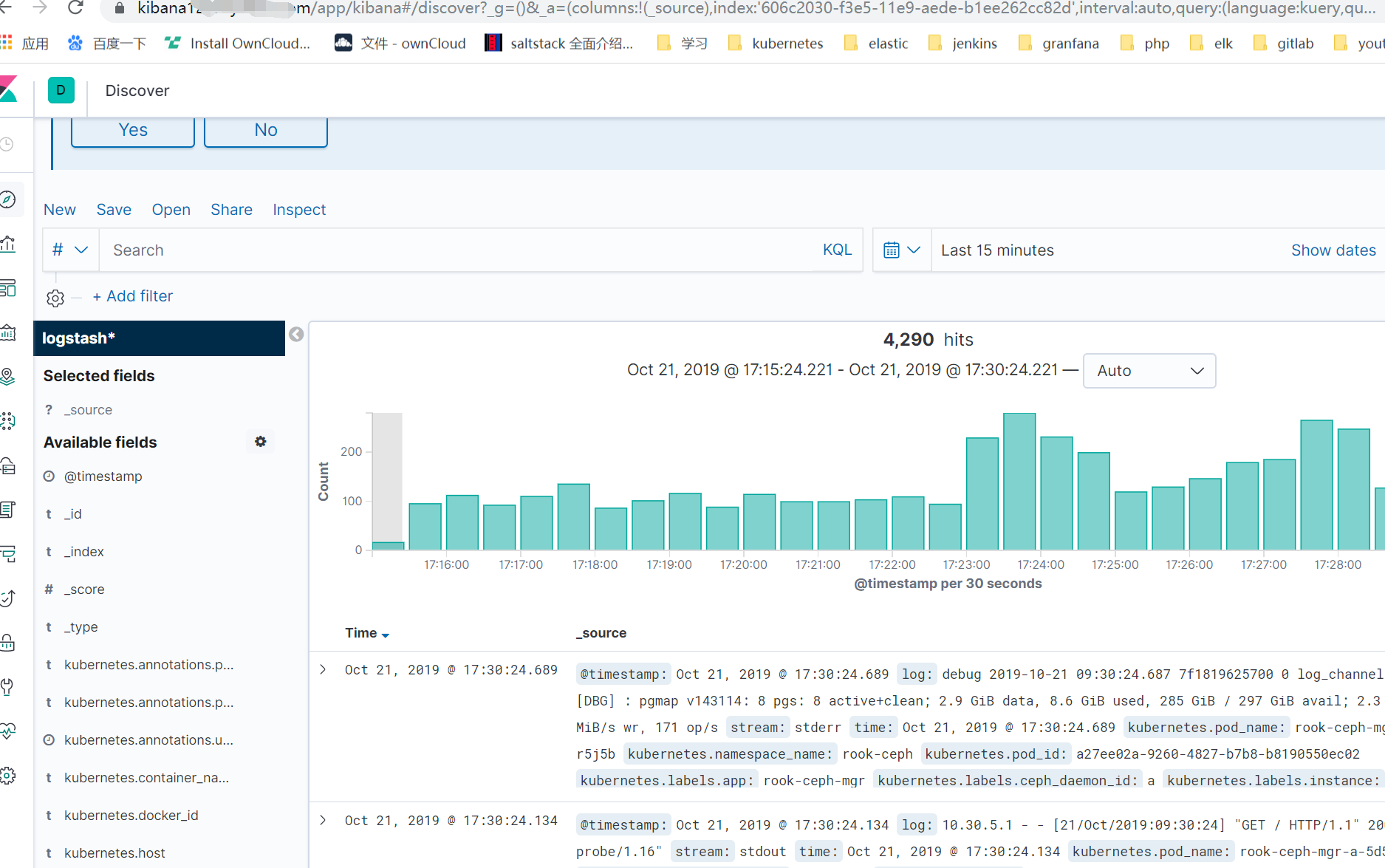
注:发现rook的日志单行了 后续将完善下各种日志的格式还有其他相关问题
-
traefik2 安装实现 http https
描述背景:
注: 文章配置文件示例都是拿阳明大佬的还有良哥转发的http://www.mydlq.club/article/41 超级小豆丁的文章中参考的。个人只是拿来整合测试了下整合,鸣谢各位大佬。
开始使用腾讯云tke,slb对外映射方式 还需要对外开启Nodeport 然后slb对端口映射,个人觉得比较反人类,然后看到阳明 良哥两位大佬都发了traefik的方式就试用了一下。
集群配置: 初始集群环境kubeadm 1.16.1 | ip | 自定义域名 | 主机名 | | :----: | :----: | :----: | |192.168.3.8 | master.k8s.io | k8s-vip | |192.168.3.10 | master01.k8s.io | k8s-master-01| |192.168.3.5 | master02.k8s.io | k8s-master-02| |192.168.3.12 | master03.k8s.io | k8s-master-03| |192.168.3.6 | node01.k8s.io | k8s-node-01| |192.168.3.2 | node02.k8s.io | k8s-node-02| |192.168.3.4 | node03.k8s.io | k8s-node-03| k8s-node-01 k8s-node-02 k8s-node-03 绑定了腾讯云负载均衡应用负载均衡并对外暴露了80 443两个端口,开始443想放在https监听器哪里,但是这样一个sbl负载均衡只能绑定一个证书的,业务不太多,不想用多个slb,就将443端口监听放在了tcp/udp监听器这里,然后证书在kubernetes集群中创建绑定在traefik上。关于Traefik
Traefik 2.0 官方文档:https://docs.traefik.io/v2.0/ 比较乱,中文的可参照阳明大佬的中文翻译https://www.qikqiak.com/traefik-book/
-
2019-09-23-k8s-1.15.3-update1.16.0
描述背景:
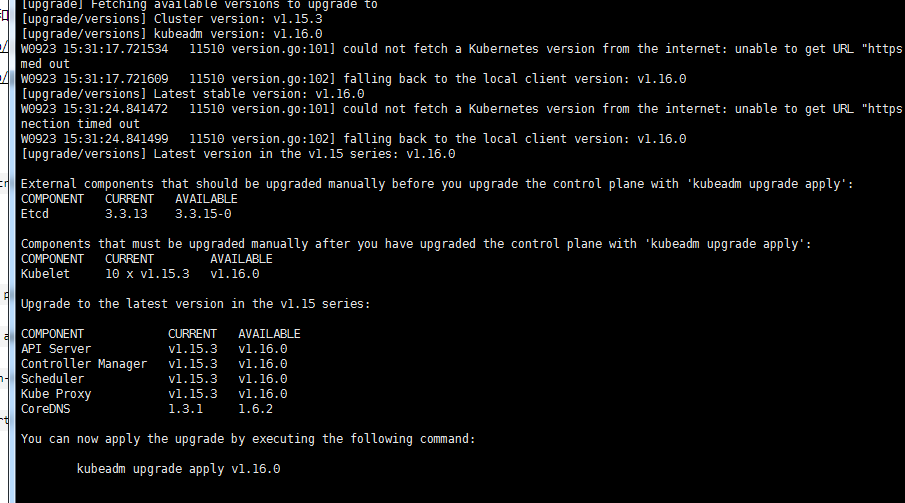
已经搭建完的k8s集群只有两个worker节点,现在增加work节点到集群。原有集群机器: | ip | 自定义域名 | 主机名 | | :----: | :----: | :----: | | | master.k8s.io | k8s-vip | |192.168.0.195 | master01.k8s.io | k8s-master-01| |192.168.0.197 | master02.k8s.io | k8s-master-02| |192.168.0.198 | master03.k8s.io | k8s-master-03| |192.168.0.199 | node01.k8s.io | k8s-node-01| |192.168.0.202 | node02.k8s.io | k8s-node-02| |192.168.0.108 | node03.k8s.io | k8s-node-03| |192.168.0.111 | node04.k8s.io | k8s-node-04| |192.168.0.115 | node05.k8s.io | k8s-node-05| 初始集群参照 https://duiniwukenaihe.github.io/2019/09/18/k8s-expanded/ 由于上周kubernetes1.15.3爆出漏洞,决定将集群升级为1.16.0 。#升级master节点
##k8s-master-01节点操作 yum list --showduplicates kubeadm --disableexcludes=kubernetes #查看yum源中可支持版本 yum install kubeadm-1.16.0 kubectl-1.16.0 --disableexcludes=kubernetes。我这里懒人方式直接yum update了 kubeadm version kubeadm upgrade plan --certificate-renewal=false # 如果不加-certificate-renewal=false将重新生成证书 kubeadm upgrade apply v1.16.0 systemctl daemon-reload systemctl restart kubelet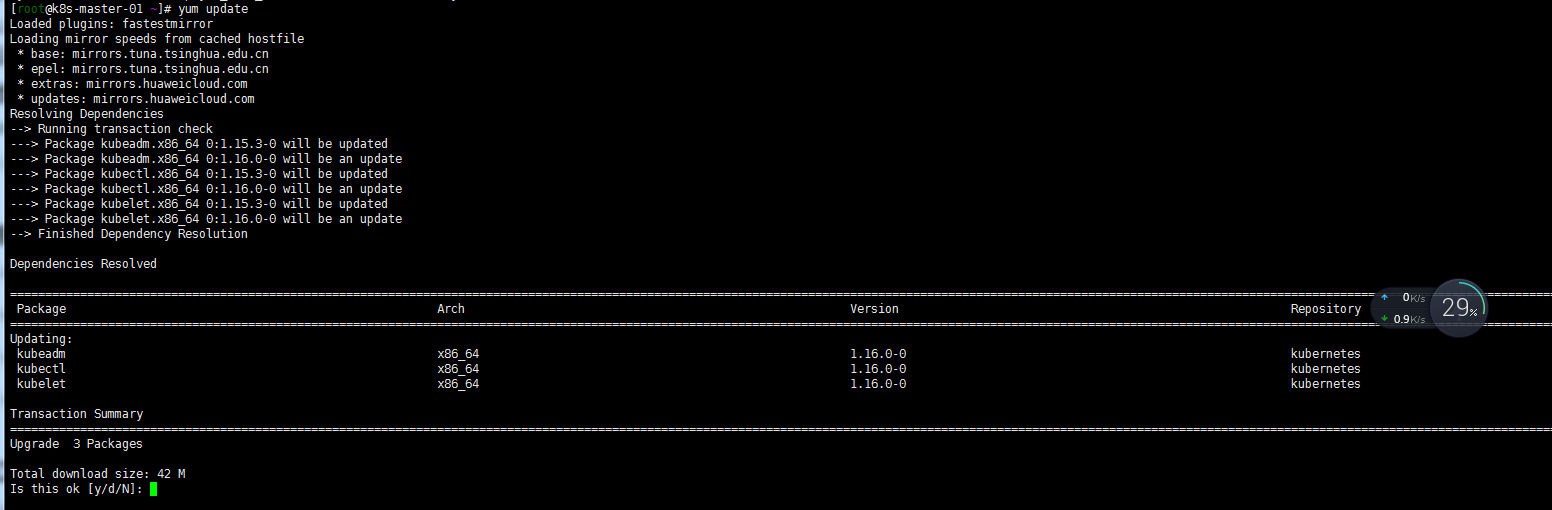
##发现 master节点一直not ready
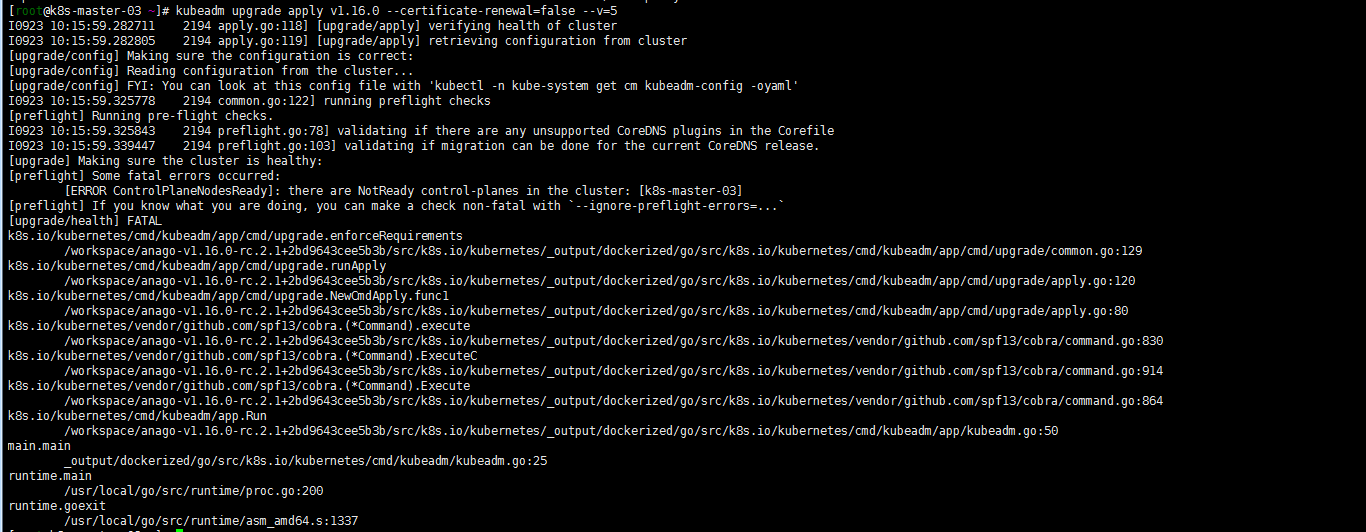
参照: https://github.com/coreos/flannel/pull/1181/commits/2be363419f0cf6a497235a457f6511df396685d4
cat <<EOF > /etc/cni/net.d/10-flannel.conflist { "name": "cbr0", "cniVersion": "0.2.0", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } EOF最好还是修改下kube-flannel.yml
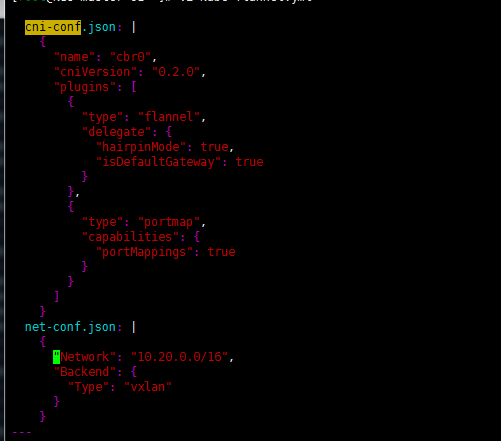
kubectl apply -f kube-flannel.yml
##依次升级其他master02 master03节点
yum install kubeadm-1.16.0 kubectl-1.16.0 --disableexcludes=kubernetes kubeadm upgrade apply v1.16.0 systemctl daemon-reload systemctl restart kubelet##worker nodes 节点升级
#在master01节点依次将worker节点设置为不可调用 kubectl drain $node --ignore-daemonsets yum install kubeadm-1.16.0 kubectl-1.16.0 --disableexcludes=kubernetes systemctl daemon-reload systemctl restart kubelet systemctl status kubelet kubectl uncordon $nodework节点以此升级
##查看集群## kubectl get nodes
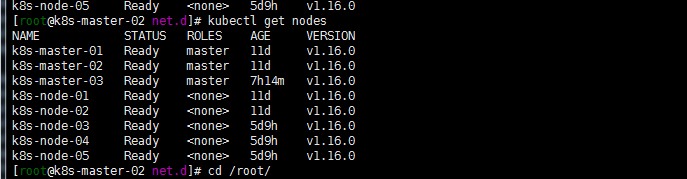
注:碰到的问题 早前yaml文件apiVersion用的是extensions/v1beta1 ,1,16要修改为apps/v1beta1。具体看https://kubernetes.io/zh/docs/concepts/workloads/controllers/deployment/
-
elasticsearch常用查询
描述背景:
公司内部做了一套elasticsearch集群,开始主要是用来收集前端客户端报错。然后用 elastalert进行微信报警,后来由于mysql数据库写的比较烂无法查询用户信息统计,客户端埋点数据也收集了一份用做数据分析。
先看下索引的mapping吧,开始早先用的是5版本的有多个type,后来升级为6就保留了1个type。7版本貌似type取消了。索引格式为 项目名_渠道_年月份
GET *_wx_201909/_mapping
具体的就不贴了。简单说下mapping:
- 2022-08-09-Operator3-设计一个operator二-owns的使用
- 2022-07-11-Operator-2从pod开始简单operator
- 2021-07-20-Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)
- 2021-07-19-Kubernetes 1.18.20升级到1.19.12
- 2021-07-17-Kubernetes 1.17.17升级到1.18.20
- 2021-07-16-TKE1.20.6搭建elasticsearch on kubernetes
- 2021-07-15-Kubernets traefik代理ws wss应用
- 2021-07-09-TKE1.20.6初探
- 2021-07-08-关于centos8+kubeadm1.20.5+cilium+hubble的安装过程中cilium的配置问题--特别强调
- 2021-07-02-腾讯云TKE1.18初体验