- 背景:
- 为什么要限制资源?
- Kubernets中的资源分类
- 资源配额管理-LimitRange ResourceQuota
- 关于资源的调度与pod的Qos模型:
- 如何保证pod的资源优先性与调度的优先性?
- 总结一下:
背景:
不知道有没有小伙伴跟我一样在集群创建应用的时候没有详细计算过自己的资源配比。然后我是看到kubectl top node 一看每个节点还有很多的资源,就直接创建了几个资源配比较高的应用,而且这几个应用是高负载运行的….然后的结果就是集群中好多应用开始崩溃了……
为什么要限制资源?
1. 对pod进行资源限制,可以防止由于某一个pod应用过多占用资源,造成其他应用异常。
2. 资源的有效隔离。
3. pod调度的优先级。
4. 资源的高效合理利用。
Kubernets中的资源分类
Kubernetes根据资源能否伸缩进行分类,划分为可压缩资源和不可以压缩资源2种:
1. 可压缩资源(compressible resources )当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。例如 CPU(GPU也是吧?只不过没有搞gpu应用忽略)
2. 不可压缩资源(incompressible resources)当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。例如:Memory(内存) Disk(硬盘)。
注:参见极客时间磊神的专栏:https://time.geekbang.org/column/article/69678
资源配额管理-LimitRange ResourceQuota
ResourceQuota
ResourceQuota 用来限制 namespace 中所有的 Pod 占用的总的资源 request 和 limit
可以参照:https://kubernetes.io/zh/docs/concepts/policy/resource-quotas/
1. 计算资源配额(Compute Resource Quata)
可以参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/manage-resources/quota-memory-cpu-namespace/。
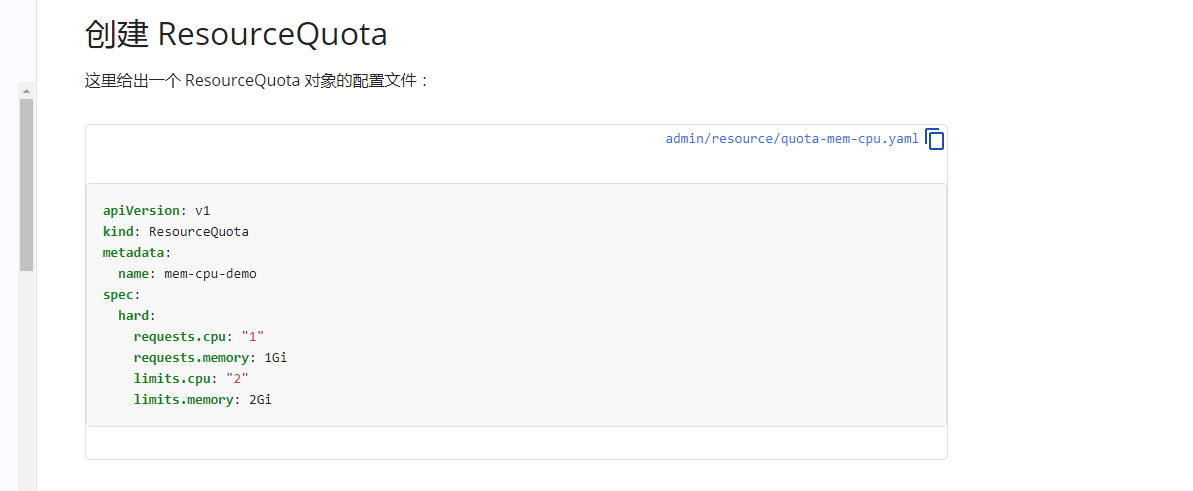
但是根据磊神:https://time.geekbang.org/column/article/69678中建议的还是将配置文件写成一下内部通用格式了:

cat > ResourceQuota.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-mem
namespace: quota
spec:
hard:
requests.cpu: 1000m
requests.memory: 1000Mi
limits.cpu: 2000m
limits.memory: 2000Mi
EOF
[root@sh-master-01 quota]# kubectl create ns quota
namespace/quota created
[root@sh-master-01 quota]# kubectl apply -f ResourceQuota.yaml
resourcequota/cpu-mem created
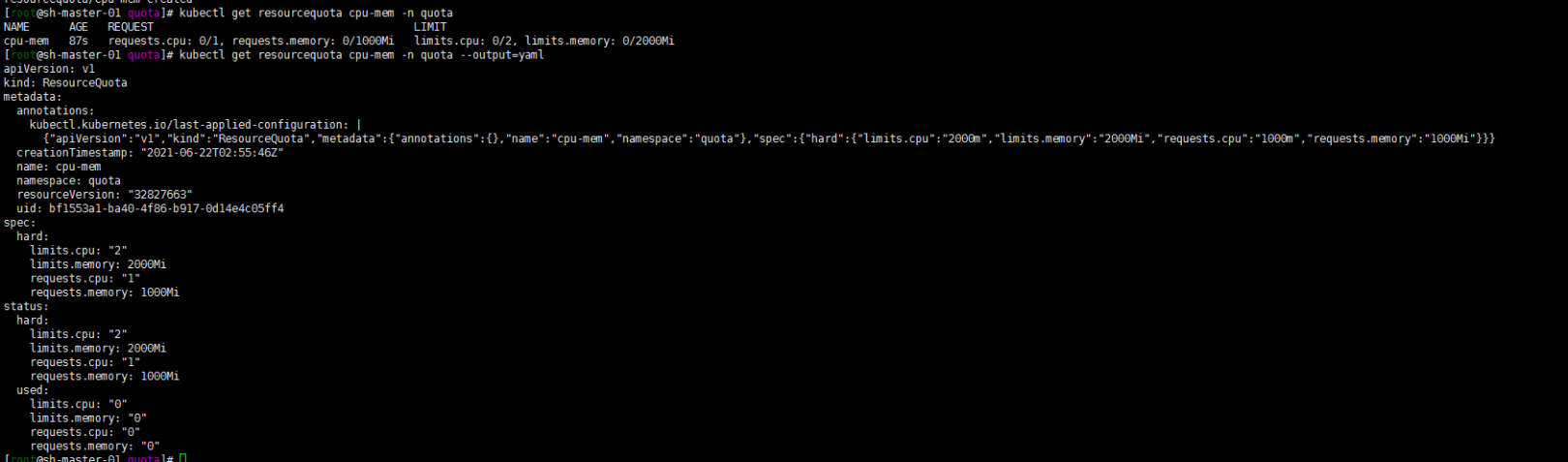
kubectl get resourcequota cpu-mem -n quota
kubectl get resourcequota cpu-mem--namespace=quota --output=yaml
用官方文档实例创建一个pod测试一下:
cat > quota-mem-cpu-pod.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"
EOF
在quota 命名空间中创建pod:
kubectl apply -f quota-mem-cpu-pod.yaml --namespace=quota
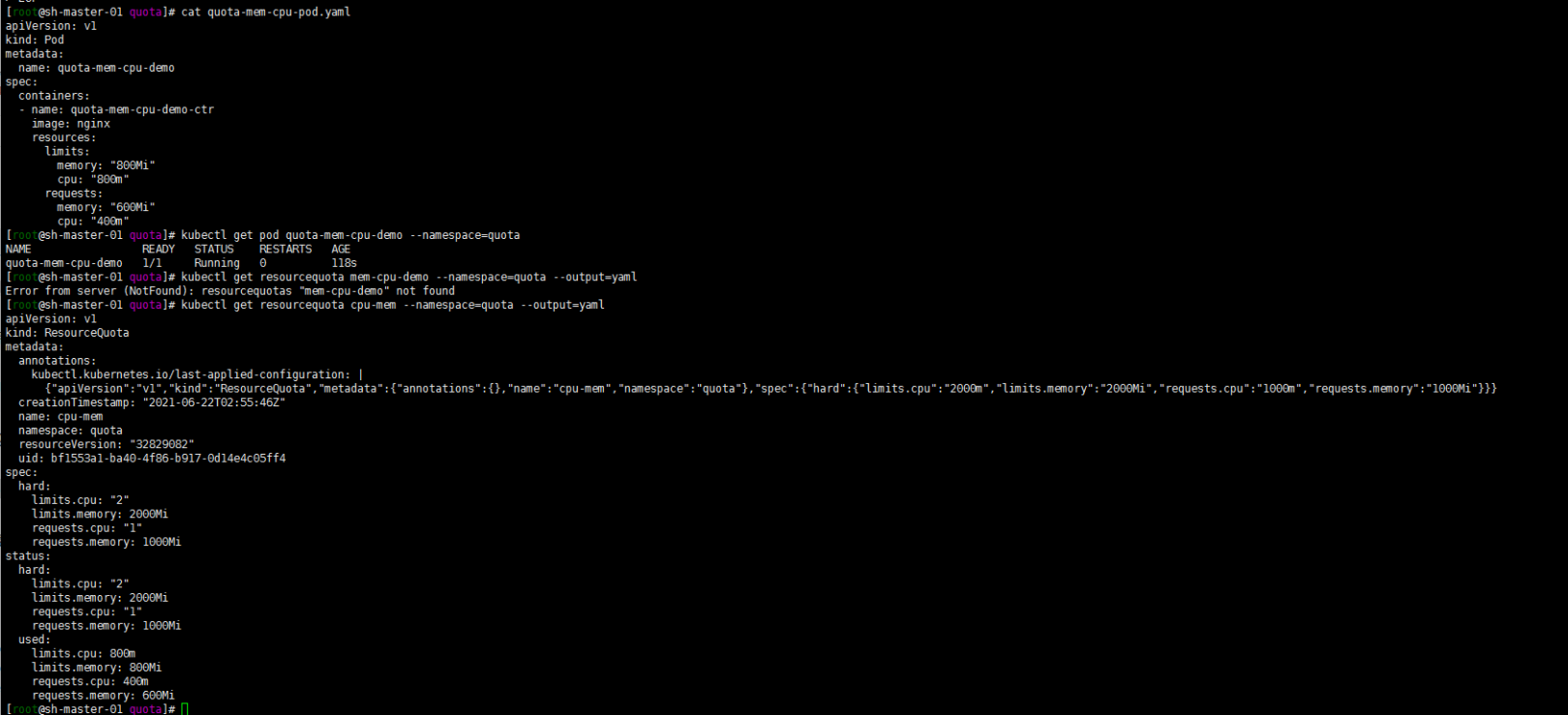
检查下 Pod 中的容器在运行:
kubectl get pod quota-mem-cpu-demo --namespace=quota
再查看 ResourceQuota 的详情:
kubectl get resourcequota cpu-mem --namespace=quota --output=yaml
输出结果显示了配额以及有多少配额已经被使用。你可以看到 Pod 的内存和 CPU 请求值及限制值没有超过配额
再创建一个pod:
cat > quota-mem-cpu-pod-2.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo-2
spec:
containers:
- name: quota-mem-cpu-demo-2-ctr
image: nginx
resources:
limits:
memory: "1000Mi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"
EOF
kubectl apply -f quota-mem-cpu-pod-2.yaml --namespace=quota
得到如下报错,第二个 Pod 不能被创建成功。输出结果显示创建第二个 Pod 会导致内存请求总量超过内存请求配额。

2. 存储资源配额(Volume Count Quata)
存储资源配额也演示一下吧。我这里就只限制存储总量了。其他的可设置参数可以参考官方文档:
cat > storage.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage
namespace: quota
spec:
hard:
requests.storage: 10Gi
EOF
cat > pvc.yaml << EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: quota-mem-cpu-demo-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: cbs-csi
EOF
在quota namespace中创建pvc:
kubectl apply -f pvc.yaml -n quota
得到如下报错。最大限制为10G。

3. 对象数量配额(Object Count Quata)
cat > objects.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: objects
namespace: quota
spec:
hard:
pods: 10
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 4
services: 5
services.loadbalancers: 1
services.nodeports: 2
cbs.storageclass.storage.k8s.io/persistentvolumeclaims: 2
EOF
数量配额就不演示。根据官方文档设置可以设置的限制数量的参数,并设置数量。只要数量大于设置数量失败就可以验证!
4. 配额的作用域(Quota Scopes)
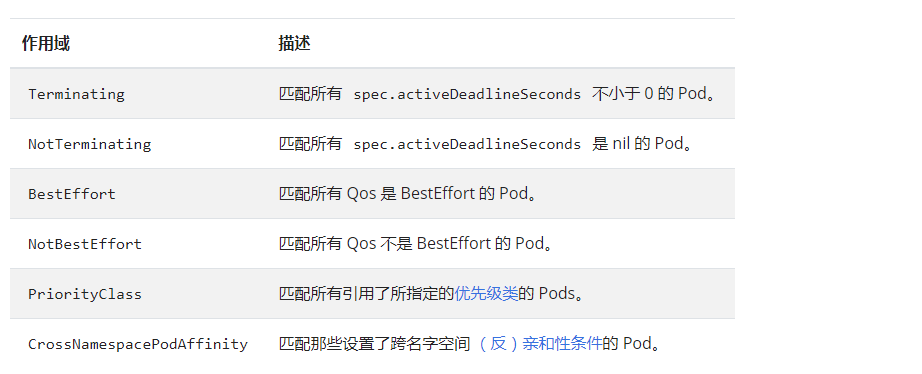
这个鬼东西功能没有怎么用过,就抄了一下官方的。有时间研究一下,一下实例摘自kubernetes权威指南第五版750页:
1. 创建ResourceQuota scope
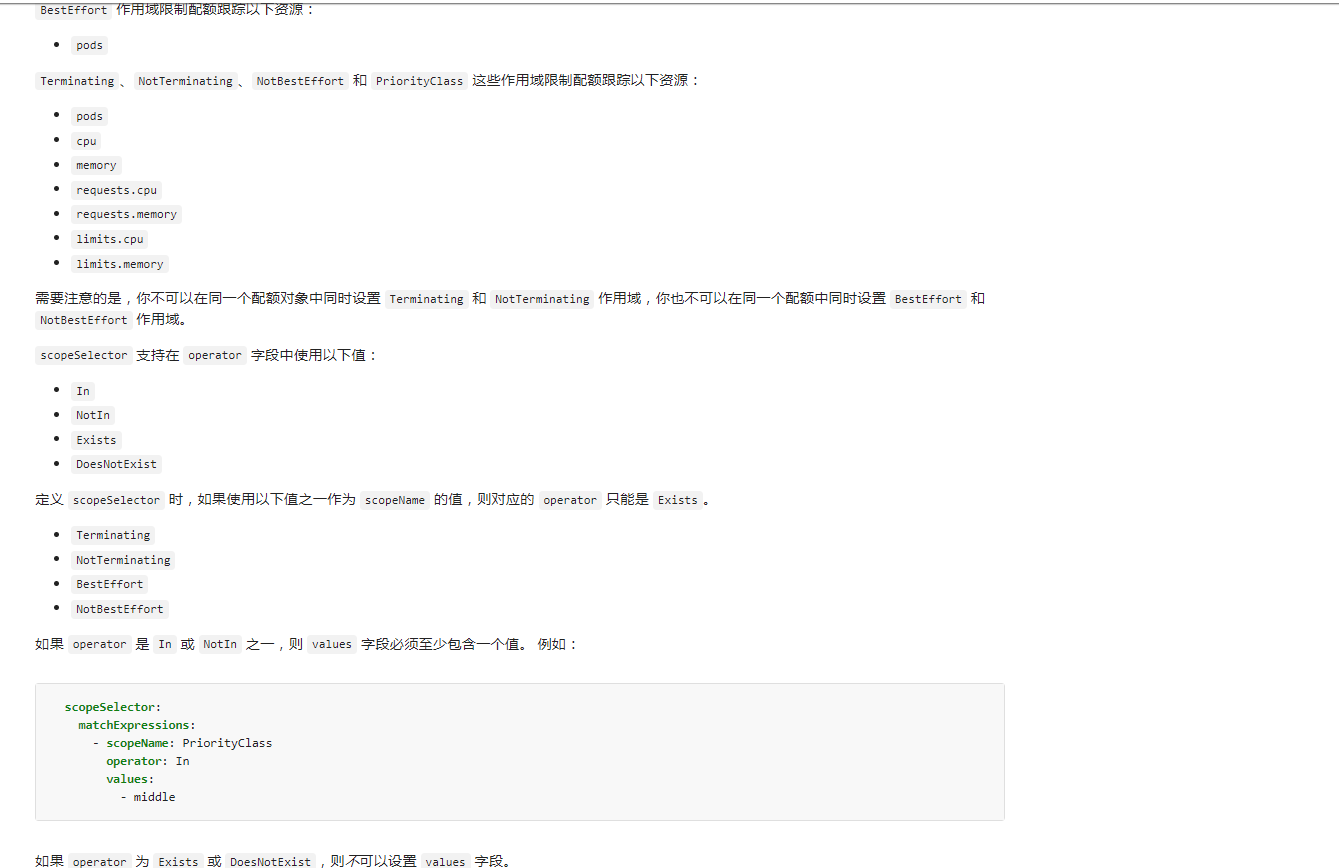
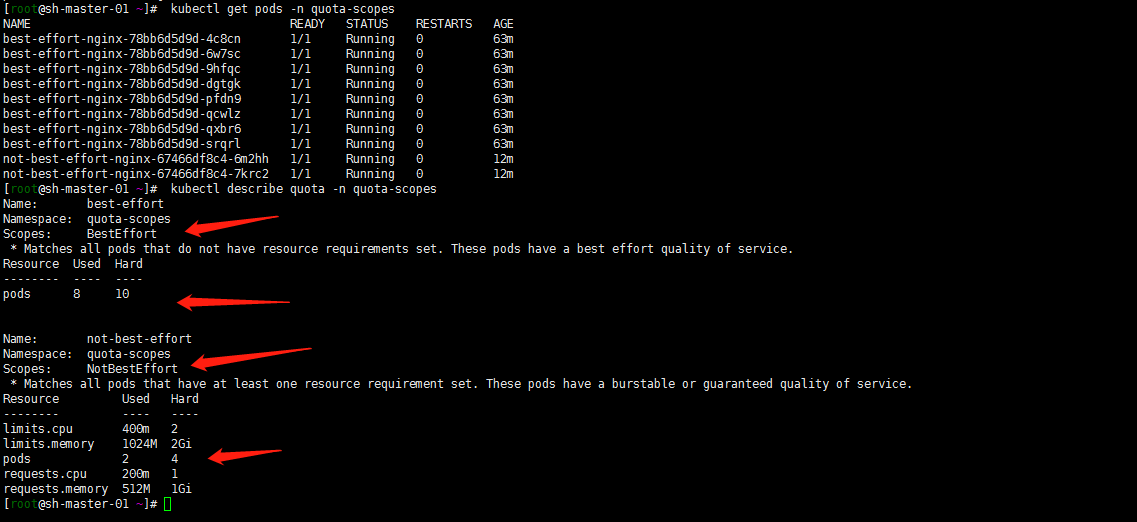
创建一个quota-scopes的命名空间,并创建一个名为best-effort的 ResourceQuota,一个名为not-best-effort的 ResourceQuota:
kubectl create ns quota-scopes
kubectl create quota best-effort --hard=pods=10 --scopes=BestEffort -n quota-scopes
kubectl create quota not-best-effort --hard=pods=4,requests.cpu=1000m,requests.memory=1024Mi,limits.cpu=2000m,limits.memory=2048Mi --scopes=NotBestEffort -n quota-scopes
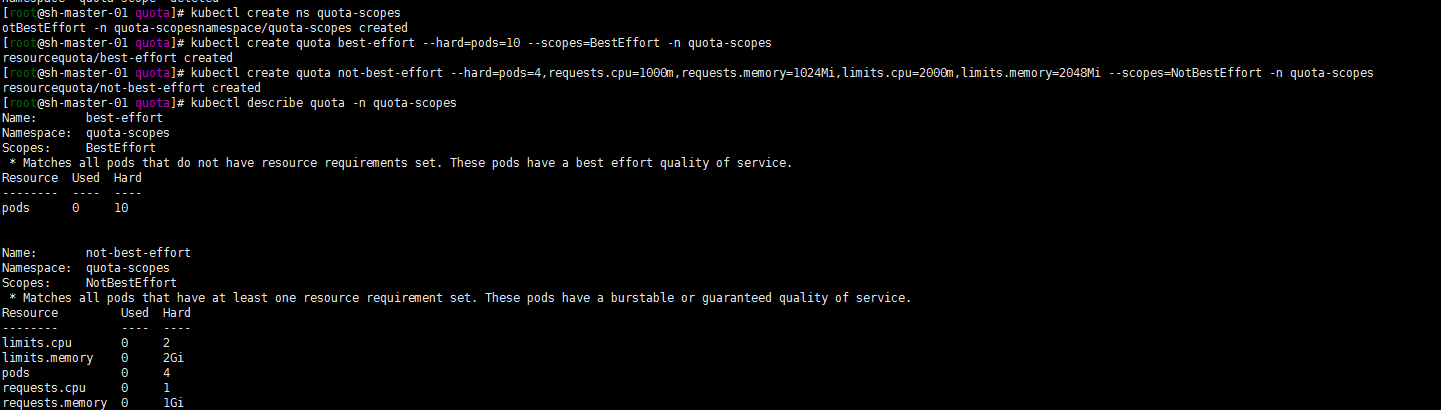
注:官方的方式是yaml的方式。正巧看到了http://docs.kubernetes.org.cn/541.html#kubectl_create_quota中
kubectl create quota就用了一下.
2. 创建两个deployment
kubectl run best-effort-nginx --image=nginx --replicas=8 --namespace=quota-scope
kubectl run not-best-effort-nginx --image=nginx= --replicas=2 --requests=cpu=100m,memory=256Mi --limits=cpu=200m,memory=512Mi --namespace=quota-scopes
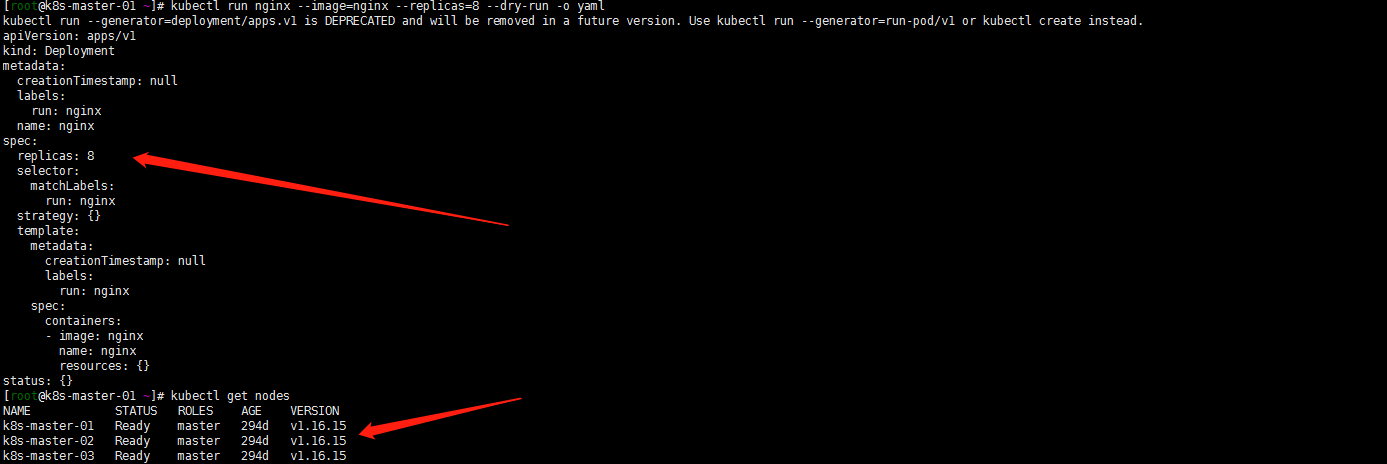

嗯这里就坑了。kubectl run 在1.16.16测试了下可以带replicas。但是我的1.21.1不能这样执行了。看了下文档使用下面的kubectl create deployment 命令
kubectl create deployment best-effort-nginx --image=nginx --replicas=8 --namespace=quota-scopes
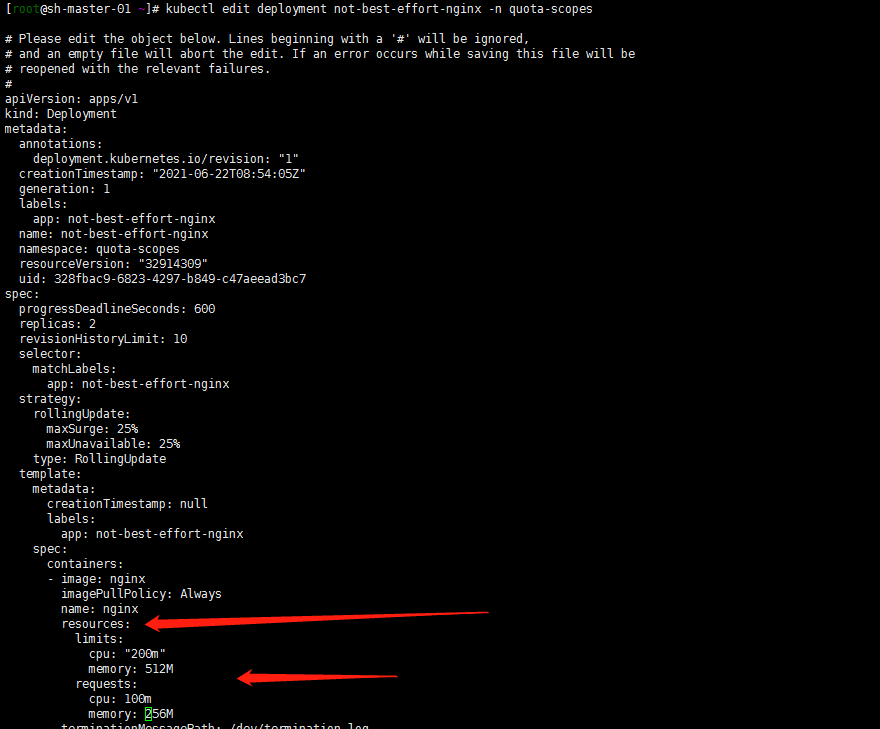
但是创建not-best-effort-nginx deployment时候,命令中貌似不能使用 –requests 和–limits了?用最笨的方法吧,创建deployment然后edit deployment增加resources限制:
kubectl create deployment not-best-effort-nginx --image=nginx --replicas=2 --namespace=quota-scopes
kubectl edit deployment not-best-effort-nginx -n quota-scopes
3. 验证:
kubectl get pods -n quota-scopes
kubectl describe quota -n quota-scopes
5. 基于优先级类(PriorityClass)来设置资源配额
注:这个鬼东西没有用过官方文档看来的……
FEATURE STATE: Kubernetes v1.17 stable
Pod 可以创建为特定的优先级。 通过使用配额规约中的 scopeSelector 字段,用户可以根据 Pod 的优先级控制其系统资源消耗。
仅当配额规范中的 scopeSelector 字段选择到某 Pod 时,配额机制才会匹配和计量 Pod 的资源消耗。
如果配额对象通过 scopeSelector 字段设置其作用域为优先级类,则配额对象只能 跟踪以下资源:
- pods
- cpu
- memory
- ephemeral-storage
- limits.cpu
- limits.memory
- limits.ephemeral-storage
- requests.cpu
- requests.memory
- requests.ephemeral-storage
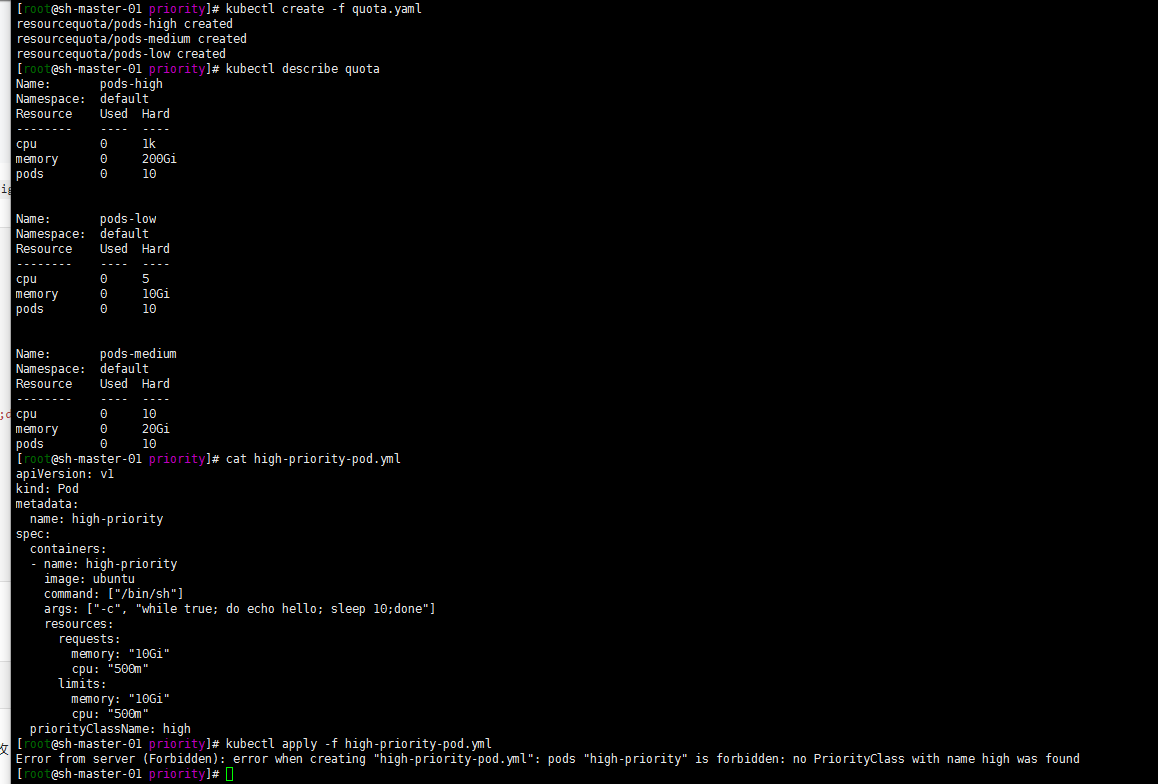
本示例创建一个配额对象,并将其与具有特定优先级的 Pod 进行匹配。 该示例的工作方式如下:
- 集群中的 Pod 可取三个优先级类之一,即 “low”、”medium”、”high”。
- 为每个优先级创建一个配额对象。
将以下 YAML 保存到文件 quota.yml 中。
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high
spec:
hard:
cpu: "1000"
memory: 200Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["high"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium
spec:
hard:
cpu: "10"
memory: 20Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["medium"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["low"]
使用 kubectl create 命令运行以下操作。
kubectl create -f quota.yml
kubectl describe quota
LimitRange
LimitRange 用来限制 namespace 中 单个Pod 默认资源 request 和 limit
1. 一般的例子 单个container的pod
嗯 一般是通过requests limits去限制pod cpu与内存的资源的。如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-test
spec:
replicas: 2
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: php-test
template:
metadata:
labels:
app: php-test
spec:
containers:
- name: php-test
image: ccr.ccs.tencentyun.com/master/php-test:0.1
env:
- name: PHP_MEM_LIMIT
value: "256M"
envFrom:
- configMapRef:
name: deploy
ports:
- containerPort: 80
resources:
requests:
memory: "256M"
cpu: "250m"
limits:
memory: "2048M"
cpu: "4000m"
livenessProbe:
httpGet:
scheme: HTTP
path: /test.html
port: 80
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
scheme: HTTP
path: /test.html
port: 80
initialDelaySeconds: 30
periodSeconds: 30
imagePullSecrets:
- name: tencent
---
apiVersion: v1
kind: Service
metadata:
name: php-test
labels:
app: php-test
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: php-test
2. 多个container的pod
当然了 一个pod可以有多个container:
apiVersion: v1
kind: Pod
metadata:
name: kucc1
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
memory: "256M"
cpu: "250m"
limits:
memory: "2048M"
cpu: "4000m"
- image: redis
name: redis
resources:
requests:
memory: "256M"
cpu: "250m"
limits:
memory: "2048M"
cpu: "4000m"
这个pod的request 内存最低是512M ,cpu是0.5核。limits 内存是4096M,cpu是8核。
嗯 pod 与container的关系,一个pod可以包括多个container
关于资源的调度与pod的Qos模型:
资源管理-Compute Resource
qos-服务质量管理
kubernetes在对pod进行调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。
Kubernetes 将 pod 划分为 3 种 QoS 等级 :
- BestEffort (优先级最低)
- Burstable
- Guaranteed (优先级最高)
最低优先级的 QoS 等级是 BestEffort 。 会分配给那些没有(为任何容器) 设置任何 requests 和 limits 的 pod。在这个等级运行的容器没有任何资源保证。 在最坏情况下,它们分不到任何 CPU 资源,同时在需要为其他 pod 释放内存时, 这些容器会第一批被杀死。 不过因为 BestEffort pod 没有配置内存 limits, 当有充足的可用内存时,这些容器可以使用任意多的内存。
apiVersion: v1
kind: Pod
metadata:
name: php-test
namespace: develop
spec:
containers:
- name: php-test
image: nginx
Guaranteed 级别的 pod,有以下几个条件:
- CPU 和内存都要设置 requests 和 limits
```
apiVersion: v1
kind: Pod
metadata:
name: php-test
namespace: qa
spec:
containers:
- name: php-test image: nginx resources: limits: memory: “200Mi” cpu: “700m” requests: memory: “200Mi” cpu: “700m” ```
- 每个容器都需要设置资源量
- 它们必须相等(每个容器的每种资源的 requests 和 limits 必须相等)
Burstable QoS 等级介于 BestEffort 和 Guaranteed 之间。其他所有 的 pod 都属于这个等级。 包括容器的requests 和 limits 不相同的单容器 pod,至少有 一个容器只定义了 requests 但没有定义 limits 的 pod,以及一个容器的 requests,limits 相等,但是另一个容器不指定 requests 或 limits 的 pod。
apiVersion: v1
kind: Pod
metadata:
name: php-test
namespace: master
spec:
containers:
- name: php-test
image: nginx
resources:
limits
memory: "200Mi"
requests:
memory: "100Mi"
注:
Guaranteed >Burstable > BestEffort 故 在上面的实例中我采用了三个不同的namespace进行了优先性的一个区分吧算是。因为我的master namespace是最重要优先的线上服务,qa算是测试环境,develop是开发环境。避免资源被抢占的最好方式就是将resource中limits与requests值设置为相同的值,Qos优先级为Guaranteed。
如何保证pod的资源优先性与调度的优先性?
kubernetes pod应用分布到哪个节点上默认是通过master的scheduler经过一系列算法得出的,用户是无干预过程和结果的。设置Qos优先级为Guaranteed只能保证资源的优先。还有什么其他的方式去保证资源的优先与调度呢?
1. NodeSelector 定向调度
将pod 调度到一组含有相同标签的work节点
[root@sh-master-01 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
sh-master-01 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
sh-master-02 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-02,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
sh-master-03 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-03,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
sh-work-01 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-01,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2
sh-work-02 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-02,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2
sh-work-03 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-03,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2
给节点sh-work-01打一个zone=shanghai标签,
[root@sh-master-01 ~]# kubectl label node sh-work-01 zone=shanghai
node/sh-work-01 labeled
[root@sh-master-01 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
sh-master-01 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
sh-master-02 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-02,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
sh-master-03 Ready control-plane,master 92d v1.21.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-master-03,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
sh-work-01 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-01,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2,zone=shanghai
sh-work-02 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-02,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2
sh-work-03 Ready <none> 92d v1.21.1 IngressProxy=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sh-work-03,kubernetes.io/os=linux,topology.com.tencent.cloud.csi.cbs/zone=ap-shanghai-2
新建一个pod调度到zone=shanghai节点
就用 nginx镜像去做测试了:
kubectl run nginx --image=nginx:latest --port=80 --dry-run -o yaml > nodeselector.yaml
vim nodeselector.yaml,增加nodeSelector 配置
cat > nodeselector.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx:latest
name: nginx
ports:
- containerPort: 80
resources: {}
nodeSelector:
zone: shanghai
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
EOF
部署并验证pod是否调度到sh-work-01节点:
kubectl apply -f nodeselector.yaml
kubectl get pods -o wide
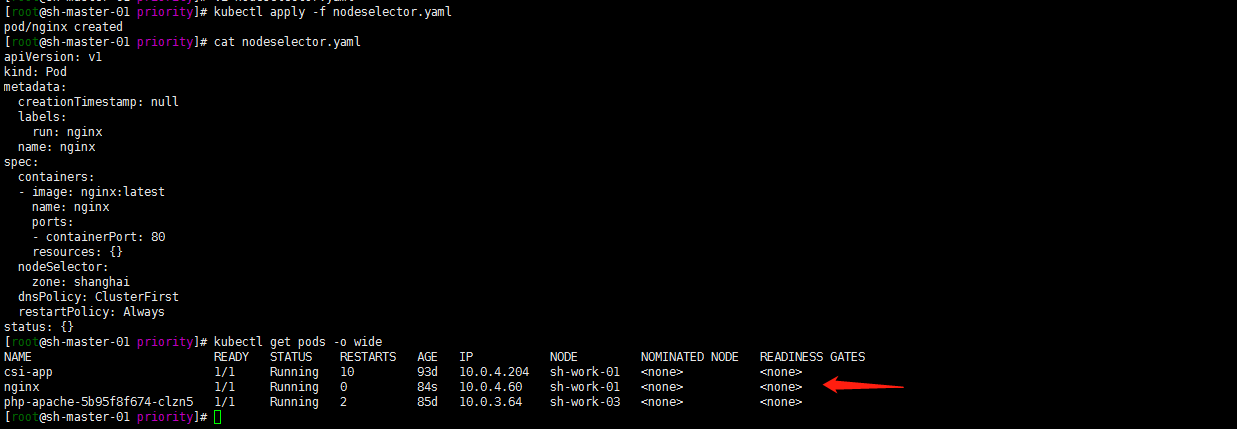
注:nodeSelector属于强制性的,如果我们的目标节点没有可用的资源,Pod 就会一直处于 Pending 状态。
2. NodeAffinity: Node亲和性
1. 亲和性调度可以分成软策略和硬策略两种方式:
1. 软策略-preferredDuringSchedulingIgnoredDuringExecution
只是强调优先,但是不强求。就是如果你没有满足调度要求的节点的话,pod 就会忽略这条规则,继续完成调度过程,说白了就是**满足条件最好了,没有的话也无所谓了**的策略。当然还可以有多个优先规则,可以设置wight权重值,定义先后顺序。
2. 硬策略-requiredDuringSchedulingIgnoredDuringExecution
必须满足指定的规则才可以调度pod到node上,比较强硬了,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不干的策略。
2. 关于IgnoredDuringExecution
详细见官方:

IgnoredDuringExecution类似于 nodeSelector 的工作原理, 如果节点的标签在运行时发生变更,从而不再满足 Pod 上的亲和性规则,那么 Pod 将仍然继续在该节点上运行。
3. 常见的语法操作符
提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
如果你同时指定了 nodeSelector 和 nodeAffinity,_两者_必须都要满足, 才能将 Pod 调度到候选节点上。
如果你指定了多个与 nodeAffinity 类型关联的 nodeSelectorTerms,则 如果其中一个 nodeSelectorTerms 满足的话,pod将可以调度到节点上。
如果你指定了多个与 nodeSelectorTerms 关联的 matchExpressions,则 只有当所有 matchExpressions 满足的话,Pod 才会可以调度到节点上。
如果你修改或删除了 pod 所调度到的节点的标签,Pod 不会被删除。 换句话说,亲和性选择只在 Pod 调度期间有效。
preferredDuringSchedulingIgnoredDuringExecution 中的 weight 字段值的 范围是 1-100。 对于每个符合所有调度要求(资源请求、RequiredDuringScheduling 亲和性表达式等) 的节点,调度器将遍历该字段的元素来计算总和,并且如果节点匹配对应的 MatchExpressions,则添加“权重”到总和。 然后将这个评分与该节点的其他优先级函数的评分进行组合。 总分最高的节点是最优选的。
4. 举个例子
1. 关于硬策略的例子
搞一个没有的的标签试一下硬限制:
cat > pod-nodeAffinity.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity
namespace: default
labels:
app: myapp
type: pod
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node01
EOF
kubectl apply -f pod-nodeAffinity.yaml
kubectl get pods
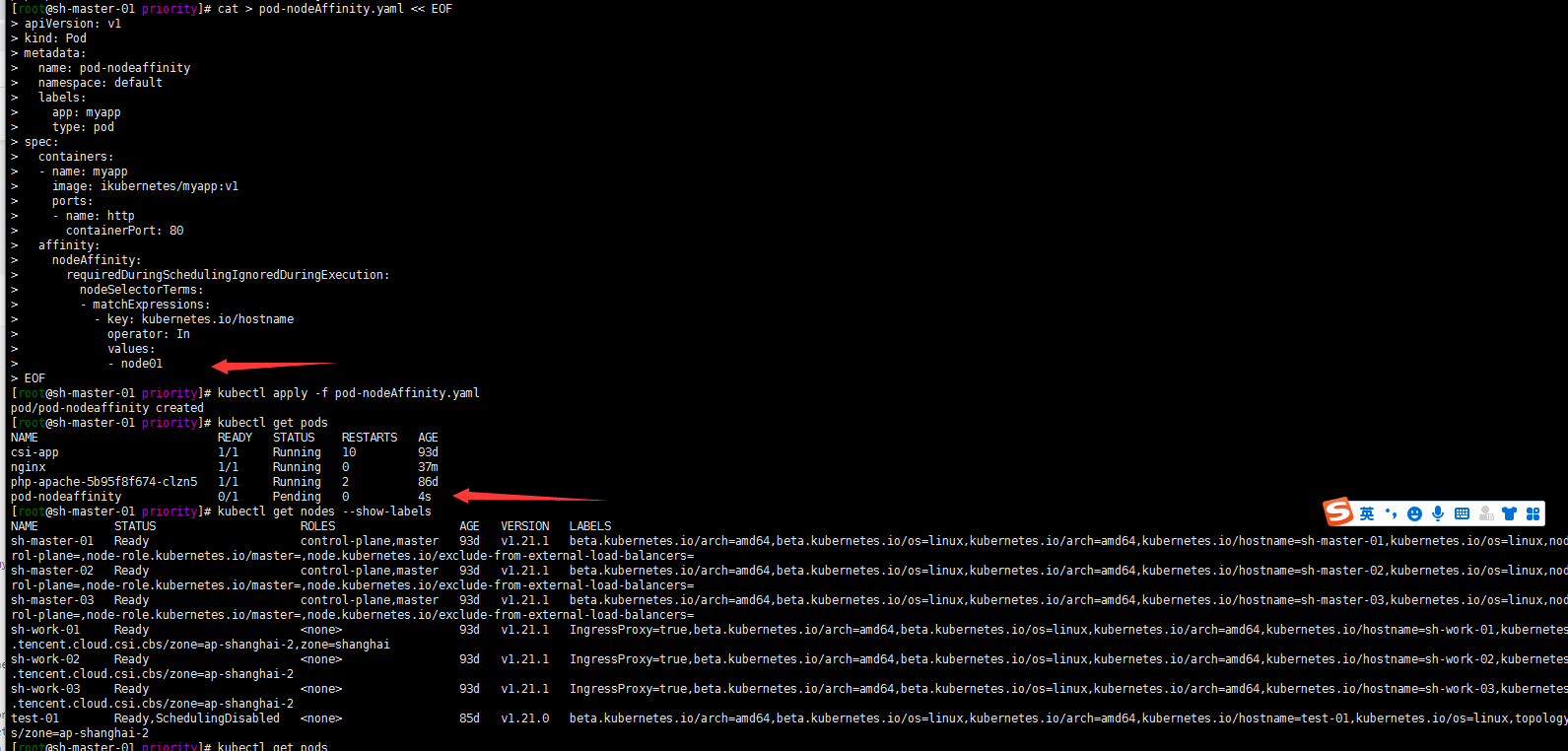
嗯 我是没有kubernetes.io/hostname:node01标签的节点的所以pod一直处于pending状态
修改一下kubernetes.io/hostname:sh-work-01吧
嗯 如下
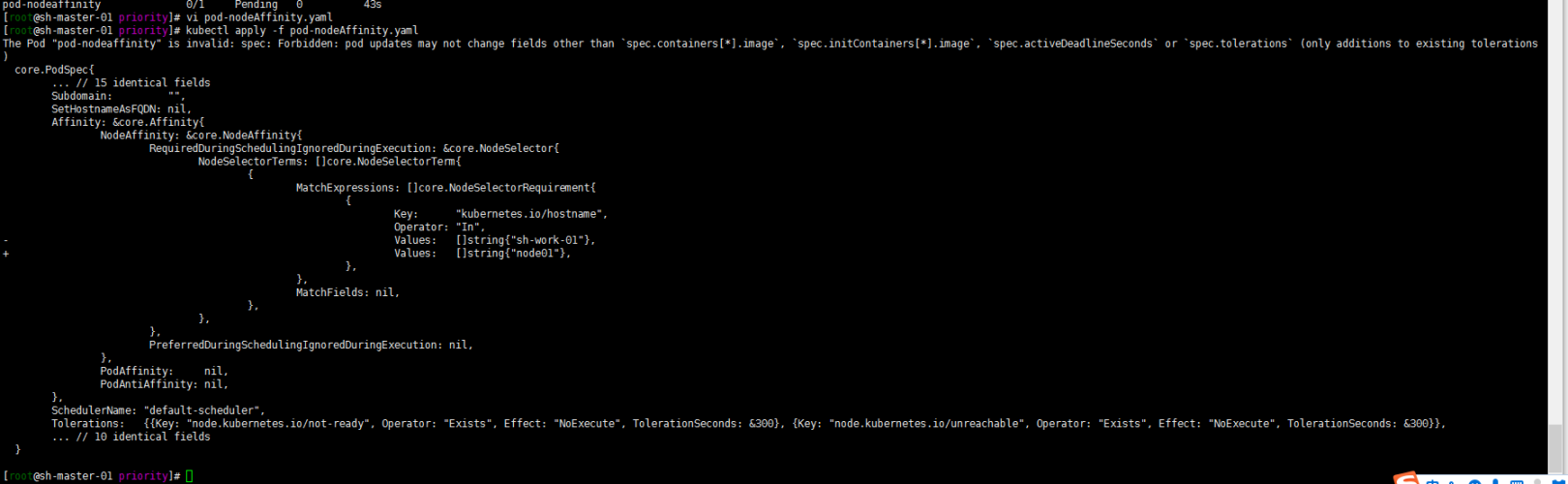
删除重新部署一下试试:
kubectl delete -f pod-nodeAffinity.yaml
kubectl create -f pod-nodeAffinity.yaml
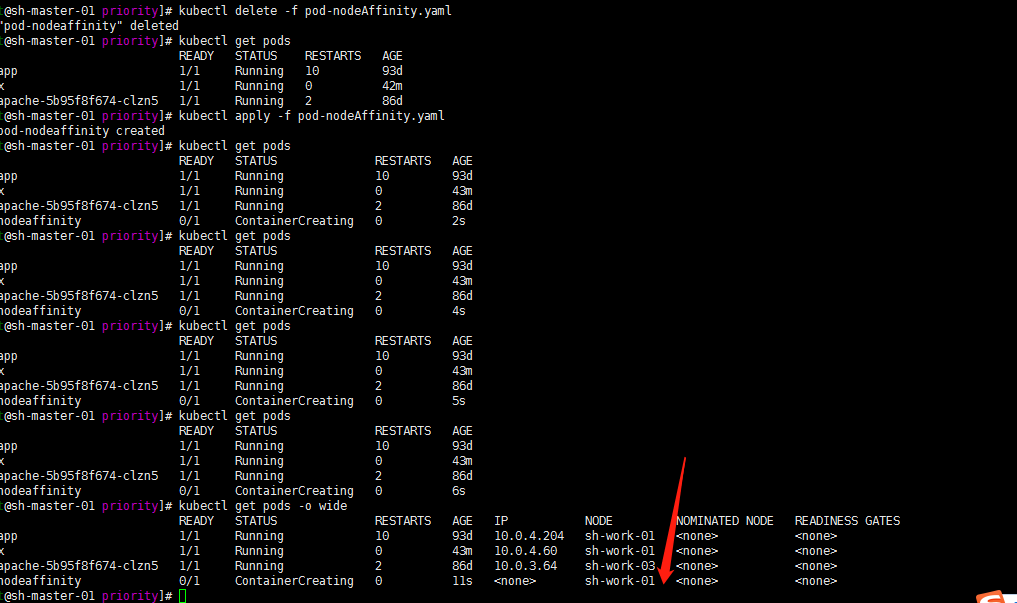
然后我现在修改下values试试? 将sh-work-01修改为sh-work-02
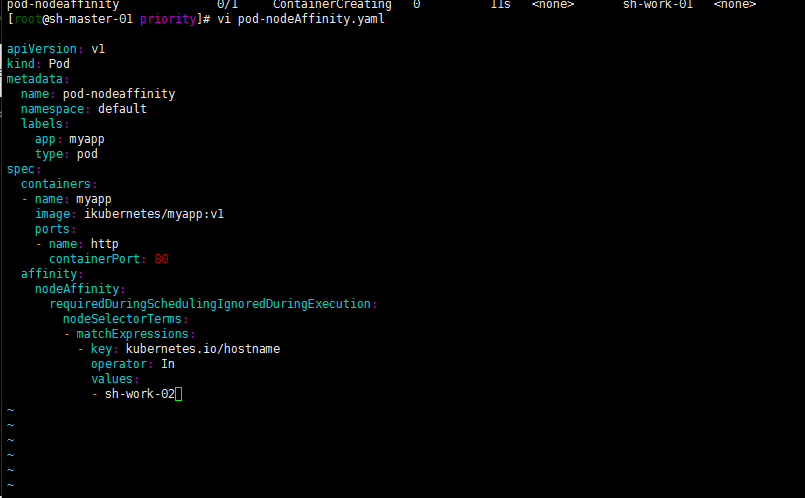
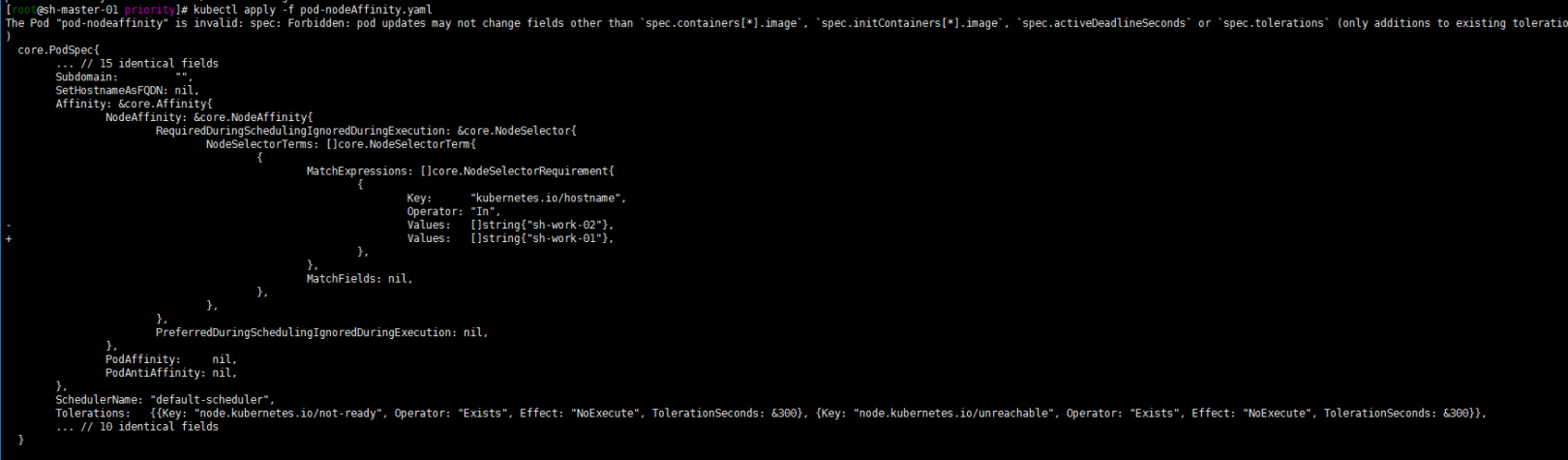
依然如此! 进一步验证了IgnoredDuringExecution的特性!
2. 关于软策略的例子
依然是整一个没有的label标签的节点去调度:
cat > pod-prefer.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: pod-prefer
namespace: default
labels:
app: myapp
type: pod
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node01
EOF
[root@sh-master-01 priority]# kubectl apply -f pod-prefer.yaml
pod/pod-prefer created
[root@sh-master-01 priority]# kubectl get pods
NAME READY STATUS RESTARTS AGE
csi-app 1/1 Running 10 93d
nginx 1/1 Running 0 62m
php-apache-5b95f8f674-clzn5 1/1 Running 2 86d
pod-nodeaffinity 1/1 Running 0 19m
pod-prefer 0/1 ContainerCreating 0 3s
[root@sh-master-01 priority]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-app 1/1 Running 10 93d 10.0.4.204 sh-work-01 <none> <none>
nginx 1/1 Running 0 62m 10.0.4.60 sh-work-01 <none> <none>
php-apache-5b95f8f674-clzn5 1/1 Running 2 86d 10.0.3.64 sh-work-03 <none> <none>
pod-nodeaffinity 1/1 Running 0 19m 10.0.4.118 sh-work-01 <none> <none>
pod-prefer 0/1 ContainerCreating 0 7s <none> sh-work-02 <none> <none>
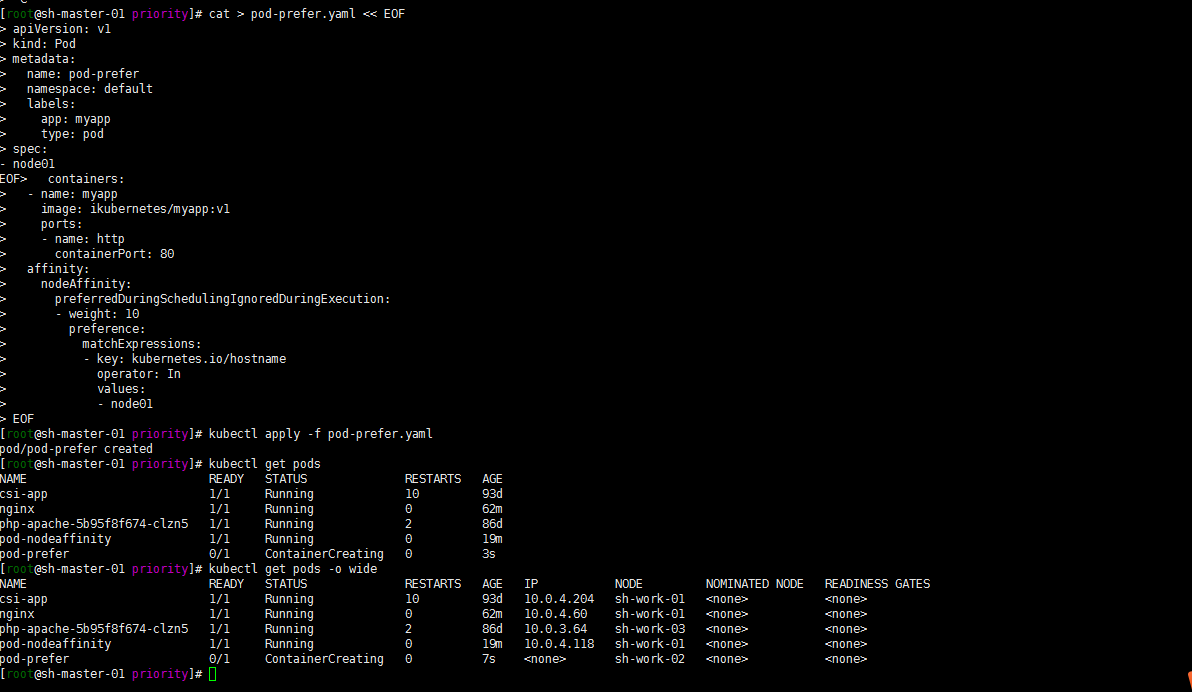
嗯 我是没有label kubernetes.io/hostname:node01节点的。结果他调度到了sh-work-02节点。这算是体现了不强制了吧?
然后再测试一下权重?
cat > pod-prefer1.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: pod-prefer1
namespace: default
labels:
app: myapp1
type: pod
spec:
containers:
- name: myapp1
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- sh-work-01
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- sh-work-03
EOF
[root@sh-master-01 priority]# kubectl apply -f pod-prefer1.yaml
pod/pod-prefer1 created
[root@sh-master-01 priority]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-app 1/1 Running 10 93d 10.0.4.204 sh-work-01 <none> <none>
nginx 1/1 Running 0 67m 10.0.4.60 sh-work-01 <none> <none>
php-apache-5b95f8f674-clzn5 1/1 Running 2 86d 10.0.3.64 sh-work-03 <none> <none>
pod-nodeaffinity 1/1 Running 0 23m 10.0.4.118 sh-work-01 <none> <none>
pod-prefer 1/1 Running 0 4m57s 10.0.5.181 sh-work-02 <none> <none>
pod-prefer1 0/1 ContainerCreating 0 6s <none> sh-work-03 <none> <none>
嗯基于权重调度到了sh-work-03的节点上了
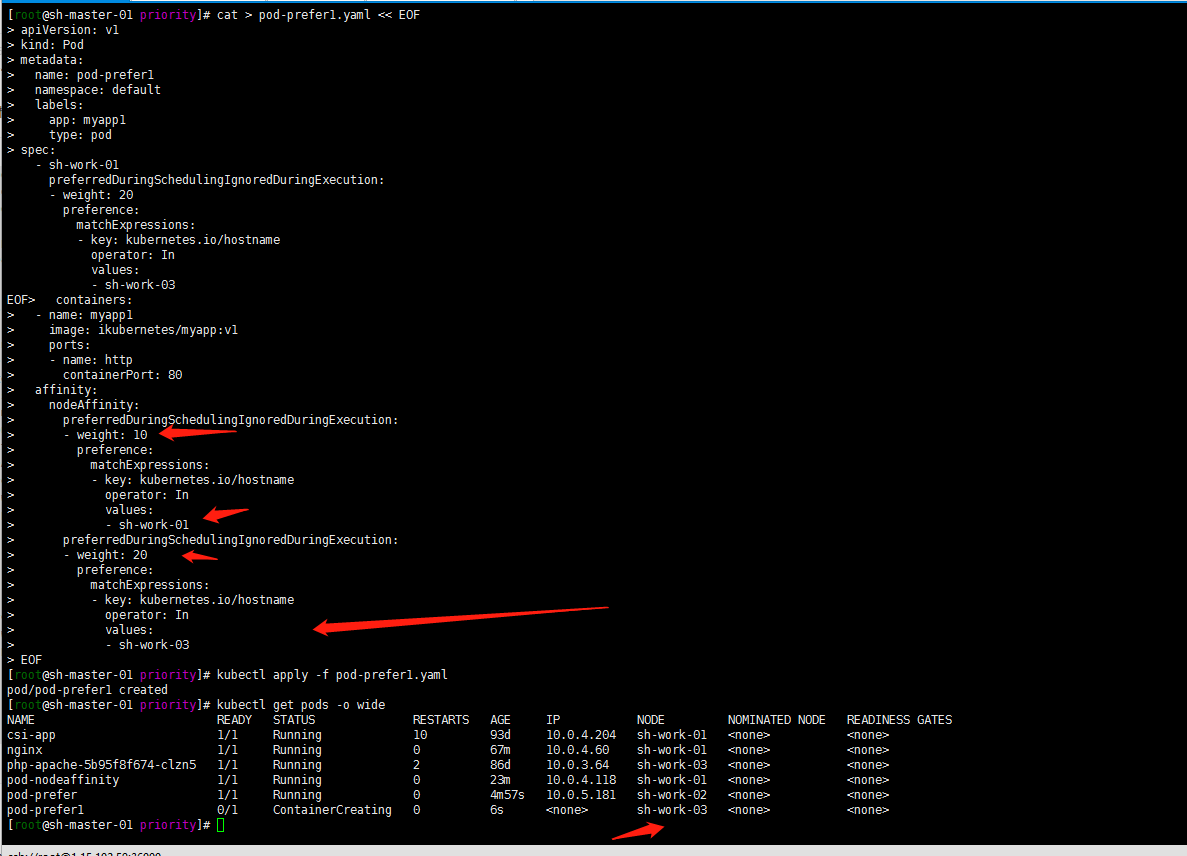
3. 至于软硬策略同时存在呢?
做一个例子同事存在软策略与硬策略
cat > pod-prefer2.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- sh-work-01
- sh-work-02
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: zone
operator: In
values:
- shanghai
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
EOF
kubectl apply -f pod-prefer2.yaml
kubectl get pods -o wide
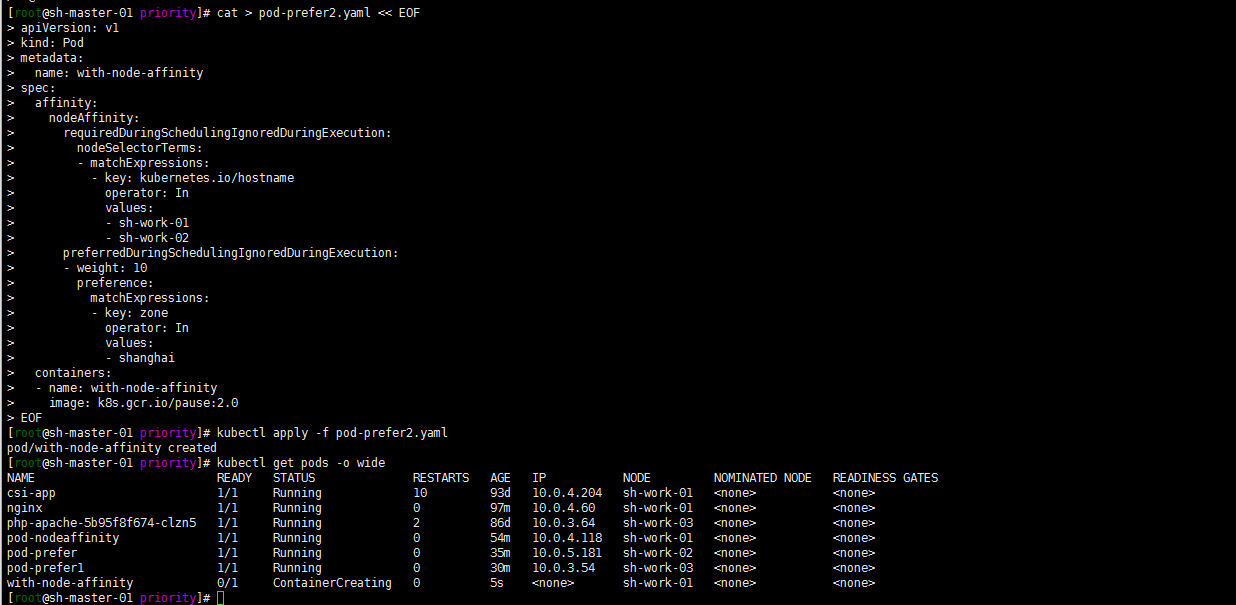
当然了不管preferredDuringSchedulingIgnoredDuringExecution中的值是什么,前提是要先满足requiredDuringSchedulingIgnoredDuringExecution中的values。
3. PodAfinity: Pod亲和性和互斥调度策略
Pod 间亲和性通过 PodSpec 中 affinity 字段下的 podAffinity 字段进行指定。 而 Pod 间反亲和性通过 PodSpec 中 affinity 字段下的 podAntiAffinity 字段进行指定。
主要还是用来让一些频繁调用互相依赖的pod尽可能部署在一台node或者相同区域,还有占用资源的pod互斥,分布在不同的节点或者区域。
举例子:
1.先部署一个带有标签security=S1 app=busybox的Pod
cat > pod-flag.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: pod-flag
namespace: default
labels:
app: busybox
security: S1
spec:
containers:
- name: busybox
image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
EOF
kubectl apply -f pod-flag.yaml
kubectl get pods --show-labels
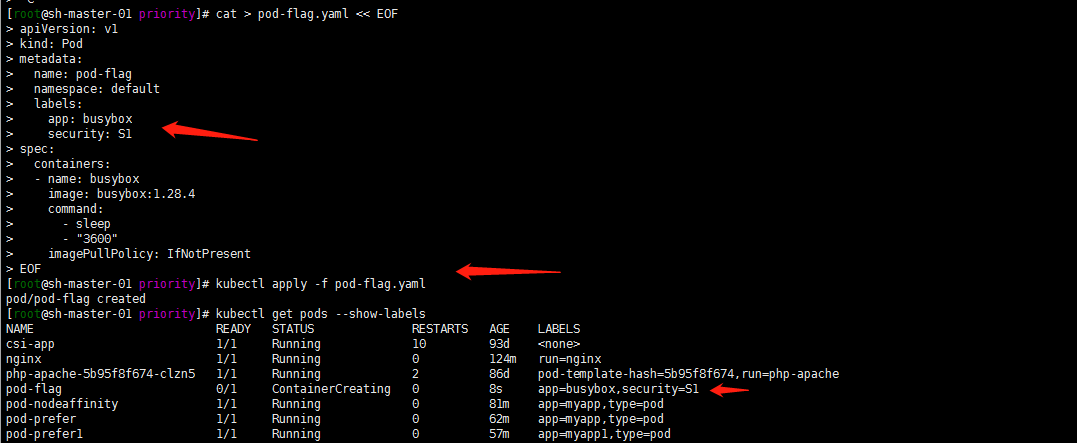
2. Pod 使用 pod 亲和性 的示例:
1. 软策略亲和性
cat > with-pod-affinity.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
EOF
kubectl apply -f with-pod-affinity.yaml
kubectl get pods -o wide
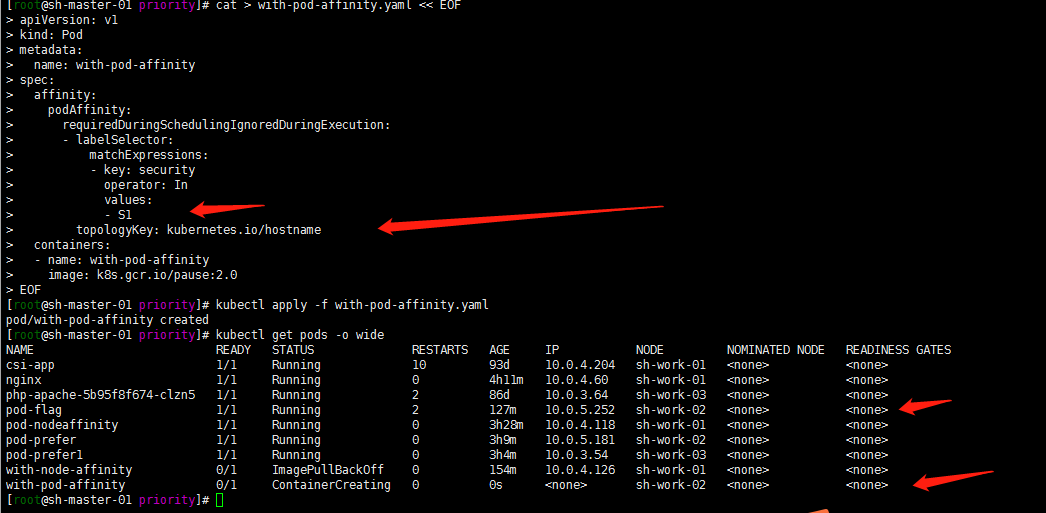
2. 关于topologyKey
顾名思义,topology 就是 拓扑 的意思,这里指的是一个 拓扑域,是指一个范围的概念,比如一个 Node、一个机柜、一个机房或者是一个地区(如杭州、上海)等,实际上对应的还是 Node 上的标签。这里的 topologyKey 对应的是 Node 上的标签的 Key(没有Value),可以看出,其实 topologyKey 就是用于筛选 Node 的。通过这种方式,我们就可以将各个 Pod 进行跨集群、跨机房、跨地区的调度了。没有搞多个区域zone就一个我这里现在。
原文链接:https://blog.csdn.net/asdfsadfasdfsa/article/details/106027367
3. 硬策略亲和性
强制要求
cat > with-pod-affinity1.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity1
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity1
image: k8s.gcr.io/pause:2.0
EOF
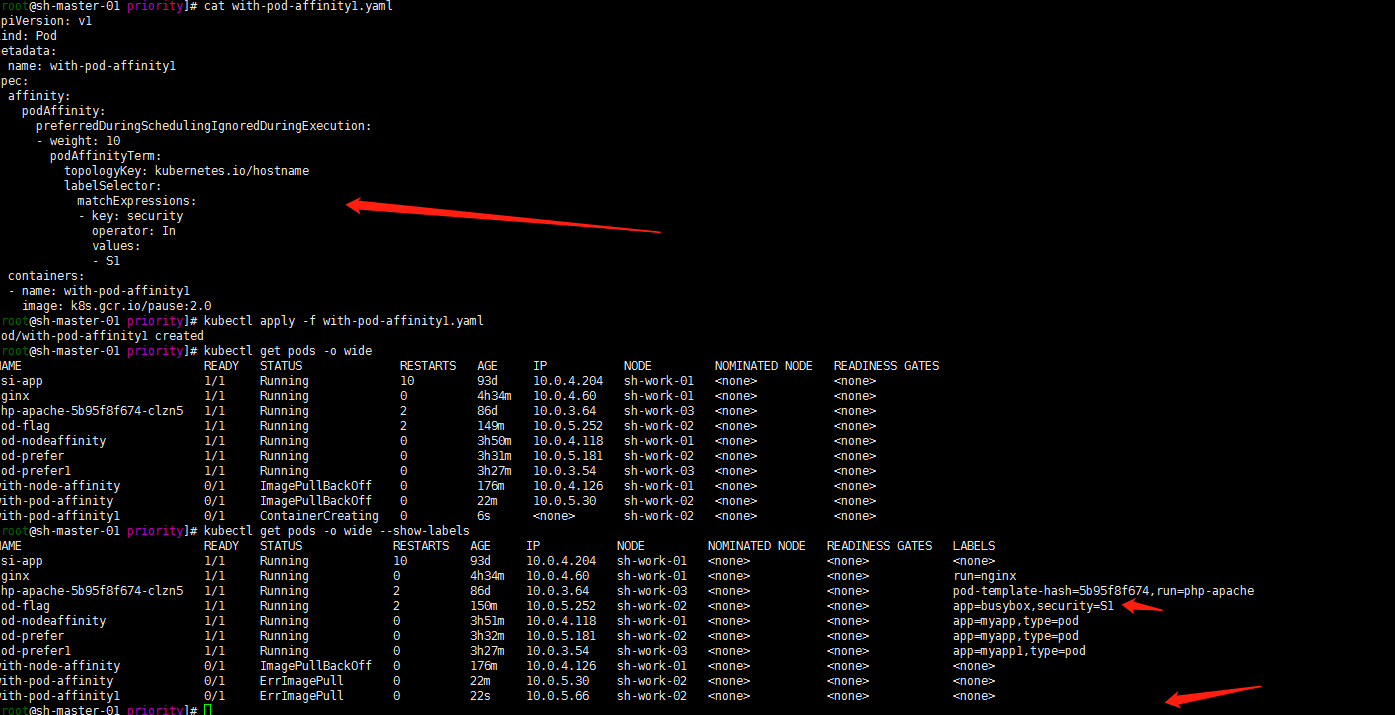
ErrImagePull忽略,用的官方例子没有改镜像image。正常的用nginx image就好了。
3. Pod的互斥性调度
Pod与security=S1处于同一个zone,不与app=busybox的 pod在同一个Node:
cat > with-pod-antiaffinity.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: with-pod-antiaffinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.com.tencent.cloud.csi.cbs/zone
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- busybox
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-antiaffinity
image: nginx
EOF
kubectl apply -f with-pod-antiaffinity.yaml
kubectl get pods -o wide --show-labels
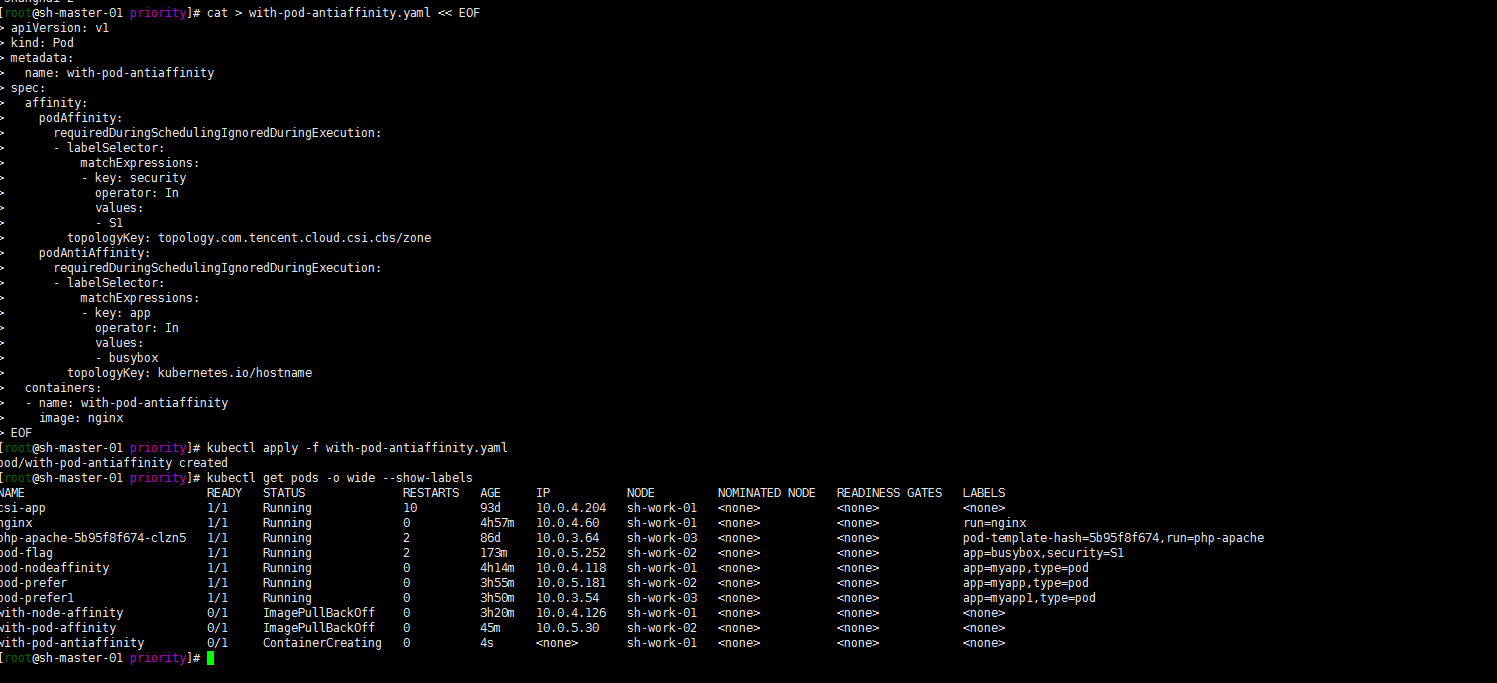
嗯 pod调度到了 sh-work-02之外的节点,这个地方还是有点绕,有时间再好好研究一下
4. Taints and Tolerations污点和容忍
1. 集群信息
[root@sh-master-01 priority]# kubectl get node
NAME STATUS ROLES AGE VERSION
sh-master-01 Ready control-plane,master 93d v1.21.1
sh-master-02 Ready control-plane,master 93d v1.21.1
sh-master-03 Ready control-plane,master 93d v1.21.1
sh-work-01 Ready <none> 93d v1.21.1
sh-work-02 Ready <none> 93d v1.21.1
sh-work-03 Ready <none> 93d v1.21.1
test-01 Ready,SchedulingDisabled <none> 86d v1.21.0
2.给sh-work-01节点打上污点(key=work、value=ops、effect=NoSchedule)
kubectl taint nodes sh-work-01 work=ops:NoSchedule
3. 整一个daemonset做测试吧 比较直观
cat > nginx-daemonset.yaml << EOF
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-1
namespace: default
labels:
web: nginx-1
spec:
selector:
matchLabels:
web: nginx-1
template:
metadata:
labels:
web: nginx-1
spec:
containers:
- name: nginx-1
image: nginx:1.17
ports:
- containerPort: 80
EOF
kubectl apply -f nginx-daemonset.yaml
kubectl get pods -o wide --show-labels
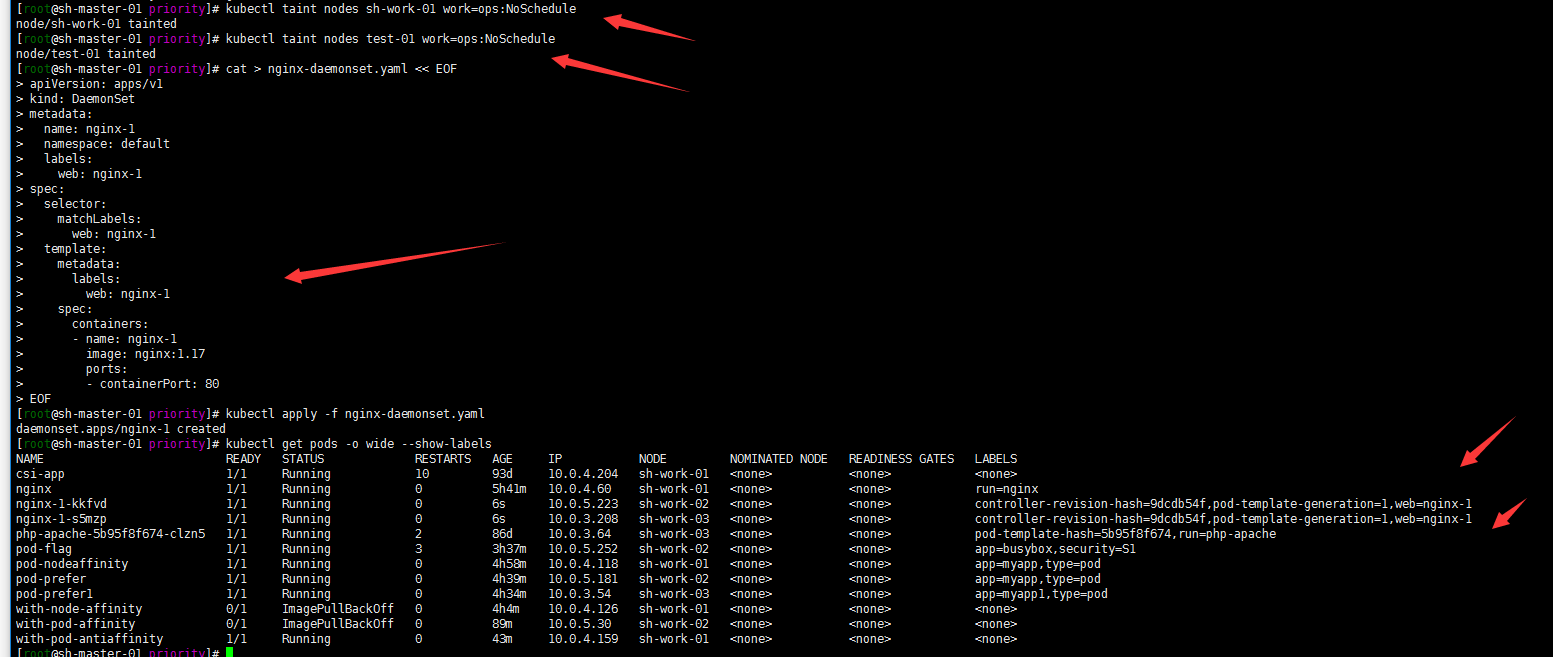
注: 我将test-01节点加上污点是因为我这个node是SchedulingDisabled的其实。但是daemonset也是会部署到IE点上去为了方便区分。
移除sh-work-01的污点看一下会发生什么:
[root@sh-master-01 priority]# kubectl taint nodes sh-work-01 work:NoSchedule-
node/sh-work-01 untainted
[root@sh-master-01 priority]# kubectl get pods -o wide --show-labels

嗯 去掉sh-work-01节点的污点标签。节点就恢复调度了。
4. 增加容忍度参数,进行测试
cat > nginx-daemonset-2.yaml << EOF
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-2
namespace: default
labels:
web: nginx-2
spec:
selector:
matchLabels:
web: nginx-2
template:
metadata:
labels:
web: nginx-2
spec:
containers:
- name: nginx-2
image: nginx:1.17
ports:
- containerPort: 80
tolerations:
- key: "work"
operator: "Equal"
value: "ops"
effect: "NoSchedule"
EOF
kubectl apply -f nginx-daemonset-2.yaml
kubectl get pods -o wide --show-labels
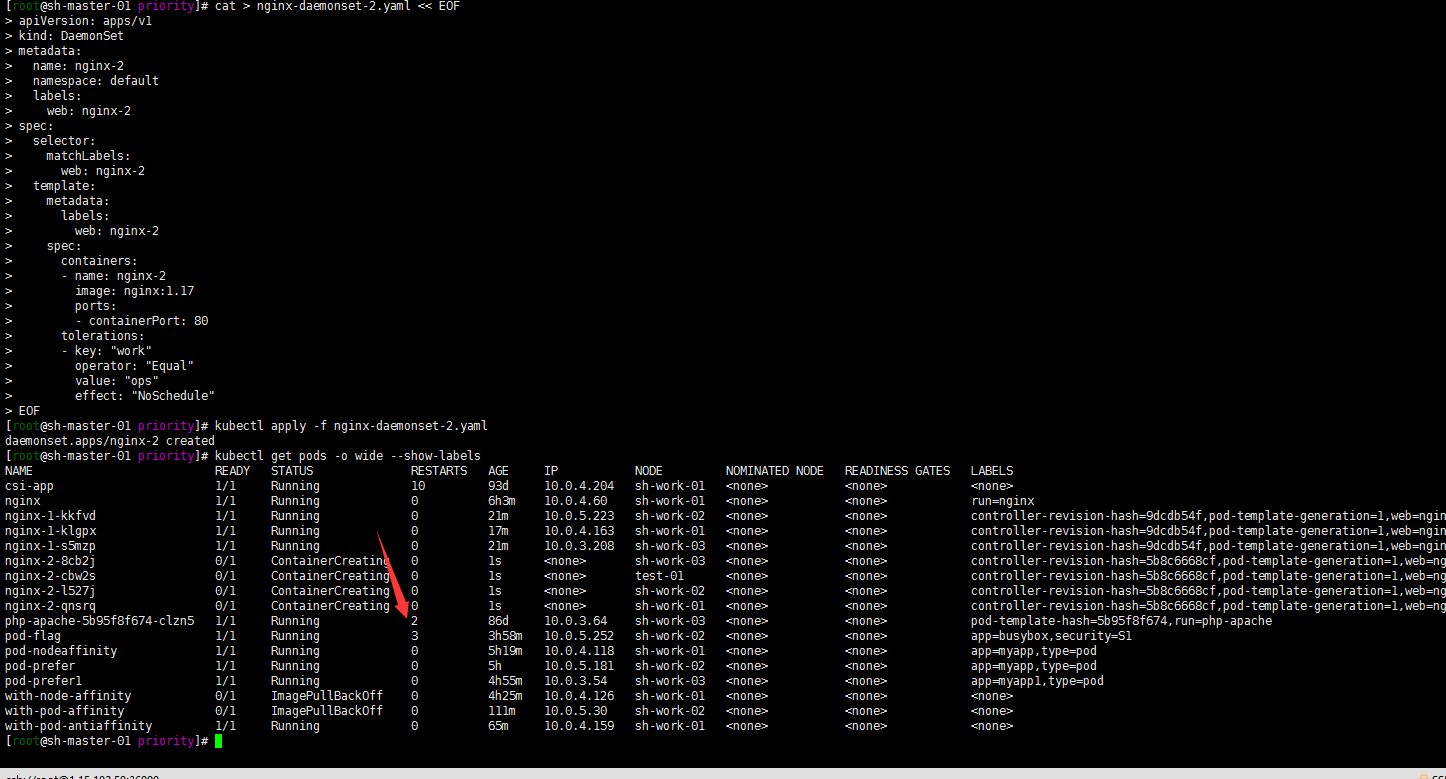
嗯污点节点都被调度了,包括test-01节点。这里在给test-01节点加个其他污点?反正就是不想让他被调度:
kubectl taint nodes test-01 work1=dev:NoSchedule
test-01节点中的pod仍未被驱逐
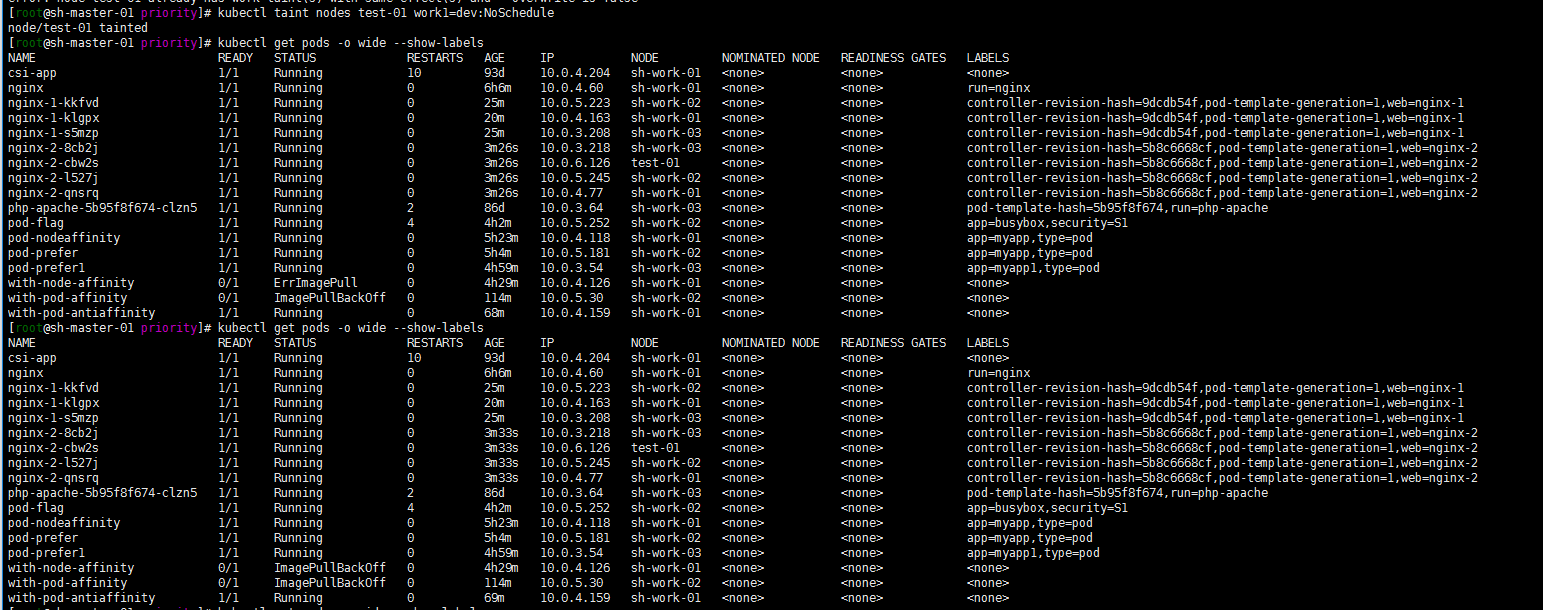
修改下work=ops的标签要不然?
kubectl taint nodes test-01 work=dev:NoSchedule --overwrite=true
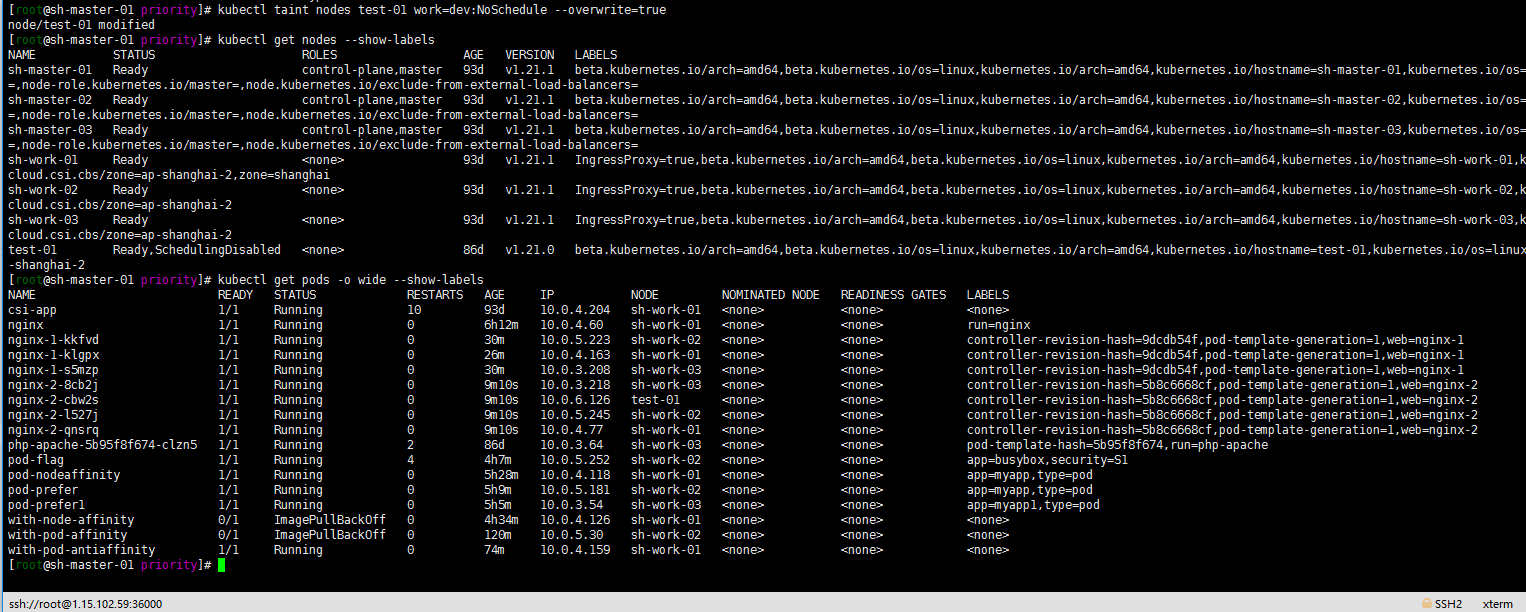
还是一样。
该怎么搞呢?
5. 修改test-01节点的污点,将effect修改为”NoExecute”,测试Pod是否会被驱逐
kubectl taint nodes test-01 work=dev:NoExecute --overwrite=true
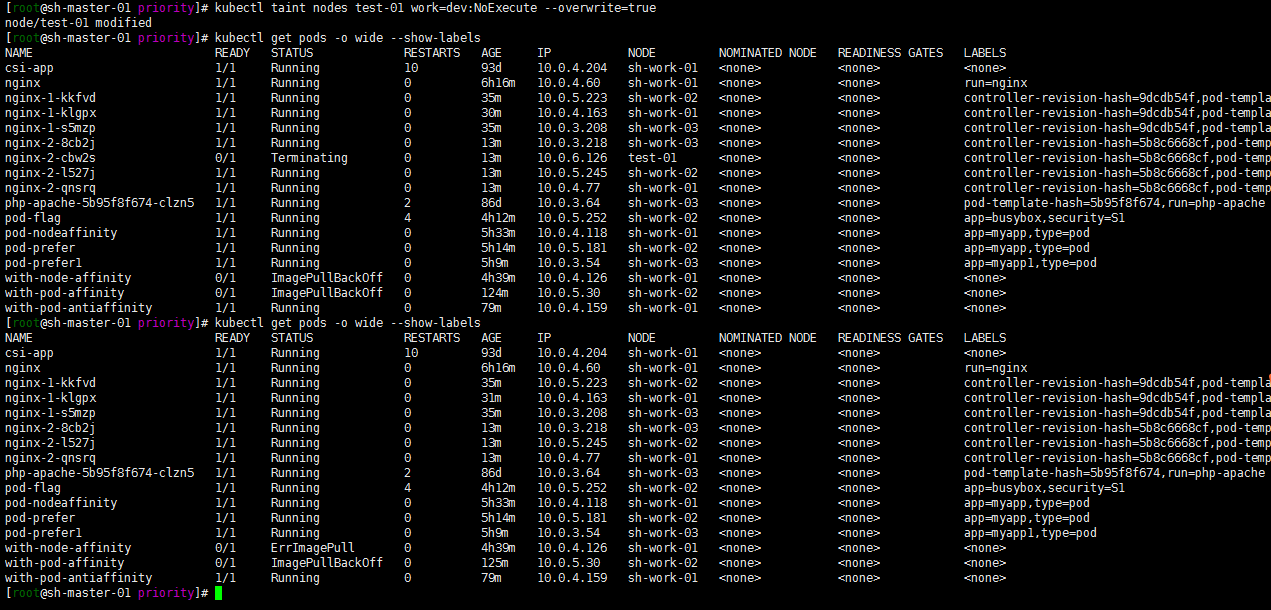
驱逐成功了……
关于Taints and Tolerations可以参照:https://www.jianjiacc.cn/archives/6fdbe877.html
总结一下:
- 创建集群应该进行合理的资源规划,对容量进行规划
- 可以根据pod的 qos进行资源的优先调度以及资源分配(当然了还是会有pod OOM)
- 可以通过节点打标签 亲和性反亲和性对资源进行合理调度,以免造成集群资源雪崩
- 不同kubernetes版本直接还是有些许的区别的,尽量还官方看文档吧!