Welcome to duiniwukenaihe's Blog!
这里记录着我的运维学习之路-
日志服务CLS初体验
-
Prometheus Operator 监控 Traefik V2.4
背景:
traefik搭建方式如下: https://www.yuque.com/duiniwukenaihe/ehb02i/odflm7 。 Prometheus-oprator搭建方式如下: https://www.yuque.com/duiniwukenaihe/ehb02i/tm6vl7。 Prometheus的文档写了grafana添加了traefik的监控模板。但是现在仔细一看。traefik的监控图是空的,Prometheus的 target也没有对应traefik的监控。 现在配置下添加traefik服务发现以及验证一下grafana的图表。
1. Prometheus Operator 监控 Traefik V2.4
1.1. Traefik 配置文件设置 Prometheus
参照https://www.yuque.com/duiniwukenaihe/ehb02i/odflm7。配置中默认开启了默认的Prometheus监控。
 https://doc.traefik.io/traefik/observability/metrics/prometheus/可参照traefik官方文档。
https://doc.traefik.io/traefik/observability/metrics/prometheus/可参照traefik官方文档。1.2、Traefik Service 设置标签
1.2.1 查看traefik service
$ kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE cilium-agent ClusterIP None <none> 9095/TCP 15d etcd-k8s ClusterIP None <none> 2379/TCP 8d hubble-metrics ClusterIP None <none> 9091/TCP 15d hubble-relay ClusterIP 172.254.38.50 <none> 80/TCP 15d hubble-ui ClusterIP 172.254.11.239 <none> 80/TCP 15d kube-controller-manager ClusterIP None <none> 10257/TCP 8d kube-controller-manager-svc ClusterIP None <none> 10252/TCP 6d kube-dns ClusterIP 172.254.0.10 <none> 53/UDP,53/TCP,9153/TCP 15d kube-scheduler ClusterIP None <none> 10259/TCP 8d kube-scheduler-svc ClusterIP None <none> 10251/TCP 6d kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 8d traefik ClusterIP 172.254.12.88 <none> 80/TCP,443/TCP,8080/TCP 11d1.2.2、编辑该 Service 设置 Label
kubectl edit service traefik -n kube-system设置 Label “app: traefik”
 参照的是traefik-deploy.yaml 中的app:traefik这个标签用了,当然了也可以自己定义下用下别的……
参照的是traefik-deploy.yaml 中的app:traefik这个标签用了,当然了也可以自己定义下用下别的……

1.3、Prometheus Operator 配置监控规则
traefik-service-monitoring.yaml
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: traefik namespace: monitoring labels: app: traefik spec: jobLabel: traefik-metrics selector: matchLabels: app: traefik namespaceSelector: matchNames: - kube-system endpoints: - port: admin path: /metrics创建该Service Monitor
$ kubectl apply -f traefik-monitor.yaml1.4、查看 Prometheus target规则是否生效

1.5 查看grafana中的traefik仪表盘是否有数据生成图表
 嗯 这也算是添加target的一个例子。下次写下配置下自动发现规则?
嗯 这也算是添加target的一个例子。下次写下配置下自动发现规则?
-
Kubernetes 1.20.5 安装gitlab
- 前言:
- 1. 创建gitlab搭建过程中所需要的pvc
- 2. gitlab-redis搭建
- 3.gitlab-postgresql搭建
- 4. gitlab deployment搭建
- 5. ingress配置
- 6. 关闭用户注册,更改默认语言为中文。
前言:
参照https://www.yuque.com/duiniwukenaihe/ehb02i内https://www.yuque.com/duiniwukenaihe/ehb02i/qz49ev之前文章。要完成kubernetes devops工作流的完成。前面已经搭建了jenkins。gitlab代码仓库也是必不可缺少的。现在搞一下gitlab,关于helm前面也做了详细的讲述,这里略过了。另外之前gitlab版本没有中文版本可参照https://hub.docker.com/r/twang2218/gitlab-ce-zh/ twang2218的汉化版本。现在的gitlab已经支持多语言了,可以略过。下面就开始安装gitlab。看了一眼helm的安装方式…文章较少。还是决定老老实实yaml方式安装了
1. 创建gitlab搭建过程中所需要的pvc
初步规划:存储storageclass是用的腾讯云开源的cbs-csi插件,由于最小值只能是10G,redis postgresql就设置为10G了。特意强调下 pvc指定namespace。昨天手贱安装kubesphere玩下了,结果发现他自带的Prometheus把我的pv,pvc抢占了….不知道这是cbs的坑还是自己搭建方式有问题。最后用户名密码一直错误。卸载了,不玩了……
cat gitlab-pvc.yaml
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gitlab-pvc namespace: kube-ops spec: accessModes: - ReadWriteOnce resources: requests: storage: 100Gi storageClassName: cbs-csicat gitlab-redis-pvc.yaml
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gitlab-redis-pvc namespace: kube-ops spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: cbs-csicat gitlab-pg-pvc.yaml
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gitlab-pg-pvc namespace: kube-ops spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: cbs-csi在当前目录下执行
kubectl apply -f .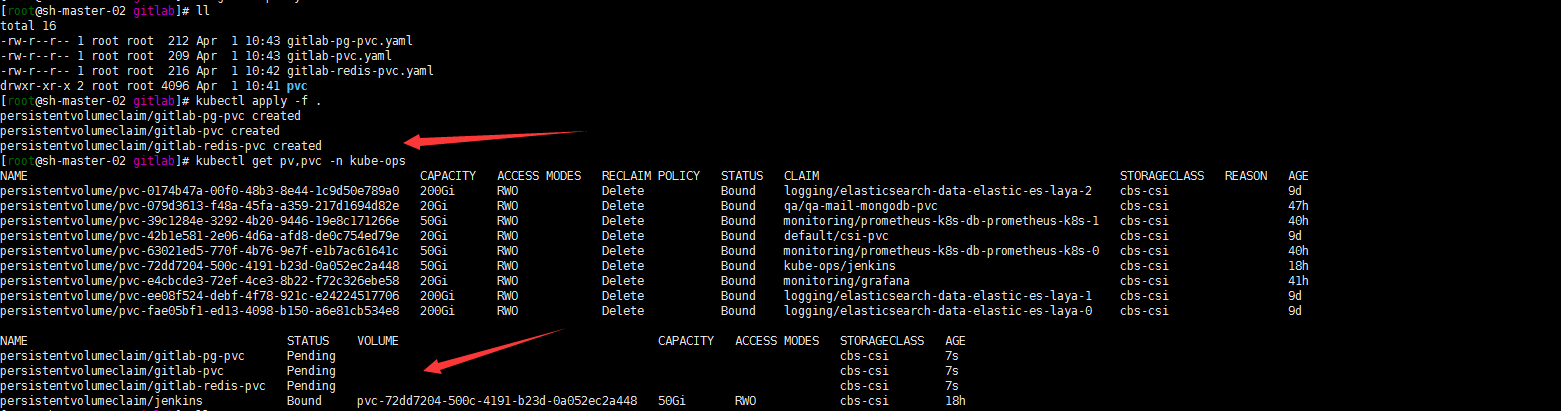
2. gitlab-redis搭建
注: 特意指定了namespace,否则执行kubectl apply -f yaml文件的时候经常会忘掉指定namespace ,claimName 修改为自己创建的pvc。
cat redis.yaml
## Service kind: Service apiVersion: v1 metadata: name: gitlab-redis namespace: kube-ops labels: name: gitlab-redis spec: type: ClusterIP ports: - name: redis protocol: TCP port: 6379 targetPort: redis selector: name: gitlab-redis --- ## Deployment kind: Deployment apiVersion: apps/v1 metadata: name: gitlab-redis namespace: kube-ops labels: name: gitlab-redis spec: replicas: 1 selector: matchLabels: name: gitlab-redis template: metadata: name: gitlab-redis labels: name: gitlab-redis spec: containers: - name: gitlab-redis image: 'sameersbn/redis:4.0.9-3' ports: - name: redis containerPort: 6379 protocol: TCP resources: limits: cpu: 1000m memory: 2Gi requests: cpu: 1000m memory: 2Gi volumeMounts: - name: data mountPath: /var/lib/redis livenessProbe: exec: command: - redis-cli - ping initialDelaySeconds: 5 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 3 readinessProbe: exec: command: - redis-cli - ping initialDelaySeconds: 5 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 3 volumes: - name: data persistentVolumeClaim: claimName: gitlab-redis-pvckubectl apply -f redis.yaml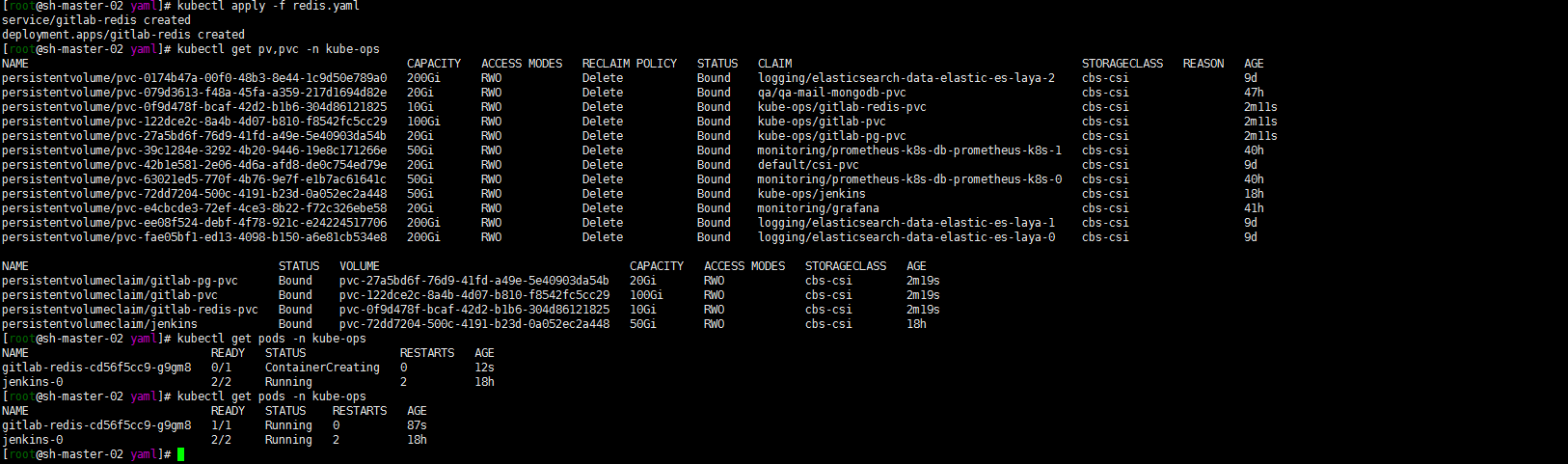 等待创建完成running。
等待创建完成running。3.gitlab-postgresql搭建
同redis 配置一样修改pg配置.
cat pg.yaml
## Service kind: Service apiVersion: v1 metadata: name: gitlab-postgresql namespace: kube-ops labels: name: gitlab-postgresql spec: ports: - name: postgres protocol: TCP port: 5432 targetPort: postgres selector: name: postgresql type: ClusterIP --- ## Deployment kind: Deployment apiVersion: apps/v1 metadata: name: postgresql namespace: kube-ops labels: name: postgresql spec: replicas: 1 selector: matchLabels: name: postgresql template: metadata: name: postgresql labels: name: postgresql spec: containers: - name: postgresql image: sameersbn/postgresql:12-20200524 ports: - name: postgres containerPort: 5432 env: - name: DB_USER value: gitlab - name: DB_PASS value: admin@mydlq - name: DB_NAME value: gitlabhq_production - name: DB_EXTENSION value: 'pg_trgm,btree_gist' resources: requests: cpu: 2 memory: 2Gi limits: cpu: 2 memory: 2Gi livenessProbe: exec: command: ["pg_isready","-h","localhost","-U","postgres"] initialDelaySeconds: 30 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 3 readinessProbe: exec: command: ["pg_isready","-h","localhost","-U","postgres"] initialDelaySeconds: 5 timeoutSeconds: 1 periodSeconds: 10 successThreshold: 1 failureThreshold: 3 volumeMounts: - name: data mountPath: /var/lib/postgresql volumes: - name: data persistentVolumeClaim: claimName: gitlab-pg-pvckubectl apply -f pg.yaml
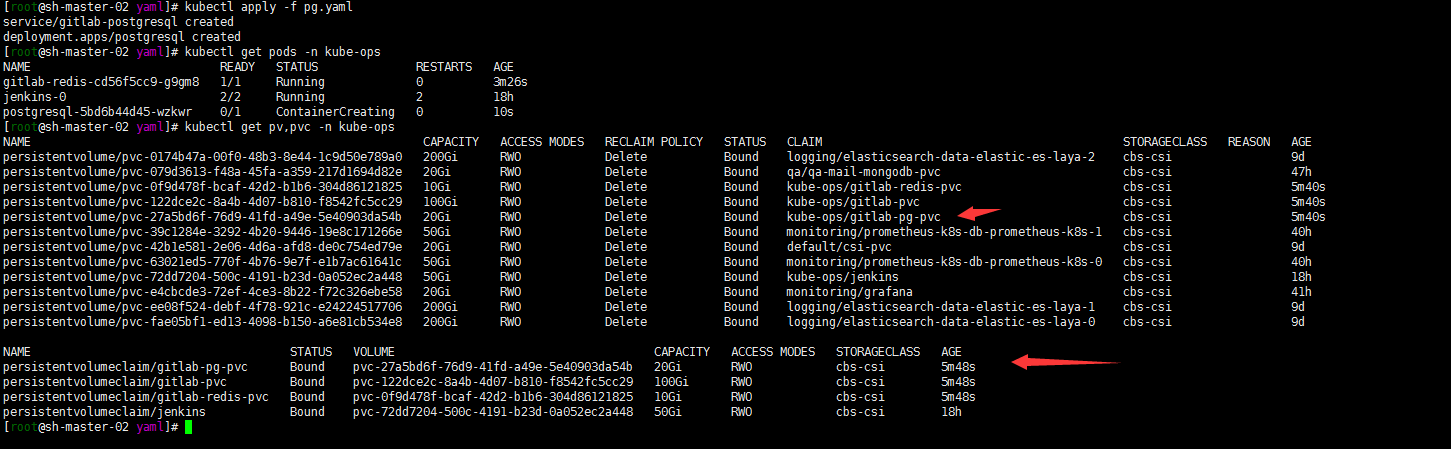
4. gitlab deployment搭建
cat gitlab.yaml
## Service kind: Service apiVersion: v1 metadata: name: gitlab namespace: kube-ops labels: name: gitlab spec: ports: - name: http protocol: TCP port: 80 - name: ssh protocol: TCP port: 22 selector: name: gitlab type: ClusterIP --- ## Deployment kind: Deployment apiVersion: apps/v1 metadata: name: gitlab namespace: kube-ops labels: name: gitlab spec: replicas: 1 selector: matchLabels: name: gitlab template: metadata: name: gitlab labels: name: gitlab spec: containers: - name: gitlab image: 'sameersbn/gitlab:13.6.2' ports: - name: ssh containerPort: 22 - name: http containerPort: 80 - name: https containerPort: 443 env: - name: TZ value: Asia/Shanghai - name: GITLAB_TIMEZONE value: Beijing - name: GITLAB_SECRETS_DB_KEY_BASE value: long-and-random-alpha-numeric-string - name: GITLAB_SECRETS_SECRET_KEY_BASE value: long-and-random-alpha-numeric-string - name: GITLAB_SECRETS_OTP_KEY_BASE value: long-and-random-alpha-numeric-string - name: GITLAB_ROOT_PASSWORD value: admin@mydlq - name: GITLAB_ROOT_EMAIL value: 820042728@qq.com - name: GITLAB_HOST value: 'gitlab.saynaihe.com' - name: GITLAB_PORT value: '80' - name: GITLAB_SSH_PORT value: '22' - name: GITLAB_NOTIFY_ON_BROKEN_BUILDS value: 'true' - name: GITLAB_NOTIFY_PUSHER value: 'false' - name: DB_TYPE value: postgres - name: DB_HOST value: gitlab-postgresql - name: DB_PORT value: '5432' - name: DB_USER value: gitlab - name: DB_PASS value: admin@mydlq - name: DB_NAME value: gitlabhq_production - name: REDIS_HOST value: gitlab-redis - name: REDIS_PORT value: '6379' resources: requests: cpu: 2 memory: 4Gi limits: cpu: 2 memory: 4Gi livenessProbe: httpGet: path: / port: 80 scheme: HTTP initialDelaySeconds: 300 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 3 readinessProbe: httpGet: path: / port: 80 scheme: HTTP initialDelaySeconds: 5 timeoutSeconds: 30 periodSeconds: 10 successThreshold: 1 failureThreshold: 3 volumeMounts: - name: data mountPath: /home/git/data - name: localtime mountPath: /etc/localtime volumes: - name: data persistentVolumeClaim: claimName: gitlab-pvc - name: localtime hostPath: path: /etc/localtime基本抄的豆丁大佬的文档。但是删掉了NodePort的方式。还是喜欢用ingress的代理方式。密码 用户名配置的可以安装自己的需求更改了。
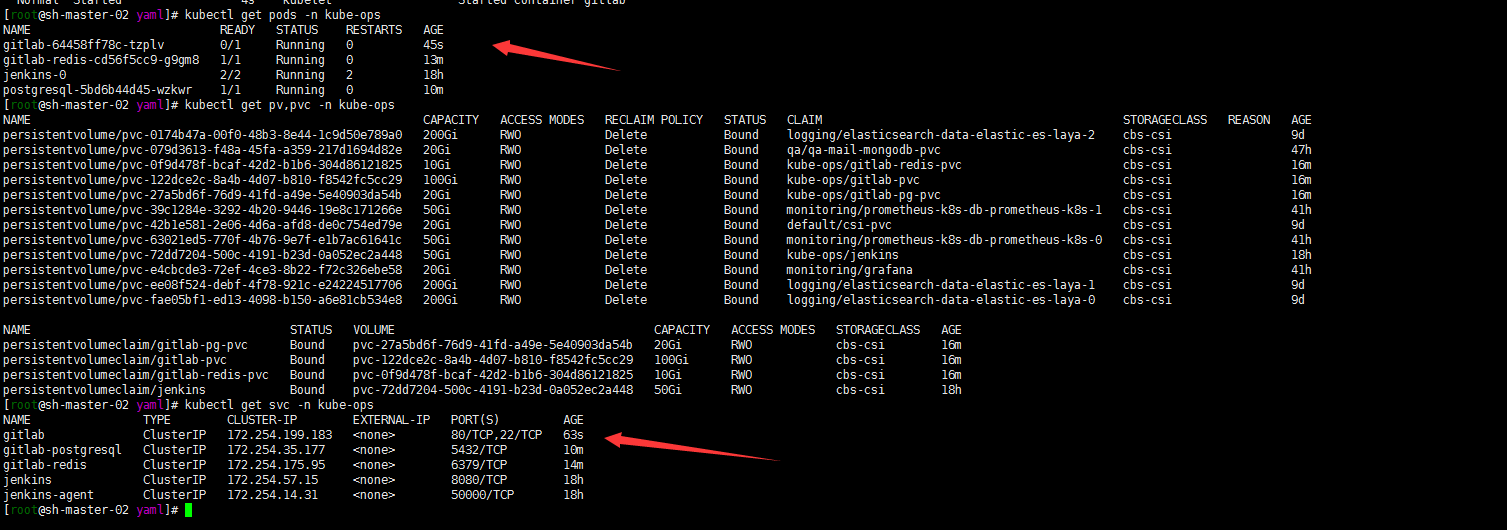 等待running……
等待running……5. ingress配置
cat ingress.yaml
apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: gitlab-http spec: entryPoints: - web routes: - match: Host(`gitlab.saynaine.com`) kind: Rule services: - name: gitlab port: 80kubectl apply -f ingress.yaml 访问 gitlab.saynaihe.com(域名仍然为虚构.)。都做了强制跳转了。故访问的伟http页面默认用户名root,密码是自己gitlab.yaml文件中设置的。(至于显示中文,是因为我的谷歌浏览器安装了中文翻译插件)
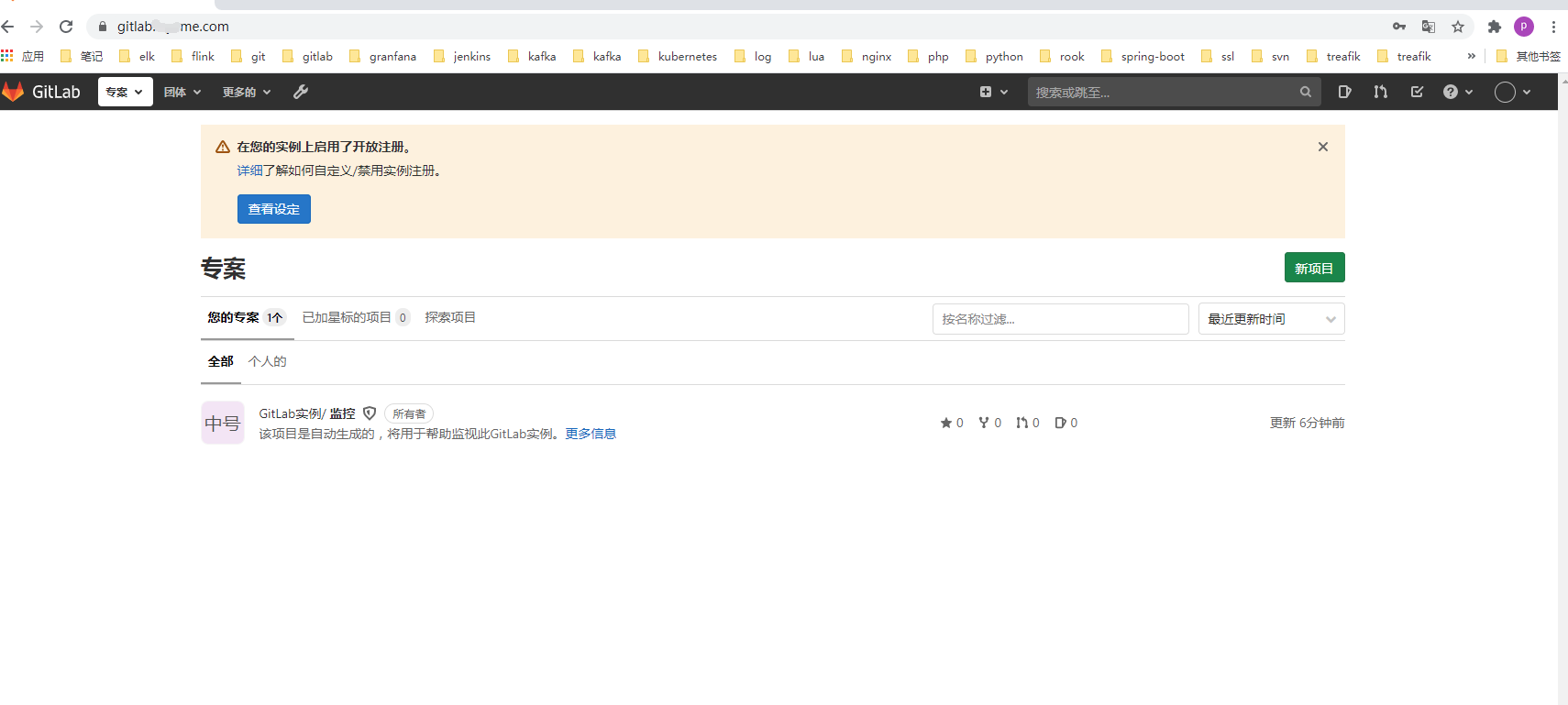 OK,登陆成功
OK,登陆成功6. 关闭用户注册,更改默认语言为中文。
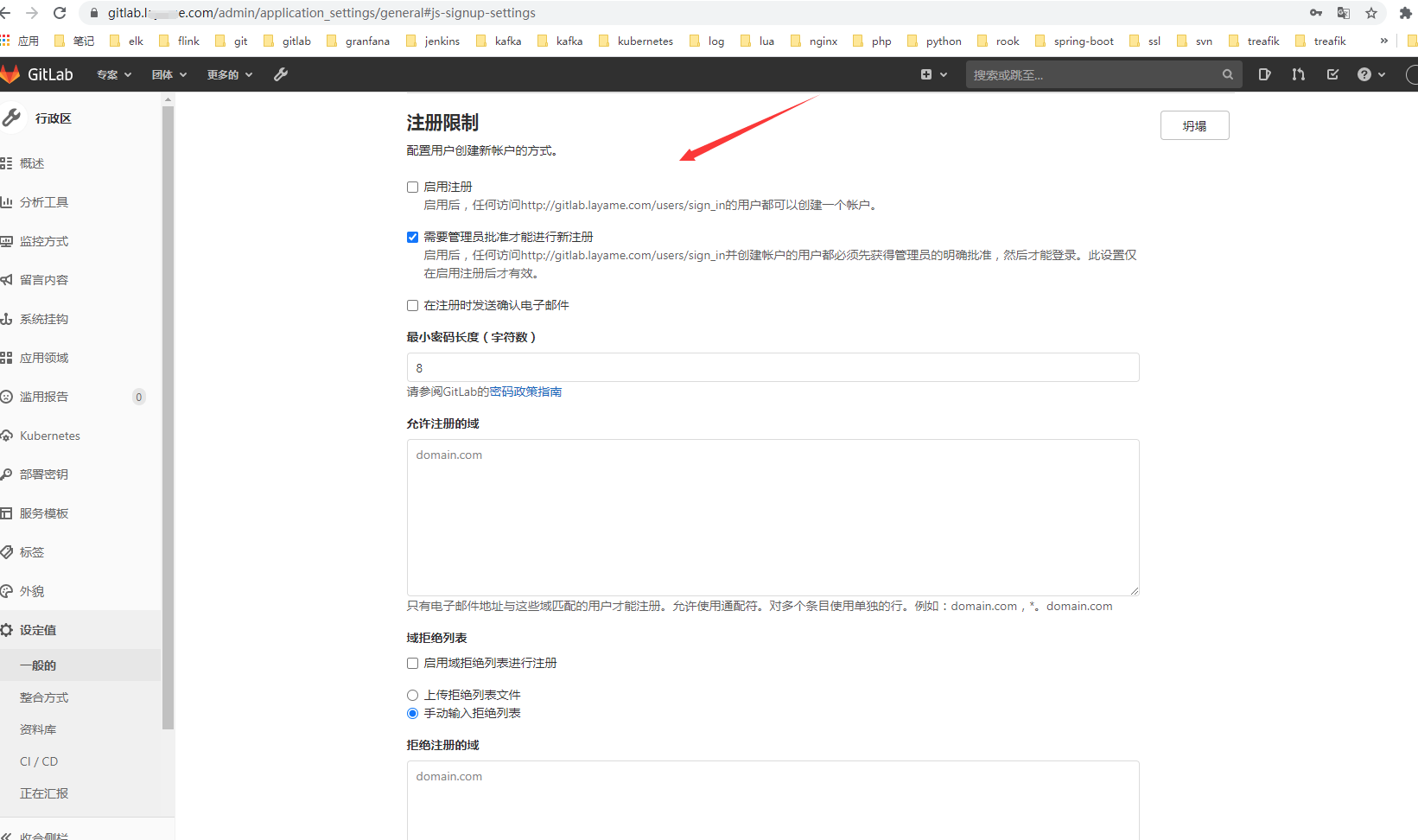
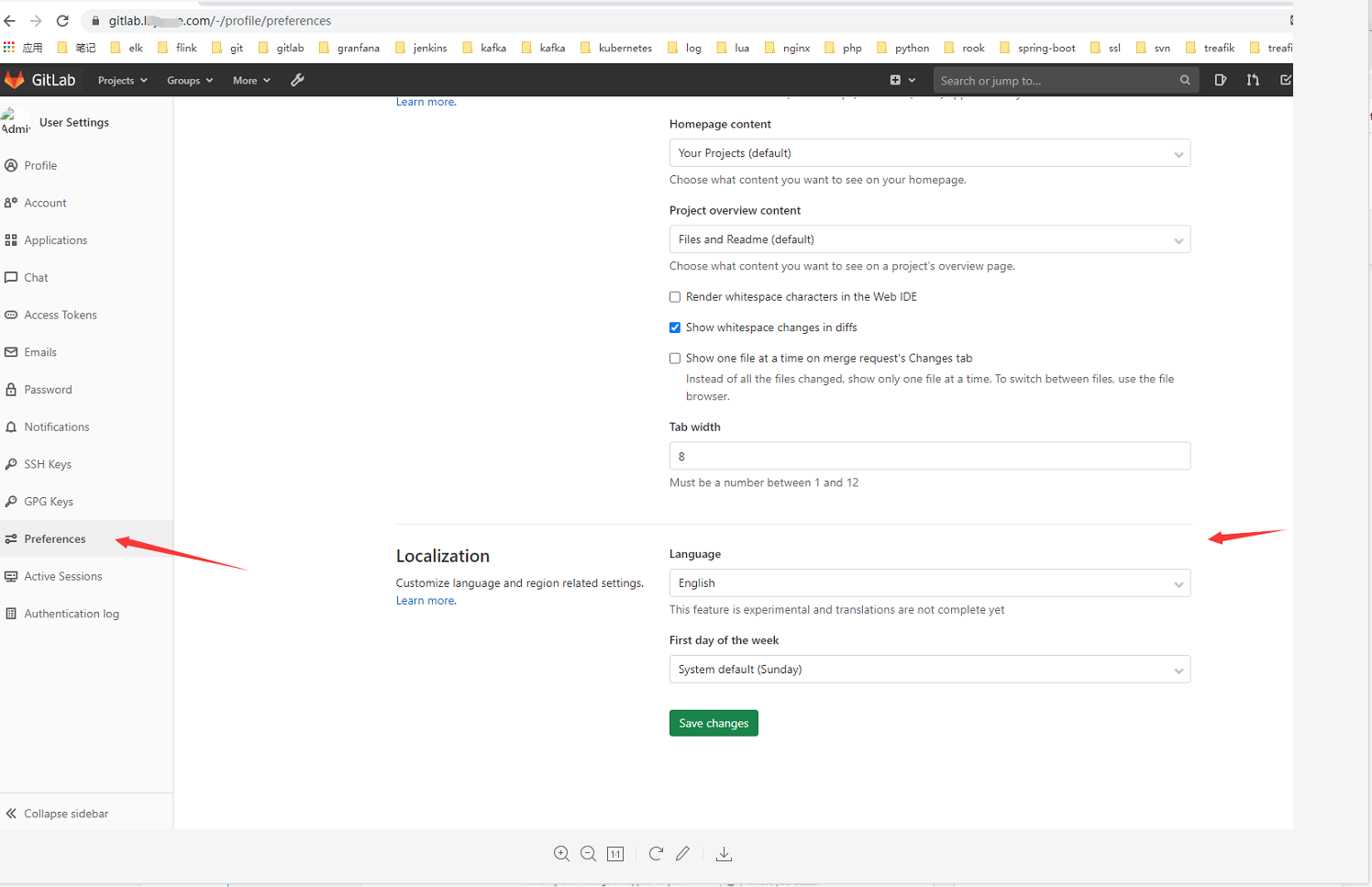
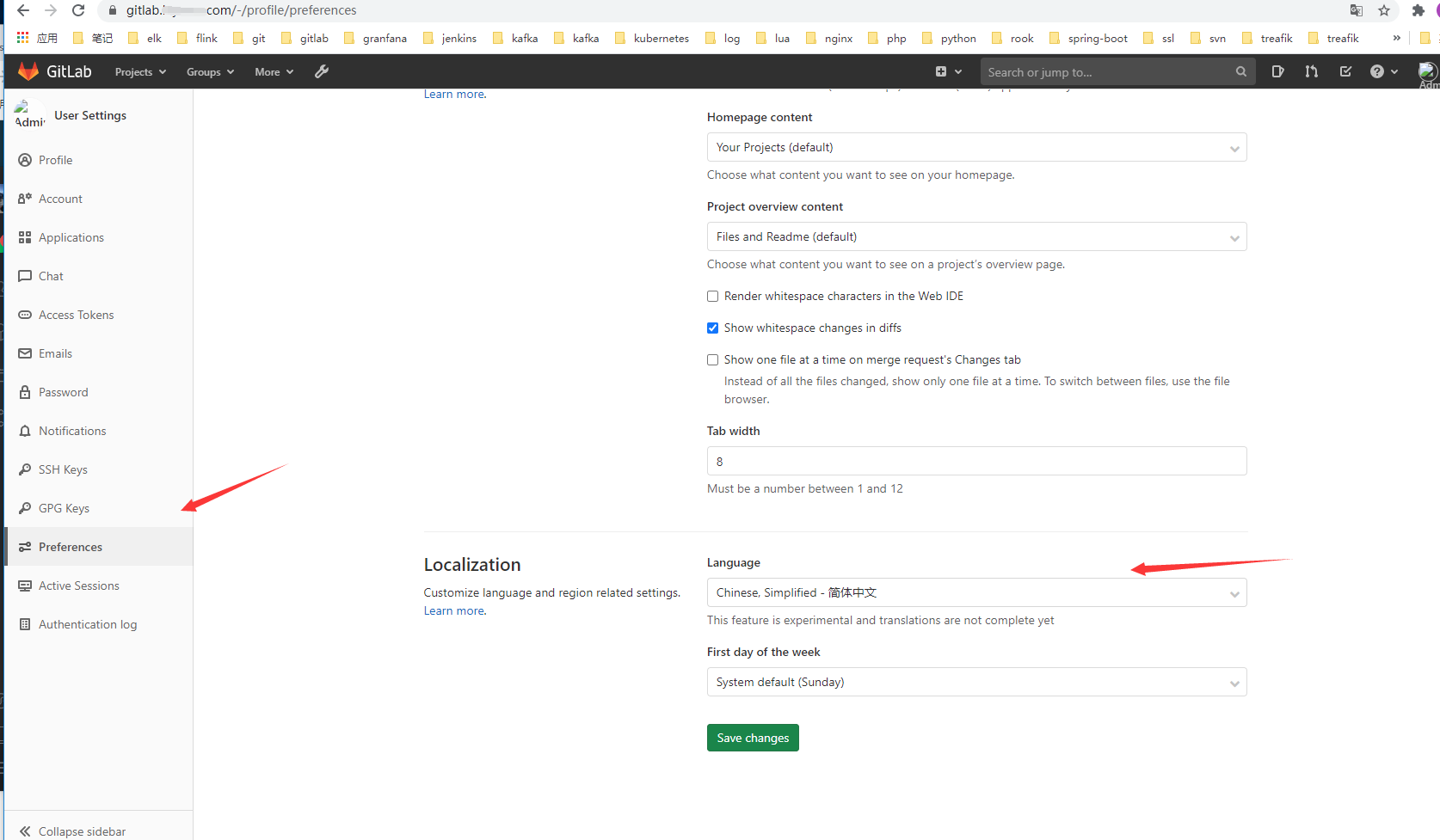
 基本安装完成。其他的用法以后慢慢研究……. 现在就是先把工具链安装整合起来。对了gitlab 登陆后记得更改用户名密码….增加个人安全意识是很有必要的。
基本安装完成。其他的用法以后慢慢研究……. 现在就是先把工具链安装整合起来。对了gitlab 登陆后记得更改用户名密码….增加个人安全意识是很有必要的。
-
Kubernetes 1.20.5 helm 安装jenkins
初始环境 kubeadm 搭建kubenretes 1.20.5 集群如下
 前面https://www.yuque.com/duiniwukenaihe/ehb02i/dkwh3p的时候安装了cilium hubble的时候安装了helm3.
存储集成了腾讯云的cbs块存储
网络? traefik代理(纯http,证书都交给腾讯云负载均衡clb了)
准备集成规划一下cicd还是走一遍传统的jenkins github spinnaker这几样的集成了。先搭建下基础的环境。就从jenkins开始了
前面https://www.yuque.com/duiniwukenaihe/ehb02i/dkwh3p的时候安装了cilium hubble的时候安装了helm3.
存储集成了腾讯云的cbs块存储
网络? traefik代理(纯http,证书都交给腾讯云负载均衡clb了)
准备集成规划一下cicd还是走一遍传统的jenkins github spinnaker这几样的集成了。先搭建下基础的环境。就从jenkins开始了1. 再次重复一下helm3的安装
1. 下载helm应用程序
https://github.com/helm/helm/releases现在最新版本 3.5.3吧? 找到对应系统平台的包下载

2. 安装helm
上传tar.gz包到服务器(我是master节点随机了都可以的)
tar zxvf helm-v3.5.3-linux-amd64.tar.gz mv linux-amd64/helm /usr/bin/helmok helm 安装成功

2. jenkins的配置与安装
2.1. helm 添加jenkins仓库。并pull 下jenkins版本包
helm repo add jenkins https://charts.jenkins.io helm pull jenkins/jenkins #我的版本还是3.3.0其他版本也是同理 tar zxvf jenkins-3.3.0.tgz2.2. 根据个人需求更改value.yaml
cd jenkins目录,将values.yaml安装个人需求改一下 个人就修改了clusterZone和默认存储使用了腾讯云的cbs.


3. helm安装jenkins到指定namespace
3.1. 正常的安装过程
kubectl create ns kube-ops helm install -f values.yaml jenkins jenkins/jenkins -n kube-ops
3.2. 安装中int 下载插件等待时间过长的坑
下载插件很坑,等不了时间可以把value.yaml文件中安装插件的过程注释掉。
 注释掉install的插件后面手动安装吧
注释掉install的插件后面手动安装吧

我是直接注释掉然后删除helm部署程序重新来了一次。
helm delete jenkins -n kube-ops helm install -f values.yaml jenkins jenkins/jenkins -n kube-ops果然注释掉直接就启动了
4. 初始化后的一些事情
4.1. 等待pod 初始化启动完成

4.2 初始化密码在log中查找
先传统方式找一遍密码:
kubectl logs -f jenkins-0 jenkins -n kube-ops嗯密码不在log中的

4.3. 正确获取jenkins初始密码的方式secret
printf $(kubectl get secret --namespace kube-ops jenkins -o jsonpath="{.data.jenkins-admin-password}" | base64 --decode);echo5. traefik 代理jenkins应用
(https://www.yuque.com/duiniwukenaihe/ehb02i/odflm7前文已经注明搭建与代理方式)
 还是习惯ingressroute代理jenkins
cat jenkins-ingress.yaml
还是习惯ingressroute代理jenkins
cat jenkins-ingress.yamlapiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: kube-ops name: jenkins-http spec: entryPoints: - web routes: - match: Host(`jenkins.saynaihe.com`) kind: Rule services: - name: jenkins port: 8080kubectl apply -f jenkins-ingress.yaml
6. web访问jenkins应用
6.1. 登陆jenkins web
 what没有输入账号密码啊?也不整明白为什么初始化后第一次登陆不用密码就可以进入…….
what没有输入账号密码啊?也不整明白为什么初始化后第一次登陆不用密码就可以进入…….6.2 更改安全设置,不允许用户匿名登陆
 创建初始管理员用户
创建初始管理员用户

6.3 安装中文插件
 OK开始安装插件吧,先安装中文插件,安装完重启….
OK开始安装插件吧,先安装中文插件,安装完重启….
 中文插件安装完成。嗯到这里我个人设置的密码还是有效的……
中文插件安装完成。嗯到这里我个人设置的密码还是有效的……

6.4 安装一下helm 初始化过程中屏蔽的插件
然后吧helm中屏蔽掉的初始化插件手工安装一下?就手动先安装一下下面这四个插件。也是常用的kubernetes插件 .
 等待完成后。重启jenkins应用
等待完成后。重启jenkins应用

7. 彩蛋
嗯 重启后我的密码错误了…what
-
Kubernetes 1.20.5 安装Prometheus-Oprator
- 背景
- 1. prometheus环境的搭建
背景
线上kubernetes集群为1.16版本 Prometheus oprator 分支为0.4关于Prometheus oprator与kubernetes版本对应关系如下图。可见https://github.com/prometheus-operator/kube-prometheus. 注: Prometheus operator? kube-prometheus? kube-prometheus 就是 Prometheus的一种operator的部署方式….Prometheus-operator 已经改名为 Kube-promethues。
 关于部署过程可以参考超级小豆丁大佬的笔记:http://www.mydlq.club/article/10/。Prometheus这种架构图,在各位大佬的文章中都可以看到的…….
关于部署过程可以参考超级小豆丁大佬的笔记:http://www.mydlq.club/article/10/。Prometheus这种架构图,在各位大佬的文章中都可以看到的……. 先简单部署一下Prometheus oprator(or或者叫kube-promethus)。完成微信报警的集成,其他的慢慢在生成环境中研究。
基本过程就是Prometheus oprator 添加存储,增加微信报警,外部traefik代理应用。
先简单部署一下Prometheus oprator(or或者叫kube-promethus)。完成微信报警的集成,其他的慢慢在生成环境中研究。
基本过程就是Prometheus oprator 添加存储,增加微信报警,外部traefik代理应用。1. prometheus环境的搭建
1. 克隆prometheus-operator仓库
git clone https://github.com/prometheus-operator/kube-prometheus.git 网络原因,经常会搞不下来的,还是直接下载zip包吧,其实安装版本的支持列表kubernetes1.20的版本可以使用kube-prometheus的0.6 or 0.7 还有HEAD分支的任一分支。偷个懒直接用HEAD了。
记录一下tag,以后有修改了也好能快速修改了 让版本升级跟得上…..
网络原因,经常会搞不下来的,还是直接下载zip包吧,其实安装版本的支持列表kubernetes1.20的版本可以使用kube-prometheus的0.6 or 0.7 还有HEAD分支的任一分支。偷个懒直接用HEAD了。
记录一下tag,以后有修改了也好能快速修改了 让版本升级跟得上…..
 上传zip包解压缩
上传zip包解压缩unzip kube-prometheus-main.zip
2. 按照快捷方式来一遍
cd kube-prometheus-main/ kubectl create -f manifests/setup until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done kubectl create -f manifests/ kubectl get pods -n monitoring

3. imagepullbackoff
由于网络原因会出现有些镜像下载不下来的问题,可墙外服务器下载镜像修改tag上传到harbor,修改yaml文件中镜像为对应私有镜像仓库的标签tag解决(由于我的私有仓库用的腾讯云的仓库,现在跨地域上传镜像应该个人版的不可以了,所以我使用了docker save导出镜像的方式):

kubectl describe pods kube-state-metrics-56f988c7b6-qxqjn -n monitoring
1. 使用国外服务器下载镜像,并打包为tar包下载到本地。
docker pull k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0-rc.0 docker save k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0-rc.0 -o kube-state-metrics.tar
2. ctr导入镜像
ctr -n k8s.io i import kube-state-metrics.tar 导入的只是一个工作节点这样,但是kubernetes本来就是保证高可用用性,如果这个pod漂移调度到其他节点呢?难道要加上节点亲和性?这个节点如果就崩溃了呢?每个节点都导入此镜像?新加入的节点呢?还是老老实实的上传到镜像仓库吧!
正常的流程应该是这样吧?
导入的只是一个工作节点这样,但是kubernetes本来就是保证高可用用性,如果这个pod漂移调度到其他节点呢?难道要加上节点亲和性?这个节点如果就崩溃了呢?每个节点都导入此镜像?新加入的节点呢?还是老老实实的上传到镜像仓库吧!
正常的流程应该是这样吧?crictl images ctr image tag k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0-rc.0 ccr.ccs.tencentyun.com/k8s_containers/kube-state-metrics:v2.0.0-rc.0 但是为什么是not found?不知道是不是标签格式问题….。反正就这样了 ,然后上传到镜像库,具体命令可以参考https://blog.csdn.net/tongzidane/article/details/114587138 https://blog.csdn.net/liumiaocn/article/details/103320426/
(上传我的仓库权限还是有问题(仓库里面可以下载啊但是我……..搞迷糊了),不先搞了直接导入了)
但是为什么是not found?不知道是不是标签格式问题….。反正就这样了 ,然后上传到镜像库,具体命令可以参考https://blog.csdn.net/tongzidane/article/details/114587138 https://blog.csdn.net/liumiaocn/article/details/103320426/
(上传我的仓库权限还是有问题(仓库里面可以下载啊但是我……..搞迷糊了),不先搞了直接导入了)
 反正咋样把kube-state-metrics-XXXX启动起来就好了,有时间好好研究下ctr crictl命令 还是有点懵。
反正咋样把kube-state-metrics-XXXX启动起来就好了,有时间好好研究下ctr crictl命令 还是有点懵。3. 验证服务都正常启动
kubectl get pod -n monitoring kubectl get svc -n monitoring
4. 使用traefik代理应用
注: 参照前文Kubernetes 1.20.5 安装traefik在腾讯云下的实践https://www.yuque.com/duiniwukenaihe/ehb02i/odflm7#WT4ab。比较习惯了ingresroute的方式就保持这种了没有使用ingress 或者api的方式。
cat monitoring.com.yaml
apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: monitoring name: alertmanager-main-http spec: entryPoints: - web routes: - match: Host(\`alertmanager.saynaihe.com\`) kind: Rule services: - name: alertmanager-main port: 9093 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: monitoring name: grafana-http spec: entryPoints: - web routes: - match: Host(\`monitoring.saynaihe.com\`) kind: Rule services: - name: grafana port: 3000 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: namespace: monitoring name: prometheus spec: entryPoints: - web routes: - match: Host(\`prometheus.saynaihe.com\`) kind: Rule services: - name: prometheus-k8s port: 9090 ---kubectl apply -f monitoring.com.yaml
验证traefik代理应用是否成功:

 修改密码
修改密码
 先随便演示一下,后面比较还要修改
先随便演示一下,后面比较还要修改

 仅用于演示,后面起码alertmanager Prometheus两个web要加个basic安全验证….
仅用于演示,后面起码alertmanager Prometheus两个web要加个basic安全验证….5. 添加 kubeControllerManager kubeScheduler监控
通过https://prometheus.saynaihe.com/targets 页面可以看到和前几个版本一样依然木有kube-scheduler 和 kube-controller-manager 的监控。

修改/etc/kubernetes/manifests/目录下kube-controller-manager.yaml kube-scheduler.yaml将 - –bind-address=127.0.0.1 修改为 - –bind-address=0.0.0.0


修改为配置文件 control manager scheduler服务会自动重启的。等待重启验证通过。
 在manifests目录下(这一步一点要仔细看下新版的matchLabels发生了改变)
在manifests目录下(这一步一点要仔细看下新版的matchLabels发生了改变)grep -A2 -B2 selector kubernetes-serviceMonitor*
cat <<EOF > kube-controller-manager-scheduler.yml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: app.kubernetes.io/name: kube-controller-manager spec: selector: component: kube-controller-manager type: ClusterIP clusterIP: None ports: - name: https-metrics port: 10257 targetPort: 10257 protocol: TCP --- apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: app.kubernetes.io/name: kube-scheduler spec: selector: component: kube-scheduler type: ClusterIP clusterIP: None ports: - name: https-metrics port: 10259 targetPort: 10259 protocol: TCP EOF kubectl apply -f kube-controller-manager-scheduler.yml

cat <<EOF > kube-ep.yml apiVersion: v1 kind: Endpoints metadata: labels: k8s-app: kube-controller-manager name: kube-controller-manager namespace: kube-system subsets: - addresses: - ip: 10.3.2.5 - ip: 10.3.2.13 - ip: 10.3.2.16 ports: - name: https-metrics port: 10257 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: kube-system subsets: - addresses: - ip: 10.3.2.5 - ip: 10.3.2.13 - ip: 10.3.2.16 ports: - name: https-metrics port: 10259 protocol: TCP EOF kubectl apply -f kube-ep.yml 登陆https://prometheus.saynaihe.com/targets进行验证:
登陆https://prometheus.saynaihe.com/targets进行验证:

6. ECTD的监控
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt kubectl edit prometheus k8s -n monitoring
验证Prometheus是否正常挂载证书
[root@sh-master-02 yaml]# kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. Defaulting container name to prometheus. Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod. /prometheus $ ls /etc/prometheus/secrets/etcd-certs/ ca.crt healthcheck-client.crt healthcheck-client.keycat <<EOF > kube-ep-etcd.yml apiVersion: v1 kind: Service metadata: name: etcd-k8s namespace: kube-system labels: k8s-app: etcd spec: type: ClusterIP clusterIP: None ports: - name: etcd port: 2379 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: labels: k8s-app: etcd name: etcd-k8s namespace: kube-system subsets: - addresses: - ip: 10.3.2.5 - ip: 10.3.2.13 - ip: 10.3.2.16 ports: - name: etcd port: 2379 protocol: TCP --- EOF kubectl apply -f kube-ep-etcd.ymlcat <<EOF > prometheus-serviceMonitorEtcd.yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: etcd-k8s namespace: monitoring labels: k8s-app: etcd spec: jobLabel: k8s-app endpoints: - port: etcd interval: 30s scheme: https tlsConfig: caFile: /etc/prometheus/secrets/etcd-certs/ca.crt certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key insecureSkipVerify: true selector: matchLabels: k8s-app: etcd namespaceSelector: matchNames: - kube-system EOF kubectl apply -f prometheus-serviceMonitorEtcd.yaml
7. prometheus配置文件修改为正式
1. 添加自动发现配置
网上随便抄 了一个
cat <<EOF > prometheus-additional.yaml - job_name: 'kubernetes-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name EOF kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring2. 增加存储 保留时间 etcd secret
cat <<EOF > prometheus-prometheus.yaml apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: labels: app.kubernetes.io/component: prometheus app.kubernetes.io/name: prometheus app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 2.25.0 prometheus: k8s name: k8s namespace: monitoring spec: alerting: alertmanagers: - apiVersion: v2 name: alertmanager-main namespace: monitoring port: web externalLabels: {} image: quay.io/prometheus/prometheus:v2.25.0 nodeSelector: kubernetes.io/os: linux podMetadata: labels: app.kubernetes.io/component: prometheus app.kubernetes.io/name: prometheus app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 2.25.0 podMonitorNamespaceSelector: {} podMonitorSelector: {} probeNamespaceSelector: {} probeSelector: {} replicas: 2 resources: requests: memory: 400Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules secrets: - etcd-certs securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 additionalScrapeConfigs: name: additional-configs key: prometheus-additional.yaml serviceAccountName: prometheus-k8s retention: 60d serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: 2.25.0 storage: volumeClaimTemplate: spec: storageClassName: cbs-csi resources: requests: storage: 50Gi EOF kubectl apply -f prometheus-prometheus.yaml
8. grafana添加存储
- 新建grafana pvc
cat <<EOF > grafana-pv.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: grafana namespace: monitoring spec: storageClassName: cbs-csi accessModes: - ReadWriteOnce resources: requests: storage: 20Gi EOF kubectl apply -f grafana-pv.yaml修改manifests目录下grafana-deployment.yaml存储
9. grafana添加监控模板
添加etcd traefik 模板,import模板号10906 3070.嗯 会发现traefik模板会出现Panel plugin not found: grafana-piechart-panel.
解决方法:重新构建grafana镜像,/usr/share/grafana/bin/grafana-cli plugins install grafana-piechart-panel安装缺失插件


10. 微信报警

 将对应秘钥填入alertmanager.yaml
将对应秘钥填入alertmanager.yaml1. 配置alertmanager.yaml
cat <<EOF > alertmanager.yaml global: resolve_timeout: 2m wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' route: group_by: ['alert'] group_wait: 10s group_interval: 1m repeat_interval: 1h receiver: wechat receivers: - name: 'wechat' wechat_configs: - api_secret: 'XXXXXXXXXX' send_resolved: true to_user: '@all' to_party: 'XXXXXX' agent_id: 'XXXXXXXX' corp_id: 'XXXXXXXX' templates: - '/etc/config/alert/wechat.tmpl' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'production', 'instance'] EOF2. 个性化配置报警模板,这个随意了网上有很多例子
cat <<EOF > wechat.tpl ==========异常告警========== 告警类型: 告警级别: 告警详情: ; 故障时间: 实例信息: 命名空间: 节点信息: 实例名称: ============END============ ==========异常恢复========== 告警类型: 告警级别: 告警详情: ; 故障时间: 恢复时间: 实例信息: 命名空间: 节点信息: 实例名称: ============END============ EOF3. 部署secret
kubectl delete secret alertmanager-main -n monitoring kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --from-file=wechat.tmpl -n monitoring
4. 验证

11. 彩蛋
正好个人想试一下kubernetes的HPA ,
[root@sh-master-02 yaml]# kubectl top pods -n qa W0330 16:00:54.657335 2622645 top_pod.go:265] Metrics not available for pod qa/dataloader-comment-5d975d9d57-p22w9, age: 2h3m13.657327145s error: Metrics not available for pod qa/dataloader-comment-5d975d9d57-p22w9, age: 2h3m13.657327145swhat Prometheus oprator不是有metrics吗 ?怎么回事
kubectl logs -f prometheus-adapter-c96488cdd-vfm7h -n monitoring如下图…. 我安装kubernete时候修改了集群的dnsDomain。没有修改配置文件,这样是有问题的
 manifests目录下 修改prometheus-adapter-deployment.yaml中Prometheus-url
manifests目录下 修改prometheus-adapter-deployment.yaml中Prometheus-url
 然后kubectl top nodes.可以使用了
然后kubectl top nodes.可以使用了

12. 顺便讲一下hpa
参照https://blog.csdn.net/weixin_38320674/article/details/105460033。环境中有metrics。从第七步骤开始

1. 打包上传到镜像库
docker build -t ccr.ccs.tencentyun.com/XXXXX/test1:0.1 . docker push ccr.ccs.tencentyun.com/XXXXX/test1:0.12. 通过deployment部署一个php-apache服务
cat php-apache.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: php-apache spec: selector: matchLabels: run: php-apache replicas: 1 template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: ccr.ccs.tencentyun.com/XXXXX/test1:0.1 ports: - containerPort: 80 resources: limits: cpu: 200m requests: cpu: 100m --- apiVersion: v1 kind: Service metadata: name: php-apache labels: run: php-apache spec: ports: - port: 80 selector: run: php-apachekubectl apply -f php-apache.yaml
3. 创建hpa
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10下面是释意:
kubectl autoscale deployment php-apache (php-apache表示deployment的名字) --cpu-percent=50(表示cpu使用率不超过50%) --min=1(最少一个pod) --max=10(最多10个pod)4.压测php-apache服务,只是针对CPU做压测
启动一个容器,并将无限查询循环发送到php-apache服务(复制k8s的master节点的终端,也就是打开一个新的终端窗口):
kubectl run v1 -it --image=busybox /bin/sh登录到容器之后,执行如下命令
while true; do wget -q -O- http://php-apache.default; done 这里只对cpu做了测试。简单demo.其他的单单讲了.
这里只对cpu做了测试。简单demo.其他的单单讲了.13. 其他坑爹的
无意间把pv,pvc删除了…. 以为我的storageclass有问题。然后重新部署吧 ? 个人觉得部署一下 prometheus-prometheus.yaml就好了,然后 并没有出现Prometheus的服务。瞄了一遍日志7.1整有了,重新执行下就好了,不记得自己具体哪里把这的secret 搞掉了….记录一下
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
-
Kuberentes 1.20.5搭建eck
-
Kubernetes 1.20.5 安装traefik在腾讯云下的实践
背景
个人使用traefik有差不多1-2年时间,kubernetes ingress controller 代理有很多种方式 例如 ingress-nginx kong istio 等等。个人比较习惯traefik。从19年就开始使用。最早使用traefik 不直接使用腾讯云公有云的slb是因为当时slb不能挂载多个证书,而我kubernetes的自建集群实在不想挂载多个slb.就偷懒用了slb udp绑定运行traefik节点的 80 443端口。证书tls的secret 直接挂载在traefik代理层上面。hsts http跳转https的特性都配置在了traefik代理层上面。应用比较少。qps也没有那么高,这样的简单应用就满足了我的需求了
关于traefik的结缘
最早接触traefik是Google上面看ingress controller 找到的 然后再阳明大佬的博客看到了traefik的实践https://www.qikqiak.com/post/traefik2-ga/,还有超级小豆丁的博客http://www.mydlq.club/article/41 。两位大佬的博客是kubernetes初学者的宝藏博客值得收藏拜读。 顺便吐个糟,用的traefik2.4版本… 抄的豆丁大佬的..http://www.mydlq.club/article/107/哈哈哈
ingress controller对比:
参照https://zhuanlan.zhihu.com/p/109458069。

1. Kubernetes Gateway API
v2.4版本的改变(在 Traefik v2.4 版本中增加了对 Kubernetes Gateway API 的支持)一下部分抄自豆丁大佬与官方文档https://gateway-api.sigs.k8s.io/。
1、Gateway API 是什么
Gateway API是由SIG-NETWORK 社区管理的一个开源项目。它是在Kubernetes中对服务网络建模的资源的集合。这些资源- ,
GatewayClass,Gateway,HTTPRoute,TCPRoute,Service等-旨在通过表现力,可扩展和面向角色由很多供应商实现的,并具有广泛的行业支持接口演进Kubernetes服务网络。 注意:此项目以前被称为“服务API”,直到2021年2月被重命名为“_Gateway API _”。2、Gateway API 的目标
Gateway API 旨在通过提供可表达的,可扩展的,面向角色的接口来改善服务网络,这些接口已由许多供应商实施并获得了广泛的行业支持。 网关 API 是 API 资源(服务、网关类、网关、HTTPRoute、TCPRoute等)的集合。这些资源共同为各种网络用例建模。
 Gateway API 如何根据 Ingress 等当前标准进行改进?
Gateway API 如何根据 Ingress 等当前标准进行改进?- 以下设计目标驱动了Gateway API的概念。这些证明了Gateway如何旨在改进Ingress等当前标准。
- 面向角色-网关由API资源组成,这些API资源对使用和配置Kubernetes服务网络的组织角色进行建模。
- 便携式-这不是改进,而是应该保持不变。就像Ingress是具有许多实现的通用规范一样 ,Gateway API也被设计为受许多实现支持的可移植规范。
- 富有表现力-网关API资源支持核心功能,例如基于标头的匹配,流量加权以及其他只能通过自定义批注在Ingress中实现的功能。
- 可扩展-网关API允许在API的各个层上链接自定义资源。这样就可以在API结构内的适当位置进行精细的自定义。
其他一些值得注意的功能包括:
- GatewayClasses -GatewayClasses形式化负载平衡实现的类型。这些类使用户可以轻松,明确地了解通过Kubernetes资源模型可以使用的功能。
- 共享网关和跨命名空间支持-通过允许独立的Route资源绑定到同一网关,它们可以共享负载平衡器和VIP。这允许团队(甚至跨命名空间)在没有直接协调的情况下安全地共享基础结构。
- 类型化路由和类型化后端-网关API支持类型化路由资源以及不同类型的后端。这使API可以灵活地支持各种协议(例如HTTP和gRPC)和各种后端目标(例如Kubernetes Services,存储桶或函数)。
如果想了解更多内容,可以访问 Kubernetes Gateway API 文档 。
2. traefik on kubernetes实践
部署玩Traefik 应用后,创建外部访问 Kubernetes 内部应用的路由规则,才能从外部访问kubernetes内部应用。Traefik 目前支持三种方式创建路由规则方式,一种是创建 Traefik 自定义
Kubernetes CRD资源,另一种是创建Kubernetes Ingress资源,还有就是 v2.4 版本对 Kubernetes 扩展 APIKubernetes Gateway API适配的一种方式,创建GatewayClass、Gateway与HTTPRoute资源 注意:这里 Traefik 是部署在 kube-system namespace 下,如果不想部署到配置的 namespace,需要修改下面部署文件中的 namespace 参数。当然了也可以新建一个单独的namespace去部署traefik1. 创建CRD
参照https://doc.traefik.io/traefik/reference/dynamic-configuration/kubernetes-crd/
traefik-crd.yaml
cat <<EOF > traefik-crd.yaml apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: ingressroutes.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: IngressRoute plural: ingressroutes singular: ingressroute scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: middlewares.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: Middleware plural: middlewares singular: middleware scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: ingressroutetcps.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: IngressRouteTCP plural: ingressroutetcps singular: ingressroutetcp scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: ingressrouteudps.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: IngressRouteUDP plural: ingressrouteudps singular: ingressrouteudp scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: tlsoptions.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: TLSOption plural: tlsoptions singular: tlsoption scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: tlsstores.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: TLSStore plural: tlsstores singular: tlsstore scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: traefikservices.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: TraefikService plural: traefikservices singular: traefikservice scope: Namespaced --- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: serverstransports.traefik.containo.us spec: group: traefik.containo.us version: v1alpha1 names: kind: ServersTransport plural: serverstransports singular: serverstransport scope: Namespaced EOF kubectl apply -f traefik-crd.yaml2. 创建RBAC权限
cat <<EOF > traefik-rbac.yaml kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: traefik-ingress-controller namespace: kube-system rules: - apiGroups: - "" resources: - services - endpoints - secrets verbs: - get - list - watch - apiGroups: - extensions - networking.k8s.io resources: - ingresses - ingressclasses verbs: - get - list - watch - apiGroups: - extensions resources: - ingresses/status verbs: - update - apiGroups: - traefik.containo.us resources: - middlewares - ingressroutes - traefikservices - ingressroutetcps - ingressrouteudps - tlsoptions - tlsstores - serverstransports verbs: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: traefik-ingress-controller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: traefik-ingress-controller subjects: - kind: ServiceAccount name: traefik-ingress-controller namespace: kube-system EOF kubectl apply -f traefik-rbac.yaml3. 创建 Traefik 配置文件
#号后为注释,跟2.X前几个版本一样。增加了kubernetesIngress kubernetesGateway两种路由方式,过去只部署了CRD的方式。
cat <<EOF > traefik-config.yaml kind: ConfigMap apiVersion: v1 metadata: name: traefik-config namespace: kube-system data: traefik.yaml: |- ping: "" ## 启用 Ping serversTransport: insecureSkipVerify: true ## Traefik 忽略验证代理服务的 TLS 证书 api: insecure: true ## 允许 HTTP 方式访问 API dashboard: true ## 启用 Dashboard debug: false ## 启用 Debug 调试模式 metrics: prometheus: "" ## 配置 Prometheus 监控指标数据,并使用默认配置 entryPoints: web: address: ":80" ## 配置 80 端口,并设置入口名称为 web websecure: address: ":443" ## 配置 443 端口,并设置入口名称为 websecure providers: kubernetesCRD: "" ## 启用 Kubernetes CRD 方式来配置路由规则 kubernetesIngress: "" ## 启用 Kubernetes Ingress 方式来配置路由规则 kubernetesGateway: "" ## 启用 Kubernetes Gateway API experimental: kubernetesGateway: true ## 允许使用 Kubernetes Gateway API log: filePath: "" ## 设置调试日志文件存储路径,如果为空则输出到控制台 level: error ## 设置调试日志级别 format: json ## 设置调试日志格式 accessLog: filePath: "" ## 设置访问日志文件存储路径,如果为空则输出到控制台 format: json ## 设置访问调试日志格式 bufferingSize: 0 ## 设置访问日志缓存行数 filters: #statusCodes: ["200"] ## 设置只保留指定状态码范围内的访问日志 retryAttempts: true ## 设置代理访问重试失败时,保留访问日志 minDuration: 20 ## 设置保留请求时间超过指定持续时间的访问日志 fields: ## 设置访问日志中的字段是否保留(keep 保留、drop 不保留) defaultMode: keep ## 设置默认保留访问日志字段 names: ## 针对访问日志特别字段特别配置保留模式 ClientUsername: drop headers: ## 设置 Header 中字段是否保留 defaultMode: keep ## 设置默认保留 Header 中字段 names: ## 针对 Header 中特别字段特别配置保留模式 User-Agent: redact Authorization: drop Content-Type: keep #tracing: ## 链路追踪配置,支持 zipkin、datadog、jaeger、instana、haystack 等 # serviceName: ## 设置服务名称(在链路追踪端收集后显示的服务名) # zipkin: ## zipkin配置 # sameSpan: true ## 是否启用 Zipkin SameSpan RPC 类型追踪方式 # id128Bit: true ## 是否启用 Zipkin 128bit 的跟踪 ID # sampleRate: 0.1 ## 设置链路日志采样率(可以配置0.0到1.0之间的值) # httpEndpoint: http://localhost:9411/api/v2/spans ## 配置 Zipkin Server 端点 EOF kubectl apply -f traefik-config.yaml4. 设置节点label标签
Traefix 采用 DaemonSet方式构建,在需要安装的节点上面打上标签,这里在三个work节点都安装上了默认:
kubectl label nodes {sh-work-01,sh-work-02,sh-work-02} IngressProxy=true kubectl get nodes --show-labels
 注意:如果想删除标签,可以使用 **kubectl label nodes k8s-node-03 IngressProxy- **命令。哈哈哈偶尔需要去掉标签,不调度。
注意:如果想删除标签,可以使用 **kubectl label nodes k8s-node-03 IngressProxy- **命令。哈哈哈偶尔需要去掉标签,不调度。5、安装 Kubernetes Gateway CRD 资源
由于目前 Kubernetes 集群上默认没有安装 Service APIs,我们需要提前安装 Gateway API 的 CRD 资源,需要确保在 Traefik 安装之前启用 Service APIs 资源。
kubectl apply -k "github.com/kubernetes-sigs/service-apis/config/crd?ref=v0.2.0"不过由于github网络问题,基本无法安装的。我是直接把github上包下载到本地采用本地安装的方式安装 进入
 进入base目录直接全部安装:
进入base目录直接全部安装:kubectl apply -f .
6. Kubernetes 部署 Traefik
其实我就可以忽略443了….因为我想在slb 哦 对也叫clb.直接做限制。对外只保留80端口。
cat <<EOF > traefik-deploy.yaml apiVersion: v1 kind: Service metadata: name: traefik namespace: kube-system spec: ports: - name: web port: 80 - name: websecure port: 443 - name: admin port: 8080 selector: app: traefik --- apiVersion: apps/v1 kind: DaemonSet metadata: namespace: kube-system name: traefik-ingress-controller labels: app: traefik spec: selector: matchLabels: app: traefik template: metadata: name: traefik labels: app: traefik spec: serviceAccountName: traefik-ingress-controller terminationGracePeriodSeconds: 1 containers: - image: ccr.ccs.tencentyun.com/XXXX/traefik:v2.4.3 name: traefik-ingress-lb ports: - name: web containerPort: 80 hostPort: 80 - name: websecure containerPort: 443 hostPort: 443 - name: admin containerPort: 8080 resources: limits: cpu: 2000m memory: 1024Mi requests: cpu: 1000m memory: 1024Mi securityContext: capabilities: drop: - ALL add: - NET_BIND_SERVICE args: - --configfile=/config/traefik.yaml volumeMounts: - mountPath: "/config" name: "config" readinessProbe: httpGet: path: /ping port: 8080 failureThreshold: 3 initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 livenessProbe: httpGet: path: /ping port: 8080 failureThreshold: 3 initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 volumes: - name: config configMap: name: traefik-config tolerations: ## 设置容忍所有污点,防止节点被设置污点 - operator: "Exists" nodeSelector: ## 设置node筛选器,在特定label的节点上启动 IngressProxy: "true EOF kubectl apply -f traefik-deploy.yamlkubectl get pods -n kube-system 验证

3. 配置路由规则,与腾讯云clb整合
1. slb 绑定traefik http端口
关于腾讯云负载均衡 slb or clb可以参照文档https://cloud.tencent.com/document/product/214了解。过去使用slb用的tcp代理方式有一下原因:
- 过去的腾讯云slb不支持一个负载均衡挂载多个证书,个人不想启用多个slb绑定。
- 在slb上面配置域名比较麻烦…..没有再traefik配置文件里面写对我个人来说方便。
那我现在怎么就用slb http https代理方式了呢?
- 当然了 首先是可以挂载多个证书了
- 我在slb上面直接绑定了泛域名,后面的具体域名解析还是在我的traefik配置。但是我不用绑定证书了….
- http https的方式我可以把日志直接写入他的cos对象存储和腾讯云自己的日志服务(感觉也是一个kibana)可以直接分析日志啊…..
 综上所述,来实现一下我个人的过程与思路
综上所述,来实现一下我个人的过程与思路- 创建slb .slb绑定 work节点 80端口(这里我用的是负载均衡型,没有用传统型),没有问题吧?老老实实ipv4了没有启用ipv6这个就看个人具体需求吧。

 使用了极度不要脸的方式 泛域名….因为我常用的也就这两个域名,具体的解析都还是我自己在traefik配置了。
使用了极度不要脸的方式 泛域名….因为我常用的也就这两个域名,具体的解析都还是我自己在traefik配置了。
 关于证书 我这里可是扔好了 两个主二级域名,泛域名证书直接扔上了……
关于证书 我这里可是扔好了 两个主二级域名,泛域名证书直接扔上了……
 四个后面配置我都绑定了80交给traefik处理吧。权重我都设置的一样的,有其他需求的可以根据自己需要设置呢。
四个后面配置我都绑定了80交给traefik处理吧。权重我都设置的一样的,有其他需求的可以根据自己需要设置呢。

2. 配置路由规则
Traefik 应用已经部署完成,并且和slb负载均衡集成也大致完成了。但是想让外部访问 Kubernetes 内部服务,还需要配置路由规则,上面部署 Traefik 时开启了
traefik dashboard,这是 Traefik 提供的视图看板,所以,首先配置基于http的Traefik Dashboard路由规则,使外部能够访问Traefik Dashboard。这里分别使用CRD、Ingress和Kubernetes Gateway API三种方式进行演示,过去版本常用的是CRD的方式。https的方式我就忽略了交给slb负载均衡层了。1. CRD方式
过去我个人部署应用都是crd方式,自己老把这种方式叫做ingressroute方式。
cat <<EOF> traefik-dashboard-route-http.yaml apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: traefik-dashboard-route namespaces: kube-system spec: entryPoints: - web routes: - match: Host(\`traefik.saynaihe.com\`) kind: Rule services: - name: traefik port: 8080 EOF kubectl apply -f traefik-dashboard-route-http.yaml 关于 match: Host(`traefik.saynaihe.com`) 加转义符应该都能看明白了,不加转义符会是这样的
关于 match: Host(`traefik.saynaihe.com`) 加转义符应该都能看明白了,不加转义符会是这样的
 我貌似又忘了加namespace 截图中,实际我可是加上了…老容易往事。哎,我不是两个泛域名吗 ? 特意做了两个ingressoute 做下测试
我貌似又忘了加namespace 截图中,实际我可是加上了…老容易往事。哎,我不是两个泛域名吗 ? 特意做了两个ingressoute 做下测试
 然后绑定本地hosts绑定host
然后绑定本地hosts绑定hostC:\Windows\System32\drivers\etc 遮挡的有点多….但是 这就是两个都路由过来了啊
遮挡的有点多….但是 这就是两个都路由过来了啊
 关于https可以忽略了直接挂载在slb层了啊。然后http 强制跳转 https也可以在slb层上面配置了
关于https可以忽略了直接挂载在slb层了啊。然后http 强制跳转 https也可以在slb层上面配置了
 流氓玩法强跳….测试也是成功的….
流氓玩法强跳….测试也是成功的….

2. Ingress方式
ingress的方式基本就是https://kubernetes.io/zh/docs/concepts/services-networking/ingress/ kubernetes 常见的ingress方式吧? 继续拿dashboard做演示
cat <<EOF> traefik-dashboard-ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: traefik-dashboard-ingress namespace: kube-system annotations: kubernetes.io/ingress.class: traefik traefik.ingress.kubernetes.io/router.entrypoints: web spec: rules: - host: traefik1.saynaihe.com http: paths: - pathType: Prefix path: / backend: service: name: traefik port: number: 8080 EOF kubectl apply -f traefik-dashboard-ingress.yaml 由于端口强制跳转了设置,直接https了哈哈哈验证完成
由于端口强制跳转了设置,直接https了哈哈哈验证完成

3、方式三:使用 Kubernetes Gateway API
关于
Kubernetes Gateway API可以通过CRD方式创建路由规则 CRD 自定义资源强调一下 详情可以参考:https://doc.traefik.io/traefik/v2.4/routing/providers/kubernetes-gateway/- GatewayClass: GatewayClass 是基础结构提供程序定义的群集范围的资源。此资源表示可以实例化的网关类。一般该资源是用于支持多个基础设施提供商用途的,这里我们只部署一个即可。
- Gateway: Gateway 与基础设施配置的生命周期是 1:1。当用户创建网关时,GatewayClass 控制器会提供或配置一些负载平衡基础设施。
- HTTPRoute: HTTPRoute 是一种网关 API 类型,用于指定 HTTP 请求从网关侦听器到 API 对象(即服务)的路由行为。

1. 创建 GatewayClass
**#创建 GatewayClass 资源 kubernetes-gatewayclass.yaml 文件** **参照: **https://doc.traefik.io/traefik/v2.4/routing/providers/kubernetes-gateway/#kind-gatewayclass
cat <<EOF> kubernetes-gatewayclass.yaml kind: GatewayClass apiVersion: networking.x-k8s.io/v1alpha1 metadata: name: traefik spec: # Controller is a domain/path string that indicates # the controller that is managing Gateways of this class. controller: traefik.io/gateway-controller EOF kubectl apply -f kubernetes-gatewayclass.yaml2 配置 HTTP 路由规则 (Traefik Dashboard 为例)
创建 Gateway 资源 http-gateway.yaml 文件
cat <<EOF> http-gateway.yaml apiVersion: networking.x-k8s.io/v1alpha1 kind: Gateway metadata: name: http-gateway namespace: kube-system spec: gatewayClassName: traefik listeners: - protocol: HTTP port: 80 routes: kind: HTTPRoute namespaces: from: All selector: matchLabels: app: traefik EOF kubectl apply -f http-gateway.yaml创建 HTTPRoute 资源 traefik-httproute.yaml 文件
cat <<EOF> traefik-httproute.yaml apiVersion: networking.x-k8s.io/v1alpha1 kind: HTTPRoute metadata: name: traefik-dashboard-httproute namespace: kube-system labels: app: traefik spec: hostnames: - "traefi2.saynaihe.com" rules: - matches: - path: type: Prefix value: / forwardTo: - serviceName: traefik port: 8080 weight: 1 EOF kubectl apply -f traefik-httproute.yaml这里就出问题了…..,无法访问,仔细看了下文档https://doc.traefik.io/traefik/providers/kubernetes-gateway/
 全部删除一次重新部署吧将2.5中版本变成v0.1.0就好了….图就不上了基本步骤是一样的。
全部删除一次重新部署吧将2.5中版本变成v0.1.0就好了….图就不上了基本步骤是一样的。
 注: 都没有做域名解析,本地绑定了host。 saynaihe.com域名只是做演示。没有实际搞….因为我没有做备案。现在不备案的基本绑上就被扫描到封了。用正式域名做的试验。另外养成的习惯用CRD习惯了…部署应用基本个人都用了CRD的方式 —ingressroute。ingress的方式是更适合从ingress-nginx迁移到traefik使用了。至于Kubernetes Gateway API个人还是图个新鲜,没有整明白。v0.2.0不能用…就演示下了.
注: 都没有做域名解析,本地绑定了host。 saynaihe.com域名只是做演示。没有实际搞….因为我没有做备案。现在不备案的基本绑上就被扫描到封了。用正式域名做的试验。另外养成的习惯用CRD习惯了…部署应用基本个人都用了CRD的方式 —ingressroute。ingress的方式是更适合从ingress-nginx迁移到traefik使用了。至于Kubernetes Gateway API个人还是图个新鲜,没有整明白。v0.2.0不能用…就演示下了.
-
Kuberentes集群添加腾讯云CBS为默认存储
前言
接上文https://blog.csdn.net/saynaihe/article/details/115187298 kubeadm 搭建高可用ha集群,接下来考虑的度量有存储,对外暴露服务。日志收集,监控报警几项。个人习惯就先将存储优先来讨论了。 关于存储storageclass 如https://kubernetes.io/zh/docs/concepts/storage/storage-classes所示,常见的有很多类型,如下:
 由于我的集群建在公有云上面 腾讯云有开源的cbs 的 csi组件。在kubernetes1.16-1.18 环境使用docker 做runtime的环境中使用过腾讯云的开源组件。这就又拿来用了。方便集成。
由于我的集群建在公有云上面 腾讯云有开源的cbs 的 csi组件。在kubernetes1.16-1.18 环境使用docker 做runtime的环境中使用过腾讯云的开源组件。这就又拿来用了。方便集成。初始环境
参加:https://editor.csdn.net/md/?articleId=115187298
主机名 ip 系统 内核 sh-master-01 10.3.2.5 centos8 4.18.0-240.15.1.el8_3.x86_64 sh-master-02 10.3.2.13 centos8 4.18.0-240.15.1.el8_3.x86_64 sh-master-03 10.3.2.16 centos8 4.18.0-240.15.1.el8_3.x86_64 sh-work-01 10.3.2.2 centos8 4.18.0-240.15.1.el8_3.x86_64 sh-work-02 10.3.2.2 centos8 4.18.0-240.15.1.el8_3.x86_64 sh-work-03 10.3.2.4 centos8 4.18.0-240.15.1.el8_3.x86_64 集成腾讯云 CBS CSI
1. clone 仓库
注: kubernetes-csi-tencentcloud中包括 CBS CSI, CFS CSI 与 COSFS CSI。这里我就只用CBS块存储了。其他两个也用过,感觉用起来还是不太适合。
git clone https://github.com/TencentCloud/kubernetes-csi-tencentcloud.git各种名词可以参照:https://github.com/TencentCloud/kubernetes-csi-tencentcloud/blob/master/docs/README_CBS_zhCN.md。
2.参照文档前置要求完成kubernetes集群的配置修改
1. master节点
参照https://github.com/TencentCloud/kubernetes-csi-tencentcloud/blob/master/docs/README_CBS_zhCN.md。参照一下图片前置要求
 对三台master节点修改 kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml。增加如下配置(查看对应版本对应需求)
对三台master节点修改 kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml。增加如下配置(查看对应版本对应需求)- --feature-gates=VolumeSnapshotDataSource=true


2. 修改所有节点的kubelet配置
kubelet增加–feature-gates=VolumeSnapshotDataSource=true的支持

3.部署CBS CSI插件
1. 使用腾讯云 API Credential 创建 kubernetes secret:
1. 前提:
首先的在腾讯云后台https://console.cloud.tencent.com/cam创建一个用户,访问方式我是只开通了编程访问,至于用户权限则需要开通CBS相关权限。我是直接绑定了CSB两个默认相关的权限,还有财务付款权限,记得一定的支持付款,否则硬盘创建不了……。玩的好的可以自定义创建下权限,否则个人觉得财务权限貌似有点大……


2. 根据文档提示将SecretId SecretKey base64转换生成kubernetes secret
echo -n "XXXXXXXXXXX" |base6 echo -n "XXXXXXXXXX" |base64将base64写入secret.yaml文件

cd /root/kubernetes-csi-tencentcloud-master/deploy/cbs/kubernetes kubectl apply -f secret.yaml注:项目是在root目录git clone的,故cd /root/kubernetes-csi-tencentcloud-master/deploy/cbs/kubernetes.包括一下没有特别强调目录的,都是在此目录下执行的

2. 创建rbac
创建attacher,provisioner,plugin需要的rbac:
kubectl apply -f csi-controller-rbac.yaml kubectl apply -f csi-node-rbac.yaml3.创建controller,node和plugin
创建controller plugin和node plugin
kubectl apply -f csi-controller.yaml kubectl apply -f csi-node.yaml ### snapshot-crd我没有使用,字面意思应该是快照的.... kubectl apply -f snapshot-crd.yamlkubectl get pods -n kube-system 可以看到cbs-csi相关组件创建ing:

4. 验证
切换目录 cd /root/kubernetes-csi-tencentcloud-master/deploy/cbs/examples
- 参照storageclass参数修改storageclass-basic.yaml

创建storageclass: kubectl apply -f storageclass-basic.yaml 创建pvc: kubectl apply -f pvc.yaml 创建申请pvc的pod: kubectl apply -f app.yaml 嗯 kubectl get storageclass
嗯 kubectl get storageclass
 到此为止,搭建其他应用就可以用cbs存储了。具体参数看文档 看文档 看文档 说三遍。
到此为止,搭建其他应用就可以用cbs存储了。具体参数看文档 看文档 看文档 说三遍。
-
centos8+kubeadm1.20.5+cilium+hubble环境搭建
- 前言
- 环境准备:
- 1. 系统初始化:
- 1. 更改主机名
- 2. 关闭swap交换分区
- 3. 关闭selinux
- 4. 关闭防火墙
- 5. 调整文件打开数等配置
- 6. yum update 八仙过海各显神通吧,安装自己所需的习惯的应用
- 7. ipvs添加(centos8内核默认4.18.内核4.19不包括4.19的是用这个)
- 8. 优化系统参数(不一定是最优,各取所有)
- 9. containerd安装
- 10. 配置 CRI 客户端 crictl
- 11. 安装 Kubeadm(centos8没有对应yum源使用centos7的阿里云yum源)
- 12. 修改kubelet配置
- 13 . journal 日志相关避免日志重复搜集,浪费系统资源。修改systemctl启动的最小文件打开数量,关闭ssh反向dns解析.设置清理日志,最大200m(可根据个人需求设置)
- 2. master节点操作
- 3. helm 安装 部署cilium 与hubble(默认helm3了)
- 4. work节点部署
前言
腾讯云绑定用户,开始使用过腾讯云的tke1.10版本。鉴于各种原因选择了自建。线上kubeadm自建kubernetes集群1.16版本(小版本升级到1.16.15)。kubeadm+haproxy+slb+flannel搭建高可用集群,集群启用ipvs。对外服务使用slb绑定traefik tcp 80 443端口对外映射(这是历史遗留问题,过去腾讯云slb不支持挂载多证书,这样也造成了无法使用slb的日志投递功能,现在slb已经支持了多证书的挂载,可以直接使用http http方式了)。生产环境当时搭建仓库没有使用腾讯云的块存储,直接使用cbs。直接用了local disk,还有nfs的共享存储。前几天整了个项目的压力测试,然后使用nfs存储的项目IO直接就飙升了。生产环境不建议使用。准备安装kubernetes 1.20版本,并使用cilium组网。hubble替代kube-proxy 体验一下ebpf。另外也直接上containerd。dockershim的方式确实也浪费资源的。这样也是可以减少资源开销,部署速度的。反正就是体验一下各种最新功能:

 图片引用自:https://blog.kelu.org/tech/2020/10/09/the-diff-between-docker-containerd-runc-docker-shim.html
图片引用自:https://blog.kelu.org/tech/2020/10/09/the-diff-between-docker-containerd-runc-docker-shim.html环境准备:
注:master节点4核心8G配置。work节点16核32G。腾讯云S5云主机 | 主机名 | ip | 系统 | 内核 | | — | — | — | — | | sh-master-01 | 10.3.2.5 | centos8 | 4.18.0-240.15.1.el8_3.x86_64 | | sh-master-02 | 10.3.2.13 | centos8 | 4.18.0-240.15.1.el8_3.x86_64 | | sh-master-03 | 10.3.2.16 | centos8 | 4.18.0-240.15.1.el8_3.x86_64 | | sh-work-01 | 10.3.2.2 | centos8 | 4.18.0-240.15.1.el8_3.x86_64 | | sh-work-02 | 10.3.2.3 | centos8 | 4.18.0-240.15.1.el8_3.x86_64 | | sh-work-03 | 10.3.2.4 | centos8 | 4.18.0-240.15.1.el8_3.x86_64 |
注: 用centos8是为了懒升级内核版本了。centos7内核版本3.10确实有些老了。但是同样的centos8 kubernetes源是没有的,只能使用centos7的源。 VIP slb地址:10.3.2.12(因为内网没有使用域名的需求,直接用了传统型内网负载,为了让slb映射端口与本地端口一样中间加了一层haproxy代理本地6443.然后slb代理8443端口为6443.)。


1. 系统初始化:
注:由于环境是部署在公有云的,使用了懒人方法。直接初始化了一台server.然后其他的直接都是复制的方式搭建的。
1. 更改主机名
hostnamectl set-hostname sh-master-01 cat /etc/hosts 就是举个例子了。我的host文件只在三台master节点写了,work节点都没有写的…….
就是举个例子了。我的host文件只在三台master节点写了,work节点都没有写的…….2. 关闭swap交换分区
swapoff -a sed -i 's/.*swap.*/#&/' /etc/fstab3. 关闭selinux
setenforce 0 sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config4. 关闭防火墙
systemctl disable --now firewalld chkconfig firewalld off5. 调整文件打开数等配置
cat> /etc/security/limits.conf <<EOF * soft nproc 1000000 * hard nproc 1000000 * soft nofile 1000000 * hard nofile 1000000 * soft memlock unlimited * hard memlock unlimited EOF当然了这里最好的其实是/etc/security/limits.d目录下生成一个新的配置文件。避免修改原来的总配置文件、这也是推荐使用的方式。
6. yum update 八仙过海各显神通吧,安装自己所需的习惯的应用
yum update yum -y install gcc bc gcc-c++ ncurses ncurses-devel cmake elfutils-libelf-devel openssl-devel flex* bison* autoconf automake zlib* fiex* libxml* ncurses-devel libmcrypt* libtool-ltdl-devel* make cmake pcre pcre-devel openssl openssl-devel jemalloc-devel tlc libtool vim unzip wget lrzsz bash-comp* ipvsadm ipset jq sysstat conntrack libseccomp conntrack-tools socat curl wget git conntrack-tools psmisc nfs-utils tree bash-completion conntrack libseccomp net-tools crontabs sysstat iftop nload strace bind-utils tcpdump htop telnet lsof7. ipvs添加(centos8内核默认4.18.内核4.19不包括4.19的是用这个)
:> /etc/modules-load.d/ipvs.conf module=( ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh br_netfilter ) for kernel_module in ${module[@]};do /sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || : done内核大于等于4.19的
:> /etc/modules-load.d/ipvs.conf module=( ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack br_netfilter ) for kernel_module in ${module[@]};do /sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || : done这个地方我想我开不开ipvs应该没有多大关系了吧? 因为我网络组件用的cilium hubble。网络用的是ebpf。没有用iptables ipvs吧?至于配置ipvs算是原来部署养成的习惯 加载ipvs模块
systemctl daemon-reload systemctl enable --now systemd-modules-load.service查询ipvs是否加载
# lsmod | grep ip_vs ip_vs_sh 16384 0 ip_vs_wrr 16384 0 ip_vs_rr 16384 0 ip_vs 172032 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack 172032 6 xt_conntrack,nf_nat,xt_state,ipt_MASQUERADE,xt_CT,ip_vs nf_defrag_ipv6 20480 4 nf_conntrack,xt_socket,xt_TPROXY,ip_vs libcrc32c 16384 3 nf_conntrack,nf_nat,ip_vs8. 优化系统参数(不一定是最优,各取所有)
cat <<EOF > /etc/sysctl.d/k8s.conf net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1 net.ipv4.neigh.default.gc_stale_time = 120 net.ipv4.conf.all.rp_filter = 0 net.ipv4.conf.default.rp_filter = 0 net.ipv4.conf.default.arp_announce = 2 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.all.arp_announce = 2 net.ipv4.ip_forward = 1 net.ipv4.tcp_max_tw_buckets = 5000 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_max_syn_backlog = 1024 net.ipv4.tcp_synack_retries = 2 # 要求iptables不对bridge的数据进行处理 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-arptables = 1 net.netfilter.nf_conntrack_max = 2310720 fs.inotify.max_user_watches=89100 fs.may_detach_mounts = 1 fs.file-max = 52706963 fs.nr_open = 52706963 vm.overcommit_memory=1 vm.panic_on_oom=0 vm.swappiness = 0 EOF sysctl --system9. containerd安装
dnf 与yum centos8的变化,具体的自己去看了呢。差不多吧…….
dnf install dnf-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sudo yum update -y && sudo yum install -y containerd.io containerd config default > /etc/containerd/config.toml # 替换 containerd 默认的 sand_box 镜像,编辑 /etc/containerd/config.toml sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.2" # 重启containerd $ systemctl daemon-reload $ systemctl restart containerd其他的配置一个是启用SystemdCgroup另外一个是添加了本地镜像库,账号密码(直接使用了腾讯云的仓库)。

10. 配置 CRI 客户端 crictl
cat <<EOF > /etc/crictl.yaml runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 debug: false EOF # 验证是否可用(可以顺便验证一下私有仓库) crictl pull nginx:alpine crictl rmi nginx:alpine crictl images11. 安装 Kubeadm(centos8没有对应yum源使用centos7的阿里云yum源)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF # 删除旧版本,如果安装了 yum remove kubeadm kubectl kubelet kubernetes-cni cri-tools socat # 查看所有可安装版本 下面两个都可以啊 # yum list --showduplicates kubeadm --disableexcludes=kubernetes # 安装指定版本用下面的命令 # yum -y install kubeadm-1.20.5 kubectl-1.20.5 kubelet-1.20.5 or # yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes # 默认安装最新稳定版,当前版本1.20.5 yum install kubeadm # 开机自启 systemctl enable kubelet.service12. 修改kubelet配置
vi /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS= --cgroup-driver=systemd --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock13 . journal 日志相关避免日志重复搜集,浪费系统资源。修改systemctl启动的最小文件打开数量,关闭ssh反向dns解析.设置清理日志,最大200m(可根据个人需求设置)
sed -ri 's/^\$ModLoad imjournal/#&/' /etc/rsyslog.conf sed -ri 's/^\$IMJournalStateFile/#&/' /etc/rsyslog.conf sed -ri 's/^#(DefaultLimitCORE)=/\1=100000/' /etc/systemd/system.conf sed -ri 's/^#(DefaultLimitNOFILE)=/\1=100000/' /etc/systemd/system.conf sed -ri 's/^#(UseDNS )yes/\1no/' /etc/ssh/sshd_config journalctl --vacuum-size=200M2. master节点操作
1 . 安装haproxy
yum install haproxycat <<EOF > /etc/haproxy/haproxy.cfg #--------------------------------------------------------------------- # Example configuration for a possible web application. See the # full configuration options online. # # http://haproxy.1wt.eu/download/1.4/doc/configuration.txt # #--------------------------------------------------------------------- #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode tcp log global option tcplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 #--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- frontend kubernetes bind *:8443 #配置端口为8443 mode tcp default_backend kubernetes #--------------------------------------------------------------------- # static backend for serving up images, stylesheets and such #--------------------------------------------------------------------- backend kubernetes #后端服务器,也就是说访问10.3.2.12:6443会将请求转发到后端的三台,这样就实现了负载均衡 balance roundrobin server master1 10.3.2.5:6443 check maxconn 2000 server master2 10.3.2.13:6443 check maxconn 2000 server master3 10.3.2.16:6443 check maxconn 2000 EOF systemctl enable haproxy && systemctl start haproxy && systemctl status haproxy嗯 slb绑定端口

2. sh-master-01节点初始化
1.生成config配置文件
kubeadm config print init-defaults > config.yaml下面的图就是举个例子…….

2. 修改kubeadm初始化文件
apiVersion: kubeadm.k8s.io/v1beta2 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 10.3.2.5 bindPort: 6443 nodeRegistration: criSocket: /run/containerd/containerd.sock name: sh-master-01 taints: - effect: NoSchedule key: node-role.kubernetes.io/master --- apiServer: timeoutForControlPlane: 4m0s certSANs: - sh-master-01 - sh-master-02 - sh-master-03 - sh-master.k8s.io - localhost - 127.0.0.1 - 10.3.2.5 - 10.3.2.13 - 10.3.2.16 - 10.3.2.12 apiVersion: kubeadm.k8s.io/v1beta2 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: "10.3.2.12:6443" controllerManager: {} dns: type: CoreDNS etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.20.5 networking: dnsDomain: xx.daemon serviceSubnet: 172.254.0.0/16 podSubnet: 172.3.0.0/16 scheduler: {}修改的地方在下图中做了标识

3. kubeadm master-01节点初始化(屏蔽kube-proxy)。
kubeadm init --skip-phases=addon/kube-proxy --config=config.yaml安装成功截图就忽略了,后写的笔记没有保存截图。成功的日志中包含
mkdir -p $HOME/.kube mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 按照输出sh-master-02 ,sh-master-03节点加入集群 将sh-master-01 /etc/kubernetes/pki目录下ca.* sa.* front-proxy-ca.* etcd/ca* 打包分发到sh-master-02,sh-master-03 /etc/kubernetes/pki目录下 kubeadm join 10.3.2.12:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:eb0fe00b59fa27f82c62c91def14ba294f838cd0731c91d0d9c619fe781286b6 --control-plane 然后同sh-master-01一样执行一遍下面的命令: mkdir -p $HOME/.kube sudo \cp /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config3. helm 安装 部署cilium 与hubble(默认helm3了)
1. 下载helm并安装helm
注: 由于网络原因。下载helm安装包下载不动经常,直接github下载到本地了

tar zxvf helm-v3.5.3-linux-amd64.tar.gz cp helm /usr/bin/2 . helm 安装cilium hubble
早先版本 cilium 与hubble是分开的现在貌似都集成了一波流走一遍:
helm install cilium cilium/cilium --version 1.9.5 --namespace kube-system --set nodeinit.enabled=true --set externalIPs.enabled=true --set nodePort.enabled=true --set hostPort.enabled=true --set pullPolicy=IfNotPresent --set config.ipam=cluster-pool --set hubble.enabled=true --set hubble.listenAddress=":4244" --set hubble.relay.enabled=true --set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,http}" --set prometheus.enabled=true --set peratorPrometheus.enabled=true --set hubble.ui.enabled=true --set kubeProxyReplacement=strict --set k8sServiceHost=10.3.2.12 --set k8sServicePort=6443部署成功就是这样的

 嗯 木有kube-proxy的(截图是work加点加入后的故node-init cilium pod都有6个)
嗯 木有kube-proxy的(截图是work加点加入后的故node-init cilium pod都有6个)4. work节点部署
sh-work-01 sh-work-02 sh-work-03节点加入集群
kubeadm join 10.3.2.12:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:eb0fe00b59fa27f82c62c91def14ba294f838cd0731c91d0d9c619fe781286b6
-
Cluster Hardening - RBAC
- content {:toc
注:通过RBAC对集群进行加固
关于RBAC
RBAC-role based access control 基于角色的访问控制
注:ABAC(基于属性的访问控制),ABAC木有接触过…
1. Introduction to RBAC RBAC介绍
“Role-based access control (RBAC) is a method of regulating accessto computer or network resources based on the roles of individualusers within your organization.” 基于角色的访问控制(RBAC)是一种根据个人用户在组织中的角色来管理对计算机或网络资源的访问的方法。
RBAC使用rbac.authorization.k8s.ioAPI Group 来实现授权决策,允许管理员通过 Kubernetes API 动态配置策略,要启用RBAC,需要在 apiserver 中添加参数--authorization-mode=RBAC,如果使用的kubeadm安装的集群,1.6 版本以上的都默认开启了RBAC,可以通过查看 Master 节点上 apiserver 的静态Pod定义文件:

RBAC 流程定义三大组件: subject Role rolebinding 主体 授权规则 准入控制
1. 访问Kubernetes资源时,限制对Kubernetes资源的访问基于用户或ServiceAccount
2. 使用角色和绑定
3. 指定允许的内容,其他所有内容都将被拒绝.可以设置白名单

4. POLP-Priciple of Least Privilege最小特权原则
** 仅访问合法目的所需的数据或信息** 2. RBAC的资源分类 命名空间级别and 非命名空间级别(集群级别)
 常用查询命令
常用查询命令查询在namespace中的资源对象 执行命令:kubectl api-resources --namespaced=true 查询不在namespace中的资源对象 执行命令:kubectl api-resources --namespaced=false 查询资源对象与namespace的关系 执行命令:kubectl api-resources

3. 关于role rolebinding clusterrole clusterrolebinding
其实从上面第五节的:kubectl api-resources –namespaced=true kubectl api-resources –namespaced=false两个图中就能看出来:
1. role rolebinding是限制于命名空间的。
2. clusterrole和clusterrolebinding是适用于全部命名空间的没有命名空间的限制,适用于整个集群。

- 2022-08-09-Operator3-设计一个operator二-owns的使用
- 2022-07-11-Operator-2从pod开始简单operator
- 2021-07-20-Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)
- 2021-07-19-Kubernetes 1.18.20升级到1.19.12
- 2021-07-17-Kubernetes 1.17.17升级到1.18.20
- 2021-07-16-TKE1.20.6搭建elasticsearch on kubernetes
- 2021-07-15-Kubernets traefik代理ws wss应用
- 2021-07-09-TKE1.20.6初探
- 2021-07-08-关于centos8+kubeadm1.20.5+cilium+hubble的安装过程中cilium的配置问题--特别强调
- 2021-07-02-腾讯云TKE1.18初体验