Welcome to duiniwukenaihe's Blog!
这里记录着我的运维学习之路-
2021-06-29-Kubernetes集群添加运行containerd runtime的 work节点
- 背景:
- work节点基本信息:
- 1. work节点初始化:
- 2. master节点生成token与token-ca-cert-hash(任一控制平面节点)
- 3. 将work节点加入集群
- 4. master节点验证sh02-node-01节点加入
- 5. 接下来的:
- 后记:
背景:
kuberadm搭建的1.15的初始集群,参见:2020-07-22-腾讯云-slb-kubeadm高可用集群搭建
,嗯后面进行了持续的升级:2019-09-23-k8s-1.15.3-update1.16.0,1.16版本最后持续小版本升级到了1.16.15(小版本升级唯写升级过程)。最后升级版本到了1.17.17:Kubernetes 1.16.15升级到1.17.17。计划后面还是会持续升级到最新的1.21的。只不过最近线上有项目在测试。升级部分先暂停,近期准备先扩容一下集群。由于搭建1.20.5集群测试的时候使用了containerd跑了下也还好。就想添加一个containerd的 work节点了。后面有时间逐步替换环境内的模块。当然了节点替换主要是早期的work节点都采用了8核心16G内存的腾讯云cvm。开始的时候资源还是能满足的,到了现在了pod的资源经过压测和各种测试都逐步调高了资源的request 和 limit。相应的,资源的调度优化方面节点就有些超卖oom的问题了,就准备添加下16核心32G内存的cvm节点!当然了master节点和其他work节点的docker runtime节点还没有进行替换!
work节点基本信息:
系统 ip 内核 centos8.2 10.0.4.48 4.18 1. work节点初始化:
基本参照:centos8+kubeadm1.20.5+cilium+hubble环境搭建完成系统的初始化。
1. 更改主机名:
hostnamectl set-hostname sh02-node-01先说一下自己的集群和命名:各种环境位于腾讯云上海区。线上kubernetes环境位于私网下上海3区,命名规则是k8s-node-0x。这次的10.0.4.48位于上海2区。区分下区域命名吧….就sh02-node-0x命名吧。以后不同区域的就直接sh0x去区分吧。还是有必要区分下区域的(过去太集中与上海3区了,现在也必要打乱下区域,增加一些容灾的可能性….但是腾讯云的网络貌似没有什么用,之前出问题也基本都出问题了…以后如果能业务量上来还是搞一下啊多地域或者多云的环境)。
2. 关闭swap交换分区
swapoff -a sed -i 's/.*swap.*/#&/' /etc/fstab3. 关闭selinux
setenforce 0 sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config4. 关闭防火墙
systemctl disable --now firewalld chkconfig firewalld off5. 调整文件打开数等配置
cat> /etc/security/limits.conf <<EOF * soft nproc 1000000 * hard nproc 1000000 * soft nofile 1000000 * hard nofile 1000000 * soft memlock unlimited * hard memlock unlimited EOF6. yum update
yum update yum -y install gcc bc gcc-c++ ncurses ncurses-devel cmake elfutils-libelf-devel openssl-devel flex* bison* autoconf automake zlib* fiex* libxml* ncurses-devel libmcrypt* libtool-ltdl-devel* make cmake pcre pcre-devel openssl openssl-devel jemalloc-devel tlc libtool vim unzip wget lrzsz bash-comp* ipvsadm ipset jq sysstat conntrack libseccomp conntrack-tools socat curl wget git conntrack-tools psmisc nfs-utils tree bash-completion conntrack libseccomp net-tools crontabs sysstat iftop nload strace bind-utils tcpdump htop telnet lsof7. ipvs添加(centos8内核默认4.18.内核4.19不包括4.19的是用这个)
:> /etc/modules-load.d/ipvs.conf module=( ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh br_netfilter ) for kernel_module in ${module[@]};do /sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || : done内核大于等于4.19的
:> /etc/modules-load.d/ipvs.conf module=( ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack br_netfilter ) for kernel_module in ${module[@]};do /sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || : done加载ipvs模块
systemctl daemon-reload systemctl enable --now systemd-modules-load.service查询ipvs是否加载
# lsmod | grep ip_vs ip_vs_sh 16384 0 ip_vs_wrr 16384 0 ip_vs_rr 16384 0 ip_vs 172032 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack 172032 6 xt_conntrack,nf_nat,xt_state,ipt_MASQUERADE,xt_CT,ip_vs nf_defrag_ipv6 20480 4 nf_conntrack,xt_socket,xt_TPROXY,ip_vs libcrc32c 16384 3 nf_conntrack,nf_nat,ip_vs8. 优化系统参数(不一定是最优,各取所需)
注:嗯 特别强调最好把ipv6关闭了…反正我后面是吃了这个亏了。
cat <<EOF > /etc/sysctl.d/k8s.conf net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1 net.ipv4.neigh.default.gc_stale_time = 120 net.ipv4.conf.all.rp_filter = 0 net.ipv4.conf.default.rp_filter = 0 net.ipv4.conf.default.arp_announce = 2 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.all.arp_announce = 2 net.ipv4.ip_forward = 1 net.ipv4.tcp_max_tw_buckets = 5000 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_max_syn_backlog = 1024 net.ipv4.tcp_synack_retries = 2 # 要求iptables不对bridge的数据进行处理 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-arptables = 1 net.netfilter.nf_conntrack_max = 2310720 fs.inotify.max_user_watches=89100 fs.may_detach_mounts = 1 fs.file-max = 52706963 fs.nr_open = 52706963 vm.overcommit_memory=1 vm.panic_on_oom=0 vm.swappiness = 0 EOF sysctl --system9. containerd安装
dnf install dnf-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum update -y && sudo yum install -y containerd.io containerd config default > /etc/containerd/config.toml # 替换 containerd 默认的 sand_box 镜像,并将SystemdCgroup设置为true。编辑 /etc/containerd/config.toml sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true # 重启containerd $ systemctl daemon-reload $ systemctl restart containerd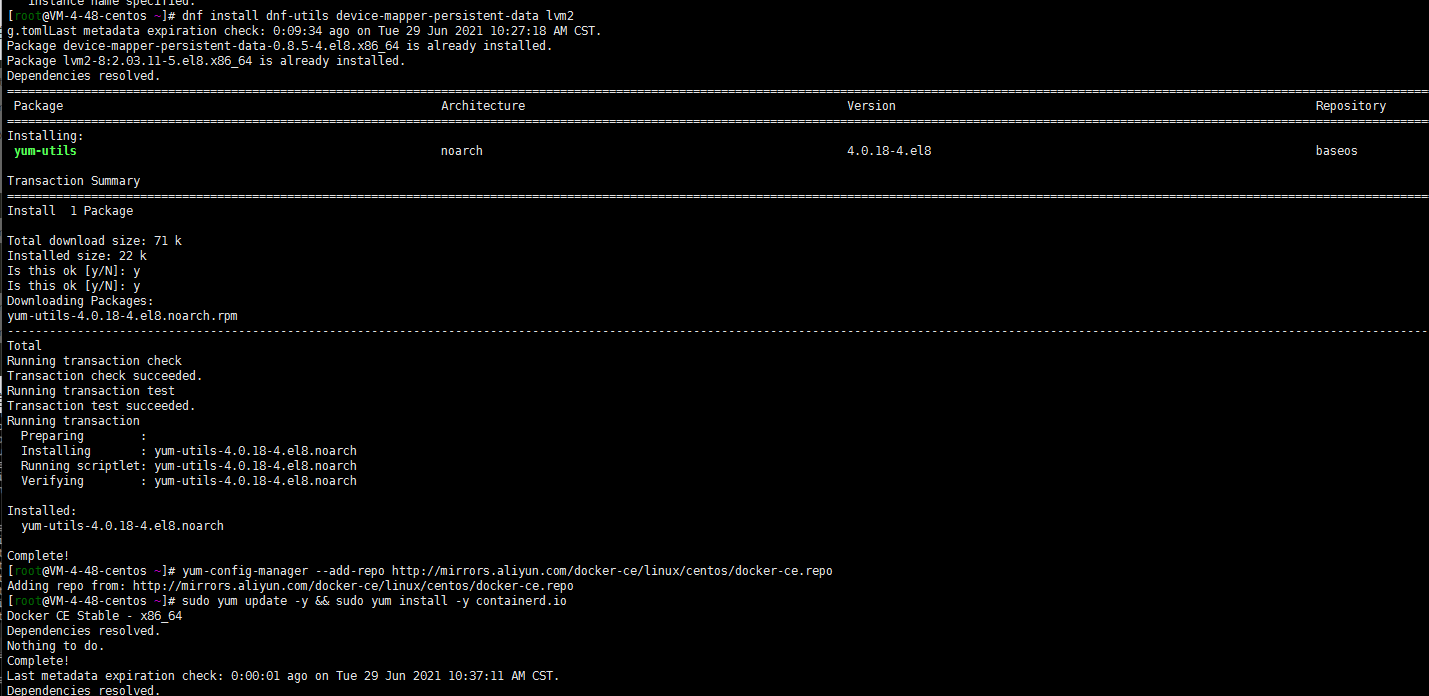
10. 配置 CRI 客户端 crictl
cat <<EOF > /etc/crictl.yaml runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 debug: false EOF
11. 安装 Kubeadm(centos8没有对应yum源使用centos7的阿里云yum源)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF # 删除旧版本,如果安装了 yum remove kubeadm kubectl kubelet kubernetes-cni cri-tools socat # 查看所有可安装版本 下面两个都可以啊 # yum list --showduplicates kubeadm --disableexcludes=kubernetes # 安装指定版本用下面的命令 # yum -y install kubeadm-1.17.17 kubectl-1.17.17 kubelet-1.17.17 # 开机自启 systemctl enable kubelet.service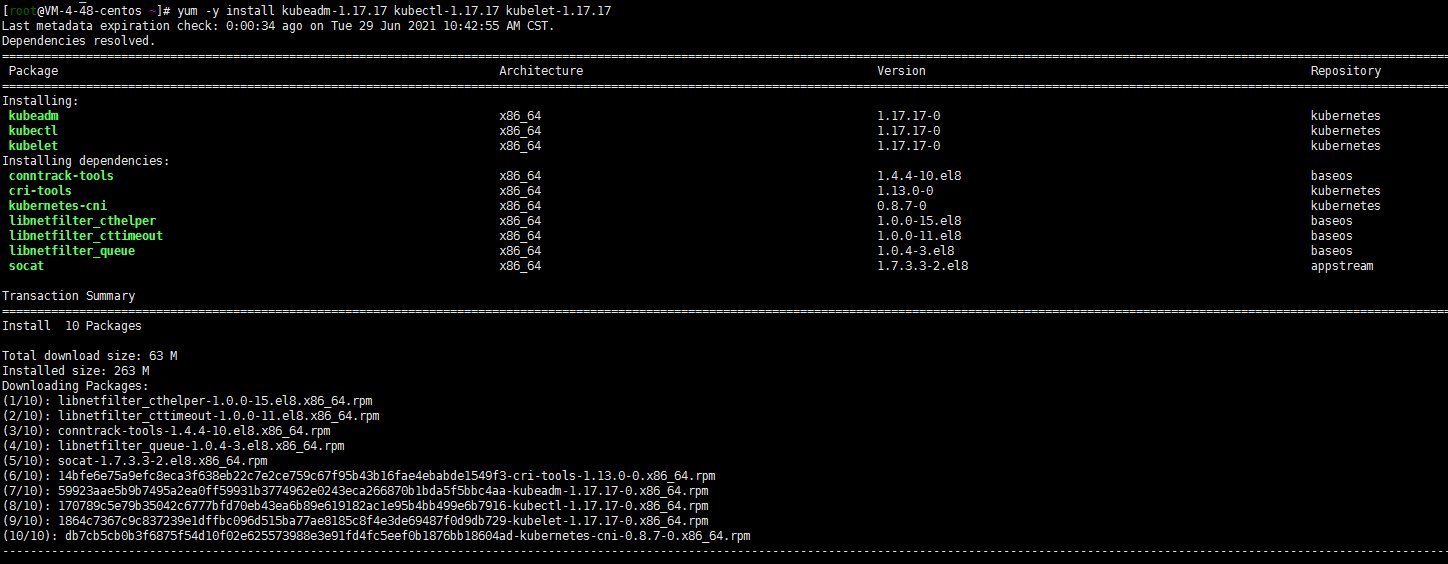
12. 修改kubelet配置
vi /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS= --cgroup-driver=systemd --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock13 . journal 日志相关避免日志重复搜集,浪费系统资源(根据个人需求设置)
sed -ri 's/^\$ModLoad imjournal/#&/' /etc/rsyslog.conf sed -ri 's/^\$IMJournalStateFile/#&/' /etc/rsyslog.conf sed -ri 's/^#(DefaultLimitCORE)=/\1=100000/' /etc/systemd/system.conf sed -ri 's/^#(DefaultLimitNOFILE)=/\1=100000/' /etc/systemd/system.conf sed -ri 's/^#(UseDNS )yes/\1no/' /etc/ssh/sshd_config journalctl --vacuum-size=200M2. master节点生成token与token-ca-cert-hash(任一控制平面节点)
[root@k8s-master-01 ~]# kubeadm token create W0629 13:59:57.505803 16857 validation.go:28] Cannot validate kube-proxy config - no validator is available W0629 13:59:57.505843 16857 validation.go:28] Cannot validate kubelet config - no validator is available 8nyjtd.xeza5fz4yitj62sx [root@k8s-master-01 ~]# kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS 8nyjtd.xeza5fz4yitj62sx 23h 2021-06-30T13:59:57+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token [root@k8s-master-01 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' 56ccafb865957c0692f5737cd8778553910c1049ef238a7781b7a39f5fd3a99a3. 将work节点加入集群
kubeadm join 10.0.0.37:6443 --token 8nyjtd.xeza5fz4yitj62sx --discovery-token-ca-cert-hash sha256:56ccafb865957c0692f5737cd8778553910c1049ef238a7781b7a39f5fd3a99a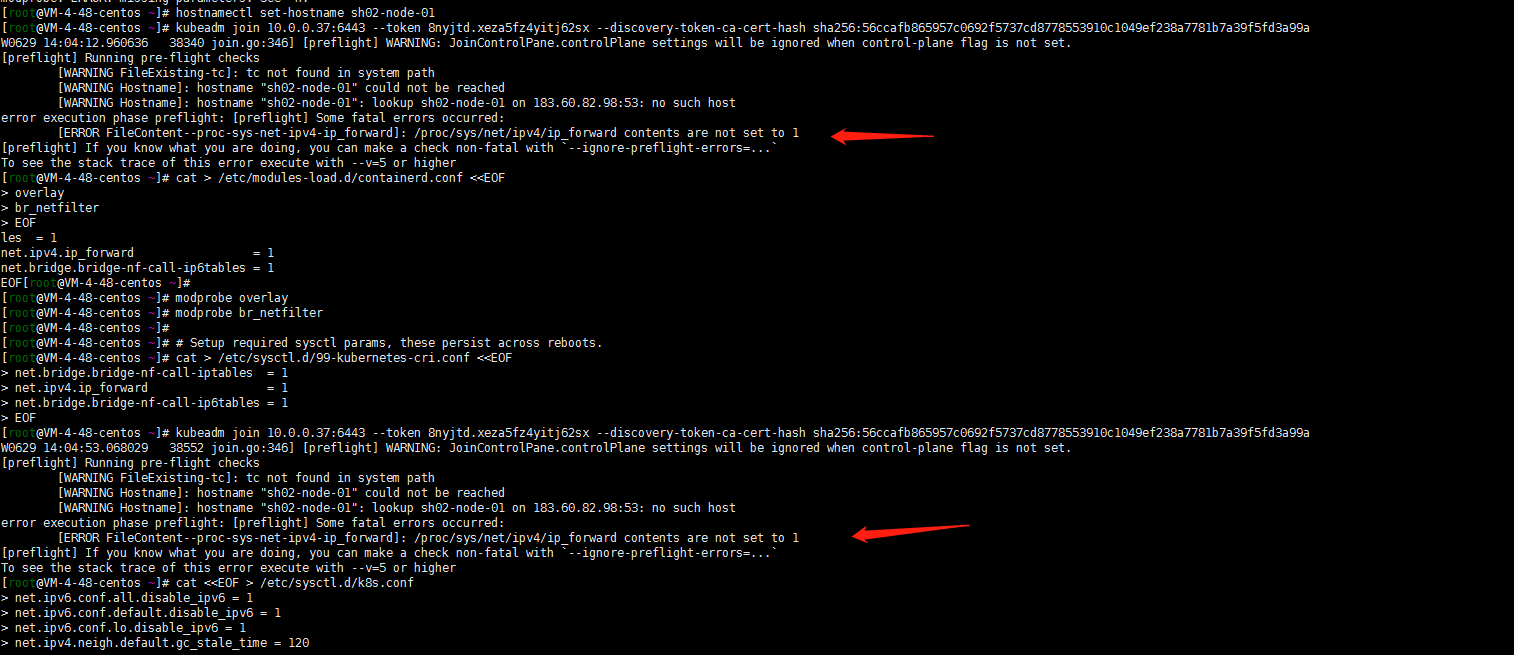
特意强调一下ipv4转发开启!当然了还有屏蔽了ipv6(当然了我这里没有先更改主机名和优化系统参数。执行了前面的步骤不会出这样的问题的!)
最终work节点如下:
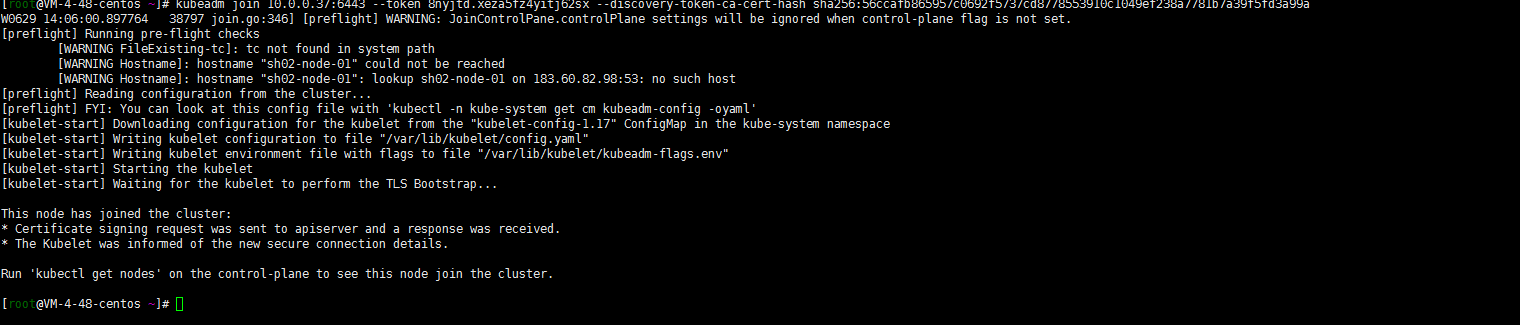
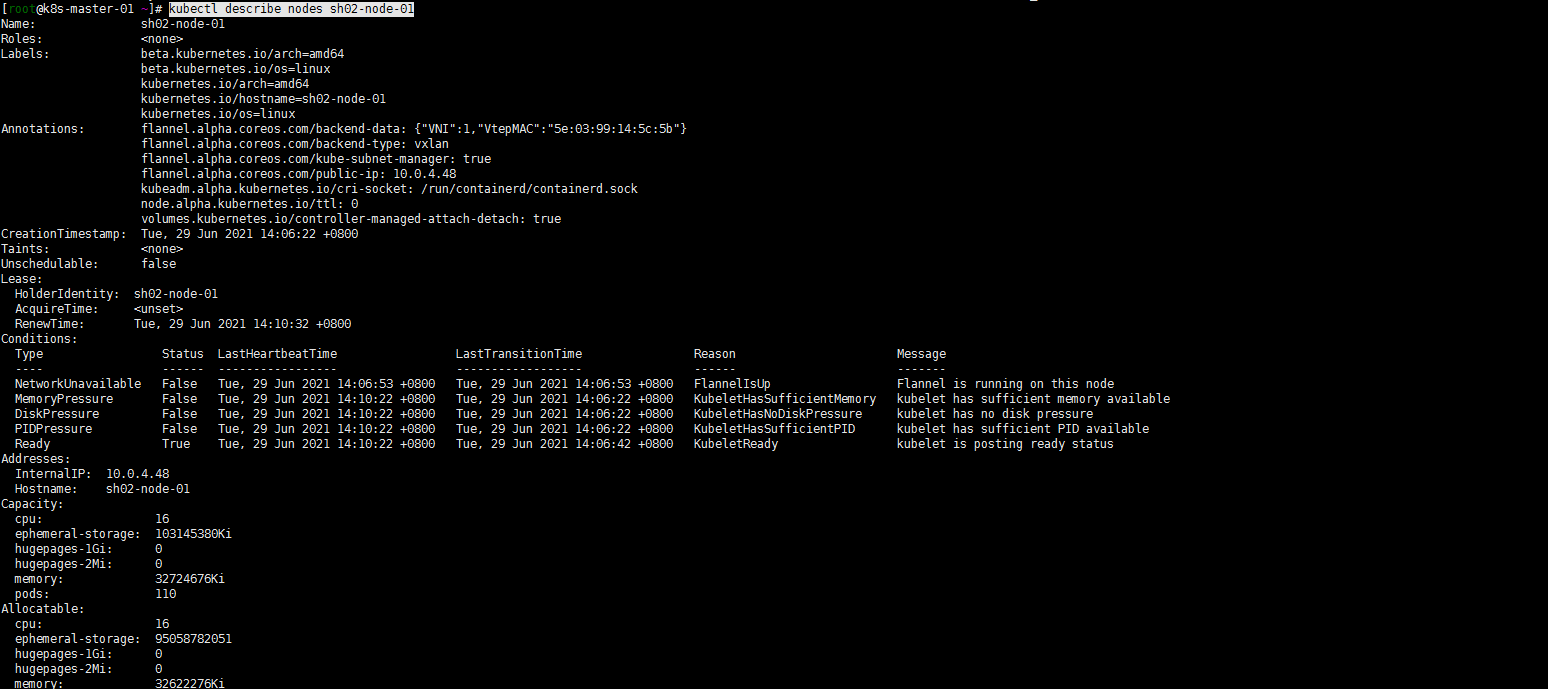
4. master节点验证sh02-node-01节点加入
kubectl get nodes -o wide kubectl describe nodes sh02-node-01
5. 接下来的:
1. 将tm-node-002节点踢出集群
我的tm-node-002节点是临时加的4核心8g内存,嗯先把他设置为不可调度然后把他踢出集群
[root@k8s-master-01 ~]# kubectl cordon tm-node-002 node/tm-node-002 cordoned
test-ubuntu-01忽略只是为了让开发能直接连kubernetes集群网络的
然后查看tm-node-002节点的pod分布:
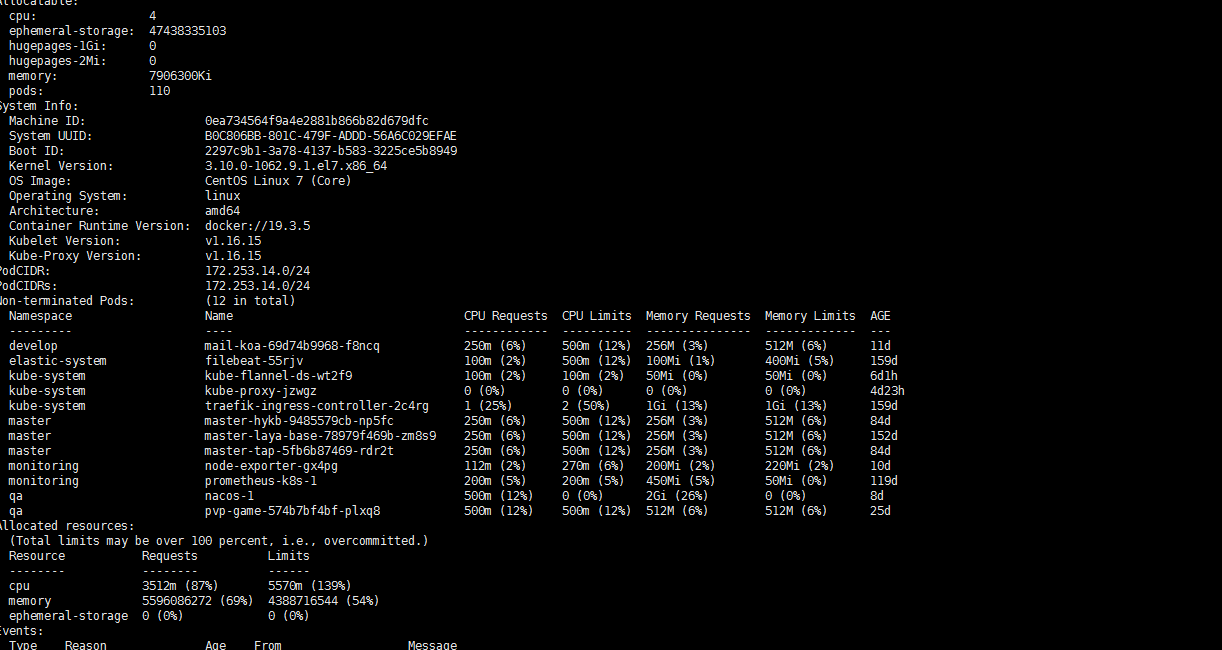
kubectl describe node sh02-node-01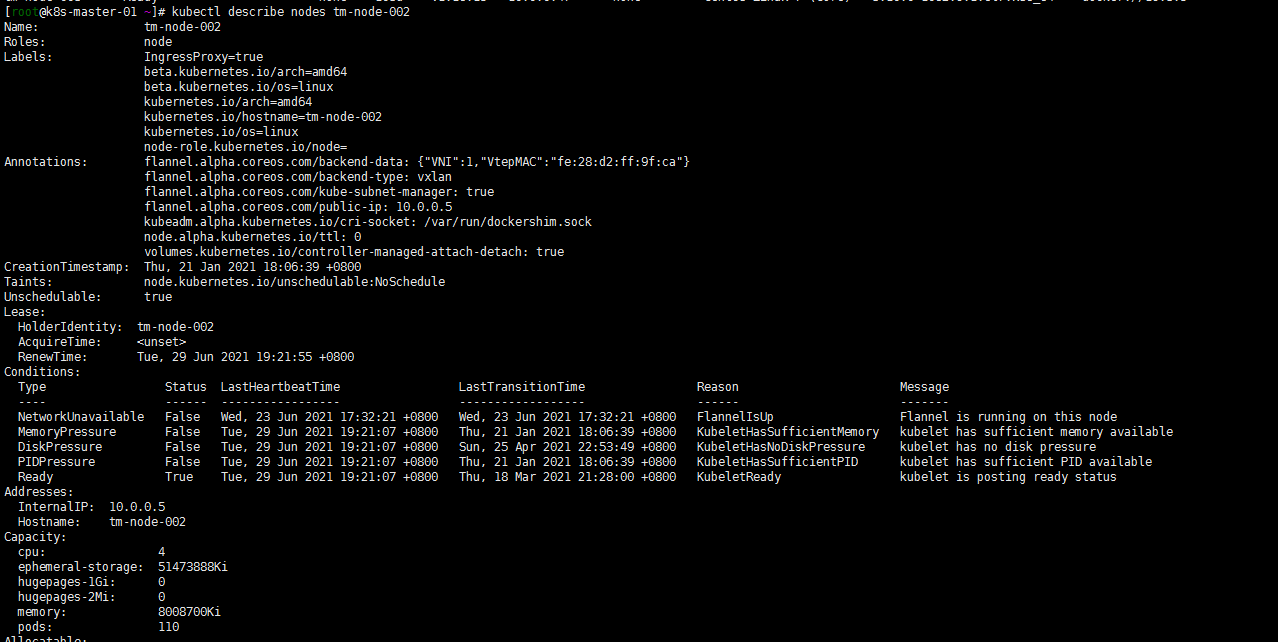
2. 重新调度一个pod
1. 重新调度一个pod(nacos-1 pod)
就讲nacos pod杀掉重新调度下吧(其他节点资源都分配较多了,调度策略怎么样也会分配到我新加入的sh02-node-01节点吧?)
[root@k8s-master-01 ~]# kubectl delete pods nacos-1 -n qa pod "nacos-1" deleted [root@k8s-master-01 ~]# kubectl get pods -n qa -o wide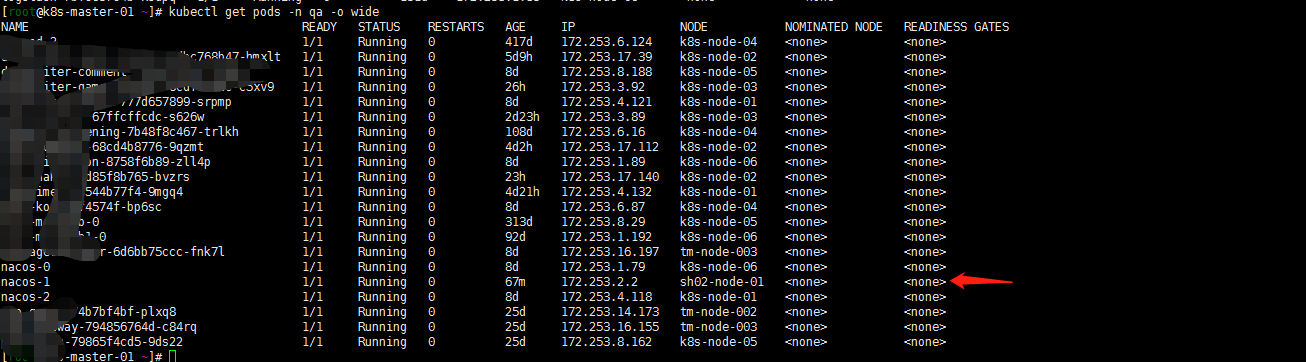
2. nfs-client的遗忘
看到 nacos-1调度到了sh02-node-01节点。但是开始并没有能running。怎么回事呢? 我的storageclass用的是nfs。sh02-node-01并没有能安装nfs客户端,故未能调度挂载pvc:
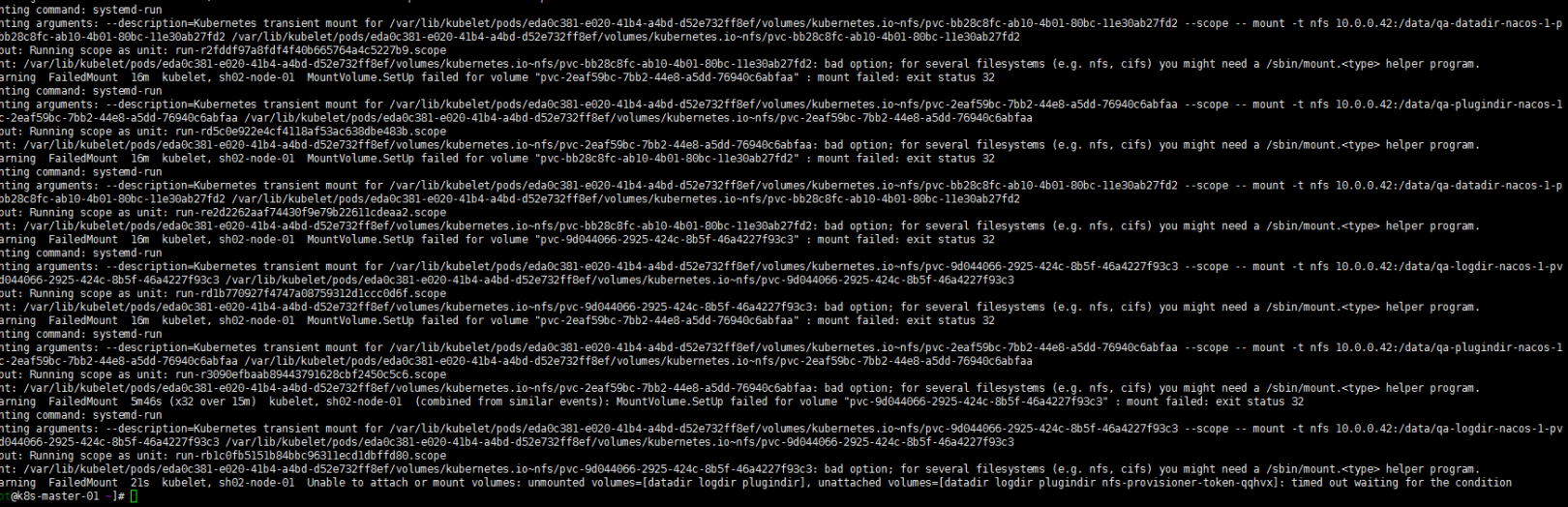
[root@sh02-node-01 ~] yum install nfs-* [root@sh02-node-01 ~] systemctl restart kubelet注:反正我重启了一下kubelet。因为开始安装上nfs-client插件还是不管用,重启了kubelet就好了。
3. iptables的问题
kubectl logs -f nacos-01 -n qa但是紧接着看了一眼nacos-1日志还是有报错。仔细看了眼怀疑iptables问题….嗯sh02-node-1开启了iptables
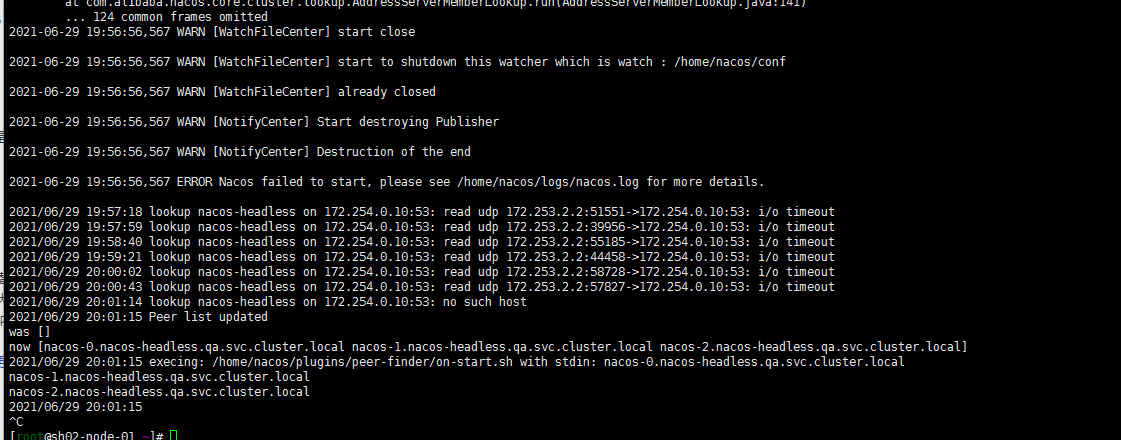
systemctl stop iptables chkconfig iptables off后记:
1. 验证一下docker 与containerd同时使用
2. 熟悉使用下ctr命令
3.还要持续升级,争取到1.21版本
4. storageclass看看有时间整成腾讯云的cbs(在其他环境中已验证过)
5. elasticsearch的存储我怎么能快速迁移呢?还是使用cos备份吗?没有想好
6. 当然了最终还是要containerd替换docker的
-
2021-06-29-Kubernetes中域名解析的异常问题分析
背景:
自建kubernetes1.16集群,服务应用早期多为php应用。docker封装nginx+php-fpm基础镜像,将代码打包成image jenkins进行ci/cd构建。 php应用中出现大佬域名解析失败的报错…..what?开始怀疑过kubernets版本问题,也怀疑过网络组件。但是未能找到原因。今天正好百度搜索资料时候偶然看到:https://www.it1352.com/589254.html,看到他上面解决的curl调取花费时间过长的时候curl指定了CURL_IPRESOLVE_V4。就顺便想了下…是了。我的集群没有禁用ipv6!划重点了:
如果开启了IPv6,curl默认会优先解析 IPv6,在对应域名没有 IPv6 的情况下,会等待 IPv6 dns解析失败 timeout 之后才按以前的正常流程去找 IPv4
关于解决方案:
自己简单想一想也有两种解决方式:
- work节点禁用ipv6
2 php代码指定CURL_IPRESOLVE_V4
入手解决:
1.关于work节点禁用ipv6
参照:https://blog.csdn.net/wh211212/article/details/80996364 我是直接sysctl设置禁用IPv6的方式了,不想重启集群节点!
在/etc/sysctl.conf中添加以下行 net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 # 或者执行 sed -i '$ a\net.ipv6.conf.all.disable_ipv6 = 1\nnet.ipv6.conf.default.disable_ipv6 = 1' /etc/sysctl.conf 要使设置生效,请执行 sysctl -p2. 关于php代码的修改
参照:https://www.jb51.net/article/39788.htm,直接扔给php小伙伴了….毕竟我也不会php。
其他可以参考的:
1. k8s – coredns禁用ipv6解析
2. 容器中使用nscd缓存优化 DNS 解析
-
2021-06-28-Kubernetes 1.16.15升级到1.17.17
背景:
线上kubernetes环境使用kubeadm搭建.当时应该是1.15的kubeadm搭建的。稳定运行了近两年的时间。其中升级了一次大版本从1.15升级到1.16。进行过多次小版本升级。现在的版本为1.16.15。中间也曾想升级过版本到更高的版本,但是升级master的时候出现异常了,还好是三节点的master集群,就恢复到了1.16的版本。一直没有进行更高版本的升级。昨天总算是对集群下手升级了……
集群配置
主机名 系统 ip k8s-vip slb 10.0.0.37 k8s-master-01 centos7 10.0.0.41 k8s-master-02 centos7 10.0.0.34 k8s-master-03 centos7 10.0.0.26 k8s-node-01 centos7 10.0.0.36 k8s-node-02 centos7 10.0.0.83 k8s-node-03 centos7 10.0.0.40 k8s-node-04 centos7 10.0.0.49 k8s-node-05 centos7 10.0.0.45 k8s-node-06 centos7 10.0.0.18 Kubernetes升级过程
1. 参考官方文档
参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
https://v1-17.docs.kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
kubeadm 创建的 Kubernetes 集群从 1.16.x 版本升级到 1.17.x 版本,以及从版本 1.17.x 升级到 1.17.y ,其中 y > x
2. 确认可升级版本与升级方案
yum list --showduplicates kubeadm --disableexcludes=kubernetes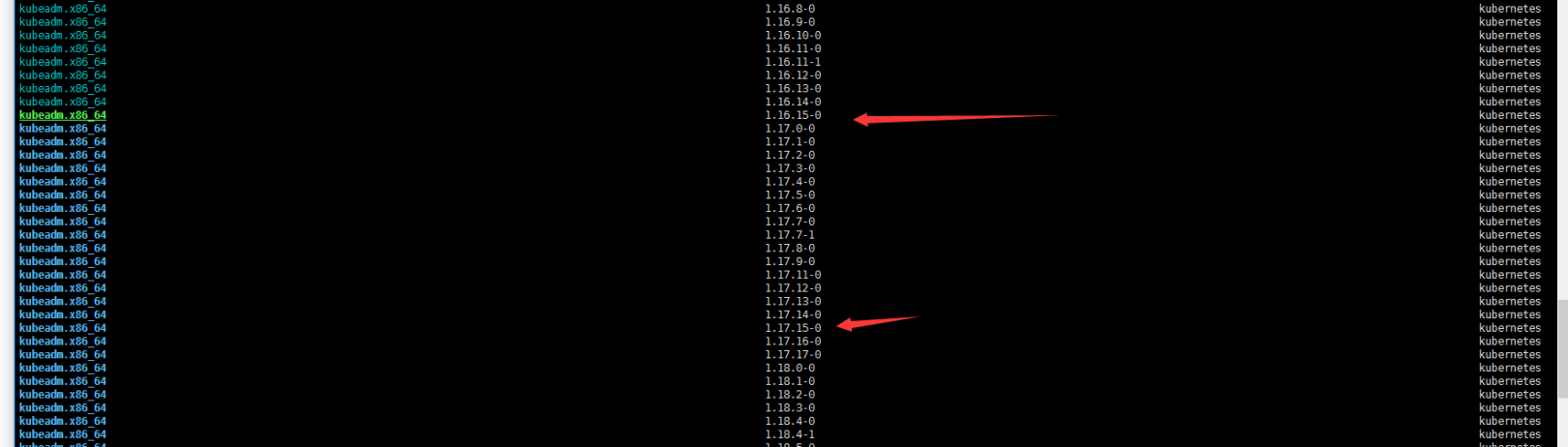
由于我的kubeadm版本是1.16.15 那我只能先升级到1.17.15 然后从1.17.15升级到1.17.17(先不考虑升级更高版本)。master节点有k8s-master-01 k8s-master-02 k8s-master-03三个节点,个人习惯一般不喜欢先动第一个,就直接从第三个节(sh-master-03)点入手了……
3. 升级k8s-master-03节点控制平面
yum install kubeadm-1.17.15-0 --disableexcludes=kubernetes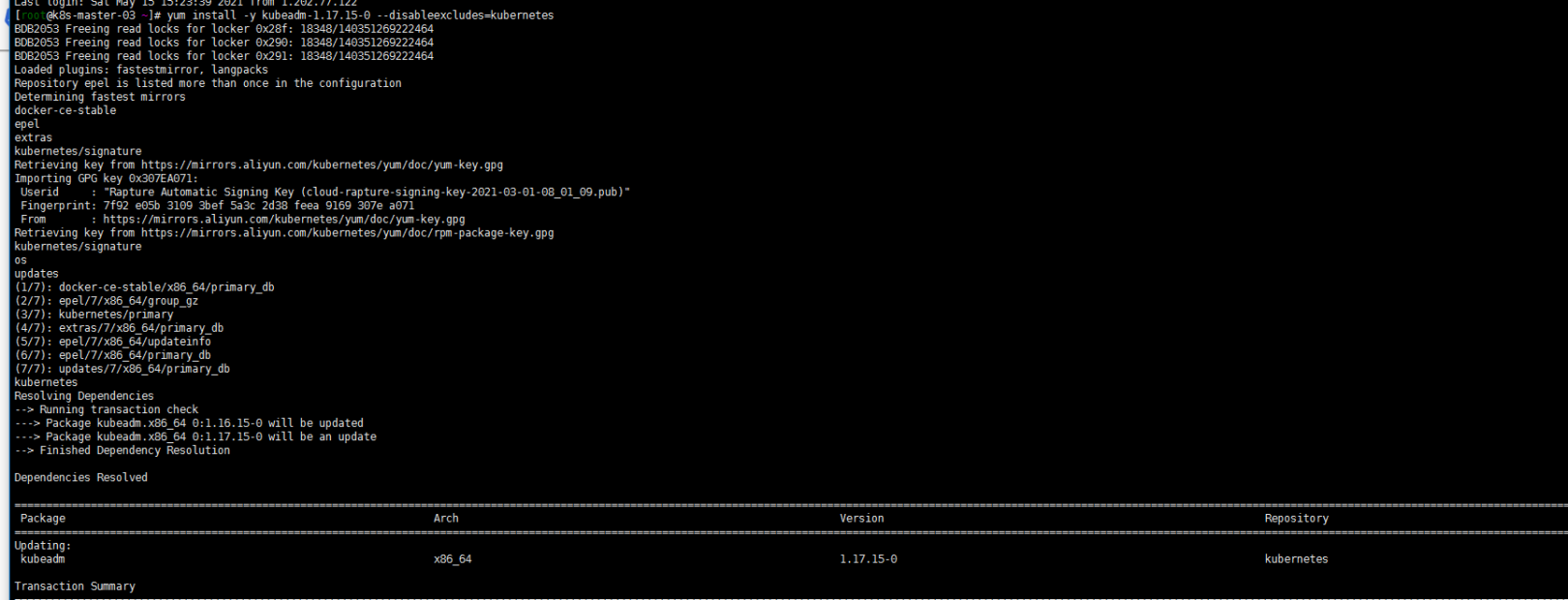
sudo kubeadm upgrade plan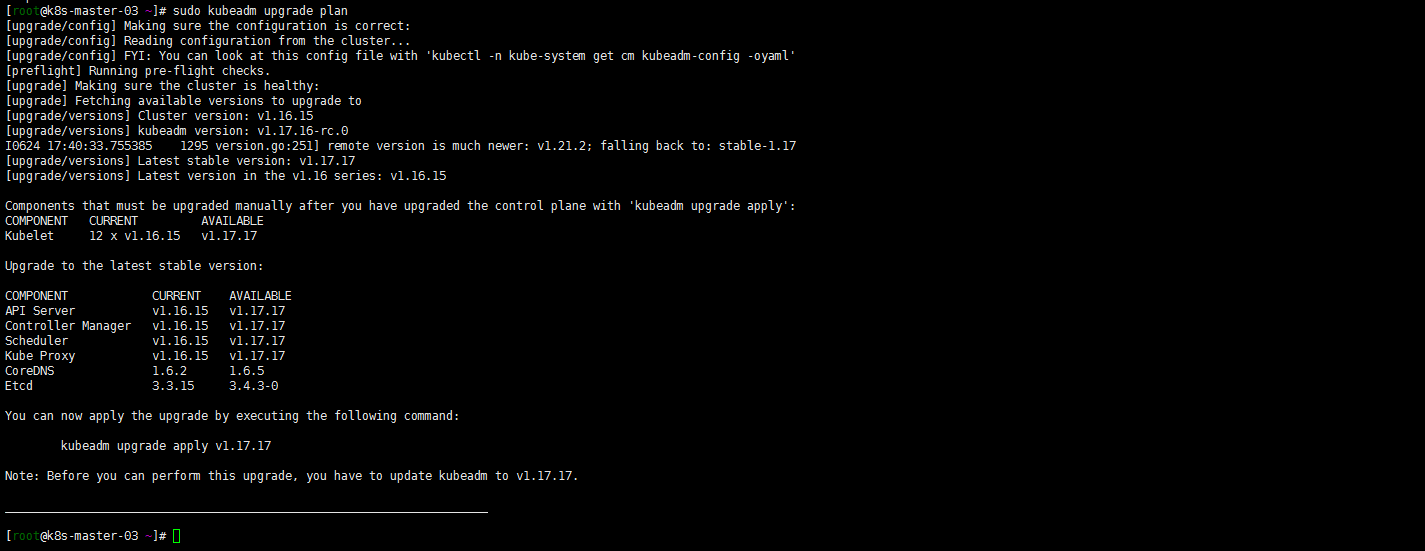
嗯 可以升级到1.17.17?试一下
kubeadm upgrade apply v1.17.17不能升级到1.17.17 但是可以到1.17.16?但是要先升级kubeadm。怎么会是这样呢?如下是可以1.y到1.y+1版本的。

kubeadm upgrade apply v1.17.15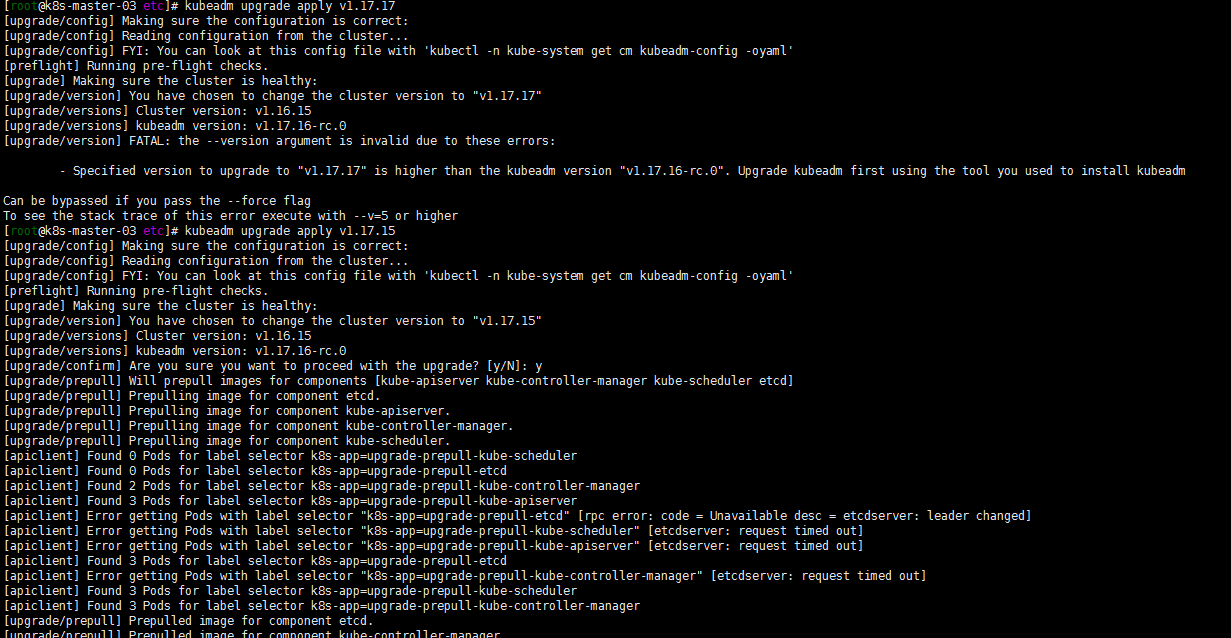
yum install -y kubelet-1.17.15-0 kubectl-1.17.15-0 --disableexcludes=kubernetes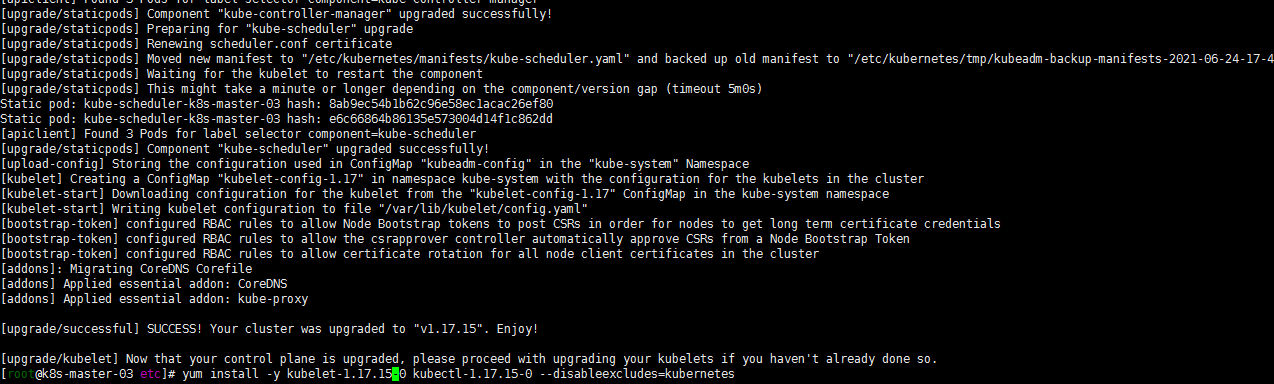
systemctl daemon-reload sudo systemctl restart kubelet嗯还是没有搞明白怎么就还是到1.17.16版本了,无伤大雅了。就先这样了!
注:当然了为了防止出现问题,应该是先把 /etc/kubernetes文件路径下配置文件备份一下!
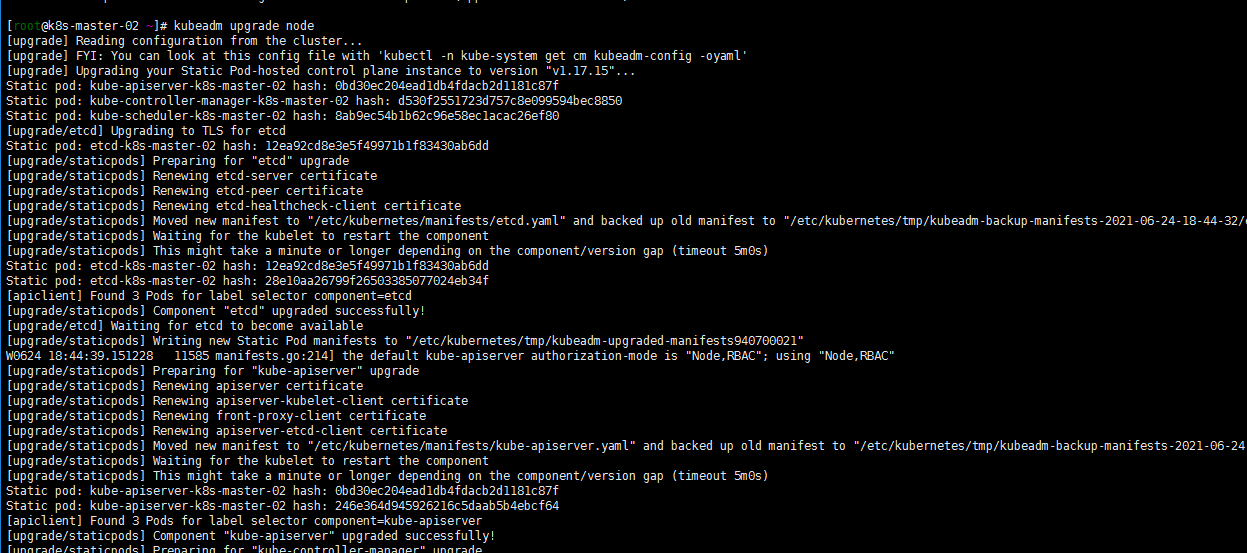
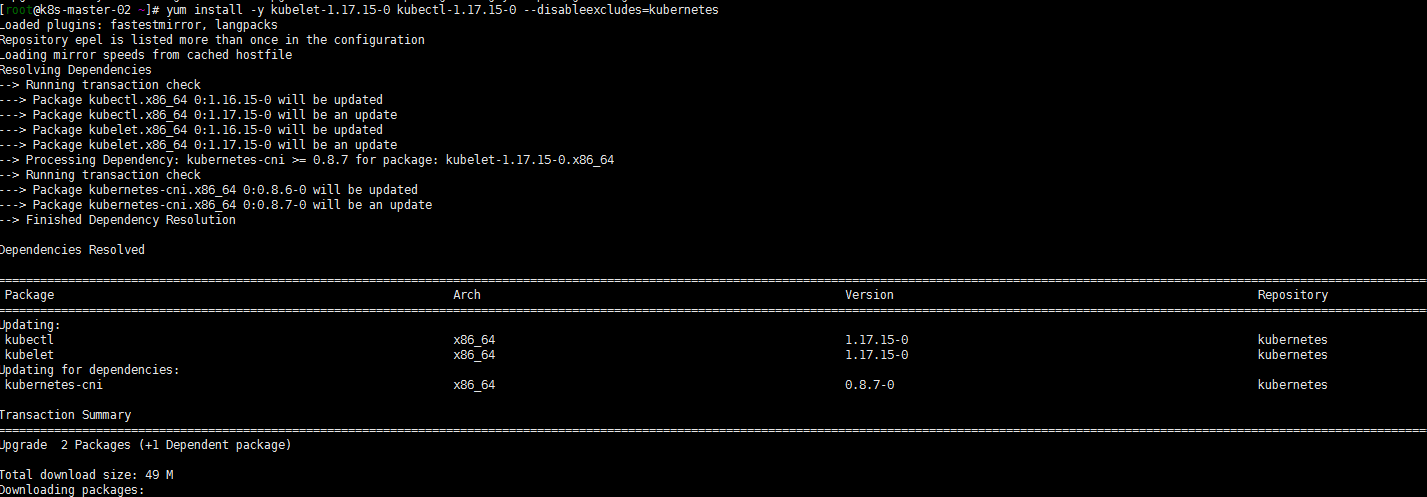
4. 升级其他控制平面(k8s-master-02 k8s-master-01)
其他两个master节点都执行一下命令:
yum install -y kubeadm-1.17.15-0 --disableexcludes=kubernetes kubeadm upgrade node yum install -y kubelet-1.17.15-0 kubectl-1.17.15-0 --disableexcludes=kubernetes systemctl daemon-reload sudo systemctl restart kubelet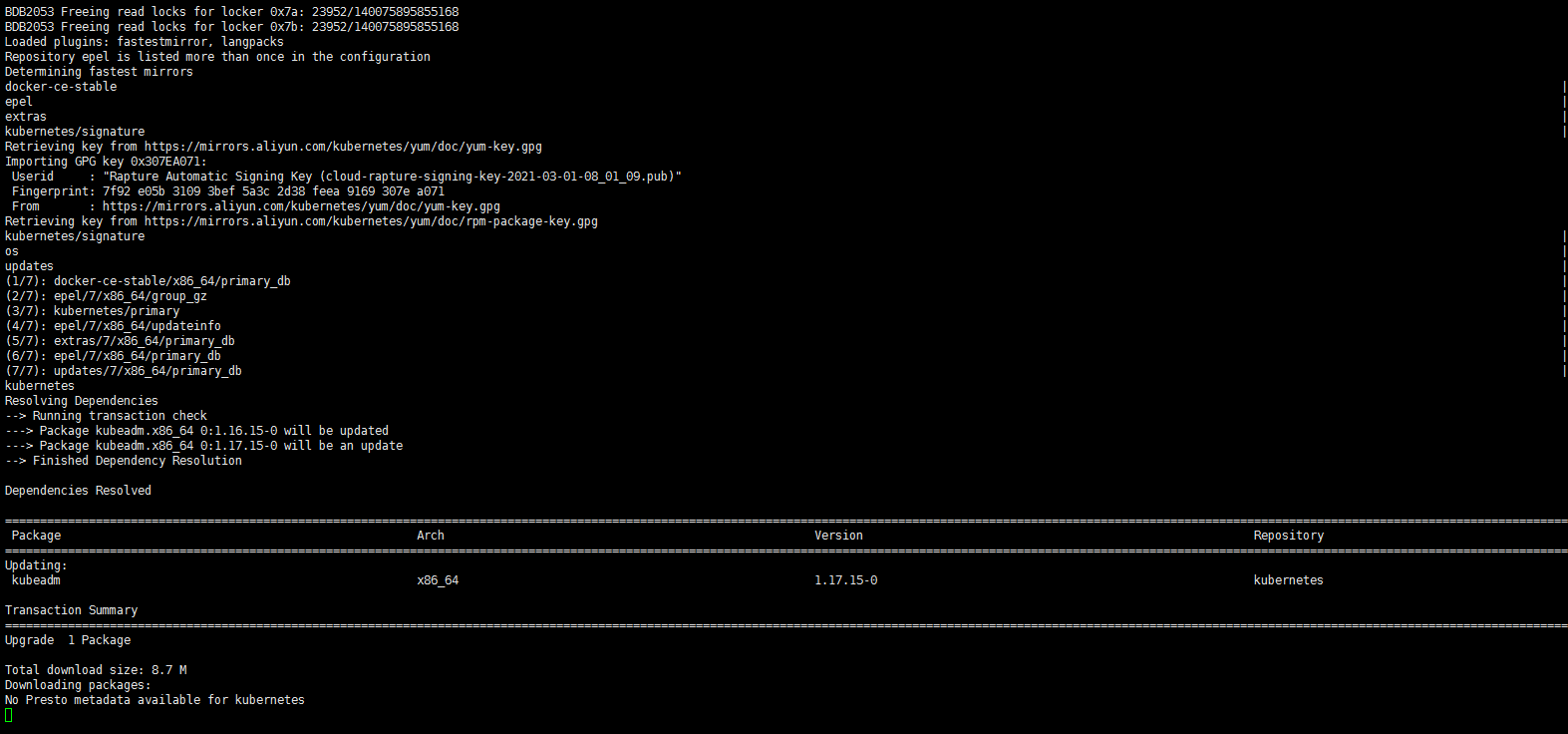
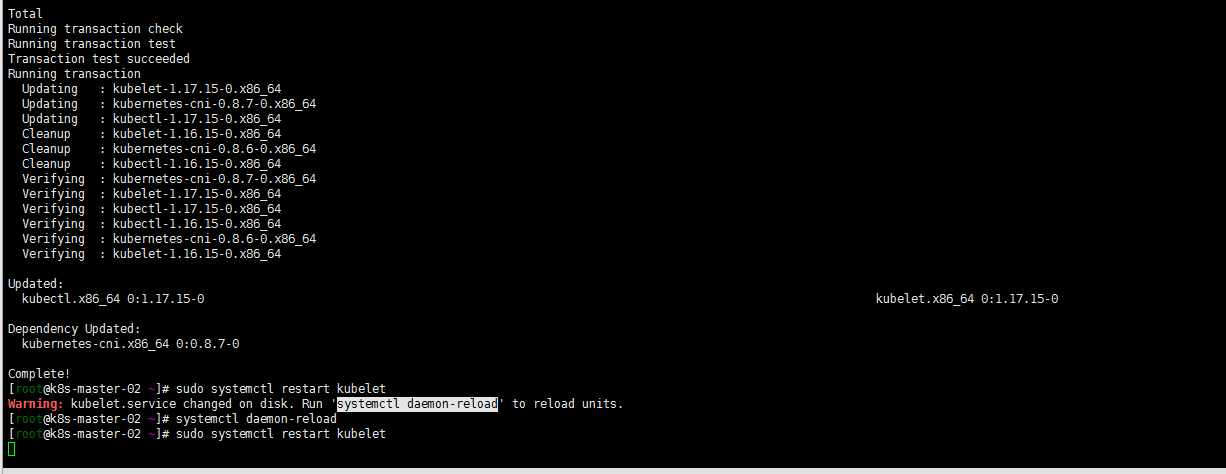
登陆任意一台master节点:
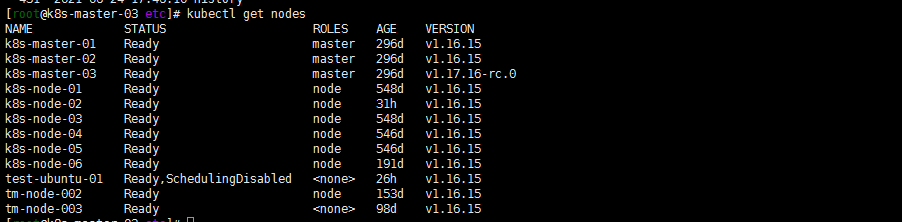
[root@k8s-master-03 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-01 Ready master 297d v1.17.15 k8s-master-02 Ready master 297d v1.17.15 k8s-master-03 Ready master 297d v1.17.16-rc.0 k8s-node-01 Ready node 549d v1.16.15 k8s-node-02 Ready node 2d5h v1.16.15 k8s-node-03 Ready node 549d v1.16.15 k8s-node-04 Ready node 547d v1.16.15 k8s-node-05 Ready node 547d v1.16.15 k8s-node-06 Ready node 192d v1.16.15 test-ubuntu-01 Ready,SchedulingDisabled <none> 47h v1.16.15 tm-node-002 Ready node 154d v1.16.15 tm-node-003 Ready <none> 99d v1.16.155. 继续升级小版本到1.17.17
同理,重复以上的步骤,小版本升级到1.17.17
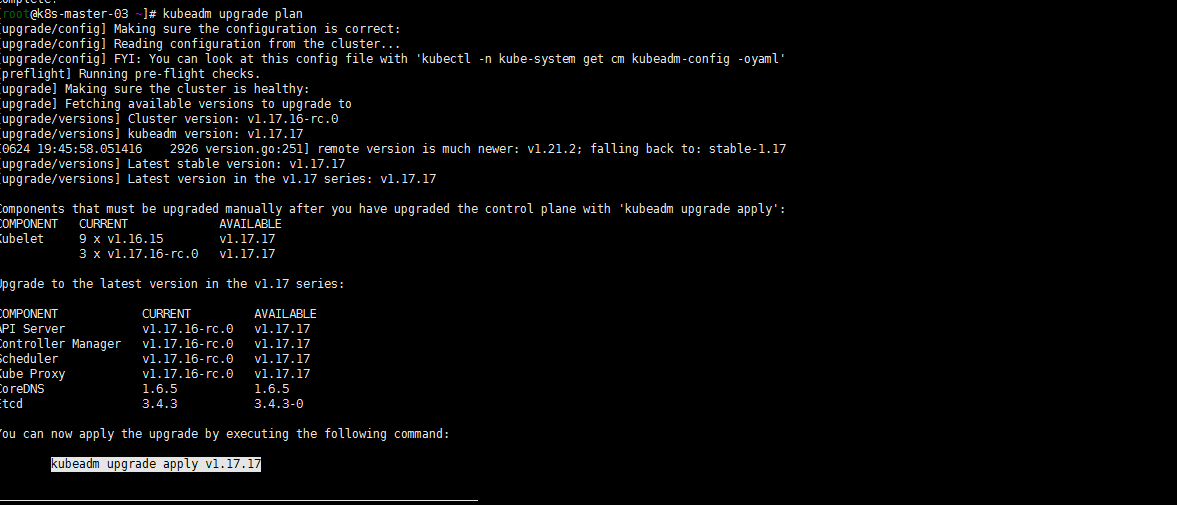
kubectl get nodes -o wide
注意:以上master-02 master-03控制平面节点升级忽略了腾空节点步骤
6. work节点的升级
所有work节点执行:
注:演示在k8s-node-03节点执行
yum install kubeadm-1.17.17 kubectl-1.17.17 kubelet-1.17.17 --disableexcludes=kubernetes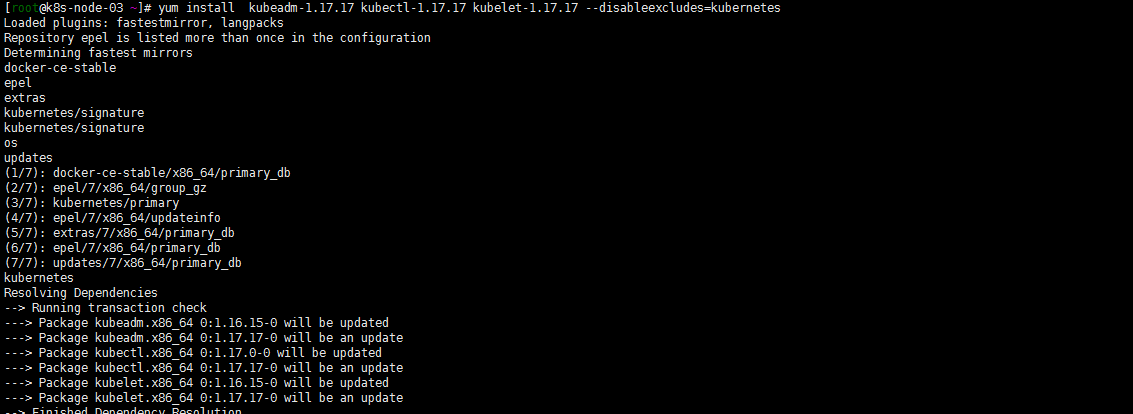
将节点设置为不可调度,并腾空节点:
kubectl drain k8s-node-03 --ignore-daemonsets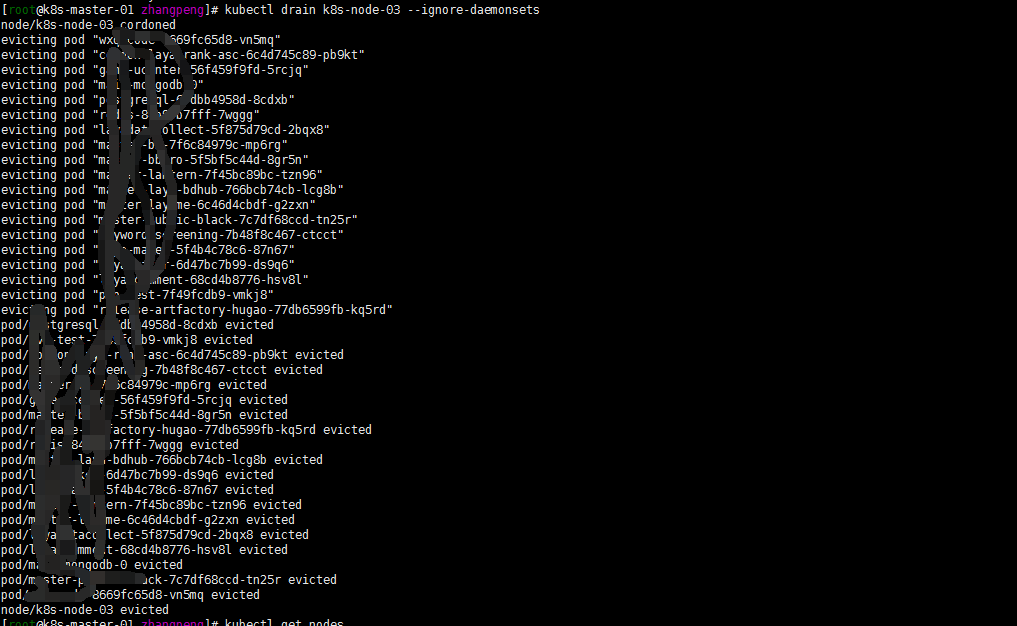
kubeadm upgrade node sudo systemctl daemon-reload sudo systemctl restart kubelet
kubectl uncordon k8s-node-03 kubectl get nodes -o wide注:后截的图already忽略,就看结果……,就先升级几个节点了。其他几点节点有时间再进行升级,估计也差不多,如有什么异常再进行整理分析!
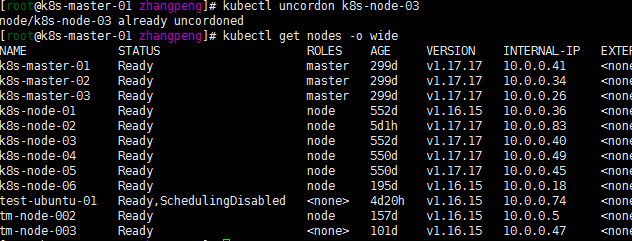
7. 升级与使用中出现的一些小问题
1. clusterrole
还是有些小异常,比如:我的controller-manager的clusterrole system:kube-controller-manager的权限怎么就有问题了?

不知道当时是不是因为只升级了两个节点k8s-master-01节点造成的。在出现这个问题的时候我是升级了k8s-master-01节点,然后删除了clusterrole system:kube-controller-manager,然后把我kubernetes1.21的clusterrole搞过来apply了
kubectl get clusterrole system:kube-controller-manager -o yaml > 1.yaml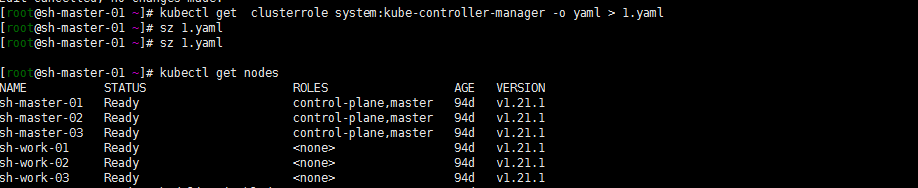
kubectl get clusterrole system:kube-controller-manager -o yaml >clusterrole.yaml kubectl apply -f 1.yaml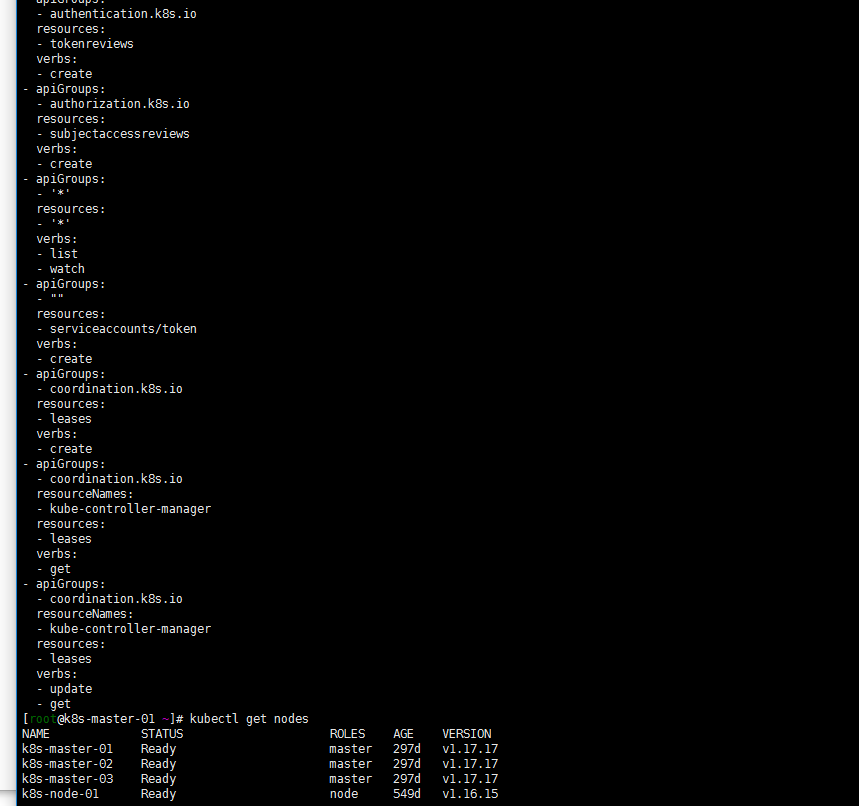
反正貌似就是解决了….clusterrole这东西看看仔细整一下。最近反正是有点懵了……
2. flannel的异常
还有一个问题是flannel的:
我的集群是1.15升级上来的。一直是没有问题的,但是新增加work节点后,分配到新节点的带探针的就会有各种诡异的问题.,要么探测不通过,要么重启反正各种问题…..怎么回事呢?
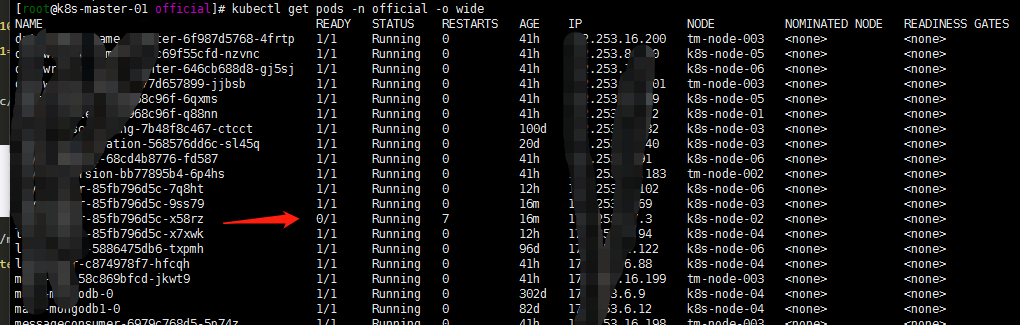
怀疑了一下flannel.登陆github flannel仓库看了一下:
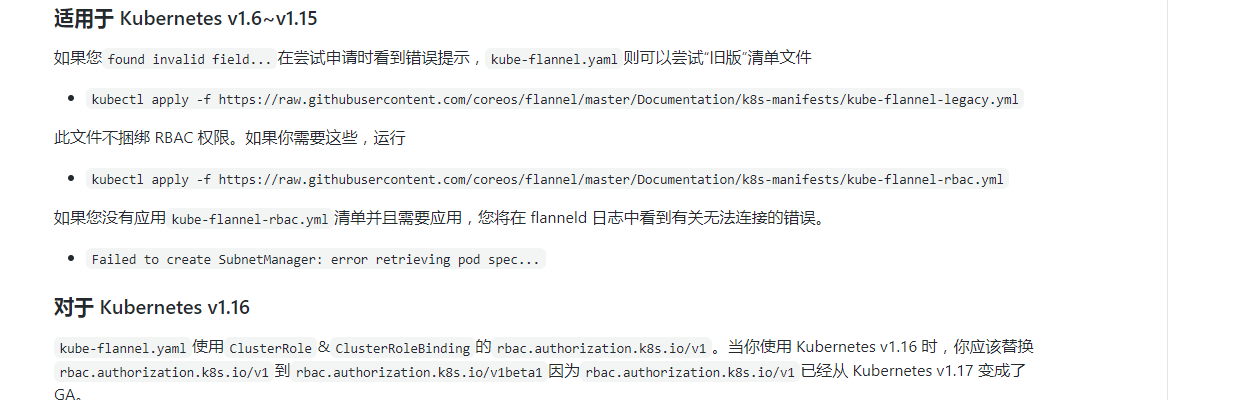
看了一下我的集群的flannel版本还都是v0.11。不管他了先升级一下flannel吧……
kubectl delete -f XXX.yaml(老的flannel插件配置文件)官方下载kube-flannel.yaml文件
修改network

注:当然了如果还是1.16也要修改一下rbac的 apiversion.
kubectl apply -f kube-flannel.yaml修改后是基本没有出现以往探针失败重启的现象了。
3. Prometheus的报错
kubernetes版本对应Prometheus的版本:
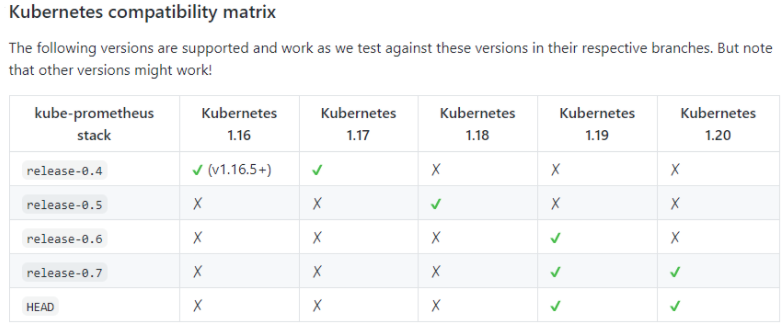
嗯我的是早期的0.4分支,kubernetes1.17还可以用。不过control-manager scheduler的报警都出现异常问题了……参照https://duiniwukenaihe.github.io/2021/05/14/Kubernetes-1.20.5-upgrade1.21.0%E5%90%8E%E9%81%97%E7%97%87/修改kube-controller-manage kube-scheduler配置文件。当然了。我如果升级到1.18或者更高的版本就刺激了…..的切换分支进行重新配置还是什么呢?
后记:
- 尽量去参考官方文档
- 记得升级网络组件
- api如有变化,记得修改相关组件version或者配置文件
-
2021-06-24-Kubernetes中资源的管理与调度
- 背景:
- 为什么要限制资源?
- Kubernets中的资源分类
- 资源配额管理-LimitRange ResourceQuota
- 关于资源的调度与pod的Qos模型:
- 如何保证pod的资源优先性与调度的优先性?
- 总结一下:
背景:
不知道有没有小伙伴跟我一样在集群创建应用的时候没有详细计算过自己的资源配比。然后我是看到kubectl top node 一看每个节点还有很多的资源,就直接创建了几个资源配比较高的应用,而且这几个应用是高负载运行的….然后的结果就是集群中好多应用开始崩溃了……
为什么要限制资源?
1. 对pod进行资源限制,可以防止由于某一个pod应用过多占用资源,造成其他应用异常。
2. 资源的有效隔离。
3. pod调度的优先级。
4. 资源的高效合理利用。
Kubernets中的资源分类
Kubernetes根据资源能否伸缩进行分类,划分为可压缩资源和不可以压缩资源2种:
1. 可压缩资源(compressible resources )当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。例如 CPU(GPU也是吧?只不过没有搞gpu应用忽略)
2. 不可压缩资源(incompressible resources)当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。例如:Memory(内存) Disk(硬盘)。
注:参见极客时间磊神的专栏:https://time.geekbang.org/column/article/69678
资源配额管理-LimitRange ResourceQuota
ResourceQuota
ResourceQuota 用来限制 namespace 中所有的 Pod 占用的总的资源 request 和 limit
可以参照:https://kubernetes.io/zh/docs/concepts/policy/resource-quotas/
1. 计算资源配额(Compute Resource Quata)
可以参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/manage-resources/quota-memory-cpu-namespace/。
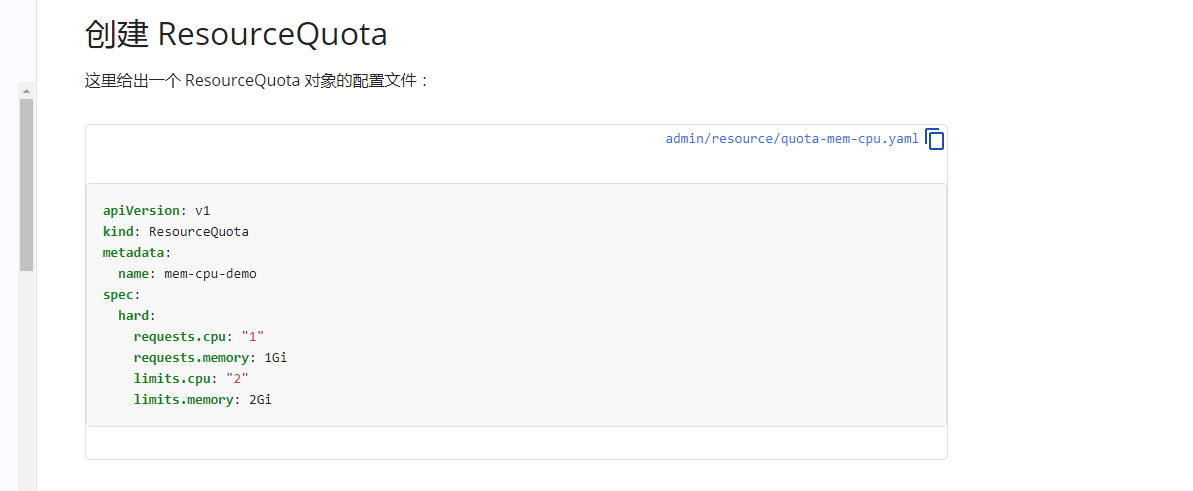
但是根据磊神:https://time.geekbang.org/column/article/69678中建议的还是将配置文件写成一下内部通用格式了:

cat > ResourceQuota.yaml << EOF apiVersion: v1 kind: ResourceQuota metadata: name: cpu-mem namespace: quota spec: hard: requests.cpu: 1000m requests.memory: 1000Mi limits.cpu: 2000m limits.memory: 2000Mi EOF[root@sh-master-01 quota]# kubectl create ns quota namespace/quota created [root@sh-master-01 quota]# kubectl apply -f ResourceQuota.yaml resourcequota/cpu-mem createdkubectl get resourcequota cpu-mem -n quota kubectl get resourcequota cpu-mem--namespace=quota --output=yaml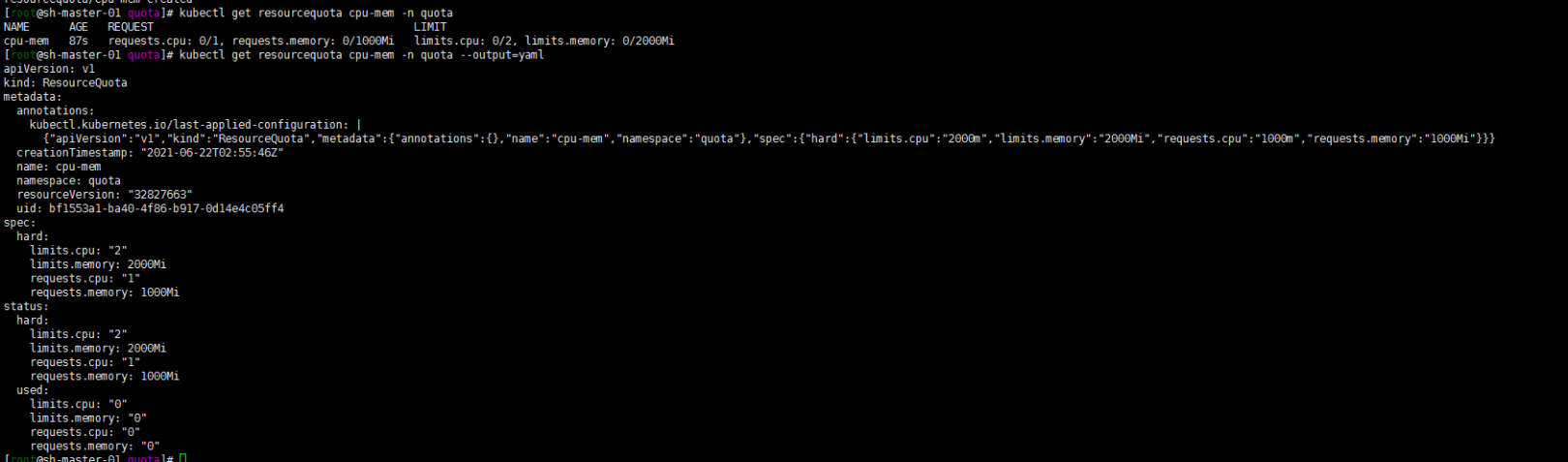
用官方文档实例创建一个pod测试一下:
cat > quota-mem-cpu-pod.yaml << EOF apiVersion: v1 kind: Pod metadata: name: quota-mem-cpu-demo spec: containers: - name: quota-mem-cpu-demo-ctr image: nginx resources: limits: memory: "800Mi" cpu: "800m" requests: memory: "600Mi" cpu: "400m" EOF在quota 命名空间中创建pod:
kubectl apply -f quota-mem-cpu-pod.yaml --namespace=quota检查下 Pod 中的容器在运行:
kubectl get pod quota-mem-cpu-demo --namespace=quota再查看 ResourceQuota 的详情:
kubectl get resourcequota cpu-mem --namespace=quota --output=yaml输出结果显示了配额以及有多少配额已经被使用。你可以看到 Pod 的内存和 CPU 请求值及限制值没有超过配额
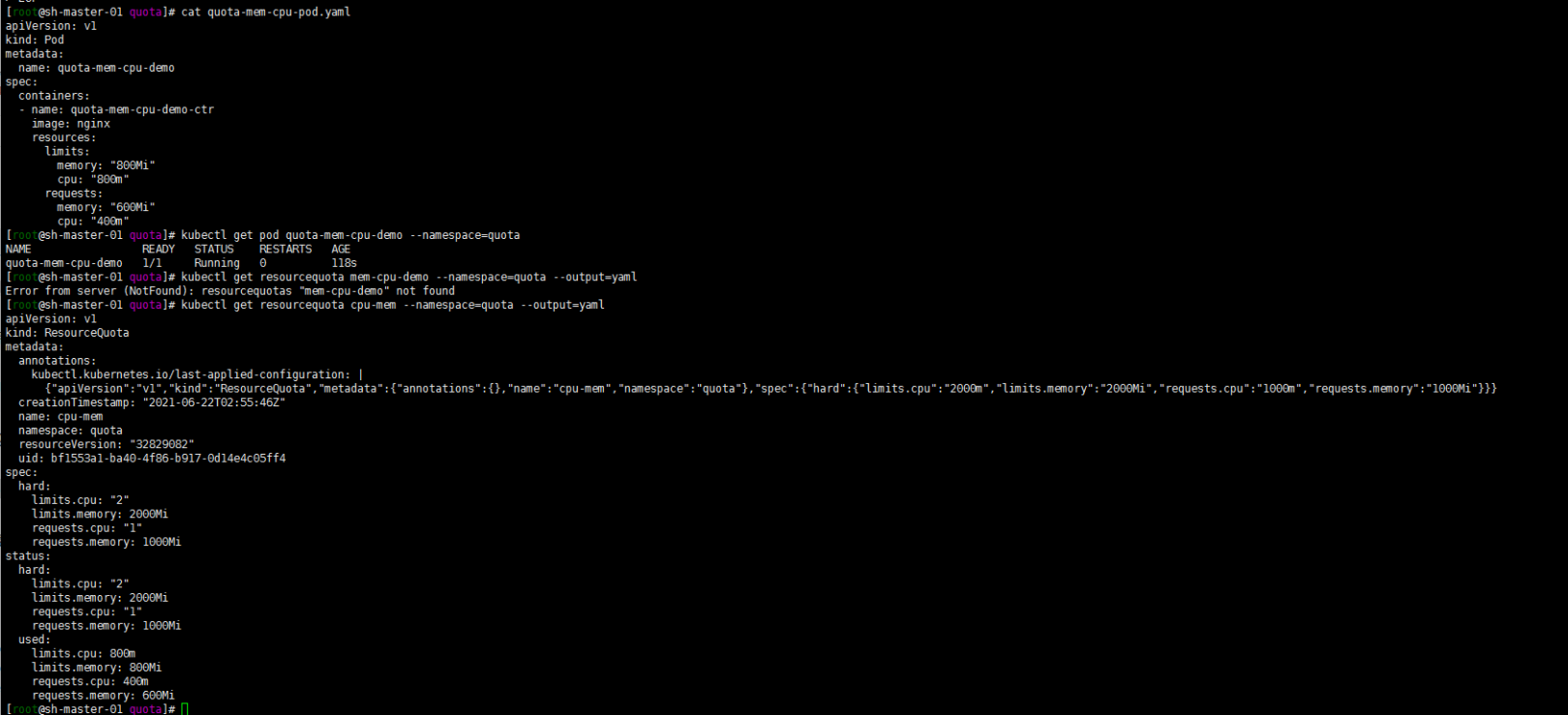
再创建一个pod:
cat > quota-mem-cpu-pod-2.yaml << EOF apiVersion: v1 kind: Pod metadata: name: quota-mem-cpu-demo-2 spec: containers: - name: quota-mem-cpu-demo-2-ctr image: nginx resources: limits: memory: "1000Mi" cpu: "800m" requests: memory: "700Mi" cpu: "400m" EOFkubectl apply -f quota-mem-cpu-pod-2.yaml --namespace=quota得到如下报错,第二个 Pod 不能被创建成功。输出结果显示创建第二个 Pod 会导致内存请求总量超过内存请求配额。

2. 存储资源配额(Volume Count Quata)
存储资源配额也演示一下吧。我这里就只限制存储总量了。其他的可设置参数可以参考官方文档:
cat > storage.yaml << EOF apiVersion: v1 kind: ResourceQuota metadata: name: storage namespace: quota spec: hard: requests.storage: 10Gi EOFcat > pvc.yaml << EOF apiVersion: v1 kind: PersistentVolumeClaim metadata: name: quota-mem-cpu-demo-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 20Gi storageClassName: cbs-csi EOF在quota namespace中创建pvc:
kubectl apply -f pvc.yaml -n quota得到如下报错。最大限制为10G。

3. 对象数量配额(Object Count Quata)
cat > objects.yaml << EOF apiVersion: v1 kind: ResourceQuota metadata: name: objects namespace: quota spec: hard: pods: 10 replicationcontrollers: 5 secrets: 10 configmaps: 10 persistentvolumeclaims: 4 services: 5 services.loadbalancers: 1 services.nodeports: 2 cbs.storageclass.storage.k8s.io/persistentvolumeclaims: 2 EOF数量配额就不演示。根据官方文档设置可以设置的限制数量的参数,并设置数量。只要数量大于设置数量失败就可以验证!
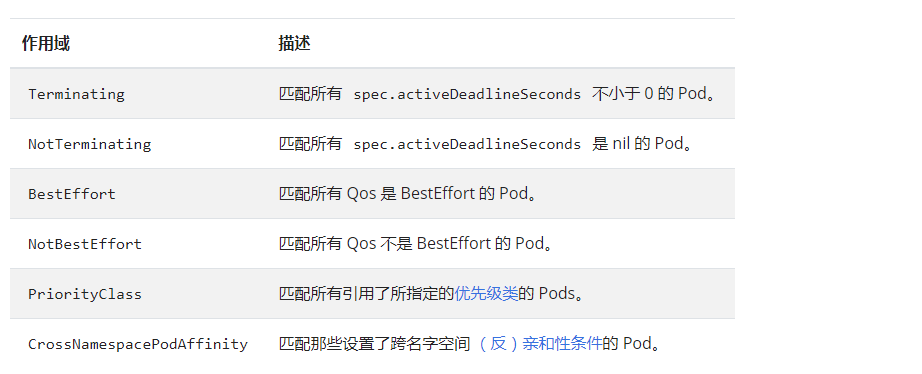
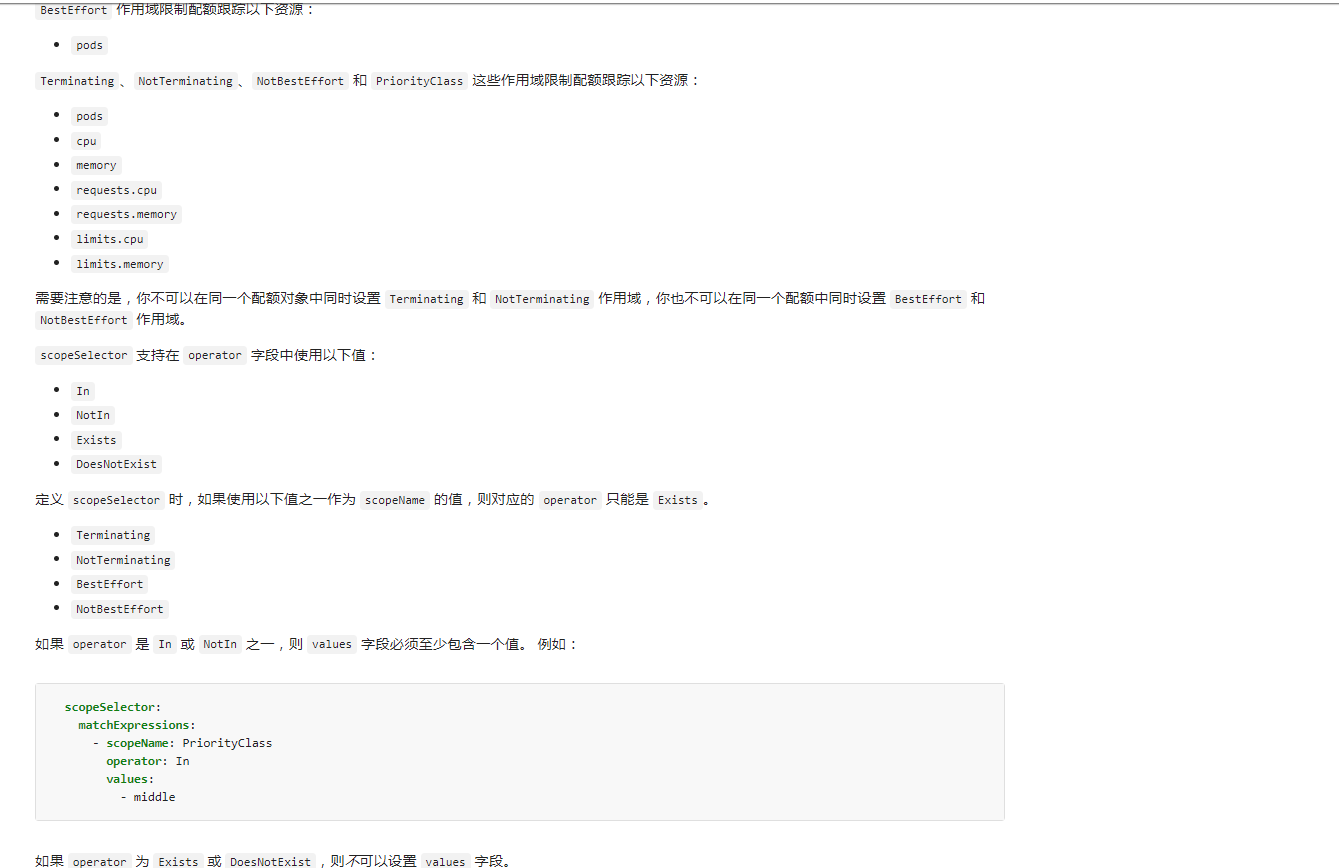
4. 配额的作用域(Quota Scopes)
这个鬼东西功能没有怎么用过,就抄了一下官方的。有时间研究一下,一下实例摘自kubernetes权威指南第五版750页:
1. 创建ResourceQuota scope
创建一个quota-scopes的命名空间,并创建一个名为best-effort的 ResourceQuota,一个名为not-best-effort的 ResourceQuota:
kubectl create ns quota-scopes kubectl create quota best-effort --hard=pods=10 --scopes=BestEffort -n quota-scopes kubectl create quota not-best-effort --hard=pods=4,requests.cpu=1000m,requests.memory=1024Mi,limits.cpu=2000m,limits.memory=2048Mi --scopes=NotBestEffort -n quota-scopes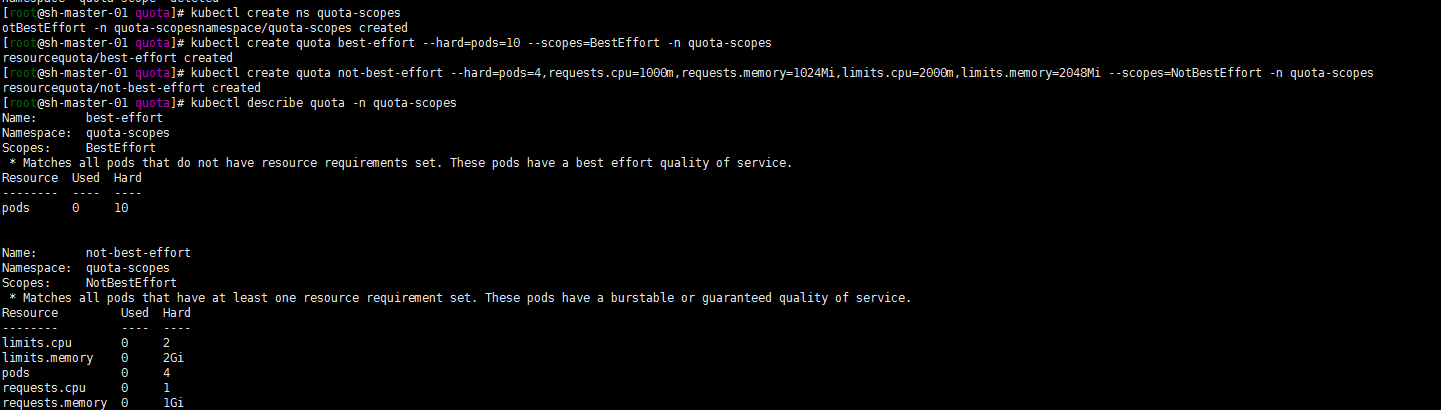
注:官方的方式是yaml的方式。正巧看到了http://docs.kubernetes.org.cn/541.html#kubectl_create_quota中
kubectl create quota就用了一下.
2. 创建两个deployment
kubectl run best-effort-nginx --image=nginx --replicas=8 --namespace=quota-scope kubectl run not-best-effort-nginx --image=nginx= --replicas=2 --requests=cpu=100m,memory=256Mi --limits=cpu=200m,memory=512Mi --namespace=quota-scopes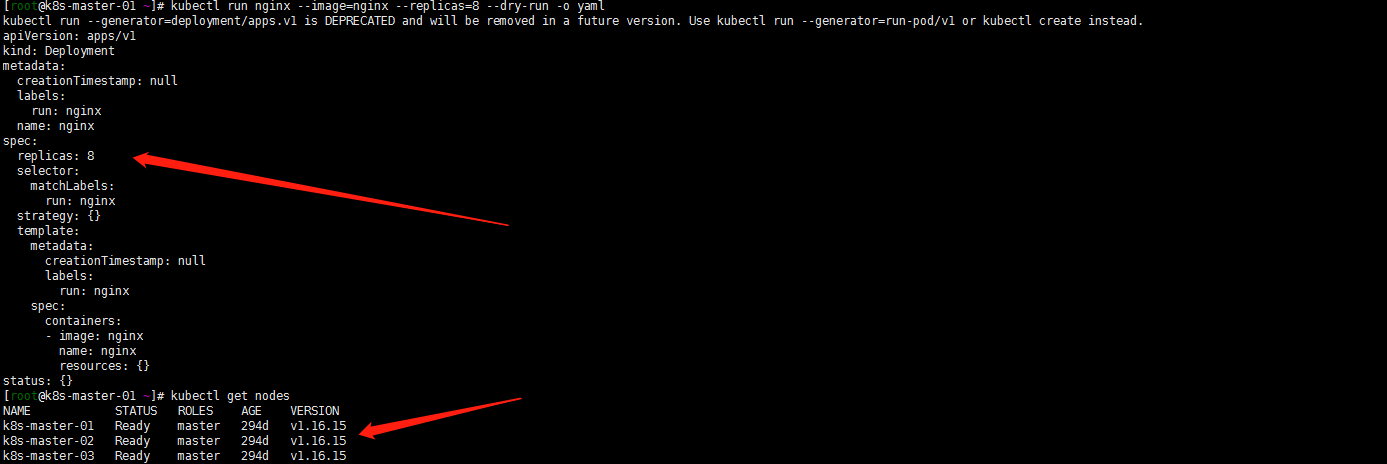

嗯这里就坑了。kubectl run 在1.16.16测试了下可以带replicas。但是我的1.21.1不能这样执行了。看了下文档使用下面的kubectl create deployment 命令
kubectl create deployment best-effort-nginx --image=nginx --replicas=8 --namespace=quota-scopes但是创建not-best-effort-nginx deployment时候,命令中貌似不能使用 –requests 和–limits了?用最笨的方法吧,创建deployment然后edit deployment增加resources限制:
kubectl create deployment not-best-effort-nginx --image=nginx --replicas=2 --namespace=quota-scopes kubectl edit deployment not-best-effort-nginx -n quota-scopes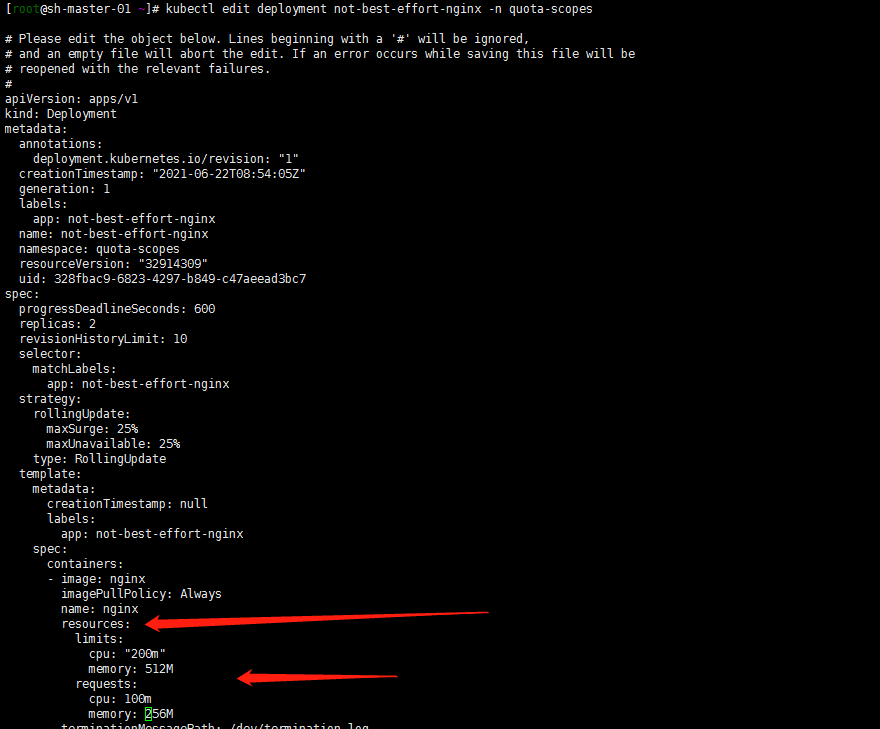
3. 验证:
kubectl get pods -n quota-scopes kubectl describe quota -n quota-scopes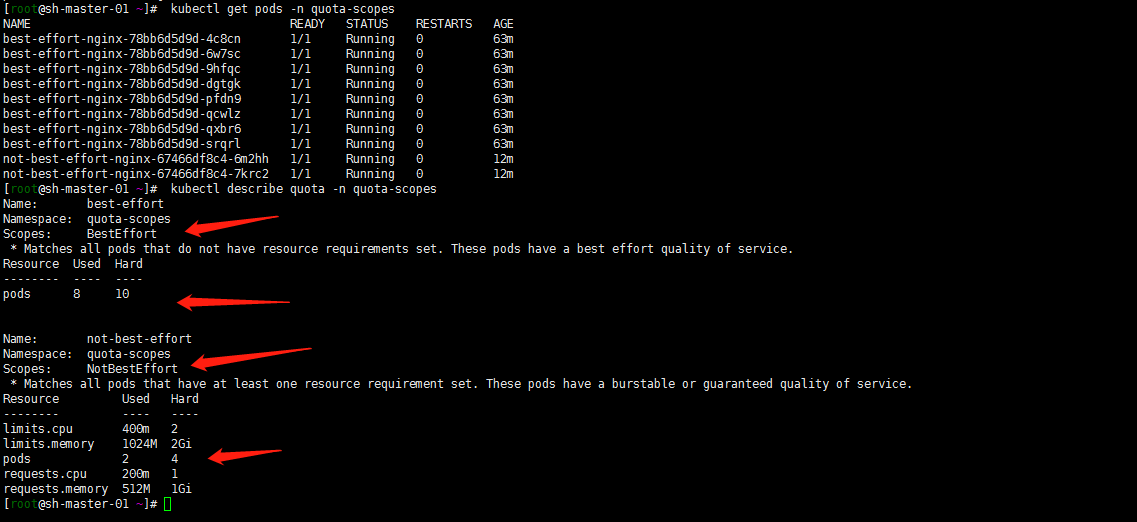
5. 基于优先级类(PriorityClass)来设置资源配额
注:这个鬼东西没有用过官方文档看来的……
FEATURE STATE: Kubernetes v1.17 stable
Pod 可以创建为特定的优先级。 通过使用配额规约中的 scopeSelector 字段,用户可以根据 Pod 的优先级控制其系统资源消耗。
仅当配额规范中的 scopeSelector 字段选择到某 Pod 时,配额机制才会匹配和计量 Pod 的资源消耗。
如果配额对象通过 scopeSelector 字段设置其作用域为优先级类,则配额对象只能 跟踪以下资源:
- pods
- cpu
- memory
- ephemeral-storage
- limits.cpu
- limits.memory
- limits.ephemeral-storage
- requests.cpu
- requests.memory
- requests.ephemeral-storage
本示例创建一个配额对象,并将其与具有特定优先级的 Pod 进行匹配。 该示例的工作方式如下:
- 集群中的 Pod 可取三个优先级类之一,即 “low”、”medium”、”high”。
- 为每个优先级创建一个配额对象。
将以下 YAML 保存到文件 quota.yml 中。
apiVersion: v1 kind: List items: - apiVersion: v1 kind: ResourceQuota metadata: name: pods-high spec: hard: cpu: "1000" memory: 200Gi pods: "10" scopeSelector: matchExpressions: - operator : In scopeName: PriorityClass values: ["high"] - apiVersion: v1 kind: ResourceQuota metadata: name: pods-medium spec: hard: cpu: "10" memory: 20Gi pods: "10" scopeSelector: matchExpressions: - operator : In scopeName: PriorityClass values: ["medium"] - apiVersion: v1 kind: ResourceQuota metadata: name: pods-low spec: hard: cpu: "5" memory: 10Gi pods: "10" scopeSelector: matchExpressions: - operator : In scopeName: PriorityClass values: ["low"]使用 kubectl create 命令运行以下操作。
kubectl create -f quota.yml kubectl describe quota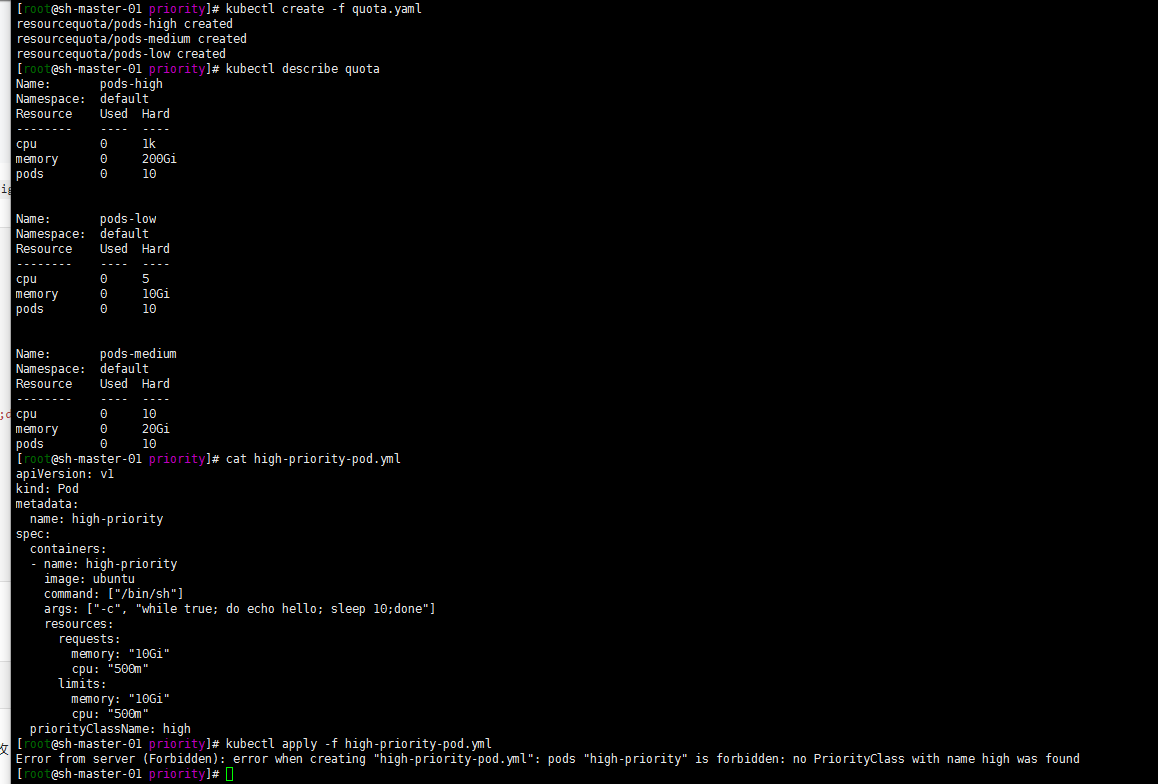
LimitRange
LimitRange 用来限制 namespace 中 单个Pod 默认资源 request 和 limit
1. 一般的例子 单个container的pod
嗯 一般是通过requests limits去限制pod cpu与内存的资源的。如下:
apiVersion: apps/v1 kind: Deployment metadata: name: php-test spec: replicas: 2 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 0 selector: matchLabels: app: php-test template: metadata: labels: app: php-test spec: containers: - name: php-test image: ccr.ccs.tencentyun.com/master/php-test:0.1 env: - name: PHP_MEM_LIMIT value: "256M" envFrom: - configMapRef: name: deploy ports: - containerPort: 80 resources: requests: memory: "256M" cpu: "250m" limits: memory: "2048M" cpu: "4000m" livenessProbe: httpGet: scheme: HTTP path: /test.html port: 80 initialDelaySeconds: 30 periodSeconds: 30 successThreshold: 1 failureThreshold: 3 readinessProbe: httpGet: scheme: HTTP path: /test.html port: 80 initialDelaySeconds: 30 periodSeconds: 30 imagePullSecrets: - name: tencent --- apiVersion: v1 kind: Service metadata: name: php-test labels: app: php-test spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: php-test2. 多个container的pod
当然了 一个pod可以有多个container:
apiVersion: v1 kind: Pod metadata: name: kucc1 spec: containers: - image: nginx name: nginx resources: requests: memory: "256M" cpu: "250m" limits: memory: "2048M" cpu: "4000m" - image: redis name: redis resources: requests: memory: "256M" cpu: "250m" limits: memory: "2048M" cpu: "4000m"这个pod的request 内存最低是512M ,cpu是0.5核。limits 内存是4096M,cpu是8核。
嗯 pod 与container的关系,一个pod可以包括多个container
关于资源的调度与pod的Qos模型:
资源管理-Compute Resource
qos-服务质量管理
kubernetes在对pod进行调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。
Kubernetes 将 pod 划分为 3 种 QoS 等级 :
- BestEffort (优先级最低)
- Burstable
- Guaranteed (优先级最高)
最低优先级的 QoS 等级是 BestEffort 。 会分配给那些没有(为任何容器) 设置任何 requests 和 limits 的 pod。在这个等级运行的容器没有任何资源保证。 在最坏情况下,它们分不到任何 CPU 资源,同时在需要为其他 pod 释放内存时, 这些容器会第一批被杀死。 不过因为 BestEffort pod 没有配置内存 limits, 当有充足的可用内存时,这些容器可以使用任意多的内存。
apiVersion: v1 kind: Pod metadata: name: php-test namespace: develop spec: containers: - name: php-test image: nginxGuaranteed 级别的 pod,有以下几个条件:
- CPU 和内存都要设置 requests 和 limits
```
apiVersion: v1
kind: Pod
metadata:
name: php-test
namespace: qa
spec:
containers:
- name: php-test image: nginx resources: limits: memory: “200Mi” cpu: “700m” requests: memory: “200Mi” cpu: “700m” ```
- 每个容器都需要设置资源量
- 它们必须相等(每个容器的每种资源的 requests 和 limits 必须相等)
Burstable QoS 等级介于 BestEffort 和 Guaranteed 之间。其他所有 的 pod 都属于这个等级。 包括容器的requests 和 limits 不相同的单容器 pod,至少有 一个容器只定义了 requests 但没有定义 limits 的 pod,以及一个容器的 requests,limits 相等,但是另一个容器不指定 requests 或 limits 的 pod。
apiVersion: v1 kind: Pod metadata: name: php-test namespace: master spec: containers: - name: php-test image: nginx resources: limits memory: "200Mi" requests: memory: "100Mi"注:
Guaranteed >Burstable > BestEffort 故 在上面的实例中我采用了三个不同的namespace进行了优先性的一个区分吧算是。因为我的master namespace是最重要优先的线上服务,qa算是测试环境,develop是开发环境。避免资源被抢占的最好方式就是将resource中limits与requests值设置为相同的值,Qos优先级为Guaranteed。
如何保证pod的资源优先性与调度的优先性?
kubernetes pod应用分布到哪个节点上默认是通过master的scheduler经过一系列算法得出的,用户是无干预过程和结果的。设置Qos优先级为Guaranteed只能保证资源的优先。还有什么其他的方式去保证资源的优先与调度呢?
1. NodeSelector 定向调度
将pod 调度到一组含有相同标签的work节点
[root@sh-master-01 ~]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS sh-master-01 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= sh-master-02 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-02,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= sh-master-03 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-03,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= sh-work-01 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-01,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2 sh-work-02 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-02,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2 sh-work-03 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-03,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2给节点sh-work-01打一个zone=shanghai标签,
[root@sh-master-01 ~]# kubectl label node sh-work-01 zone=shanghai node/sh-work-01 labeled [root@sh-master-01 ~]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS sh-master-01 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= sh-master-02 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-02,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= sh-master-03 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-03,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= sh-work-01 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-01,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2,zone=shanghai sh-work-02 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-02,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2 sh-work-03 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-03,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2新建一个pod调度到zone=shanghai节点
就用 nginx镜像去做测试了:
kubectl run nginx --image=nginx:latest --port=80 --dry-run -o yaml > nodeselector.yamlvim nodeselector.yaml,增加nodeSelector 配置
cat > nodeselector.yaml << EOF apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: nginx name: nginx spec: containers: - image: nginx:latest name: nginx ports: - containerPort: 80 resources: {} nodeSelector: zone: shanghai dnsPolicy: ClusterFirst restartPolicy: Always status: {} EOF部署并验证pod是否调度到sh-work-01节点:
kubectl apply -f nodeselector.yaml kubectl get pods -o wide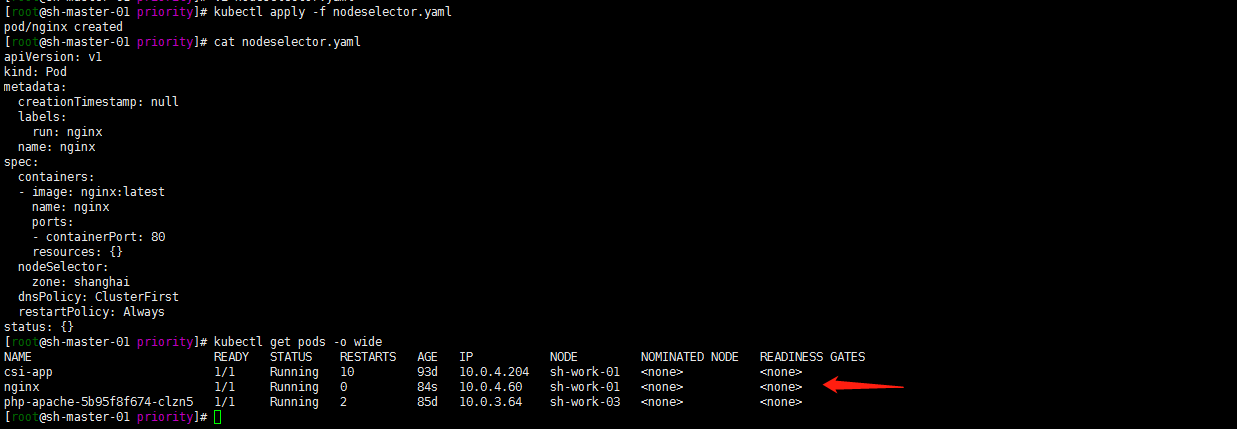
注:
nodeSelector属于强制性的,如果我们的目标节点没有可用的资源,Pod 就会一直处于 Pending 状态。2. NodeAffinity: Node亲和性
1. 亲和性调度可以分成软策略和硬策略两种方式:
1. 软策略-preferredDuringSchedulingIgnoredDuringExecution只是强调优先,但是不强求。就是如果你没有满足调度要求的节点的话,pod 就会忽略这条规则,继续完成调度过程,说白了就是**满足条件最好了,没有的话也无所谓了**的策略。当然还可以有多个优先规则,可以设置wight权重值,定义先后顺序。2. 硬策略-requiredDuringSchedulingIgnoredDuringExecution必须满足指定的规则才可以调度pod到node上,比较强硬了,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不干的策略。
2. 关于IgnoredDuringExecution详细见官方:

IgnoredDuringExecution类似于 nodeSelector 的工作原理, 如果节点的标签在运行时发生变更,从而不再满足 Pod 上的亲和性规则,那么 Pod 将仍然继续在该节点上运行。
3. 常见的语法操作符
提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
如果你同时指定了 nodeSelector 和 nodeAffinity,_两者_必须都要满足, 才能将 Pod 调度到候选节点上。
如果你指定了多个与 nodeAffinity 类型关联的 nodeSelectorTerms,则 如果其中一个 nodeSelectorTerms 满足的话,pod将可以调度到节点上。
如果你指定了多个与 nodeSelectorTerms 关联的 matchExpressions,则 只有当所有 matchExpressions 满足的话,Pod 才会可以调度到节点上。
如果你修改或删除了 pod 所调度到的节点的标签,Pod 不会被删除。 换句话说,亲和性选择只在 Pod 调度期间有效。
preferredDuringSchedulingIgnoredDuringExecution 中的 weight 字段值的 范围是 1-100。 对于每个符合所有调度要求(资源请求、RequiredDuringScheduling 亲和性表达式等) 的节点,调度器将遍历该字段的元素来计算总和,并且如果节点匹配对应的 MatchExpressions,则添加“权重”到总和。 然后将这个评分与该节点的其他优先级函数的评分进行组合。 总分最高的节点是最优选的。
4. 举个例子
1.
关于硬策略的例子搞一个没有的的标签试一下硬限制:
cat > pod-nodeAffinity.yaml << EOF apiVersion: v1 kind: Pod metadata: name: pod-nodeaffinity namespace: default labels: app: myapp type: pod spec: containers: - name: myapp image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node01 EOFkubectl apply -f pod-nodeAffinity.yaml kubectl get pods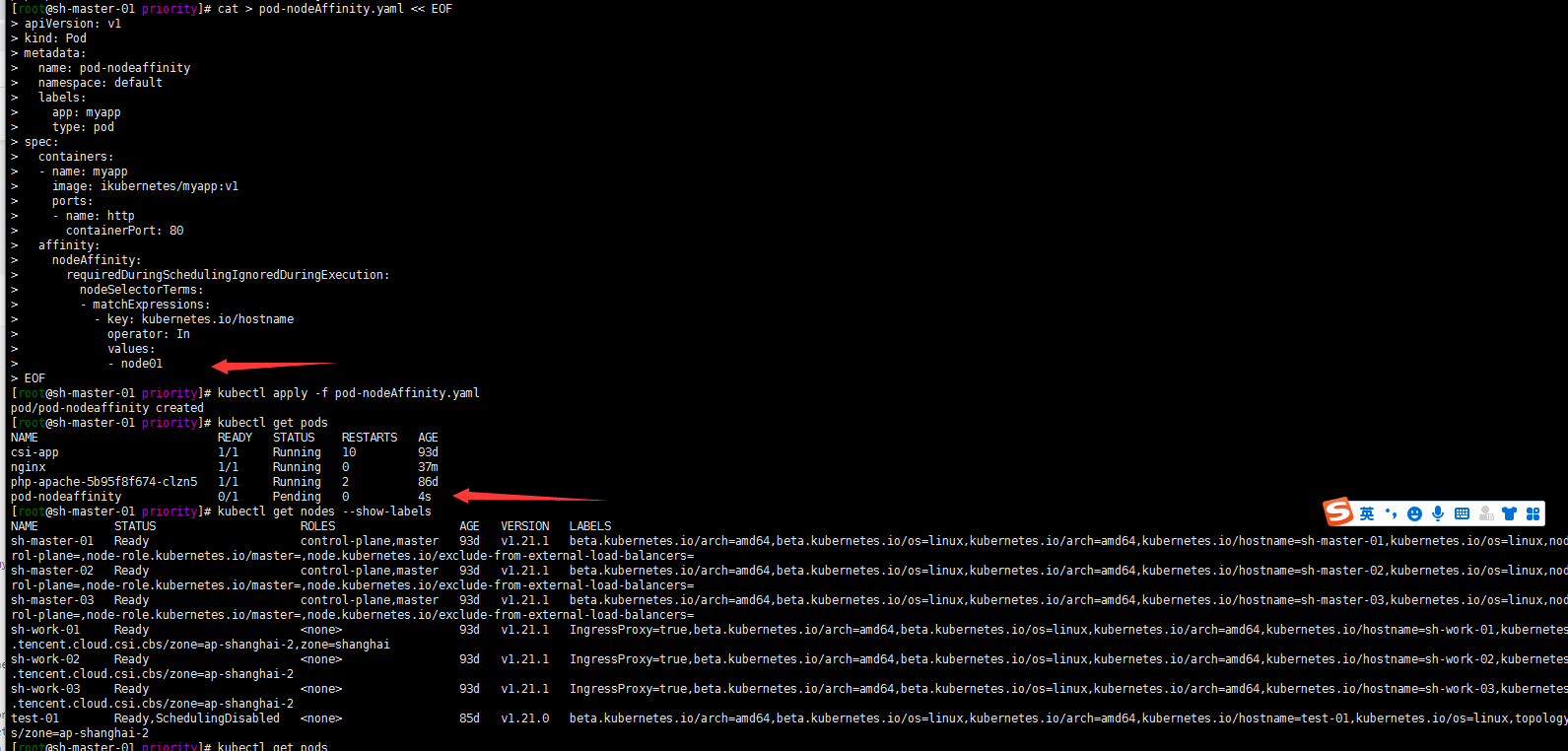
嗯 我是没有kubernetes.io/hostname:node01标签的节点的所以pod一直处于pending状态
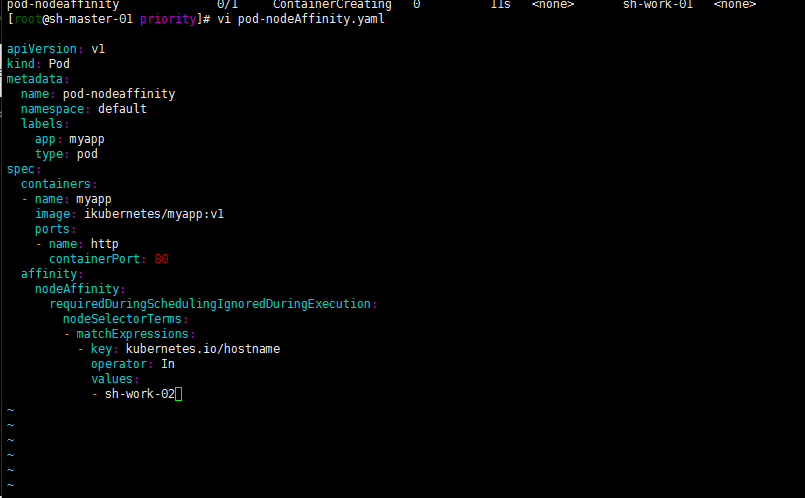
修改一下kubernetes.io/hostname:sh-work-01吧
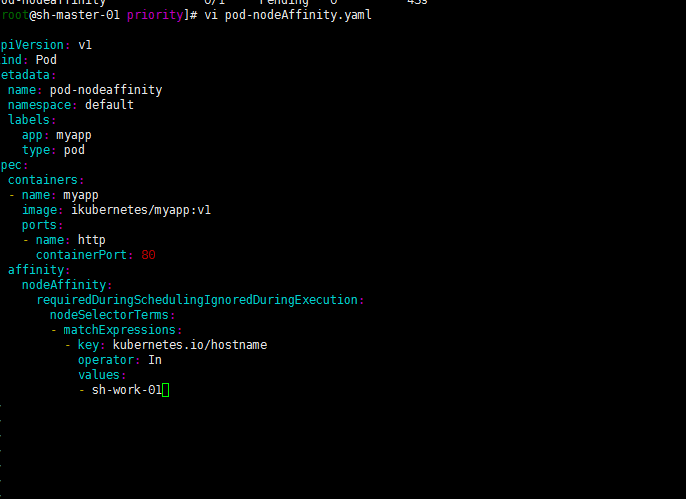
嗯 如下
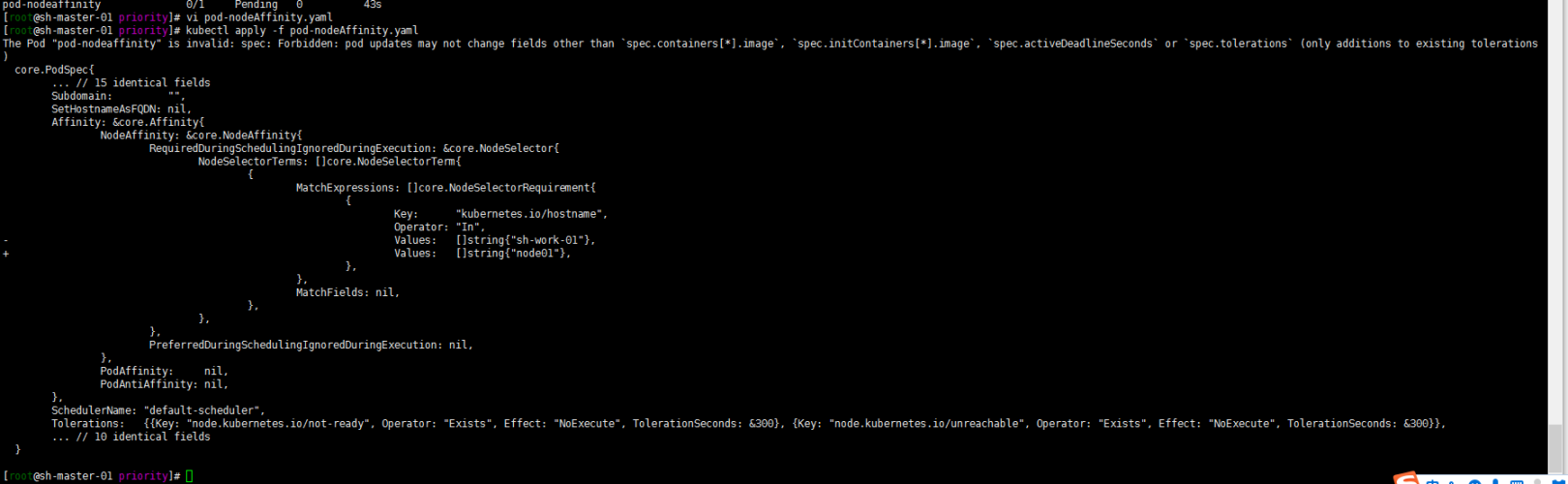
删除重新部署一下试试:
kubectl delete -f pod-nodeAffinity.yaml kubectl create -f pod-nodeAffinity.yaml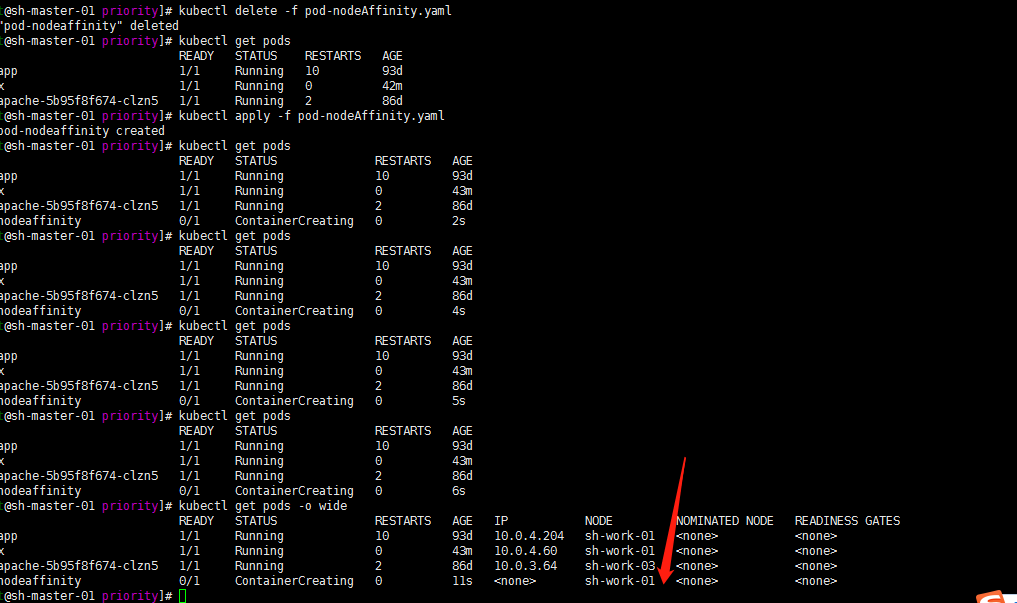
然后我现在修改下values试试? 将sh-work-01修改为sh-work-02
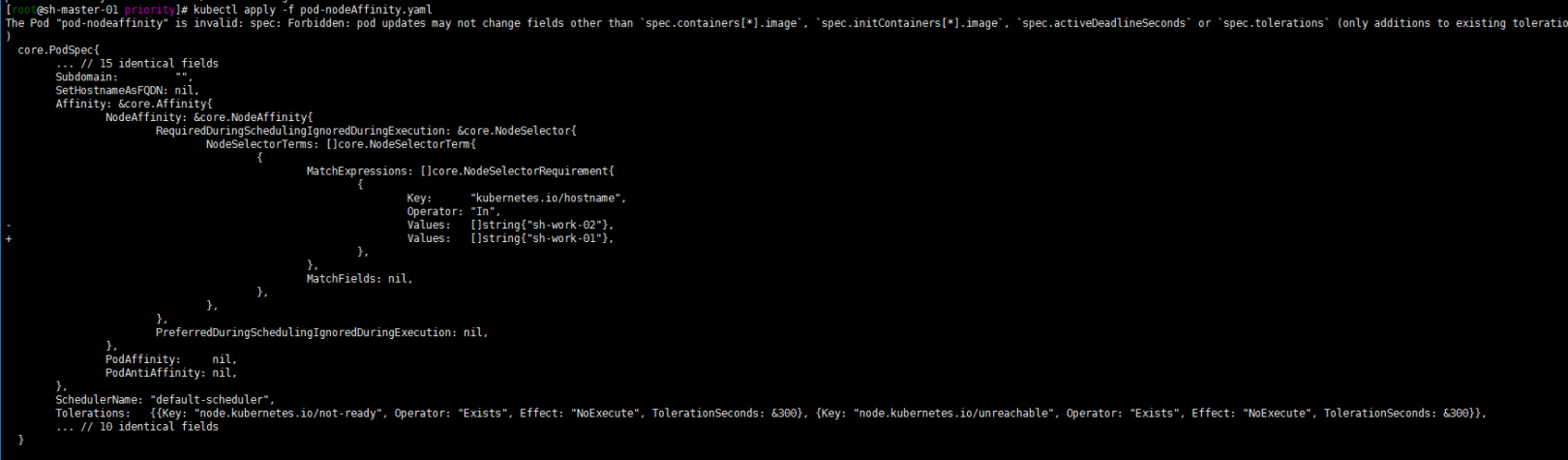
依然如此! 进一步验证了IgnoredDuringExecution的特性!
2.
关于软策略的例子依然是整一个没有的label标签的节点去调度:
cat > pod-prefer.yaml << EOF apiVersion: v1 kind: Pod metadata: name: pod-prefer namespace: default labels: app: myapp type: pod spec: containers: - name: myapp image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80 affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 10 preference: matchExpressions: - key: kubernetes.io/hostname operator: In values: - node01 EOF[root@sh-master-01 priority]# kubectl apply -f pod-prefer.yaml pod/pod-prefer created [root@sh-master-01 priority]# kubectl get pods NAME READY STATUS RESTARTS AGE csi-app 1/1 Running 10 93d nginx 1/1 Running 0 62m php-apache-5b95f8f674-clzn5 1/1 Running 2 86d pod-nodeaffinity 1/1 Running 0 19m pod-prefer 0/1 ContainerCreating 0 3s [root@sh-master-01 priority]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES csi-app 1/1 Running 10 93d 10.0.4.204 sh-work-01 <none> <none> nginx 1/1 Running 0 62m 10.0.4.60 sh-work-01 <none> <none> php-apache-5b95f8f674-clzn5 1/1 Running 2 86d 10.0.3.64 sh-work-03 <none> <none> pod-nodeaffinity 1/1 Running 0 19m 10.0.4.118 sh-work-01 <none> <none> pod-prefer 0/1 ContainerCreating 0 7s <none> sh-work-02 <none> <none>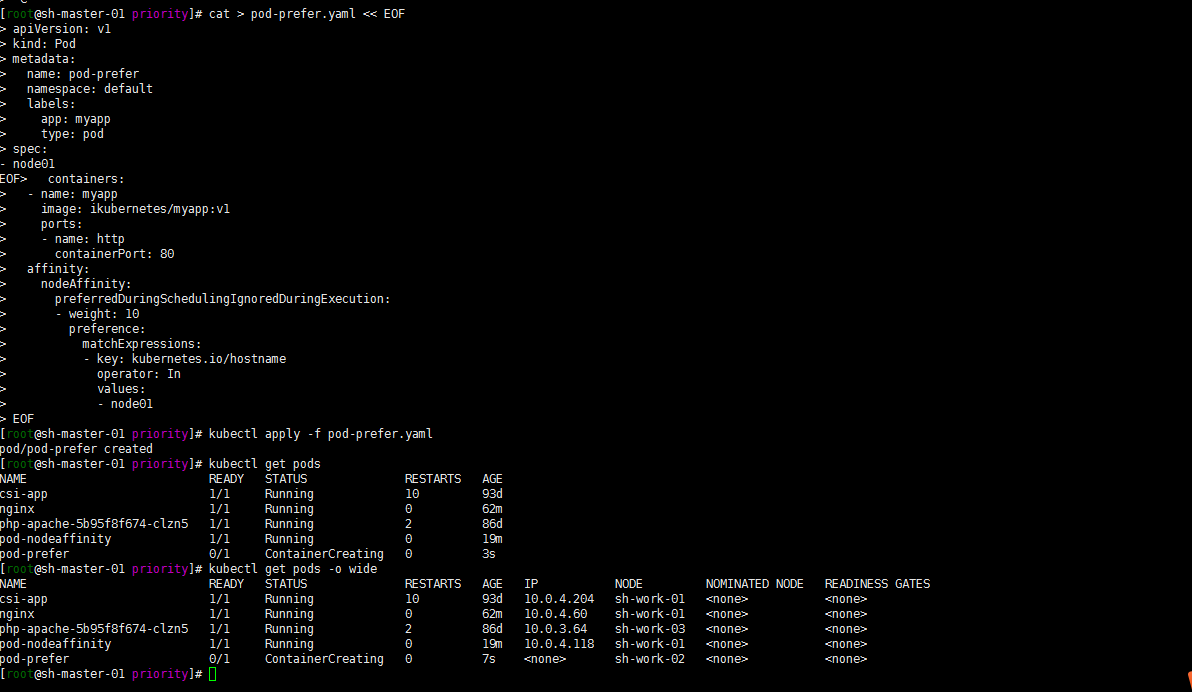
嗯 我是没有label kubernetes.io/hostname:node01节点的。结果他调度到了sh-work-02节点。这算是体现了不强制了吧?
然后再测试一下权重?
cat > pod-prefer1.yaml << EOF apiVersion: v1 kind: Pod metadata: name: pod-prefer1 namespace: default labels: app: myapp1 type: pod spec: containers: - name: myapp1 image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80 affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 10 preference: matchExpressions: - key: kubernetes.io/hostname operator: In values: - sh-work-01 preferredDuringSchedulingIgnoredDuringExecution: - weight: 20 preference: matchExpressions: - key: kubernetes.io/hostname operator: In values: - sh-work-03 EOF[root@sh-master-01 priority]# kubectl apply -f pod-prefer1.yaml pod/pod-prefer1 created [root@sh-master-01 priority]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES csi-app 1/1 Running 10 93d 10.0.4.204 sh-work-01 <none> <none> nginx 1/1 Running 0 67m 10.0.4.60 sh-work-01 <none> <none> php-apache-5b95f8f674-clzn5 1/1 Running 2 86d 10.0.3.64 sh-work-03 <none> <none> pod-nodeaffinity 1/1 Running 0 23m 10.0.4.118 sh-work-01 <none> <none> pod-prefer 1/1 Running 0 4m57s 10.0.5.181 sh-work-02 <none> <none> pod-prefer1 0/1 ContainerCreating 0 6s <none> sh-work-03 <none> <none>嗯基于权重调度到了sh-work-03的节点上了
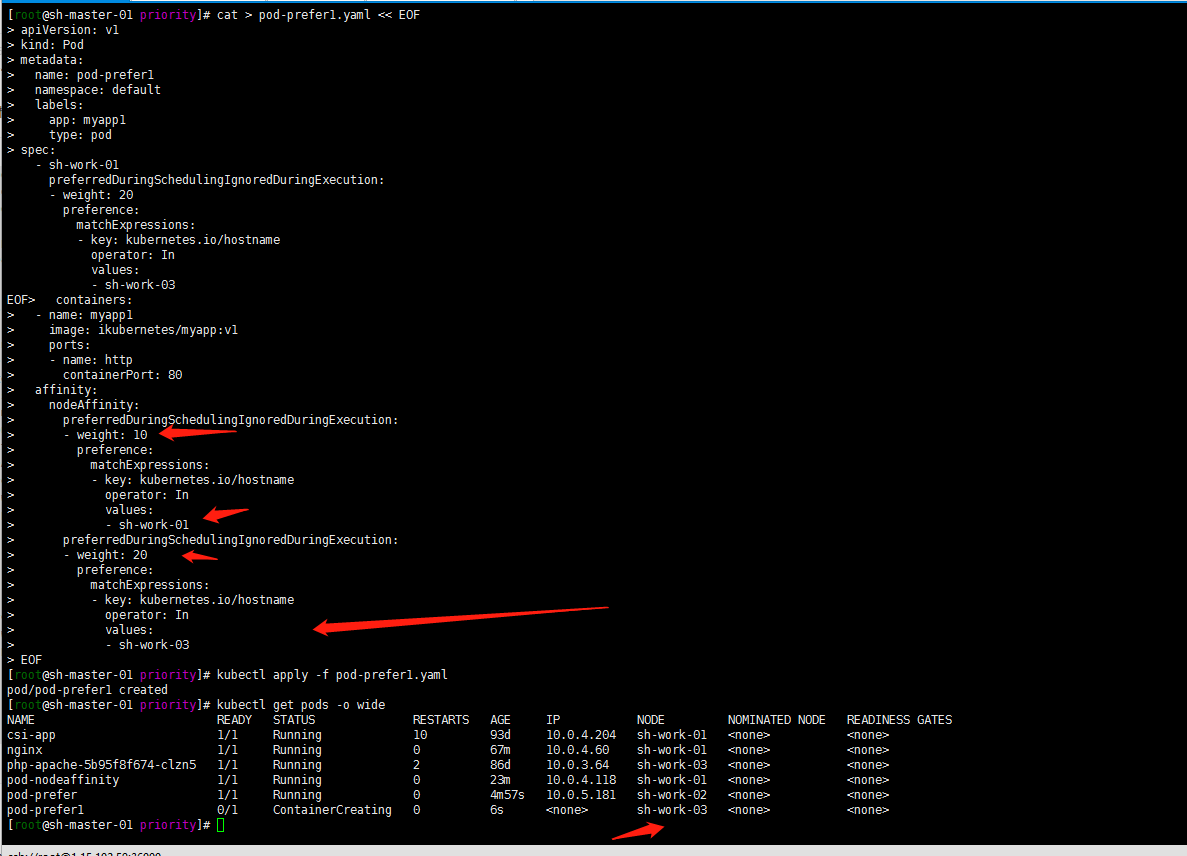
3. 至于软硬策略同时存在呢?
做一个例子同事存在软策略与硬策略
cat > pod-prefer2.yaml << EOF apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - sh-work-01 - sh-work-02 preferredDuringSchedulingIgnoredDuringExecution: - weight: 10 preference: matchExpressions: - key: zone operator: In values: - shanghai containers: - name: with-node-affinity image: k8s.gcr.io/pause:2.0 EOFkubectl apply -f pod-prefer2.yaml kubectl get pods -o wide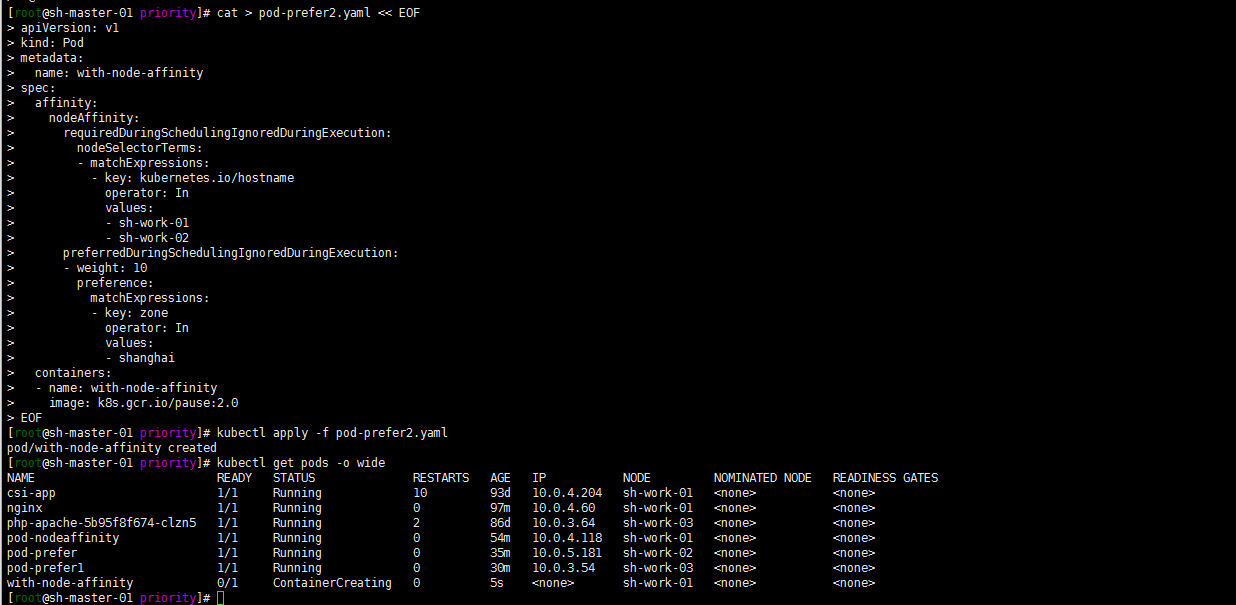
当然了不管preferredDuringSchedulingIgnoredDuringExecution中的值是什么,前提是要先满足requiredDuringSchedulingIgnoredDuringExecution中的values。
3. PodAfinity: Pod亲和性和互斥调度策略
Pod 间亲和性通过 PodSpec 中 affinity 字段下的 podAffinity 字段进行指定。 而 Pod 间反亲和性通过 PodSpec 中 affinity 字段下的 podAntiAffinity 字段进行指定。
主要还是用来让一些频繁调用互相依赖的pod尽可能部署在一台node或者相同区域,还有占用资源的pod互斥,分布在不同的节点或者区域。
举例子:
1.先部署一个带有标签security=S1 app=busybox的Pod
cat > pod-flag.yaml << EOF apiVersion: v1 kind: Pod metadata: name: pod-flag namespace: default labels: app: busybox security: S1 spec: containers: - name: busybox image: busybox:1.28.4 command: - sleep - "3600" imagePullPolicy: IfNotPresent EOFkubectl apply -f pod-flag.yaml kubectl get pods --show-labels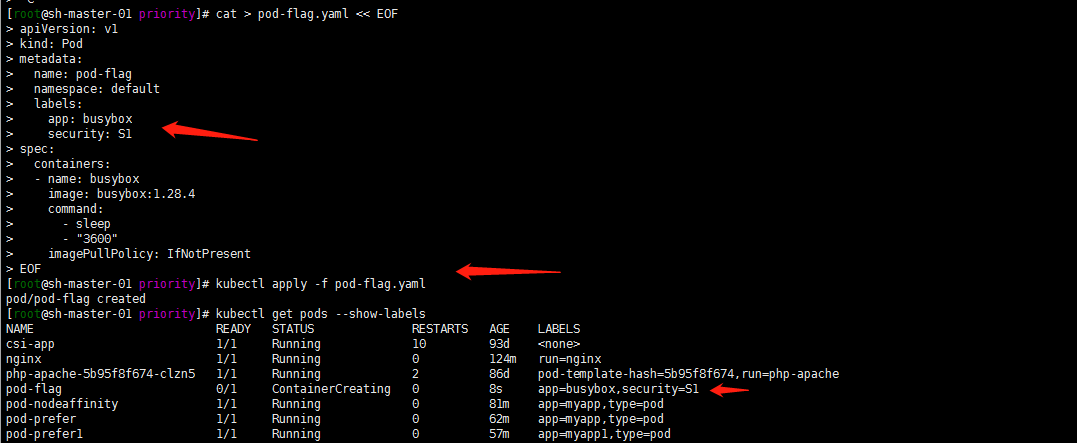
2. Pod 使用 pod 亲和性 的示例:
1. 软策略亲和性
cat > with-pod-affinity.yaml << EOF apiVersion: v1 kind: Pod metadata: name: with-pod-affinity spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: kubernetes.io/hostname containers: - name: with-pod-affinity image: k8s.gcr.io/pause:2.0 EOFkubectl apply -f with-pod-affinity.yaml kubectl get pods -o wide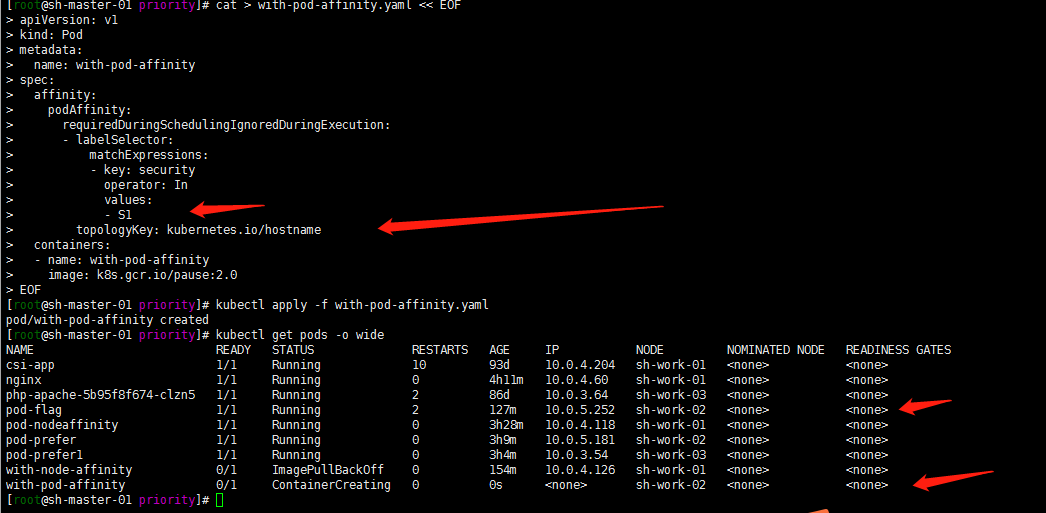
2. 关于topologyKey
顾名思义,topology 就是 拓扑 的意思,这里指的是一个 拓扑域,是指一个范围的概念,比如一个 Node、一个机柜、一个机房或者是一个地区(如杭州、上海)等,实际上对应的还是 Node 上的标签。这里的 topologyKey 对应的是 Node 上的标签的 Key(没有Value),可以看出,其实 topologyKey 就是用于筛选 Node 的。通过这种方式,我们就可以将各个 Pod 进行跨集群、跨机房、跨地区的调度了。没有搞多个区域zone就一个我这里现在。
原文链接:https://blog.csdn.net/asdfsadfasdfsa/article/details/106027367
3. 硬策略亲和性
强制要求
cat > with-pod-affinity1.yaml << EOF apiVersion: v1 kind: Pod metadata: name: with-pod-affinity1 spec: affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: kubernetes.io/hostname containers: - name: with-pod-affinity1 image: k8s.gcr.io/pause:2.0 EOF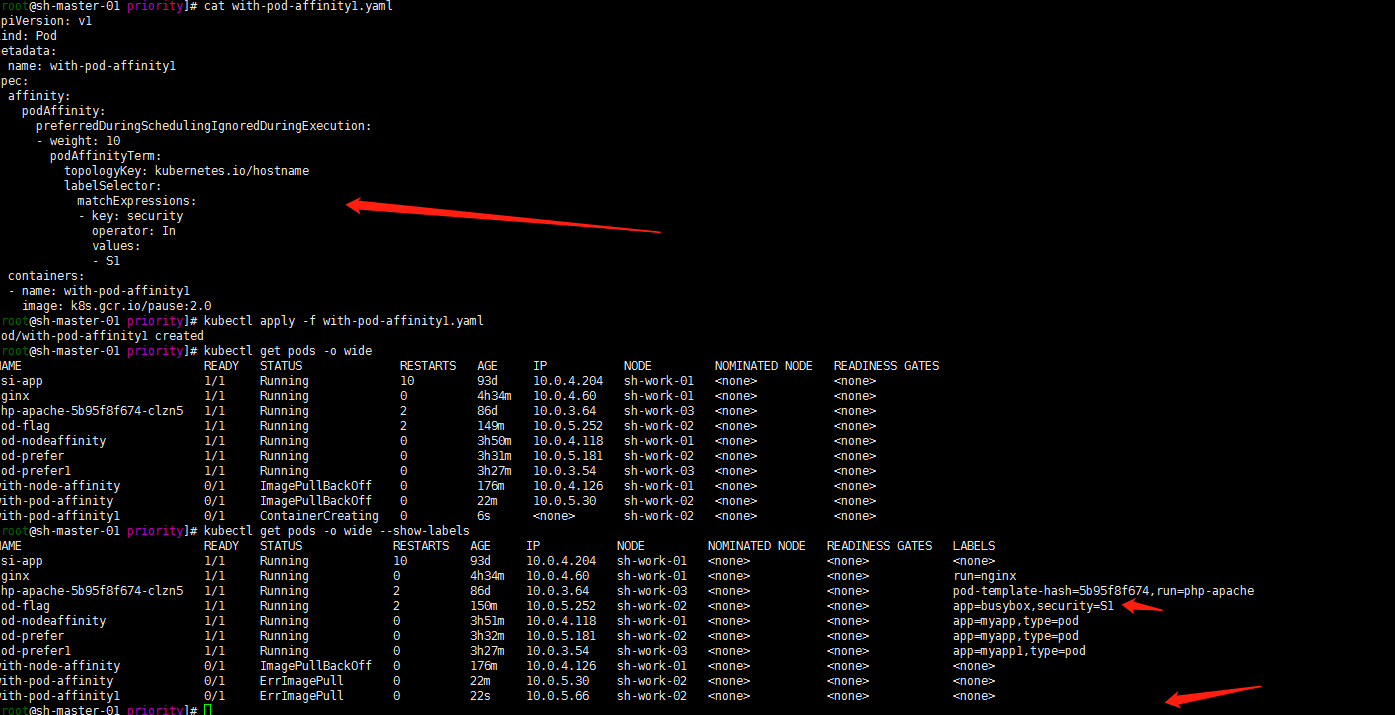
ErrImagePull忽略,用的官方例子没有改镜像image。正常的用nginx image就好了。
3. Pod的互斥性调度
Pod与security=S1处于同一个zone,不与app=busybox的 pod在同一个Node:
cat > with-pod-antiaffinity.yaml << EOF apiVersion: v1 kind: Pod metadata: name: with-pod-antiaffinity spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: topology.com.tencent.cloud.csi.cbs/zone podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - busybox topologyKey: kubernetes.io/hostname containers: - name: with-pod-antiaffinity image: nginx EOFkubectl apply -f with-pod-antiaffinity.yaml kubectl get pods -o wide --show-labels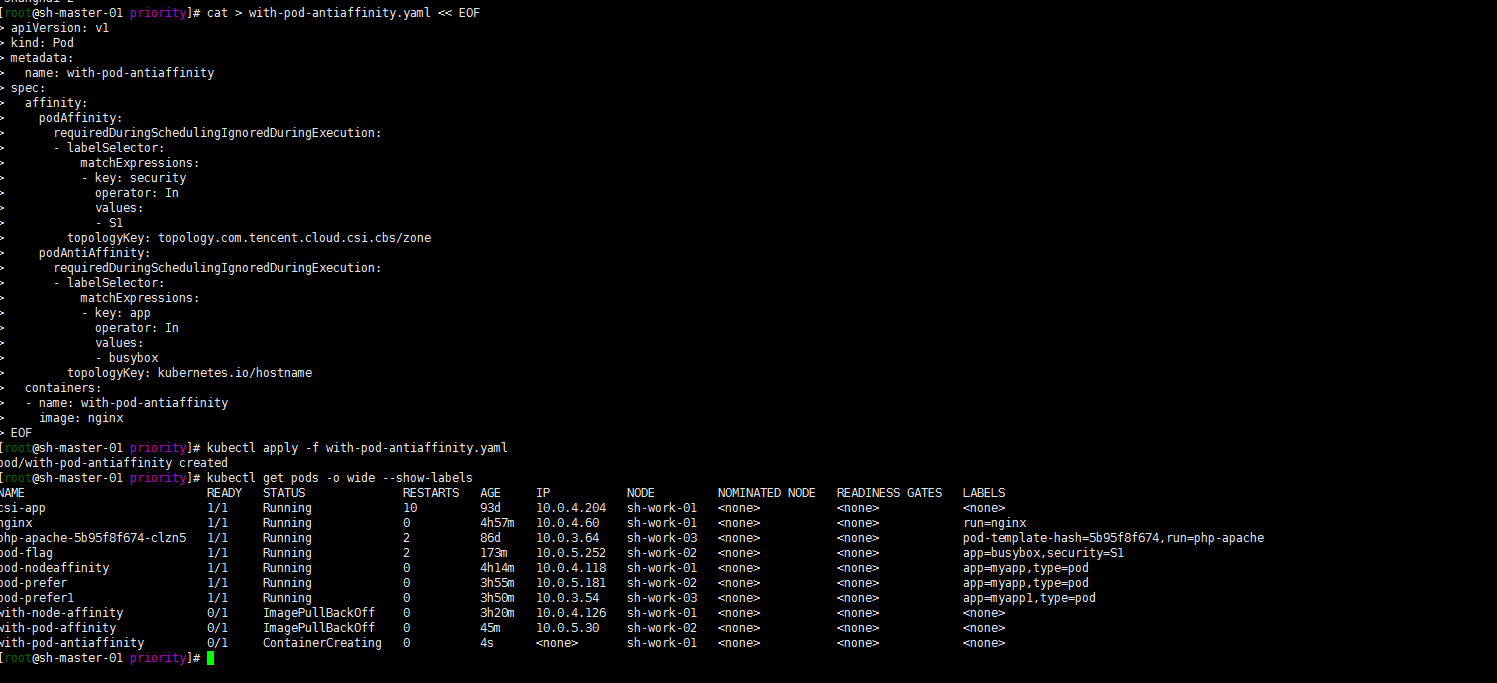
嗯 pod调度到了 sh-work-02之外的节点,这个地方还是有点绕,有时间再好好研究一下
4. Taints and Tolerations污点和容忍
1. 集群信息
[root@sh-master-01 priority]# kubectl get node NAME STATUS ROLES AGE VERSION sh-master-01 Ready control-plane,master 93d v1.21.1 sh-master-02 Ready control-plane,master 93d v1.21.1 sh-master-03 Ready control-plane,master 93d v1.21.1 sh-work-01 Ready <none> 93d v1.21.1 sh-work-02 Ready <none> 93d v1.21.1 sh-work-03 Ready <none> 93d v1.21.1 test-01 Ready,SchedulingDisabled <none> 86d v1.21.02.给sh-work-01节点打上污点(key=work、value=ops、effect=NoSchedule)
kubectl taint nodes sh-work-01 work=ops:NoSchedule3. 整一个daemonset做测试吧 比较直观
cat > nginx-daemonset.yaml << EOF apiVersion: apps/v1 kind: DaemonSet metadata: name: nginx-1 namespace: default labels: web: nginx-1 spec: selector: matchLabels: web: nginx-1 template: metadata: labels: web: nginx-1 spec: containers: - name: nginx-1 image: nginx:1.17 ports: - containerPort: 80 EOFkubectl apply -f nginx-daemonset.yaml kubectl get pods -o wide --show-labels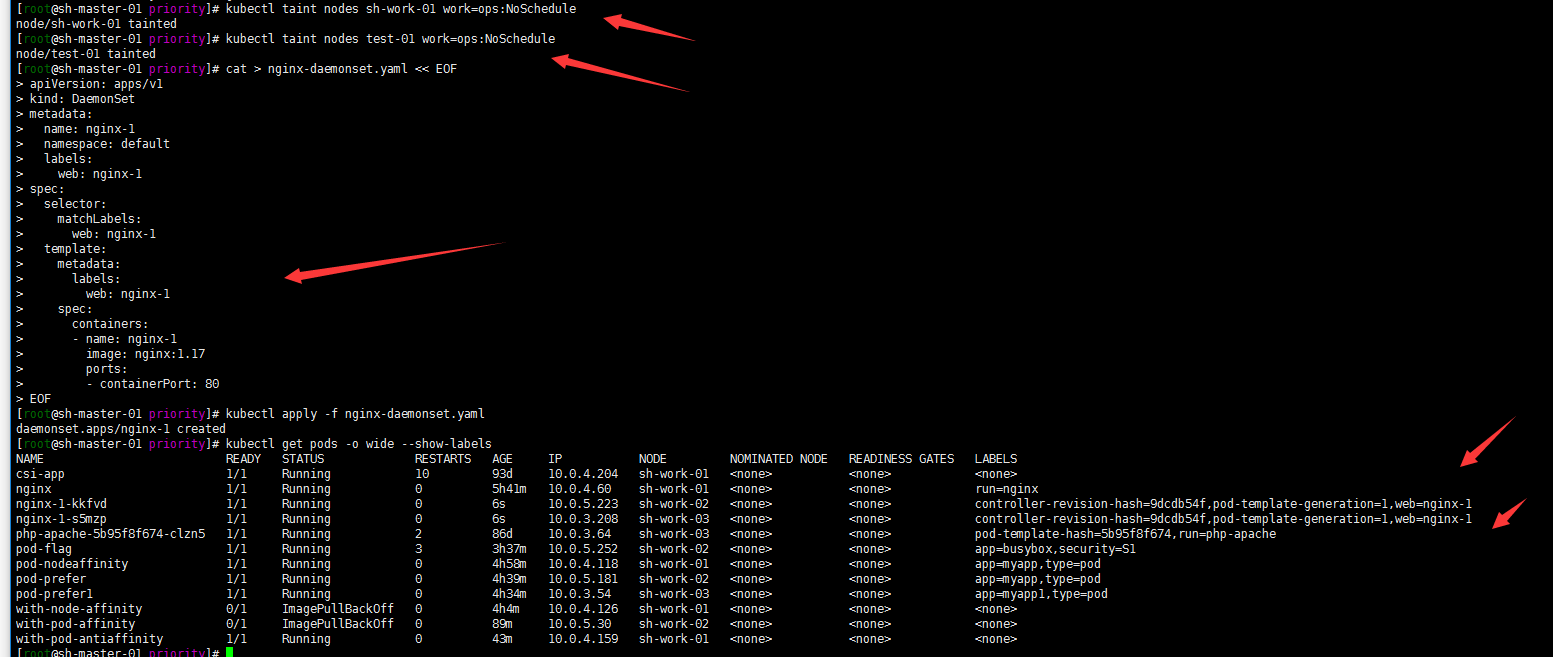
注: 我将test-01节点加上污点是因为我这个node是SchedulingDisabled的其实。但是daemonset也是会部署到IE点上去为了方便区分。
移除sh-work-01的污点看一下会发生什么:
[root@sh-master-01 priority]# kubectl taint nodes sh-work-01 work:NoSchedule- node/sh-work-01 untainted [root@sh-master-01 priority]# kubectl get pods -o wide --show-labels
嗯 去掉sh-work-01节点的污点标签。节点就恢复调度了。
4. 增加容忍度参数,进行测试
cat > nginx-daemonset-2.yaml << EOF apiVersion: apps/v1 kind: DaemonSet metadata: name: nginx-2 namespace: default labels: web: nginx-2 spec: selector: matchLabels: web: nginx-2 template: metadata: labels: web: nginx-2 spec: containers: - name: nginx-2 image: nginx:1.17 ports: - containerPort: 80 tolerations: - key: "work" operator: "Equal" value: "ops" effect: "NoSchedule" EOFkubectl apply -f nginx-daemonset-2.yaml kubectl get pods -o wide --show-labels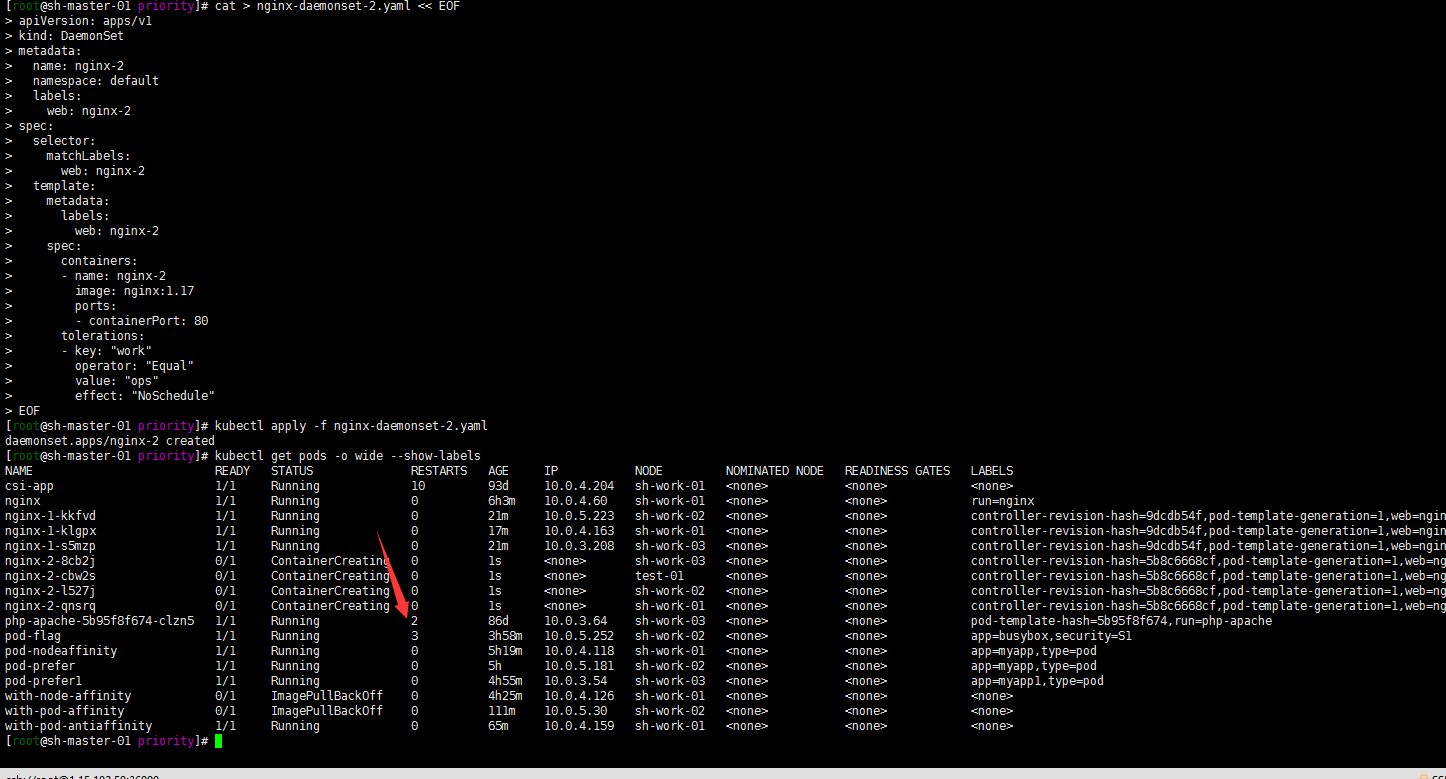
嗯污点节点都被调度了,包括test-01节点。这里在给test-01节点加个其他污点?反正就是不想让他被调度:
kubectl taint nodes test-01 work1=dev:NoScheduletest-01节点中的pod仍未被驱逐
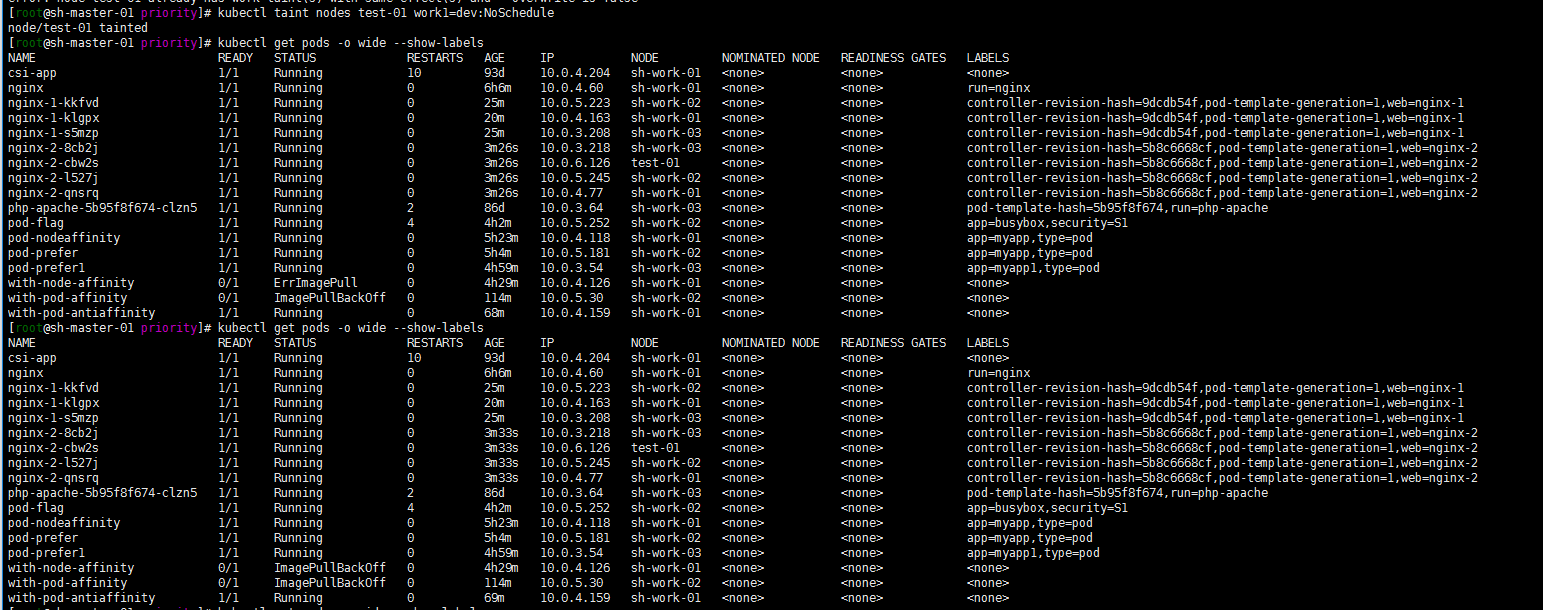
修改下work=ops的标签要不然?
kubectl taint nodes test-01 work=dev:NoSchedule --overwrite=true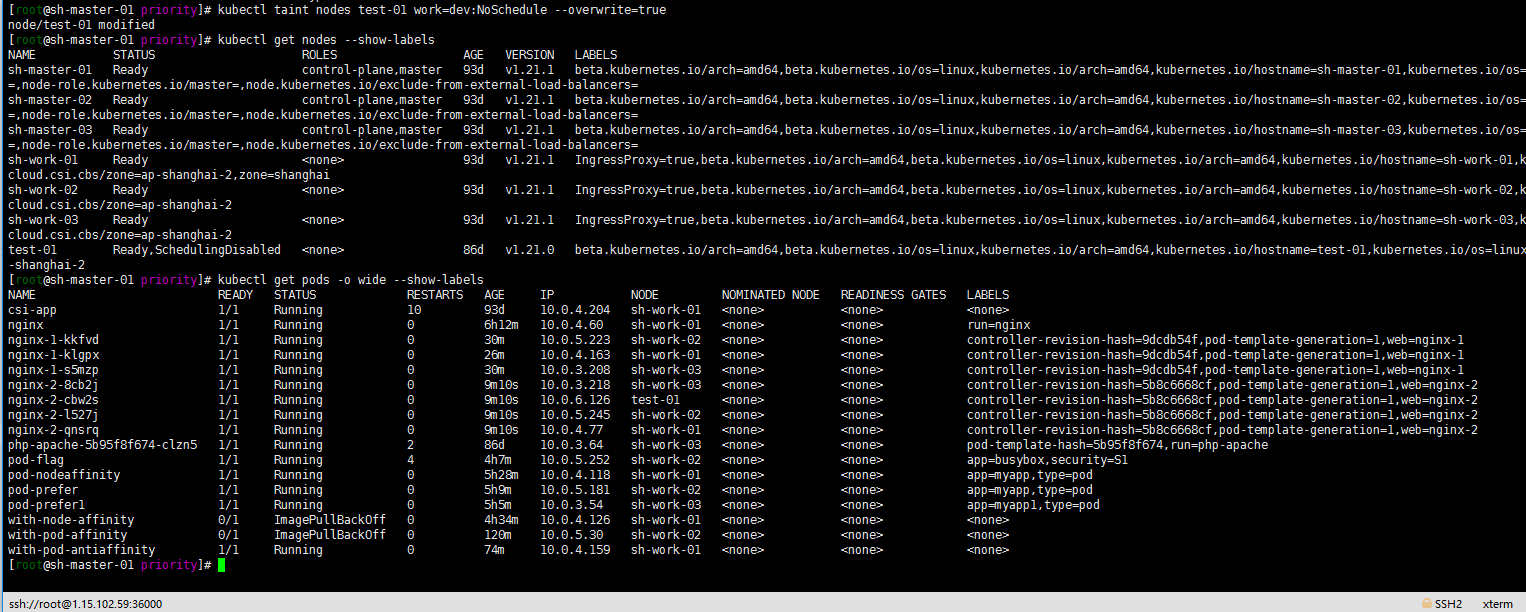
还是一样。
该怎么搞呢?
5. 修改test-01节点的污点,将effect修改为”NoExecute”,测试Pod是否会被驱逐
kubectl taint nodes test-01 work=dev:NoExecute --overwrite=true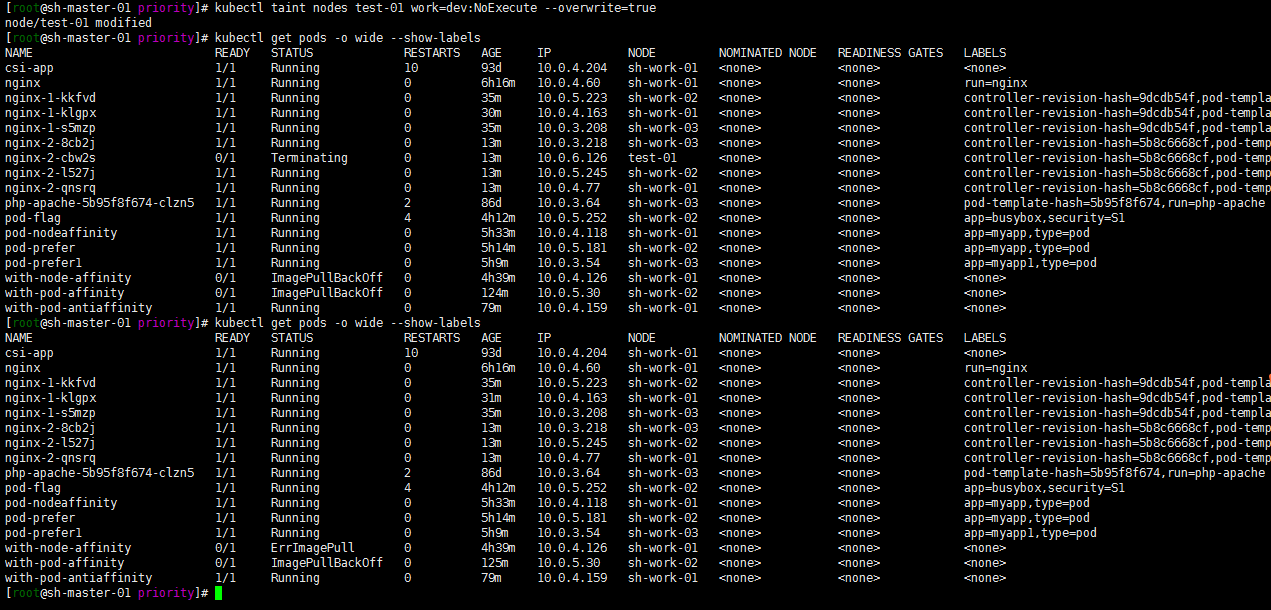
驱逐成功了……
关于Taints and Tolerations可以参照:https://www.jianjiacc.cn/archives/6fdbe877.html
总结一下:
- 创建集群应该进行合理的资源规划,对容量进行规划
- 可以根据pod的 qos进行资源的优先调度以及资源分配(当然了还是会有pod OOM)
- 可以通过节点打标签 亲和性反亲和性对资源进行合理调度,以免造成集群资源雪崩
- 不同kubernetes版本直接还是有些许的区别的,尽量还官方看文档吧!
-
2021-06-23-Kubernetes java程序无法使用jmap jstack的解决方案
背景:
基础环境centos8+kubeadm1.20.5+cilium+hubble环境搭建,线上主要跑的php nodejs java的环境。
java的pod昨天频繁出现了cpu 90%的占用率告警:
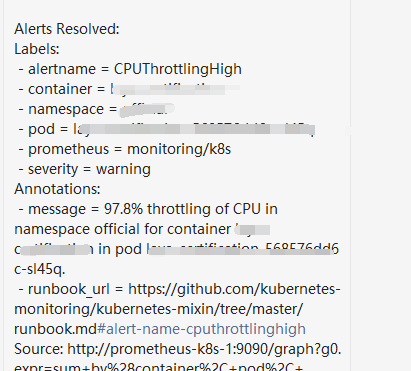
虽然cpu是可压缩资源(compressible resources ),应用只会饥饿,不会像是内存爆了一样OOM.但是也需要进行一下性能分析,看一眼是代码逻辑有问题,还是资源分配的大小不合理。
就想传统的方式进入容器查看pid,运行jstack命令进行分析了:
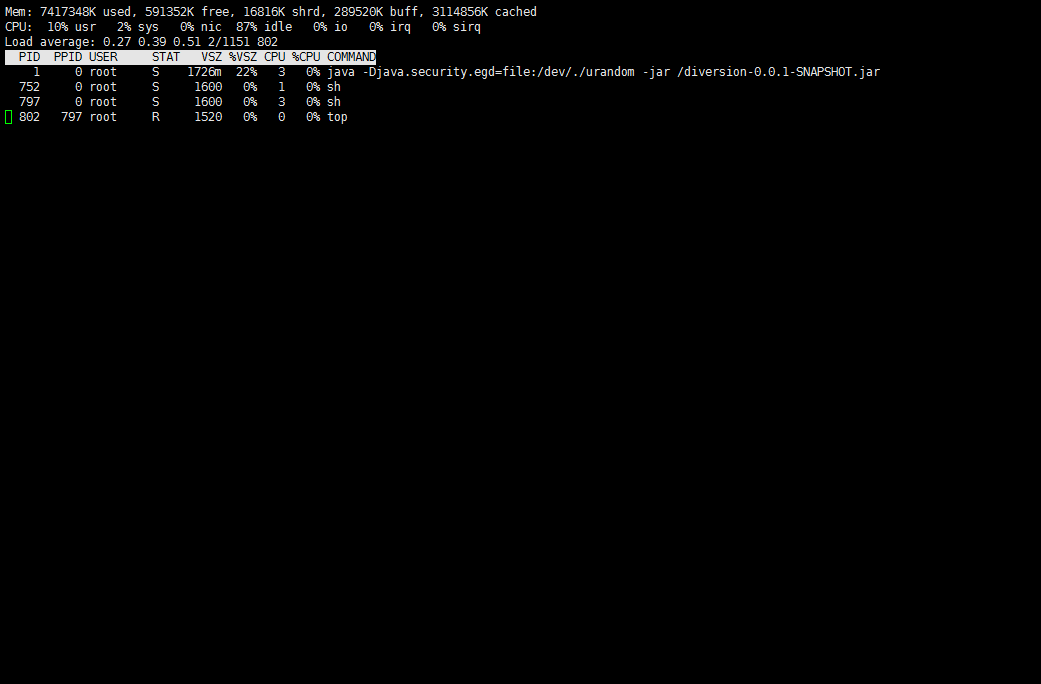
kubectl exec -it xxx-xxxx-8556c7f98b-9nh28 sh -n official / # ps PID USER TIME COMMAND 1 root 2h38 java -Djava.security.egd=file:/dev/./urandom -jar /xxx-1.0-SNAPSHOT.jar 4178 root 0:00 sh 4193 root 0:00 ps / # jstack 1 1: Unable to get pid of LinuxThreads manager threadwhat jstack命令无法分析应用……
解决过程:
百度搜索了一下,参见:
https://blog.csdn.net/qq_16887777/article/details/107417059
1. 关于pid1
发现服务的pid=1,网上查询得知pid1-5为Linux的特殊进程。
pid=1 :init进程,系统启动的第一个用户级进程,是所有其它进程的父进程,引导用户空间服务。
pid=2 :kthreadd:用于内核线程管理。
pid=3 :migration,用于进程在不同的CPU间迁移。
pid=4 :ksoftirqd,内核里的软中断守护线程,用于在系统空闲时定时处理软中断事务。
pid=5 :watchdog,此进程是看门狗进程,用于监听内核异常。当系统出现宕机,可以利用watchdog进程将宕机时的一些堆栈信息写入指定文件,用于事后分析宕机的原因。
根据排除法最简单的方式就是让java启动的进程pid不是1-5就可以了?嗯启动命令不是第一个。
2. 修改Dcokerfile java启动方式
上下我的Dockerfile
FROM openjdk:8-jdk-alpine VOLUME /tmp ENV TZ=Asia/Shanghai RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone ADD target/diversion-0.0.1-SNAPSHOT.jar diversion-0.0.1-SNAPSHOT.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/xxxx-0.0.1-SNAPSHOT.jar"]嗯个人认为可以将 java 启动文件写入脚本?然后ENTRYPOINT sh脚本?偶然看到一个tini的方法:docker运行java程序 使用jmap,jstack命令 tini运行的程序获取进程.修改Dockerfile如下:
FROM openjdk:8-jdk-alpine VOLUME /tmp ENV TZ=Asia/Shanghai RUN apk add --no-cache tini RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone ADD target/diversion-0.0.1-SNAPSHOT.jar diversion-0.0.1-SNAPSHOT.jar ENTRYPOINT ["tini","java","-Djava.security.egd=file:/dev/./urandom","-jar","/xxxx-0.0.1-SNAPSHOT.jar"]3. 构建并上传镜像到镜像仓库
docker build -t ccr.ccs.tencentyun.com/xxxx/xxxx:xxxx docker push ccr.ccs.tencentyun.com/xxxx/xxxx:xxxx4. 部署应用并测试
cat > test.yaml << EOF apiVersion: apps/v1 kind: Deployment metadata: name: test spec: replicas: 1 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 0 selector: matchLabels: app: test template: metadata: labels: app: test spec: containers: - name: test image: ccr.ccs.tencentyun.com/xxxx/xxxx:xxxx env: - name: SPRING_PROFILES_ACTIVE value: "official" ports: - containerPort: test resources: requests: memory: "256M" cpu: "250m" limits: memory: "1024M" cpu: "500m" imagePullSecrets: - name: tencent --- apiVersion: v1 kind: Service metadata: name: test labels: app: test spec: ports: - port: 8081 protocol: TCP targetPort: 8081 selector: app: test EOFkubectl apply -f test.yaml -n test kubectl exec -it xxxxxxx sh -n test top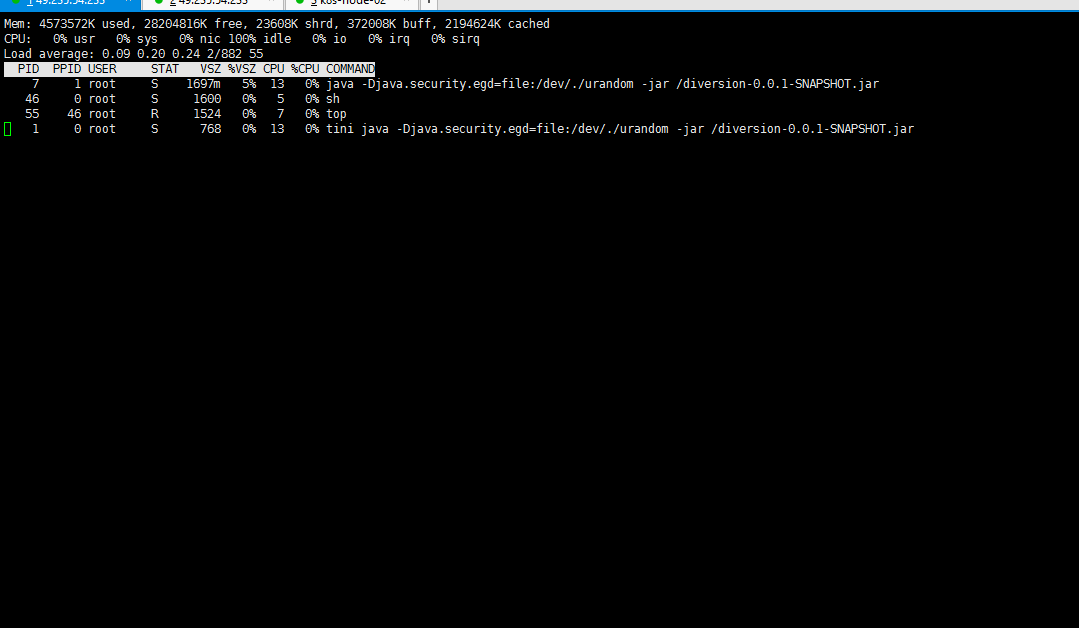
可以看到进程号是1的进程是tini的 有额外一个单独的进程号为7的java 进程,运行jstack进行测试:
jstack 7
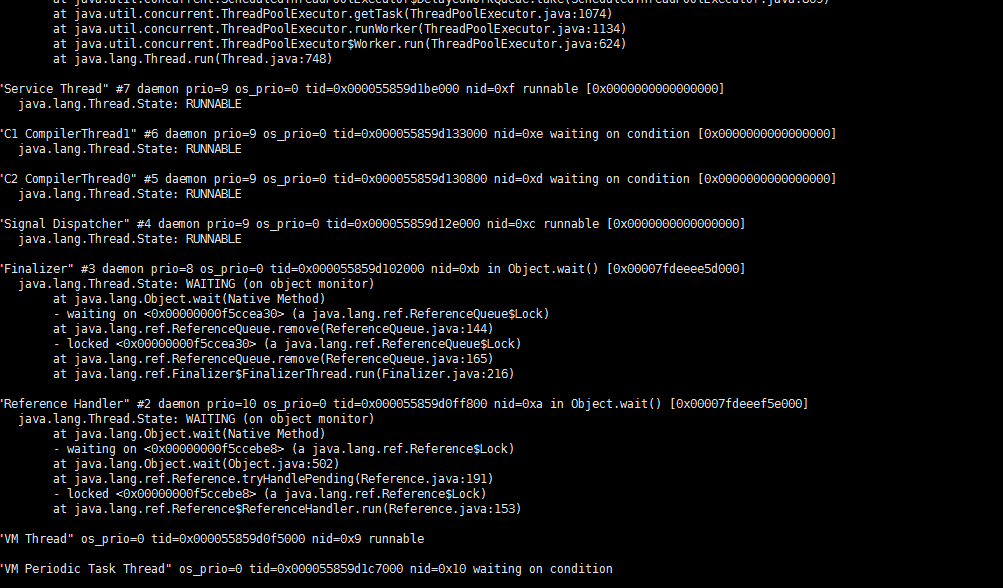
嗯能运行jstack就算是实现了自己需要的了。其他的先忽略。
总结:
1. 关于linux的pid
2. tini的命令,可参照https://zhuanlan.zhihu.com/p/59796137
3. docker的启动方式与进程隔离实现方式
-
2021-06-22-Kubernetes traefik tls证书到期替换
背景:
ssl证书都是一年签发的。到了六月份了一年一度的证书替换的日子到了…….。过去的方法一直都是先delete secret,然后继续创建一个新的。这次就突发奇想的,还有其他方法吗……百度了一下还真的搜索到了:
https://blog.csdn.net/cyxinda/article/details/107854881
我的证书是在腾讯云上面购买的 TrustAsia 域名型(DV)通配符(1 年)的 ssl证书。
考虑到成本毕竟申请的dv的泛域名证书。关于dv ov证书的区别:
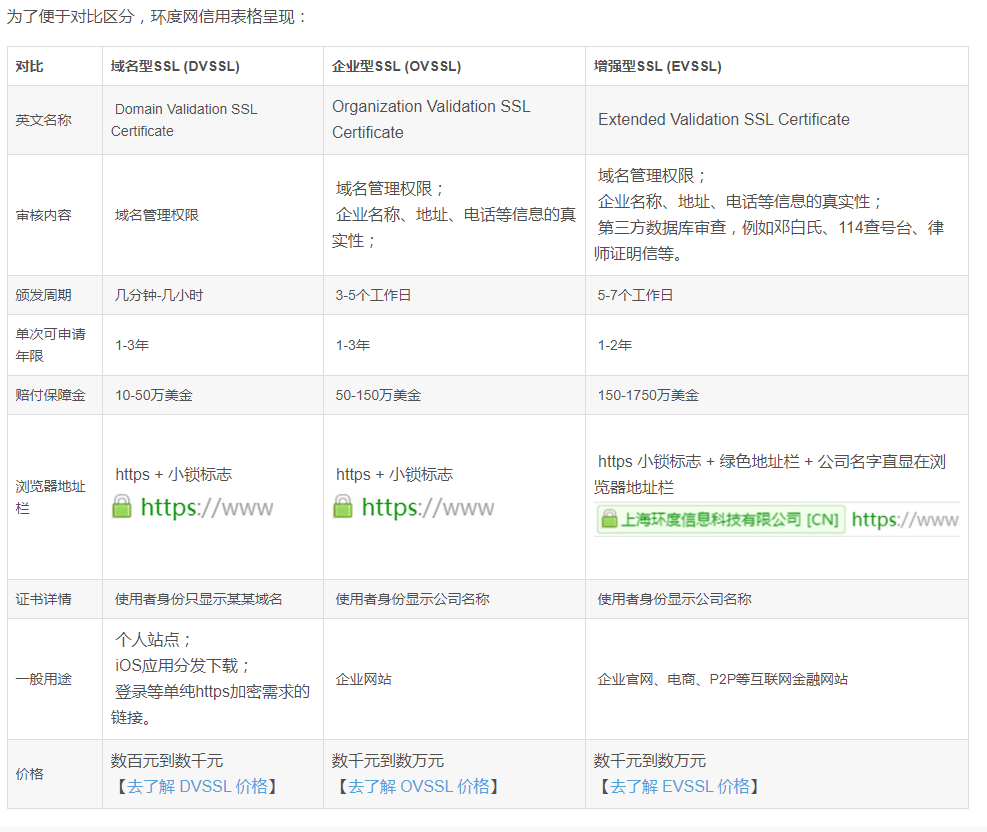
此图片来源于网络关于secret tls的创建方式
关于secret可以参照https://kubernetes.io/zh/docs/concepts/configuration/secret/。kubernetes官方文档。这里就直接创建一下tls secret 了
在腾讯云平台ssl管理页面https://console.cloud.tencent.com/ssl
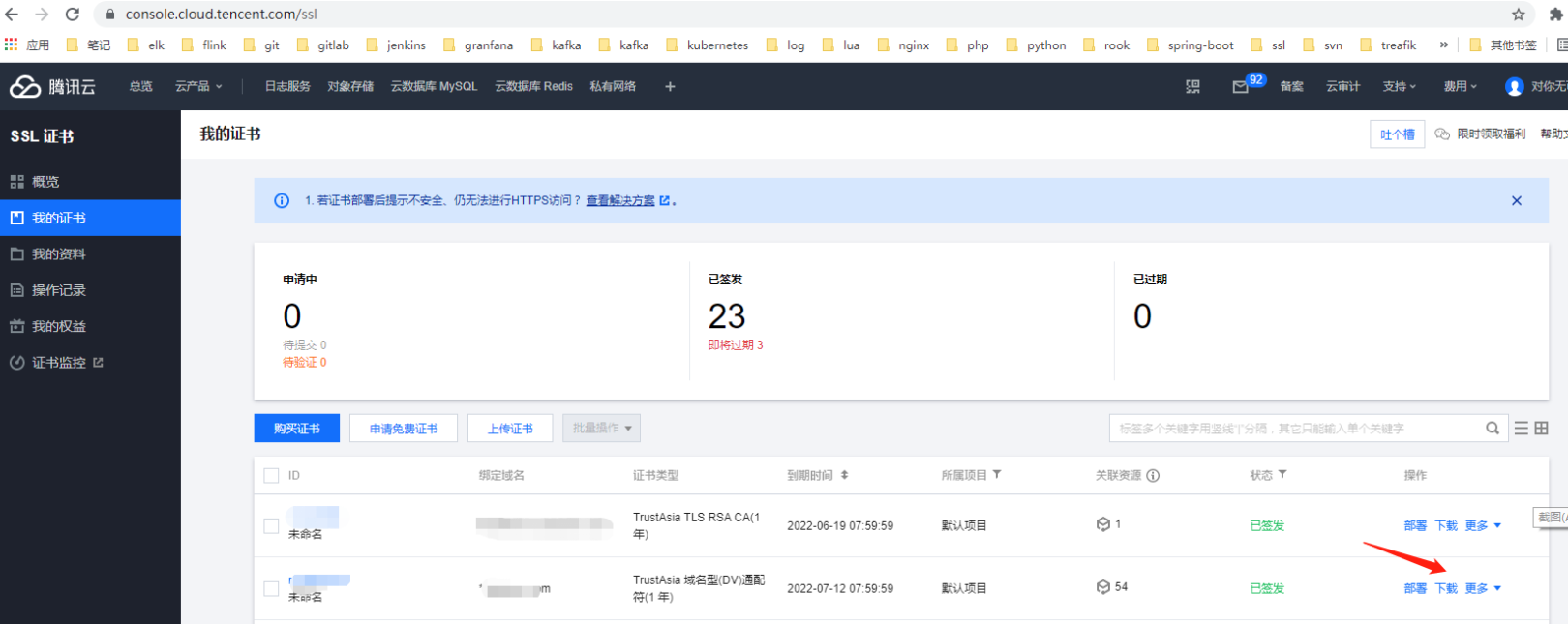
找到相关证书并点击下载将证书下载到本地。
将证书上传到服务器,并解压zip文件。解压后的文件列表如下
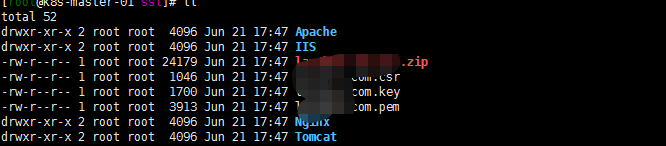
我是直接进入Nginx文件夹,文件列表如下:

当然了 其他平台申请的证书可能不是这样的(记得阿里云的不是这样的来,可以openssl 转一下吧?)
kubectl create secret tls all-xxx-com --key=2_xxx.com.key --cert=1_xxx.com_bundle.crt -n mastertraefik中应用使用证书可以参照:traefik2 安装实现 http https,2019-12-27-traefik.下面进入正题切换修改到期证书…
注:以下参考了https://blog.csdn.net/cyxinda/article/details/107854881
几种更换kubernetes中tls证书的方式:
1.删除再重建
这应该是最常见的…反正我过去是经常用
kubectl delete secret all-xxx.com -n master kubectl create secret tls all-xxx-com --key=2_xxx.com.key --cert=1_xxx.com_bundle.crt -n master2. 通过–dry-run参数预览,然后apply
kubectl create secret tls all-xxx-com --key=2_xxx.com.key --cert=1_xxx.com_bundle.crt -n master --dry-run -o yaml |kubectl apply -f -算是复习了一下–dry-run的命令。也比较优雅。通过apply更新 secret。
3. 我可不可以edit 修改一下 secret中秘钥的内容
kubectl edit secret all-xxxcom -n master
base64 1_xxx.com_bundle.crt得到的内容将secret tls.crt中内容替换 base64 2_xxx.com.key得到的内容将secret中的tls.key的内容替换4. 更优雅的方式:

个人来说倾向于第二种方式还是……
总结一下:
- 删除重建是最笨的方式,当然了不会其他方式也可以用这种方式。在删除新建secret的空窗期,是存在风险的
- kubernetes api可以通过json或者yaml文件对元数据进行更新或者交互
- –dry-run 的参数还是很有用的
- secret还是基于namespace。同一个secret在好多命名空间都有同样的存在,有没有较为方便的管理方式呢?
-
2021-06-18-Kubernetes部署php 应用时候memory_limit的修改
背景:
基础环境:centos8+kubeadm1.20.5+cilium+hubble环境搭建,traefik提供对外服务:Kubernetes 1.20.5 安装traefik在腾讯云下的实践。跑了几个基础的php服务。基础镜像是参考的https://github.com/richarvey/nginx-php-fpm搭建。然后php报错:Allowed memory size of 134217728 bytes exhausted (tried to allocate 6291488 bytes)临时需要调整个参数。不想重新打镜像啊。咋整?
1. 问题复查与解决:
1. 找出引发报错的配置项
首先分析一下报错:Allowed memory size of 134217728 bytes exhausted (tried to allocate 6291488 bytes)
仔细看了一眼上面的数字嗯。限制应该是128M。php运行的脚本需要使用134M的资源超了?
先进入容器瞄一眼,看看这可能是哪个参数:
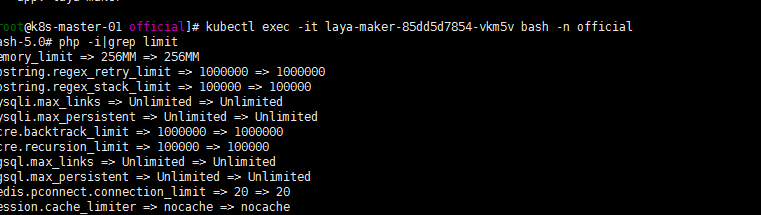
php -i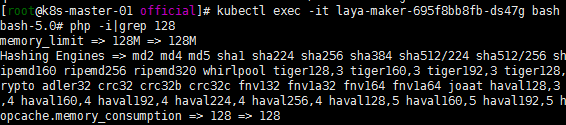
初步来看是memory_limit 这个参数限制了128M
2.深入了解配置项参数设置与含义
仔细解读了一下memory_limit这个参数:
一个PHP工作进程即php-fpm所能够使用的最大内存?

然后:
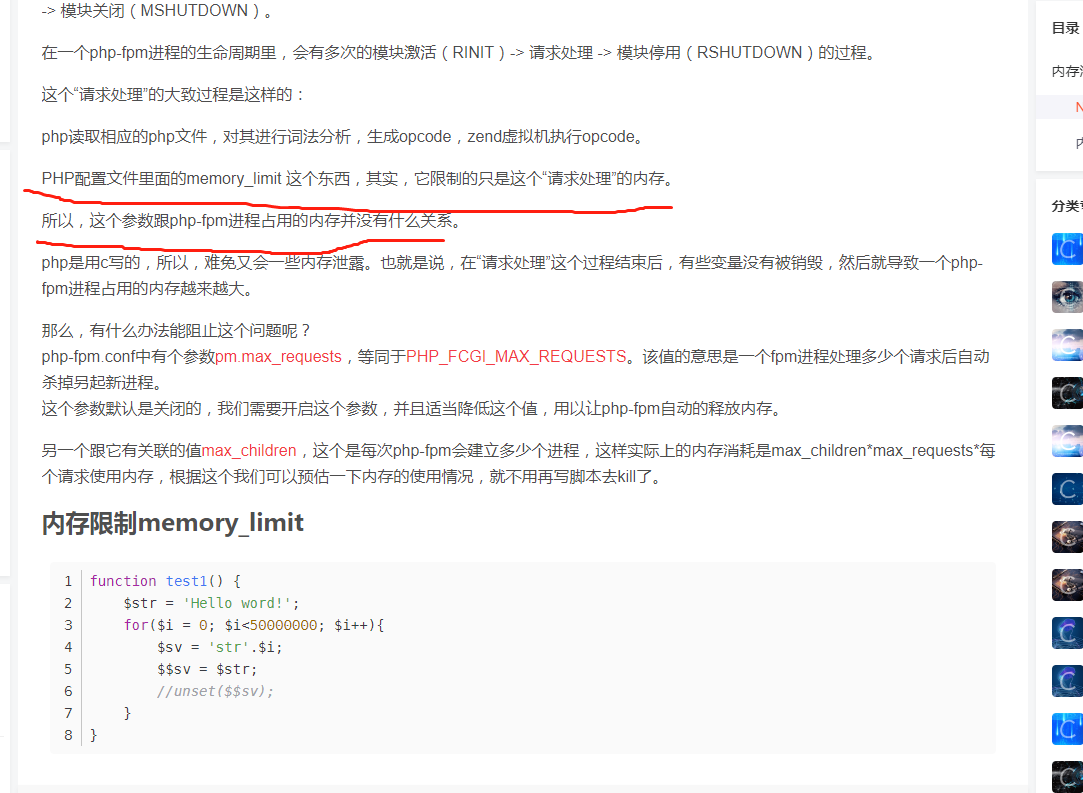
两个感觉说的都不是一会事情啊?
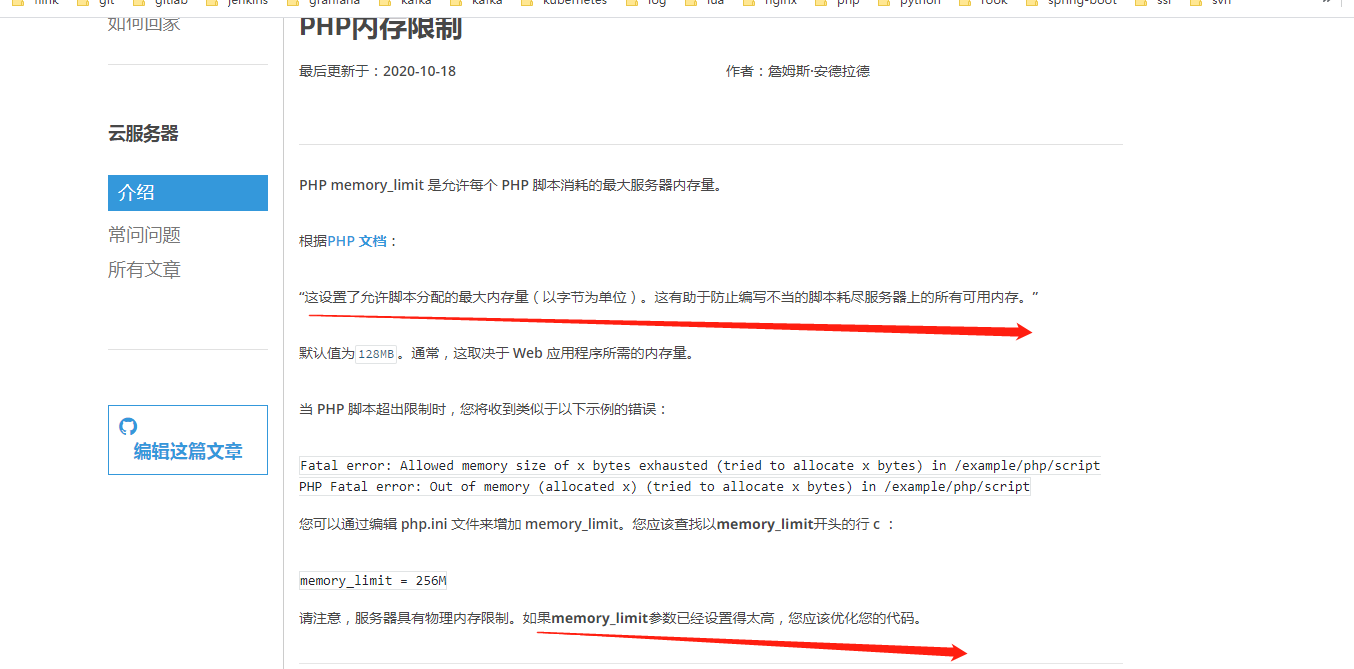
参照:https://docs.rackspace.com/support/how-to/php-memory-limit/
先不去纠结它了。反正就先这样理解了:

防止写得不好的脚本吃掉服务器上所有可用的内存
3. 如何修改参数并验证其是否生效
开始memory_limit这个参数设置的是128M既然不够了,那就先扩一下?
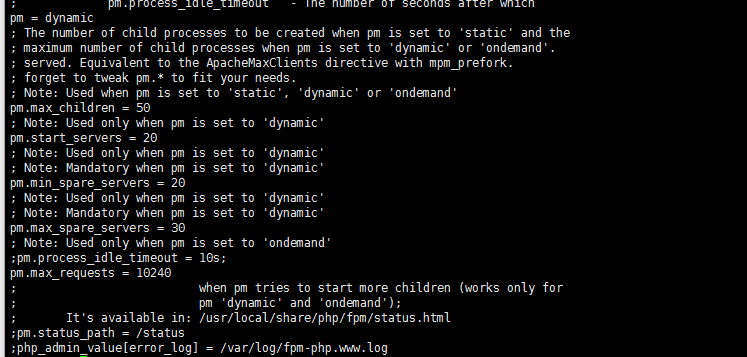
查看了下dockerfile这个参数是在start.sh启动脚本中将参数设置为128M的:

那我现在要么把start.sh脚本进行修改?or 我可不可以设置一下环境变量?
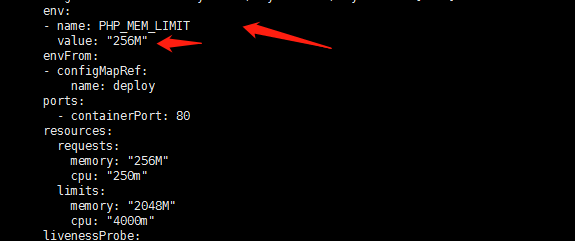
尝试了一下修改yaml文件并重新部署服务,验证如下:
ok生效了。环境变量的优先级是大于启动脚本中的变量的? 我是否可以这样理解?
复盘:
- memory_limit这个参数如何设置合适的范围?我觉得我设置为256M这个参数略大。
- 这个参数设置大后我的并发线程怎么控制….。我的这些资源会不会不够?引起各种的崩溃?先把 我容器的内存先扩大一下呢。
- 其实还是觉得是php脚本写的太烂吃掉了内存……就相对比较简单的服务。能吃掉那么多内存也是神了。只能让他们找下问题,优化一下脚本。
- 主要是觉得活学活用还的。能用变量的尽量去用变量去做各种配置。避免重复构建基础镜像。
-
2021-06-11-关于gitlab developer用户无法push的问题
背景:
参见Kubernetes 1.20.5 安装gitlab,搭建了gitlab也都是自己玩的,也没有添加什么新的用户。线上跑的有个老的8.5.8的版本貌似?一直也没有升级,跑了好些年了。昨天有个新的项目组要创建一个项目。so group repository创建完成教了一下小伙伴的一般使用方式就跑路了。
今天早上group中Developer用户的小伙伴用小乌龟的客户端clone项目后add添加后无法push?
what?我特意试了一下。我的客户端是用的GitHub Desktop客户端。试着add push了一下 发现没有问题啊……
看了下小伙伴的客户端上传的时候依然显示master分支,记得去年某些运动的时候 都改成main了啊 不会是这样的问题吧。尝试了一下排除……
解决问题:
1 . 解决gitlab developer用户无法push的问题
仔细研读了一下gitlab的权限设计,也仔细想了一下:developer怎么能把文件推送到master(main)分支呢?这本来就不应该是一个正常的方向。master(main)主分支的合并应该是master的权限!
鉴于大家都水开发,为了方便,百度了一下解决方案:
是有好多这样的问题。但是我的gitlab版本是1.13.7来吧?貌似都有点不对头,依着葫芦画瓢找了下,总算找到了相关配置:
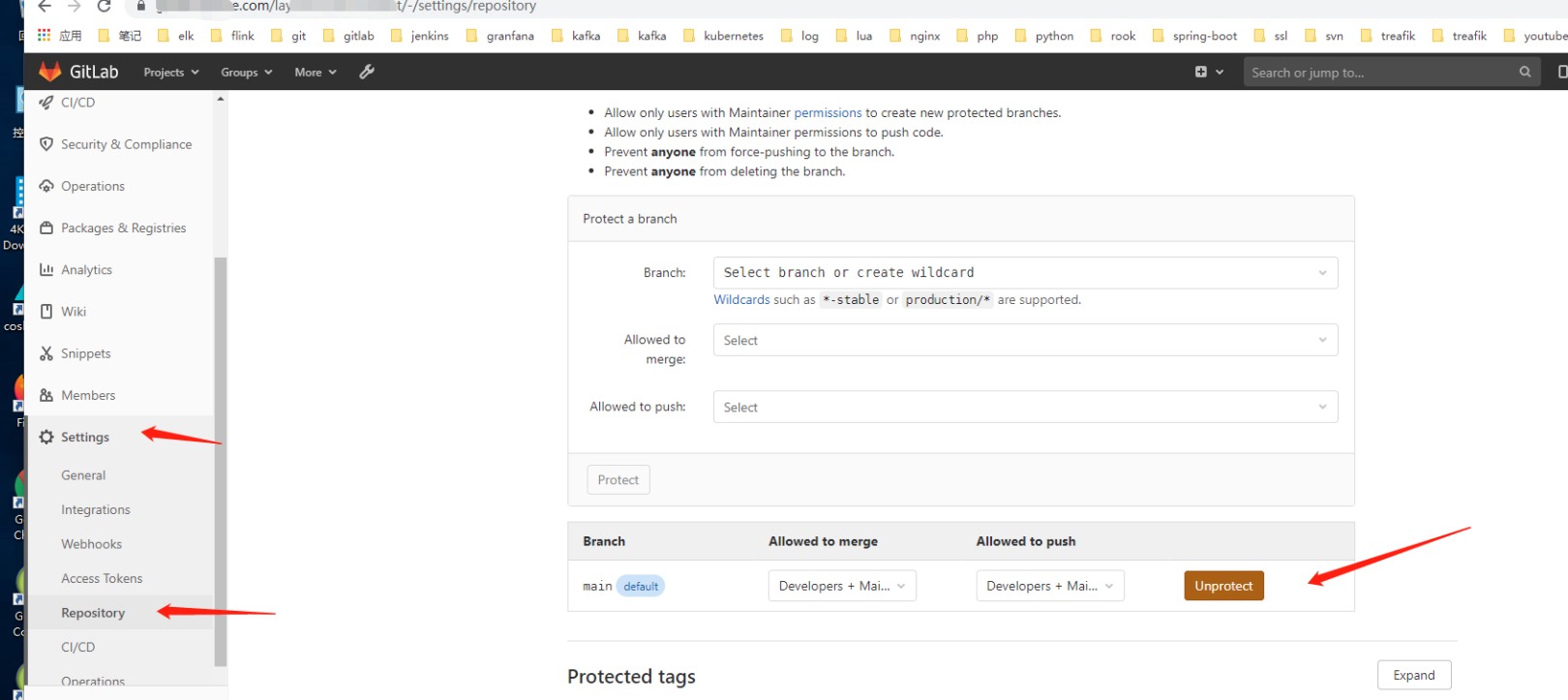
让小伙伴试了下总算可以了……
总结一下:
1. gitlab or其他git项目管理方式都有完善开发方式,如git flow等。
2. 哎小公司还是普遍太水,仓库的使用和管理方式较为单一。并不能彰显出git的强大功能。
3. 个人也太水了。没有仔细研究过git的各种好的功能。
4. 希望git的强大功能能真正的用在工作中,而不是仅仅只作为一个所谓的仓库。
-
2021-06-04-Centos8 安装hadoop 2.7.7(3节点)
背景:
本地测试环境想跑点东西,就整个三节点的hadoop2.7.7吧。也跑过3.3.0的版本。本地正好跟着友凡老师的教程做些东西,他的课程都是2.6.0的版本。也不想先升级太快不匹配各种找问题了。就找了个2.7.7的包本地跑一跑了
基础环境
主机名 ip 系统 hadoop1 192.168.0.192 centos8.2 hadoop2 192.168.0.192 centos8.2 hadoop3 192.168.0.128 centos8.2 注: 关于主机名的修改hostnamectl set-hostname XXX
嗯 ,别忘了修改三台主机的hosts文件:

开始安装:
1. java环境的配置
我的java环境是提前搭建好的(hadoop1-3节点):
[root@hadoop1 hadoop]# java -version java version "1.8.0_291" Java(TM) SE Runtime Environment (build 1.8.0_291-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode具体安装java环境如下:
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html下载jdk包。我是下载了jdk-8u291-linux-x64.tar.gz
tar zxvf jdk-8u291-linux-x64.tar.gz mv jdk1.8.0_291 /usr/java/jdk1.8.0_291vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_291 export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib export PATH=/usr/local/mysql/bin:$JAVA_HOME/bin:$PATH
source /etc/profile ###验证版本: java -verison
2. hadoop环境的安装
1. 下载hadoop安装包
hadoop1节点执行
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz tar zxvf hadoop-2.7.7.tar.gz mv hadoop-2.7.7 /usr/local/hadoop2. 用户配置
不想用root用户默认启动了,跟着大佬们的步骤创建一个hadoop用户吧!
useradd hadoop && echo 'hadoop' | passwd --stdin hadoop && for i in 1 2 3; do ssh root@hadoop${i} "useradd hadoop && echo 'hadoop' | passwd --stdin hadoop && id hadoop"; done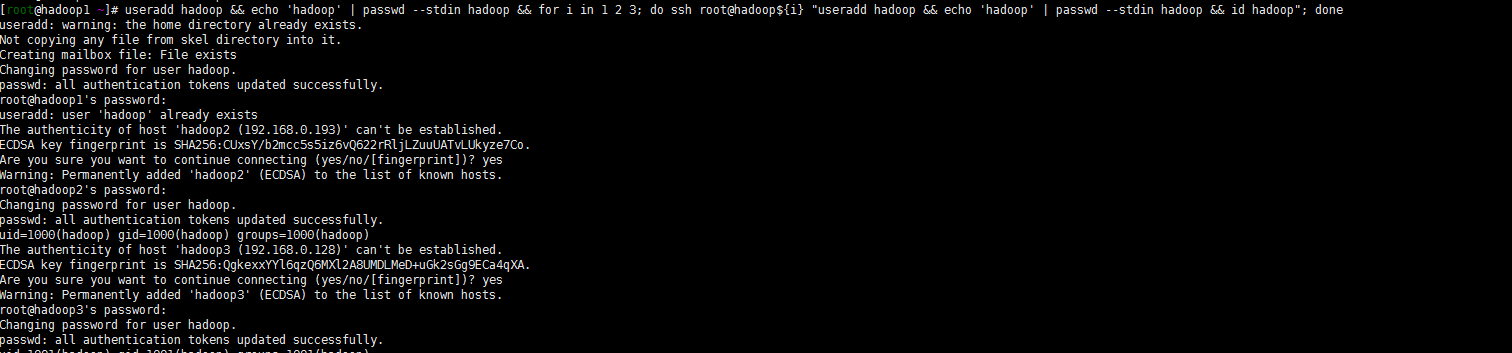
3. 设置hadoop用户秘钥登录集群每个节点
注: hadoop1节点执行
## 切换hadoop用户 su - hadoop ## 生成ssh-keygen ssh-keygen -t rsa -P '' ## 复制ssh-key秘钥到其他节点 for i in 1 2 3; do ssh-copy-id -i .ssh/id_rsa.pub hadoop@hadoop${i}; done ## 创建所需要目录并修改目录权限 for i in 1 2 3; do ssh root@hadoop${i} "mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}"; done for i in 1 2 3; do ssh root@hadoop${i} "chown -R hadoop:hadoop /data/hadoop/hdfs/"; done4. hadoop 配置文件调整
注: 仍然在hadoop1节点修改
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_291vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:8020</value> </property> </configuration>vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.address</name> <value>hadoop1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>hadoop1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop1:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> </configuration>vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hadoop/hdfs/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/hadoop/hdfs/dn</value> </property> <property> <name>fs.checkpoint.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> </configuration>vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>vi /usr/local/hadoop/etc/hadoop/slaves
hadoop2 hadoop35. 将hadoop文件同步到其他节点(hadoop2 hadoop3)
for i in 2 3; do scp -r /usr/local/hadoop hadoop${i}:/usr/local/hadoop/; done注意:记录检查一下目录文件的权限 /usr/local/hadoop目录下文件权限都chown -R hadoop:hadoop *下。 还有/data/hadoop目录下权限!
6. 将hadoop系统变量添加到profile
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop export HADOOP_PREFIX=/usr/local/hadoop export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin export HADOOP_YARN_HOME=${HADOOP_PREFIX} export HADOOP_MAPPERD_HOME=${HADOOP_PREFIX} export HADOOP_COMMON_HOME=${HADOOP_PREFIX} export HADOOP_HDFS_HOME=${HADOOP_PREFIX}source /etc/profile
7. hadoop初始化-格式化hdfs
su - hadoop hdfs namenode -format
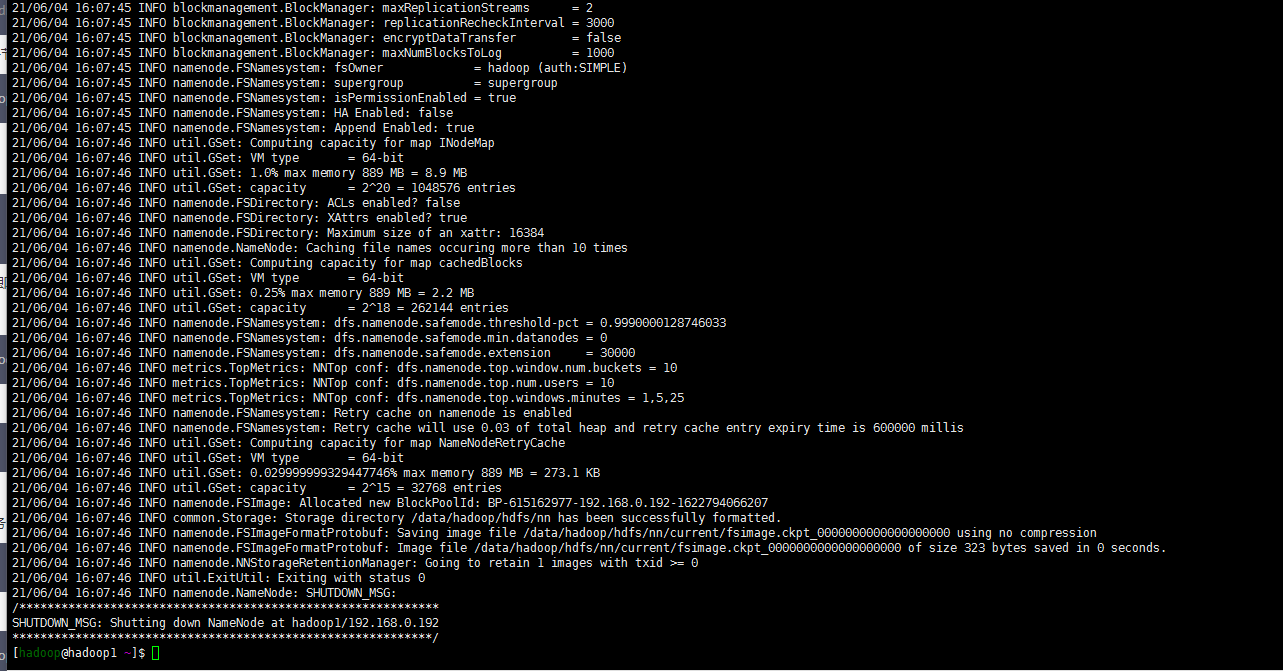
8. 启动dfs yarn 服务
start-dfs.sh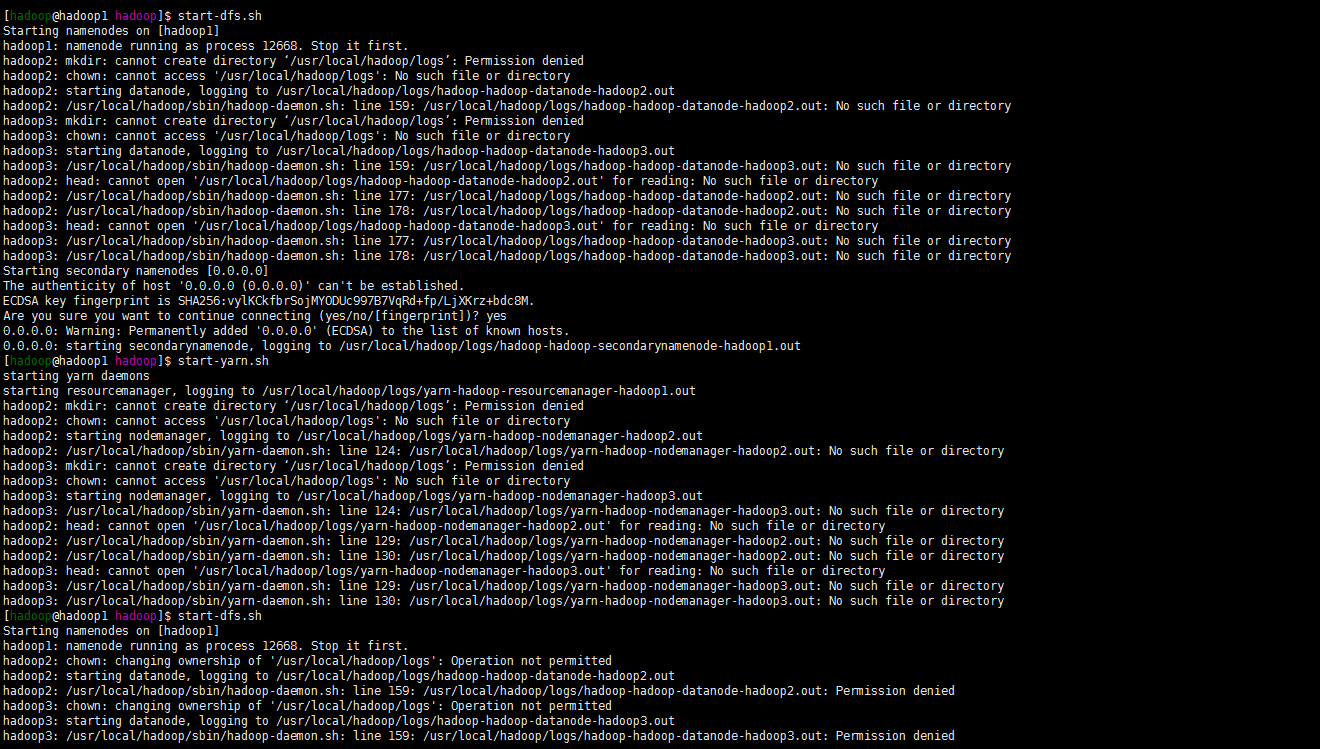
嗯报错了目录权限的问题。
cd /usr/local/hadoop chown hadoop.hadoop -R logs重新启动yarn与dfs。当然了也有可能还没有创建logs目录。手动创建一下啊可以。关键注意的还是目录的权限

9. web访问hadoop对应服务
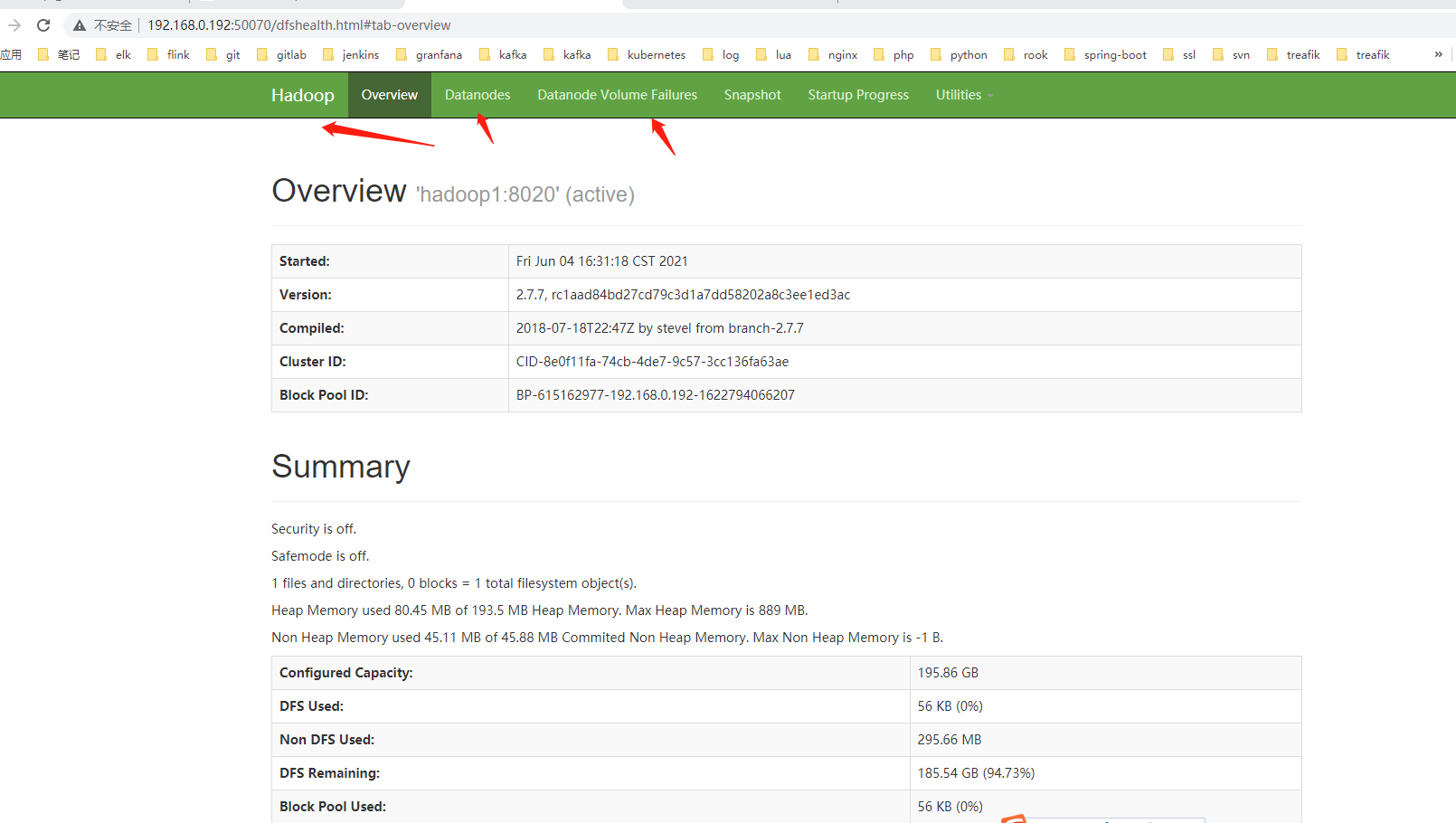
嗯可以绑定host 的方式访问hadoop1:50070
也可以直接http://192.168.0.192:50070/
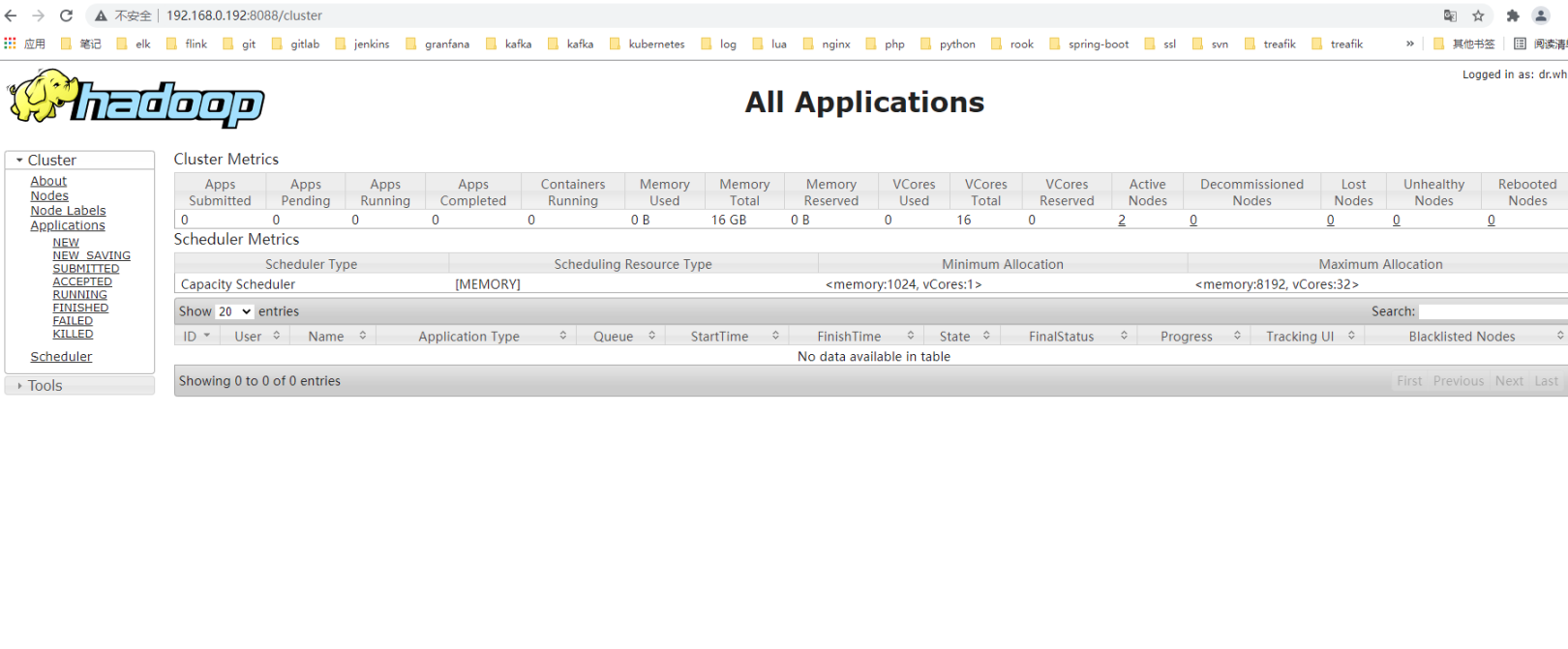
访问yarn
关于日志的查看就直接去/user/local/hadoop/logs目录下查看就可以了!
总结:
1. 文件目录的权限
2. 环境变量的正确配置
3. scp chown等命令的高效使用
-
2021-06-04-centos 8 clickhouse 单机版的安装
背景:
初始clickhouse是在一次在字节跳动参加的elasticsearch大会上面知道的,过去无聊在kubernetes集群中搭建过clickhouse但是也没有系统玩过,基本还是无脑的elasticsearch跑,也没有太深入。最近时间还算充足,就想系统跑下这些东西。当然了从简单的开始。
注: 本机服务器ip 192.168.0.193
1. centos8 搭建clickhouse
1. 验证sse 4.2是否支持
参见:https://cloud.tencent.com/developer/article/1831400 已经处理过proxmox虚拟化后对sse 4.2的支持
[root@slave1 ~]# grep -q sse4\_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported“" SSE 4.2 supported2. 安装clickhouse
网上无聊找到了下面yum的安装方式,直接拿来了使用了(反正现在是仅用于测试)
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86\_64 sudo yum install clickhouse-server clickhouse-client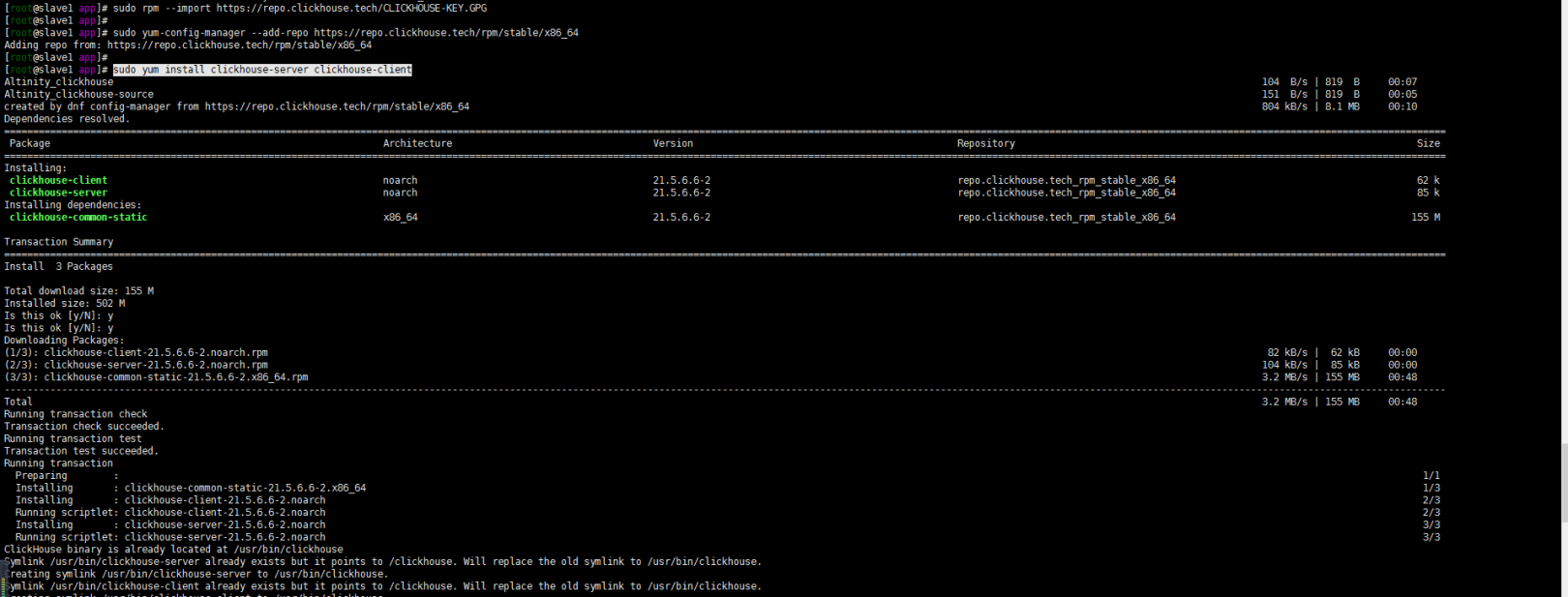
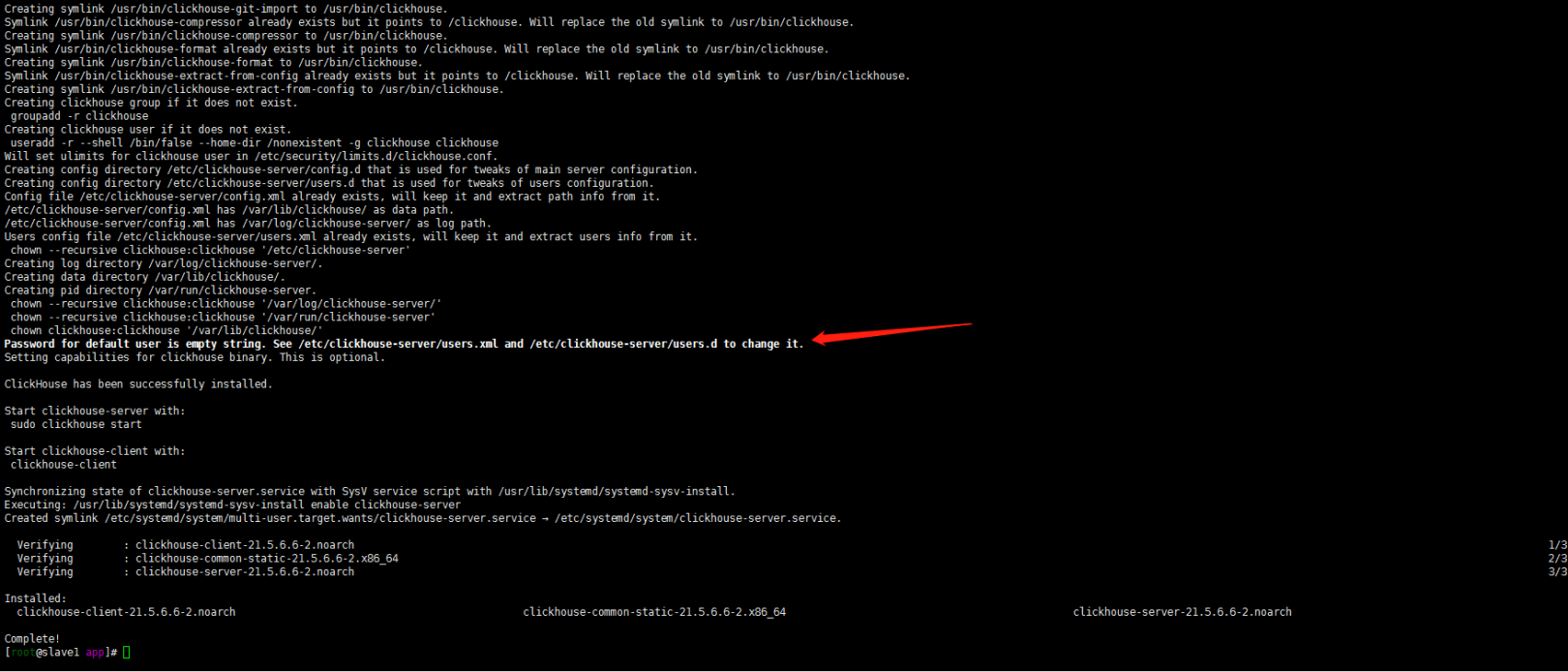
嗯 由上图也可以清晰的看到clickhouse-server配置文件目录在: /etc/clickhouse-server目录下……
3. 修改 clickhouse-server配置文件
进入/etc/clickhouse-server目录下,目录结构如下:
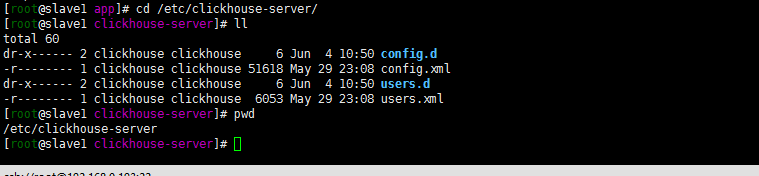
当前要做的就是允许其他ip的访问,默认的应该都是本机的……localhost.
1.修改 config.xml
vim config.xml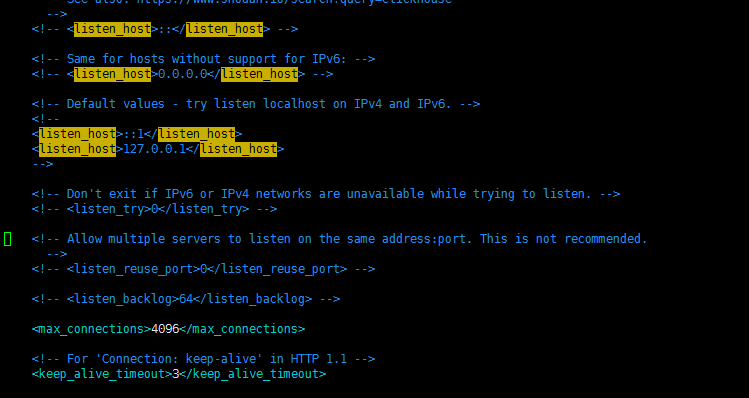
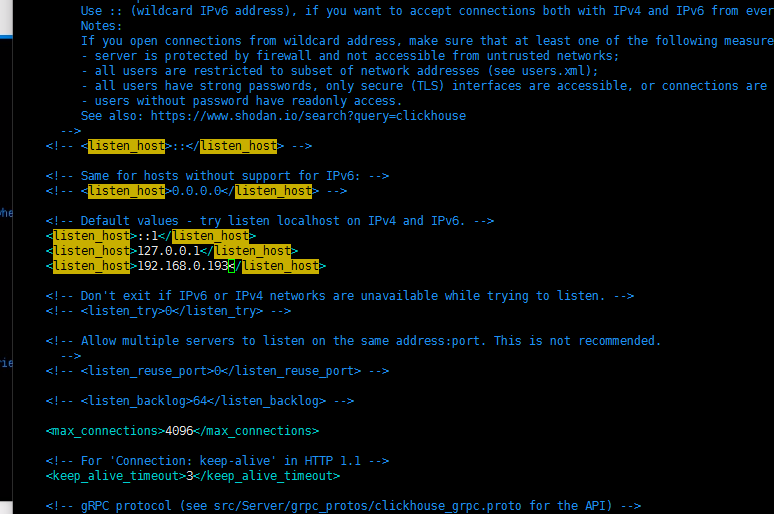
2. 查看users.xml
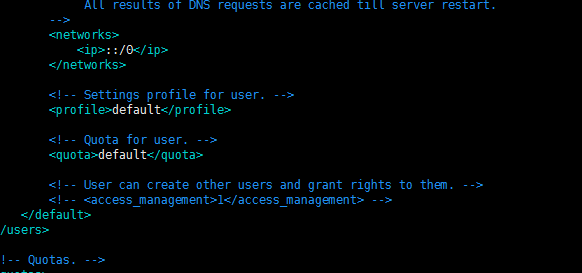
networks用ip ::/0了 应该貌似不用修改了吧?先采用默认的了
4.启动clickhouse-serve
clickhouse-server --config-file=/etc/clickhouse-server/config.xml草率了,出现如下报错:clickhouse默认是用非root用户启动的!
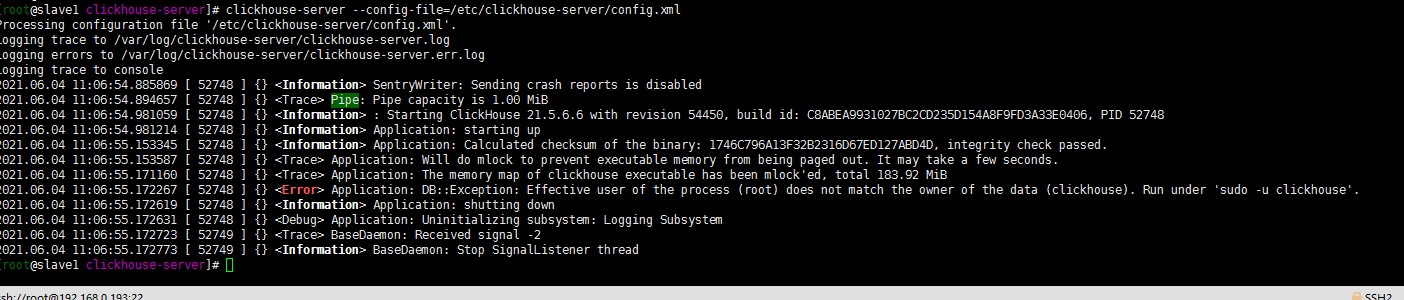
再来一下
sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml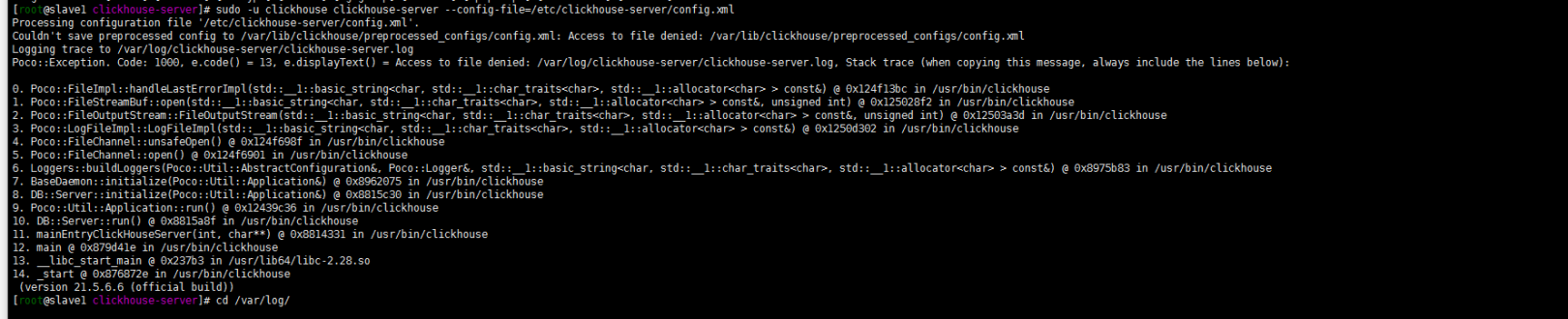
又报错了!这是由于第一次没有sudo -u 切换用户启动 log目录下生成的log文件权限是root造成的,到log目录下chown或者chmod一下文件的权限:
cd /var/log chown clickhouse.clickhouse -R clickhouse-server/重新启动clickhouse:
sudo -u clickhouse clickhouse-server --config-file=/etc/clickhouse-server/config.xml正常启动了……如下:
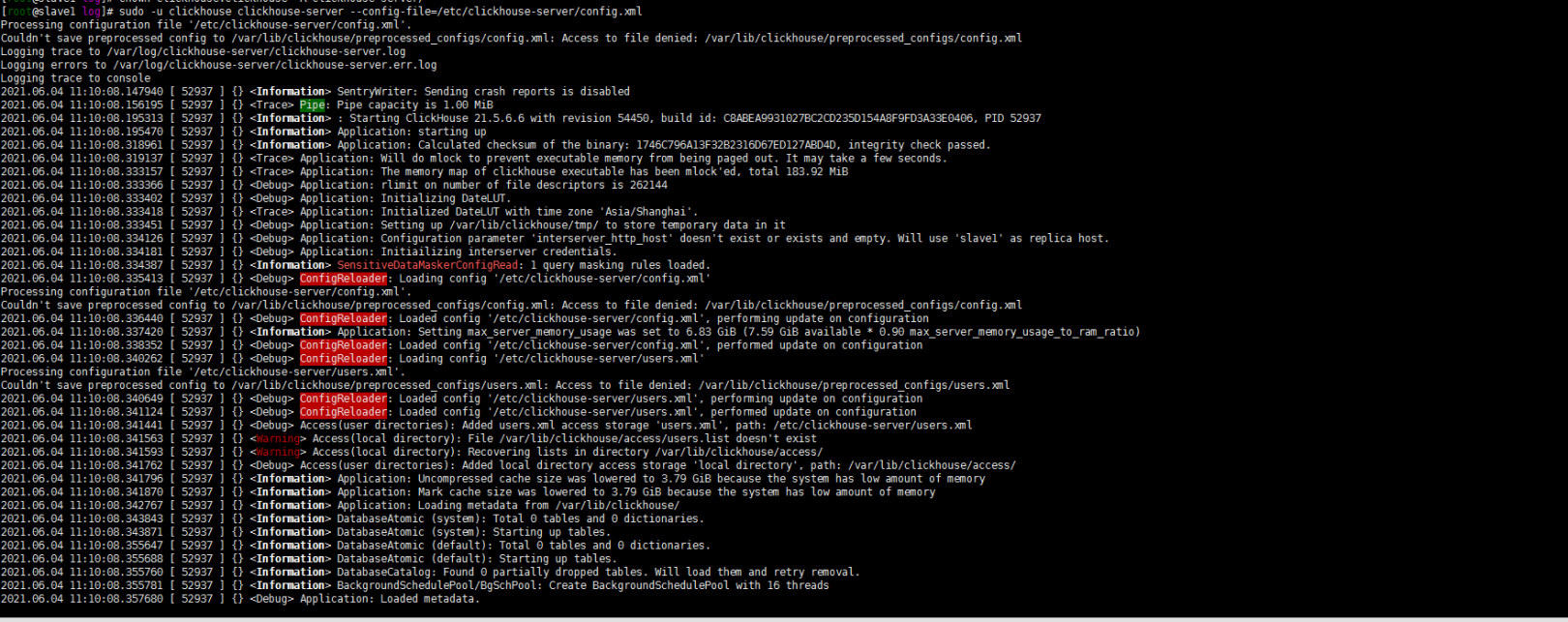
查看一下端口的启动状态,用客户端登陆一下clickhouse:
clickhouse-client --host=192.168.0.193 --port=9000如下登陆成功:
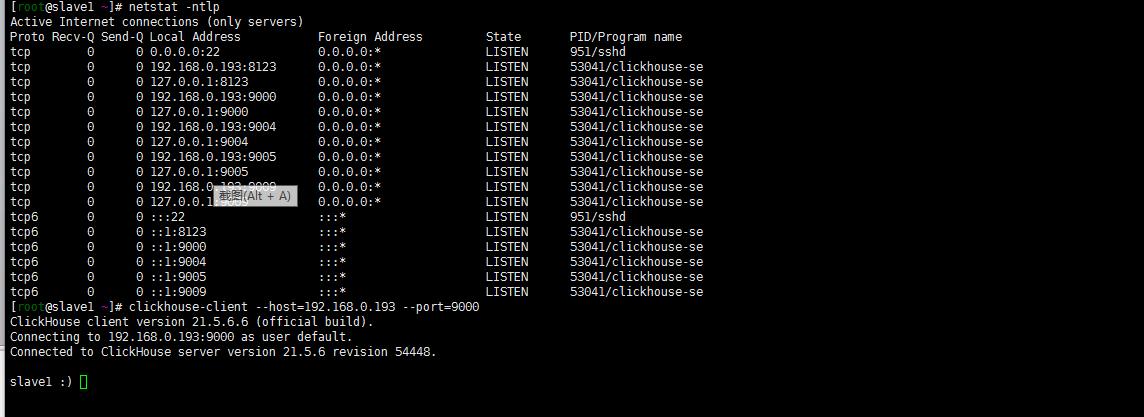
其他的后面去深入吧!
关于后续:
1. 账号密码的设置
2. 资源的隔离控制
3. 集群的搭建
4. clickhouse的正确使用
- 2022-08-09-Operator3-设计一个operator二-owns的使用
- 2022-07-11-Operator-2从pod开始简单operator
- 2021-07-20-Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)
- 2021-07-19-Kubernetes 1.18.20升级到1.19.12
- 2021-07-17-Kubernetes 1.17.17升级到1.18.20
- 2021-07-16-TKE1.20.6搭建elasticsearch on kubernetes
- 2021-07-15-Kubernets traefik代理ws wss应用
- 2021-07-09-TKE1.20.6初探
- 2021-07-08-关于centos8+kubeadm1.20.5+cilium+hubble的安装过程中cilium的配置问题--特别强调
- 2021-07-02-腾讯云TKE1.18初体验