Welcome to duiniwukenaihe's Blog!
这里记录着我的运维学习之路-
2022-08-09-Operator3-设计一个operator二-owns的使用
背景:
上一节(Operator3-设计一个operator)做完发现一个问题 我创建了jan 应用jan-sample,子资源包括deployment,service.ingress,pod(其中pod是deployment管理的)
 手动删除Pod.由于Deployment rc控制器。Pod资源可以自动重建。但是我删除deployment能不能自动重建呢?正常的deployment service ingress子资源的生命周期,我应该是靠jan应用去维系的,试一试:
手动删除Pod.由于Deployment rc控制器。Pod资源可以自动重建。但是我删除deployment能不能自动重建呢?正常的deployment service ingress子资源的生命周期,我应该是靠jan应用去维系的,试一试:[zhangpeng@zhangpeng jan]$ kubectl delete deployment jan-sample deployment.apps "jan-sample" deleted [zhangpeng@zhangpeng jan]$ kubectl get deployment No resources found in default namespace. 到这里才发现没有考虑周全……删除deployment资源并不能重建,正常创建应用应该要考虑一下jan资源下面资源的重建.搜了一下别人写的operator貌似的可以加一下Owns,尝试一下!
到这里才发现没有考虑周全……删除deployment资源并不能重建,正常创建应用应该要考虑一下jan资源下面资源的重建.搜了一下别人写的operator貌似的可以加一下Owns,尝试一下!Deployment Ingress Service关于Owns的使用
Deployment
func (r *JanReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&janv1.Jan{}). Owns(&appsv1.Deployment{}). Complete(r) }Deployment delete尝试
make run develop-operator项目,并尝试delete deployment jan-sample查看是否重建:
[zhangpeng@zhangpeng develop-operator]$ kubectl get Jan [zhangpeng@zhangpeng develop-operator]$ kubectl get all
[zhangpeng@zhangpeng develop-operator]$ kubectl delete deployment jan-sample [zhangpeng@zhangpeng develop-operator]$ kubectl get deployment 恩发现deployment应用可以自动重建了!
恩发现deployment应用可以自动重建了!
Ingress and Service资源
简单添加一下Owns?
but其他资源是否可以呢?是不是也偷懒一下添加Owns?
func (r *JanReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&janv1.Jan{}). Owns(&appsv1.Deployment{}). Owns(&corev1.Service{}). Owns(&v1.Ingress{}). Complete(r) }尝试了一下不生效的,但是这种方式思路是对的至于为什么不生效呢? deploy声明了&appv1.Deployment,但是service,ingress是没有创建变量声明的!

拆分改造代码
继续改造Jan operator使其支持service ingress子资源的误删除创建:
 把这边拆分一下?
把这边拆分一下?



 jan_controller.go
jan_controller.go/* Copyright 2022 zhang peng. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */ package jan import ( "context" "encoding/json" appsv1 "k8s.io/api/apps/v1" corev1 "k8s.io/api/core/v1" v1 "k8s.io/api/networking/v1" "k8s.io/apimachinery/pkg/api/errors" "k8s.io/apimachinery/pkg/runtime" utilruntime "k8s.io/apimachinery/pkg/util/runtime" "reflect" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/log" "sigs.k8s.io/controller-runtime/pkg/reconcile" janv1 "develop-operator/apis/jan/v1" ) // JanReconciler reconciles a Jan object type JanReconciler struct { client.Client Scheme *runtime.Scheme } //+kubebuilder:rbac:groups=mar.zhangpeng.com,resources=jan,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=mar.zhangpeng.com,resources=jan/status,verbs=get;update;patch //+kubebuilder:rbac:groups=mar.zhangpeng.com,resources=jan/finalizers,verbs=update //+kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=apps,resources=deployments/status,verbs=get;update;patch //+kubebuilder:rbac:groups=core,resources=services,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=networking,resources=ingresses,verbs=get;list;watch;create;update;patch;delete // Reconcile is part of the main kubernetes reconciliation loop which aims to // move the current state of the cluster closer to the desired state. // TODO(user): Modify the Reconcile function to compare the state specified by // the Jan object against the actual cluster state, and then // perform operations to make the cluster state reflect the state specified by // the user. // // For more details, check Reconcile and its Result here: // - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.11.2/pkg/reconcile func (r *JanReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { defer utilruntime.HandleCrash() _ = log.FromContext(ctx) instance := &janv1.Jan{} err := r.Client.Get(context.TODO(), req.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } if instance.DeletionTimestamp != nil { return reconcile.Result{}, err } // 如果不存在,则创建关联资源 // 如果存在,判断是否需要更新 // 如果需要更新,则直接更新 // 如果不需要更新,则正常返回 deploy := &appsv1.Deployment{} if err := r.Client.Get(context.TODO(), req.NamespacedName, deploy); err != nil && errors.IsNotFound(err) { // 创建关联资源 // 1. 创建 Deploy deploy := NewJan(instance) if err := r.Client.Create(context.TODO(), deploy); err != nil { return reconcile.Result{}, err } // 4. 关联 Annotations data, _ := json.Marshal(instance.Spec) if instance.Annotations != nil { instance.Annotations["spec"] = string(data) } else { instance.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), instance); err != nil { return reconcile.Result{}, nil } return reconcile.Result{}, nil } Service := &corev1.Service{} if err := r.Client.Get(context.TODO(), req.NamespacedName, Service); err != nil && errors.IsNotFound(err) { // 2. 创建 Service service := NewService(instance) if err := r.Client.Create(context.TODO(), service); err != nil { return reconcile.Result{}, err } // 4. 关联 Annotations data, _ := json.Marshal(service.Spec) if service.Annotations != nil { service.Annotations["spec"] = string(data) } else { service.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), service); err != nil { return reconcile.Result{}, nil } return reconcile.Result{}, nil } Ingress := &v1.Ingress{} if err := r.Client.Get(context.TODO(), req.NamespacedName, Ingress); err != nil && errors.IsNotFound(err) { // 2. 创建 Service ingress := NewIngress(instance) if err := r.Client.Create(context.TODO(), ingress); err != nil { return reconcile.Result{}, err } // 4. 关联 Annotations data, _ := json.Marshal(ingress.Spec) if ingress.Annotations != nil { ingress.Annotations["spec"] = string(data) } else { ingress.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), ingress); err != nil { return reconcile.Result{}, nil } return reconcile.Result{}, nil } oldspec := janv1.JanSpec{} if err := json.Unmarshal([]byte(instance.Annotations["spec"]), &oldspec); err != nil { return reconcile.Result{}, err } if !reflect.DeepEqual(instance.Spec, oldspec) { data, _ := json.Marshal(instance.Spec) if instance.Annotations != nil { instance.Annotations["spec"] = string(data) } else { instance.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), instance); err != nil { return reconcile.Result{}, nil } // 更新关联资源 newDeploy := NewJan(instance) oldDeploy := &appsv1.Deployment{} if err := r.Client.Get(context.TODO(), req.NamespacedName, oldDeploy); err != nil { return reconcile.Result{}, err } oldDeploy.Spec = newDeploy.Spec if err := r.Client.Update(context.TODO(), oldDeploy); err != nil { return reconcile.Result{}, err } newService := NewService(instance) oldService := &corev1.Service{} if err := r.Client.Get(context.TODO(), req.NamespacedName, oldService); err != nil { return reconcile.Result{}, err } oldService.Spec = newService.Spec if err := r.Client.Update(context.TODO(), oldService); err != nil { return reconcile.Result{}, err } return reconcile.Result{}, nil } newStatus := janv1.JanStatus{ Replicas: *instance.Spec.Replicas, ReadyReplicas: instance.Status.Replicas, } if newStatus.Replicas == newStatus.ReadyReplicas { newStatus.Phase = janv1.Running } else { newStatus.Phase = janv1.NotReady } if !reflect.DeepEqual(instance.Status, newStatus) { instance.Status = newStatus log.FromContext(ctx).Info("update game status", "name", instance.Name) err = r.Client.Status().Update(ctx, instance) if err != nil { return reconcile.Result{}, err } } return reconcile.Result{}, nil } // SetupWithManager sets up the controller with the Manager. func (r *JanReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&janv1.Jan{}). Owns(&appsv1.Deployment{}). Owns(&corev1.Service{}). Owns(&v1.Ingress{}). Complete(r) }make run尝试一下:
 注意:make run之前默认删除jan应用!
注意:make run之前默认删除jan应用![zhangpeng@zhangpeng develop-operator]$ kubectl delete svc jan-sample [zhangpeng@zhangpeng develop-operator]$ kubectl get svcen service的自动恢复生效了
 然后试一试ingress
然后试一试ingress[zhangpeng@zhangpeng develop-operator]$ kubectl get ingress [zhangpeng@zhangpeng develop-operator]$ kubectl delete ingress jan-sample [zhangpeng@zhangpeng develop-operator]$ kubectl get ingress 继续发现问题:
en,我修改一下jan_v1_jan.yaml中host ww1.zhangpeng.com修改为ww11.zhangpeng.com,but ingress的相关信息没有及时更新啊?
继续发现问题:
en,我修改一下jan_v1_jan.yaml中host ww1.zhangpeng.com修改为ww11.zhangpeng.com,but ingress的相关信息没有及时更新啊?
 继续模仿一下上面的service oldservice newservice新增 newIngress oldIngress :
继续模仿一下上面的service oldservice newservice新增 newIngress oldIngress :
 重新make run
ingress相关信息得到了修改
重新make run
ingress相关信息得到了修改

最终代码:
jan_controller.go
/* Copyright 2022 zhang peng. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */ package jan import ( "context" "encoding/json" appsv1 "k8s.io/api/apps/v1" corev1 "k8s.io/api/core/v1" v1 "k8s.io/api/networking/v1" "k8s.io/apimachinery/pkg/api/errors" "k8s.io/apimachinery/pkg/runtime" utilruntime "k8s.io/apimachinery/pkg/util/runtime" "reflect" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/log" "sigs.k8s.io/controller-runtime/pkg/reconcile" janv1 "develop-operator/apis/jan/v1" ) // JanReconciler reconciles a Jan object type JanReconciler struct { client.Client Scheme *runtime.Scheme } //+kubebuilder:rbac:groups=mar.zhangpeng.com,resources=jan,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=mar.zhangpeng.com,resources=jan/status,verbs=get;update;patch //+kubebuilder:rbac:groups=mar.zhangpeng.com,resources=jan/finalizers,verbs=update //+kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=apps,resources=deployments/status,verbs=get;update;patch //+kubebuilder:rbac:groups=core,resources=services,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=networking,resources=ingresses,verbs=get;list;watch;create;update;patch;delete // Reconcile is part of the main kubernetes reconciliation loop which aims to // move the current state of the cluster closer to the desired state. // TODO(user): Modify the Reconcile function to compare the state specified by // the Jan object against the actual cluster state, and then // perform operations to make the cluster state reflect the state specified by // the user. // // For more details, check Reconcile and its Result here: // - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.11.2/pkg/reconcile func (r *JanReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { defer utilruntime.HandleCrash() _ = log.FromContext(ctx) instance := &janv1.Jan{} err := r.Client.Get(context.TODO(), req.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } if instance.DeletionTimestamp != nil { return reconcile.Result{}, err } // 如果不存在,则创建关联资源 // 如果存在,判断是否需要更新 // 如果需要更新,则直接更新 // 如果不需要更新,则正常返回 deploy := &appsv1.Deployment{} if err := r.Client.Get(context.TODO(), req.NamespacedName, deploy); err != nil && errors.IsNotFound(err) { // 创建关联资源 // 1. 创建 Deploy deploy := NewJan(instance) if err := r.Client.Create(context.TODO(), deploy); err != nil { return reconcile.Result{}, err } // 4. 关联 Annotations data, _ := json.Marshal(instance.Spec) if instance.Annotations != nil { instance.Annotations["spec"] = string(data) } else { instance.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), instance); err != nil { return reconcile.Result{}, nil } return reconcile.Result{}, nil } Service := &corev1.Service{} if err := r.Client.Get(context.TODO(), req.NamespacedName, Service); err != nil && errors.IsNotFound(err) { // 2. 创建 Service service := NewService(instance) if err := r.Client.Create(context.TODO(), service); err != nil { return reconcile.Result{}, err } // 4. 关联 Annotations data, _ := json.Marshal(service.Spec) if service.Annotations != nil { service.Annotations["spec"] = string(data) } else { service.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), service); err != nil { return reconcile.Result{}, nil } return reconcile.Result{}, nil } Ingress := &v1.Ingress{} if err := r.Client.Get(context.TODO(), req.NamespacedName, Ingress); err != nil && errors.IsNotFound(err) { // 2. 创建 Ingress ingress := NewIngress(instance) if err := r.Client.Create(context.TODO(), ingress); err != nil { return reconcile.Result{}, err } // 4. 关联 Annotations data, _ := json.Marshal(ingress.Spec) if ingress.Annotations != nil { ingress.Annotations["spec"] = string(data) } else { ingress.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), ingress); err != nil { return reconcile.Result{}, nil } return reconcile.Result{}, nil } oldspec := janv1.JanSpec{} if err := json.Unmarshal([]byte(instance.Annotations["spec"]), &oldspec); err != nil { return reconcile.Result{}, err } if !reflect.DeepEqual(instance.Spec, oldspec) { data, _ := json.Marshal(instance.Spec) if instance.Annotations != nil { instance.Annotations["spec"] = string(data) } else { instance.Annotations = map[string]string{"spec": string(data)} } if err := r.Client.Update(context.TODO(), instance); err != nil { return reconcile.Result{}, nil } // 更新关联资源 newDeploy := NewJan(instance) oldDeploy := &appsv1.Deployment{} if err := r.Client.Get(context.TODO(), req.NamespacedName, oldDeploy); err != nil { return reconcile.Result{}, err } oldDeploy.Spec = newDeploy.Spec if err := r.Client.Update(context.TODO(), oldDeploy); err != nil { return reconcile.Result{}, err } newService := NewService(instance) oldService := &corev1.Service{} if err := r.Client.Get(context.TODO(), req.NamespacedName, oldService); err != nil { return reconcile.Result{}, err } oldService.Spec = newService.Spec if err := r.Client.Update(context.TODO(), oldService); err != nil { return reconcile.Result{}, err } newIngress := NewIngress(instance) oldIngress := &v1.Ingress{} if err := r.Client.Get(context.TODO(), req.NamespacedName, oldIngress); err != nil { return reconcile.Result{}, err } oldIngress.Spec = newIngress.Spec if err := r.Client.Update(context.TODO(), oldIngress); err != nil { return reconcile.Result{}, err } return reconcile.Result{}, nil } newStatus := janv1.JanStatus{ Replicas: *instance.Spec.Replicas, ReadyReplicas: instance.Status.Replicas, } if newStatus.Replicas == newStatus.ReadyReplicas { newStatus.Phase = janv1.Running } else { newStatus.Phase = janv1.NotReady } if !reflect.DeepEqual(instance.Status, newStatus) { instance.Status = newStatus log.FromContext(ctx).Info("update game status", "name", instance.Name) err = r.Client.Status().Update(ctx, instance) if err != nil { return reconcile.Result{}, err } } return reconcile.Result{}, nil } // SetupWithManager sets up the controller with the Manager. func (r *JanReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&janv1.Jan{}). Owns(&appsv1.Deployment{}). Owns(&corev1.Service{}). Owns(&v1.Ingress{}). Complete(r) }总结
- owns的一般使用
- 将 deployment service ingress或者其他资源作为operator应用的子资源,进行生命周期管理
- 下一步想处理一下 make run 控制台的输出,输出一些有用的信息
-
2022-07-11-Operator-2从pod开始简单operator
背景:
前置内容:Operator-1初识Operator,从pod开始简单创建operator……
创建Pod
RedisSpec 增加Image字段
恩 强调一下 我故意在api/v1/redis_type.go中加一个字段。接下来该怎么操作呢?

先发布了一下crd
[zhangpeng@zhangpeng kube-oprator1]$ ./bin/controller-gen rbac:roleName=manager-role crd webhook paths="./..." output:crd:artifacts:config=config/crd/bases [zhangpeng@zhangpeng kube-oprator1]$ kustomize build config/crd | kubectl apply -f - customresourcedefinition.apiextensions.k8s.io/redis.myapp1.zhangpeng.com configured describe crd 配置里面已经有了Image字段!
describe crd 配置里面已经有了Image字段![zhangpeng@zhangpeng kube-oprator1]$ kubectl describe crd redis.myapp1.zhangpeng.com

镜像要不要发布一下?
发布镜像的时候SetupWebhookWithManager打开了….不打开貌似发布了会报错
 打包镜像image并发布
打包镜像image并发布

[zhangpeng@zhangpeng kube-oprator1]$ cd config/manager && kustomize edit set image controller=ccr.ccs.tencentyun.com/layatools/zpredis:v2 [zhangpeng@zhangpeng manager]$ cd ../../ [zhangpeng@zhangpeng kube-oprator1]$ kustomize build config/default | kubectl apply -f - 注:当然了能使用原生的命令更好, 我这系统还是有问题的
注:当然了能使用原生的命令更好, 我这系统还是有问题的继续强调一下SetupWebhookWithManager
发布完成继续关了main.go中 SetupWebhookWithManager,否则没法make run本地调试哦。

创建CreateRedis函数
helper/help_redis.go
package helper import ( "context" "fmt" corev1 "k8s.io/api/core/v1" v1 "kube-oprator1/api/v1" "sigs.k8s.io/controller-runtime/pkg/client" ) func CreateRedis(client client.Client, redisConfig *v1.Redis) error { newpod := &corev1.Pod{} newpod.Name = podName newpod.Namespace = redisConfig.Namespace newpod.Spec.Containers = []corev1.Container{ { Name: redisConfig.Name, Image: redisConfig.Spec.Image, ImagePullPolicy: corev1.PullIfNotPresent, Ports: []corev1.ContainerPort{ { ContainerPort: int32(redisConfig.Spec.Port), }, }, }, } return client.Create(context.Background(), newpod) }
Reconcile调用CreateRedis函数
controlers/redis_controller.go
func (r *RedisReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { _ = log.FromContext(ctx) redis := &myapp1v1.Redis{} if err := r.Get(ctx, req.NamespacedName, redis); err != nil { fmt.Println(err) } else { fmt.Println("object", redis) err := helper.CreateRedis(r.Client, redis) return ctrl.Result{}, err } return ctrl.Result{}, nil }
make run test
注:其实也可以不make run了……都发布到集群中了, 可以到集群中查看operator日志了! test/redis.go
apiVersion: myapp1.zhangpeng.com/v1 kind: Redis metadata: name: zhangpeng1 spec: port: 6379 image: redis:latest注意:特意搞了两个又创建了一个name为zhangpeng2的应用!



[zhangpeng@zhangpeng ~]$ kubectl get Redis [zhangpeng@zhangpeng ~]$ kubectl get pods 创建成功!接着而来的是pod删除的问题:
创建成功!接着而来的是pod删除的问题:[zhangpeng@zhangpeng ~]$ kubectl delete Redis zhangpeng2 [zhangpeng@zhangpeng ~]$ kubectl get pod恩删除了zhangpeng2 Redis,but pod资源还存在,该怎么处理,让pod资源一起删除呢?

POD资源删除
参照:https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/ Finalizers

清理资源
清理一下资源删除webhook Redis 等相关资源
[zhangpeng@zhangpeng kube-oprator1]$ kubectl get ValidatingWebhookConfiguration NAME WEBHOOKS AGE cert-manager-webhook 1 3d23h kube-oprator1-validating-webhook-configuration 1 3d23h [zhangpeng@zhangpeng kube-oprator1]$ kubectl delete ValidatingWebhookConfiguration error: resource(s) were provided, but no name was specified [zhangpeng@zhangpeng kube-oprator1]$ kubectl delete ValidatingWebhookConfiguration kube-oprator1-validating-webhook-configuration validatingwebhookconfiguration.admissionregistration.k8s.io "kube-oprator1-validating-webhook-configuration" deleted [zhangpeng@zhangpeng kube-oprator1]$ kubectl get MutatingWebhookConfiguration NAME WEBHOOKS AGE cert-manager-webhook 1 3d23h kube-oprator1-mutating-webhook-configuration 1 3d23h [zhangpeng@zhangpeng kube-oprator1]$ kubectl delete MutatingWebhookConfiguration kube-oprator1-mutating-webhook-configuration mutatingwebhookconfiguration.admissionregistration.k8s.io "kube-oprator1-mutating-webhook-configuration" deleted [zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis NAME AGE zhangpeng3 5m [zhangpeng@zhangpeng kube-oprator1]$ kubectl delete Redis zhangpeng3 redis.myapp1.zhangpeng.com "zhangpeng3" deleted [zhangpeng@zhangpeng kube-oprator1]$ kubectl delete pods zhangpeng3 Error from server (NotFound): pods "zhangpeng3" not found [zhangpeng@zhangpeng kube-oprator1]$ kubectl get pods No resources found in default namespace. 这样作吧,还是为了本地调试方便,否则一些本地的修改,增加字段就要重新打包,发布,太麻烦了。老老实实make run 本地调试模式,待调试完成后再发布应用到集群,这才是正常的流程!
需求: 删除Redis 对应pod 可以删除,pod可以多副本。zhangpeng-0 zhangpeng-1 zhangpeng-3的顺序。更新策略,缩容策略。恩这是我想到的!当然了pod如果使用deployment 或者statefulset会更简单一些。这里还是拿pod演示了!
这样作吧,还是为了本地调试方便,否则一些本地的修改,增加字段就要重新打包,发布,太麻烦了。老老实实make run 本地调试模式,待调试完成后再发布应用到集群,这才是正常的流程!
需求: 删除Redis 对应pod 可以删除,pod可以多副本。zhangpeng-0 zhangpeng-1 zhangpeng-3的顺序。更新策略,缩容策略。恩这是我想到的!当然了pod如果使用deployment 或者statefulset会更简单一些。这里还是拿pod演示了!RedisSpec增加副本数量字段
修改api/v1/redis_types.go中RedisSpec struct,增加如下配置:
//+kubebuilder:validation:Minimum:=1 //+kubebuilder:validation:Maximum:=5 Num int `json:"num,omitempty"` num字段为pod副本数量字段,依着port配置把副本数量做了一个1-5的限制!
继续发布一下crd:
num字段为pod副本数量字段,依着port配置把副本数量做了一个1-5的限制!
继续发布一下crd:[zhangpeng@zhangpeng kube-oprator1]$ ./bin/controller-gen rbac:roleName=manager-role crd webhook paths="./..." output:crd:artifacts:config=config/crd/bases [zhangpeng@zhangpeng kube-oprator1]$ kustomize build config/crd | kubectl apply -f - customresourcedefinition.apiextensions.k8s.io/redis.myapp1.zhangpeng.com configured
[zhangpeng@zhangpeng kube-oprator1]$ kubectl describe crd redis.myapp1.zhangpeng.com确认crd中产生对应字段:

help_redis.go
修改helper/help_redis.go如下:
package helper import ( "context" "fmt" corev1 "k8s.io/api/core/v1" v1 "kube-oprator1/api/v1" "sigs.k8s.io/controller-runtime/pkg/client" ) //拼装Pod名称列表 func GetRedisPodNames(redisConfig *v1.Redis) []string { podNames := make([]string, redisConfig.Spec.Num) for i := 0; i < redisConfig.Spec.Num; i++ { podNames[i] = fmt.Sprintf("%s-%d", redisConfig.Name, i) } fmt.Println("podnames:", podNames) return podNames } //判断对应名称的pod在finalizer中是否存在 func IsExist(podName string, redis *v1.Redis) bool { for _, pod := range redis.Finalizers { if podName == pod { return true } } return false } //创建pod func CreateRedis(client client.Client, redisConfig *v1.Redis, podName string) (string, error) { if IsExist(podName, redisConfig) { return "", nil } newpod := &corev1.Pod{} newpod.Name = podName newpod.Namespace = redisConfig.Namespace newpod.Spec.Containers = []corev1.Container{ { Name: podName, Image: redisConfig.Spec.Image, ImagePullPolicy: corev1.PullIfNotPresent, Ports: []corev1.ContainerPort{ { ContainerPort: int32(redisConfig.Spec.Port), }, }, }, } return podName, client.Create(context.Background(), newpod) }修改controllers/redis_controller.go:
import ( "context" "fmt" v1 "k8s.io/api/core/v1" "k8s.io/apimachinery/pkg/api/errors" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/runtime" "k8s.io/client-go/tools/record" myapp1v1 "kube-oprator1/api/v1" "kube-oprator1/helper" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/log" ) func (r *RedisReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { _ = log.FromContext(ctx) // TODO(user): your logic here redis := &myapp1v1.Redis{} if err := r.Client.Get(ctx, req.NamespacedName, redis); err != nil { if errors.IsNotFound(err) { return ctrl.Result{}, nil } return ctrl.Result{}, err } //取得需要创建的POD副本的名称 podNames := helper.GetRedisPodNames(redis) fmt.Println("podNames,", podNames) updateFlag := false //删除POD,删除Kind:Redis过程中,会自动加上DeletionTimestamp字段,据此判断是否删除了自定义资源 if !redis.DeletionTimestamp.IsZero() { fmt.Println(ctrl.Result{}, r.clearRedis(ctx, redis)) return ctrl.Result{}, r.clearRedis(ctx, redis) } //创建POD for _, podName := range podNames { finalizerPodName, err := helper.CreateRedis(r.Client, redis, podName) if err != nil { fmt.Println("create pod failue,", err) return ctrl.Result{}, err } if finalizerPodName == "" { continue } //若该pod已经不在finalizers中,则添加 redis.Finalizers = append(redis.Finalizers, finalizerPodName) updateFlag = true } //更新Kind Redis状态 if updateFlag { err := r.Client.Update(ctx, redis) if err != nil { return ctrl.Result{}, err } } return ctrl.Result{}, nil } //删除POD逻辑 func (r *RedisReconciler) clearRedis(ctx context.Context, redis *myapp1v1.Redis) error { //从finalizers中取出podName,然后执行删除 for _, finalizer := range redis.Finalizers { //删除pod err := r.Client.Delete(ctx, &v1.Pod{ ObjectMeta: metav1.ObjectMeta{ Name: finalizer, Namespace: redis.Namespace, }, }) if err != nil { return err } } //清空finializers,只要它有值,就无法删除Kind redis.Finalizers = []string{} return r.Client.Update(ctx, redis) }make run & test
控制台运行make run&&控制台2运行apply命令:
[zhangpeng@zhangpeng kube-oprator1]$ kubectl apply -f test/redis.yaml redis.myapp1.zhangpeng.com/zhangpeng3 configuredtest/redis.yaml
apiVersion: myapp1.zhangpeng.com/v1 kind: Redis metadata: name: zhangpeng3 spec: port: 6379 num: 2 image: redis:latest
[zhangpeng@zhangpeng kube-oprator1]$ kubectl get pods [zhangpeng@zhangpeng kube-oprator1]$ kubectl apply -f test/redis.yaml [zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis [zhangpeng@zhangpeng kube-oprator1]$ kubectl get pods [zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis/zhangpeng3 -o yaml
[zhangpeng@zhangpeng kube-oprator1]$ kubectl delete test/redis.yaml [zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis [zhangpeng@zhangpeng kube-oprator1]$ kubectl get pods
紧接着问题又来了:
创建副本为2:
 修改副本数为3:
修改副本数为3:
 紧接着缩容副本为2,会出现怎么操作呢?
紧接着缩容副本为2,会出现怎么操作呢?
 没有自动去调度,现在需要一个自动缩容的方法……
没有自动去调度,现在需要一个自动缩容的方法……Pod资源缩容
pod的标签定义的是zhangpeng-0 zhangpeng-1 zhangpeng-2的类型,扩容是 0 1 2 3 4的递增模式,缩容也从4 3 2 1 0依次去删除 pod 注意:默认情况下前面一步的Redis资源已经删除(kubectl delete -f test/redis.yaml)
Reconcile修改
controllers/redis_controller.go 中Reconcile修改为如下:
func (r *RedisReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { _ = log.FromContext(ctx) // TODO(user): your logic here redis := &myapp1v1.Redis{} if err := r.Client.Get(ctx, req.NamespacedName, redis); err != nil { if errors.IsNotFound(err) { return ctrl.Result{}, nil } fmt.Println("object", redis) } if !redis.DeletionTimestamp.IsZero() || len(redis.Finalizers) > redis.Spec.Num { return ctrl.Result{}, r.clearRedis(ctx, redis) } if !redis.DeletionTimestamp.IsZero() || len(redis.Finalizers) > redis.Spec.Num { return ctrl.Result{}, r.clearRedis(ctx, redis) } podNames := helper.GetRedisPodNames(redis) fmt.Println("podNames,", podNames) updateFlag := false for _, podName := range podNames { finalizerPodName, err := helper.CreateRedis(r.Client, redis, podName) if err != nil { fmt.Println("create pod failue,", err) return ctrl.Result{}, err } if finalizerPodName == "" { continue } redis.Finalizers = append(redis.Finalizers, finalizerPodName) updateFlag = true } //更新Kind Redis状态 if updateFlag { err := r.Client.Update(ctx, redis) if err != nil { return ctrl.Result{}, err } } return ctrl.Result{}, nil } func (r *RedisReconciler) clearRedis(ctx context.Context, redis *myapp1v1.Redis) error { /* //finalizers > num 可能出现,删除差值部分 //finalizers = num 可能出现,删除全部 //finalizers < num 不可能出现 */ var deletedPodNames []string //删除finalizers切片的最后的指定元素 position := redis.Spec.Num if (len(redis.Finalizers) - redis.Spec.Num) > 0 { deletedPodNames = redis.Finalizers[position:] redis.Finalizers = redis.Finalizers[:position] } else { deletedPodNames = redis.Finalizers[:position] redis.Finalizers = []string{} } fmt.Println("deletedPodNames", deletedPodNames) fmt.Println("redis.Finalizers", redis.Finalizers) for _, finalizer := range deletedPodNames { //删除pod err := r.Client.Delete(ctx, &v1.Pod{ ObjectMeta: metav1.ObjectMeta{ Name: finalizer, Namespace: redis.Namespace, }, }) if err != nil { return err } } redis.Finalizers = []string{} return r.Client.Update(ctx, redis) }make run 开始测试
控制台执行make run……控制台2 执行apply -f test/redis.yaml创建3个副本pod
apiVersion: myapp1.zhangpeng.com/v1 kind: Redis metadata: name: zhangpeng3 spec: port: 6379 num: 3 image: redis:latest 修改yaml副本数量为2,缩容pod apply yaml文件,缩容成功,删除了zhangpeng3-2pod!
修改yaml副本数量为2,缩容pod apply yaml文件,缩容成功,删除了zhangpeng3-2pod!
 but!问题来了我接着想扩容副本数量到3…..不能正常操作了……不能生成新的pod
but!问题来了我接着想扩容副本数量到3…..不能正常操作了……不能生成新的pod
 观查一下make run报错……
观查一下make run报错……
 删除这几个资源重新来一遍,仔细观察一下步骤看看缺少了什么:
删除资源的时候明显发现绑定到pod跟Redis的资源没有绑定了?
删除这几个资源重新来一遍,仔细观察一下步骤看看缺少了什么:
删除资源的时候明显发现绑定到pod跟Redis的资源没有绑定了?
 apply yaml 副本数量为2, Finalizers中数据:
apply yaml 副本数量为2, Finalizers中数据:
 修改副本数为2……这 标签就没有了?
修改副本数为2……这 标签就没有了?
 继续修改副本数为3….恩问题应该还是出在绑定finalizers这里……
继续修改副本数为3….恩问题应该还是出在绑定finalizers这里……

最终代码如下:
以下代码摘抄自https://github.com/ls-2018/k8s-kustomize
实现扩容缩容删除恢复:
helper/redis_help.redis
package helper import ( "context" "fmt" corev1 "k8s.io/api/core/v1" "k8s.io/apimachinery/pkg/runtime" "k8s.io/apimachinery/pkg/types" v1 "kube-oprator1/api/v1" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/controller/controllerutil" ) func GetRedisPodNames(redisConfig *v1.Redis) []string { podNames := make([]string, redisConfig.Spec.Num) fmt.Printf("%+v", redisConfig) for i := 0; i < redisConfig.Spec.Num; i++ { podNames[i] = fmt.Sprintf("%s-%d", redisConfig.Name, i) } fmt.Println("PodNames: ", podNames) return podNames } // 判断 redis pod 是否能获取 func IsExistPod(podName string, redis *v1.Redis, client client.Client) bool { err := client.Get(context.Background(), types.NamespacedName{ Namespace: redis.Namespace, Name: podName, }, &corev1.Pod{}, ) if err != nil { return false } return true } func IsExistInFinalizers(podName string, redis *v1.Redis) bool { for _, fPodName := range redis.Finalizers { if podName == fPodName { return true } } return false } func CreateRedis(client client.Client, redisConfig *v1.Redis, podName string, schema *runtime.Scheme) (string, error) { if IsExistPod(podName, redisConfig, client) { return podName, nil } newPod := &corev1.Pod{} newPod.Name = podName newPod.Namespace = redisConfig.Namespace newPod.Spec.Containers =append(newPod.Spec.Containers, []corev1.Container{ Name: redisConfig.Name, Image: redisConfig.Spec.Image, ImagePullPolicy: corev1.PullIfNotPresent, Ports: []corev1.ContainerPort{ { ContainerPort: int32(redisConfig.Spec.Port), }, }, }) // set owner reference err := controllerutil.SetControllerReference(redisConfig, newPod, schema) if err != nil { return "", err } return podName, client.Create(context.Background(), newPod) }controllers/redis_controller.go
/* Copyright 2022 zhang peng. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */ package controllers import ( "context" "fmt" corev1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/runtime" "k8s.io/apimachinery/pkg/types" "k8s.io/client-go/tools/record" "k8s.io/client-go/util/workqueue" myapp1v1 "kube-oprator1/api/v1" "kube-oprator1/helper" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/controller/controllerutil" "sigs.k8s.io/controller-runtime/pkg/event" "sigs.k8s.io/controller-runtime/pkg/handler" "sigs.k8s.io/controller-runtime/pkg/log" "sigs.k8s.io/controller-runtime/pkg/reconcile" "sigs.k8s.io/controller-runtime/pkg/source" ) // RedisReconciler reconciles a Redis object type RedisReconciler struct { client.Client Scheme *runtime.Scheme EventRecord record.EventRecorder } //+kubebuilder:rbac:groups=myapp1.zhangpeng.com,resources=redis,verbs=get;list;watch;create;update;patch;delete //+kubebuilder:rbac:groups=myapp1.zhangpeng.com,resources=redis/status,verbs=get;update;patch //+kubebuilder:rbac:groups=myapp1.zhangpeng.com,resources=redis/finalizers,verbs=update // Reconcile is part of the main kubernetes reconciliation loop which aims to // move the current state of the cluster closer to the desired state. // TODO(user): Modify the Reconcile function to compare the state specified by // the Redis object against the actual cluster state, and then // perform operations to make the cluster state reflect the state specified by // the user. // // For more details, check Reconcile and its Result here: // - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.11.2/pkg/reconcile func (r *RedisReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { _ = log.FromContext(ctx) redis := &myapp1v1.Redis{} // 删除后会往这发一个请求,只有NamespacedName数据,别的都没有 if err := r.Get(ctx, req.NamespacedName, redis); err != nil { return ctrl.Result{}, nil } // 正在删除 if !redis.DeletionTimestamp.IsZero() { return ctrl.Result{}, r.clearPods(context.Background(), redis) } // TODO pod 个数变动 podNames := helper.GetRedisPodNames(redis) var err error if redis.Spec.Num > len(redis.Finalizers) { err = r.UpPods(ctx, podNames, redis) if err == nil { fmt.Printf("%d", redis.Spec.Num) //r.EventRecord.Event(redis, corev1.EventTypeNormal, "UpPods", fmt.Sprintf("%d", redis.Spec.Num)) } else { // r.EventRecord.Event(redis, corev1.EventTypeWarning, "DownPods", fmt.Sprintf("%d", redis.Spec.Num)) } } else if redis.Spec.Num < len(redis.Finalizers) { err = r.DownPods(ctx, podNames, redis) if err == nil { // r.EventRecord.Event(redis, corev1.EventTypeNormal, "DownPods", fmt.Sprintf("%d", redis.Spec.Num)) } else { // r.EventRecord.Event(redis, corev1.EventTypeWarning, "DownPods", fmt.Sprintf("%d", redis.Spec.Num)) } redis.Status.RedisNum = len(redis.Finalizers) } else { for _, podName := range redis.Finalizers { if helper.IsExistPod(podName, redis, r.Client) { continue } else { // 重建此pod err = r.UpPods(ctx, []string{podName}, redis) if err != nil { return ctrl.Result{}, err } } } } r.Status().Update(ctx, redis) return ctrl.Result{}, err } // SetupWithManager sets up the controller with the Manager. func (r *RedisReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&myapp1v1.Redis{}). Watches(&source.Kind{Type: &corev1.Pod{}}, handler.Funcs{ CreateFunc: nil, UpdateFunc: nil, DeleteFunc: r.podDeleteHandler, GenericFunc: nil, }). Complete(r) } // 对于用户主动 删除的pod 需要重新创建 func (r *RedisReconciler) podDeleteHandler(event event.DeleteEvent, limitingInterface workqueue.RateLimitingInterface) { fmt.Printf(`###################### %s ###################### `, event.Object.GetName()) for _, ref := range event.Object.GetOwnerReferences() { if ref.Kind == r.kind() && ref.APIVersion == r.apiVersion() { //触发 Reconcile limitingInterface.Add(reconcile.Request{ NamespacedName: types.NamespacedName{ Namespace: event.Object.GetNamespace(), Name: ref.Name, }, }) } } } func (r *RedisReconciler) kind() string { return "Redis" } func (r *RedisReconciler) apiVersion() string { return "myapp1.zhangpeng.com/v1" } func (r *RedisReconciler) clearPods(ctx context.Context, redis *myapp1v1.Redis) error { for _, podName := range redis.Finalizers { err := r.Client.Delete(ctx, &corev1.Pod{ ObjectMeta: metav1.ObjectMeta{ Name: podName, Namespace: redis.Namespace, }, }) //TODO 如果pod已经被删除、 if err != nil { return err } } redis.Finalizers = []string{} return r.Client.Update(ctx, redis) } func (r *RedisReconciler) DownPods(ctx context.Context, podNames []string, redis *myapp1v1.Redis) error { for i := len(redis.Finalizers) - 1; i >= len(podNames); i-- { if !helper.IsExistPod(redis.Finalizers[i], redis, r.Client) { continue } err := r.Client.Delete(ctx, &corev1.Pod{ ObjectMeta: metav1.ObjectMeta{ Name: redis.Finalizers[i], Namespace: redis.Namespace, }, }) if err != nil { return err } } redis.Finalizers = append(redis.Finalizers[:0], redis.Finalizers[:len(podNames)]...) return r.Client.Update(ctx, redis) } func (r *RedisReconciler) UpPods(ctx context.Context, podNames []string, redis *myapp1v1.Redis) error { for _, podName := range podNames { podName, err := helper.CreateRedis(r.Client, redis, podName, r.Scheme) if err != nil { return err } if controllerutil.ContainsFinalizer(redis, podName) { continue } redis.Finalizers = append(redis.Finalizers, podName) } err := r.Client.Update(ctx, redis) return err }

 删除zhangpeng3 Redis
删除zhangpeng3 Redis 基本功能算是完成了,测试一下Pod重建:
基本功能算是完成了,测试一下Pod重建:


其他的
[zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis api/v1/redis_types.go
api/v1/redis_types.go// RedisStatus defines the observed state of Redis type RedisStatus struct { RedisNum int `json:"num,omitempty"` } //下面两个注释对应的是 kubectl get Redis 看到的状态 //+kubebuilder:printcolumn:JSONPath=".status.num",name=NUM,type=integer //+kubebuilder:printcolumn:JSONPath=".metadata.creationTimestamp",name=AGE,type=date //+kubebuilder:object:root=true //+kubebuilder:subresource:status
[zhangpeng@zhangpeng kube-oprator1]$ make install [zhangpeng@zhangpeng kube-oprator1]$ make run看一下config/crd/bases/myapp1.zhangpeng.com_redis.yaml

[zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis
增加Event事件支持
[zhangpeng@zhangpeng kube-oprator1]$ kubectl get Redis NAME NUM AGE zhangpeng3 2 82m [zhangpeng@zhangpeng kube-oprator1]$ kubectl describe Redis zhangpeng3 观察我redis_controller.go代码的时候发现我注释了这些代码……这些其实就是event的输出,不知道怎么会事情就空指针报错了 ,就注释掉了!
观察我redis_controller.go代码的时候发现我注释了这些代码……这些其实就是event的输出,不知道怎么会事情就空指针报错了 ,就注释掉了!
 什么原因呢?参照:https://github.com/767829413/learn-to-apply/blob/3621065003918070635880c3348f1d72bf6ead88/docs/Kubernetes/kubernetes-secondary-development.md
什么原因呢?参照:https://github.com/767829413/learn-to-apply/blob/3621065003918070635880c3348f1d72bf6ead88/docs/Kubernetes/kubernetes-secondary-development.md
 修改main.go
修改main.goif err = (&controllers.RedisReconciler{ Client: mgr.GetClient(), Scheme: mgr.GetScheme(), EventRecord: mgr.GetEventRecorderFor("myapp1.zhangpeng.com"), //名称任意 }).SetupWithManager(mgr); err != nil { setupLog.Error(err, "unable to create controller", "controller", "Redis") os.Exit(1) }
 注:刚才修改副本为2了,又修改成4进行测试的!
注:刚才修改副本为2了,又修改成4进行测试的!最终打包发布:
webhook
打包发布第一步骤如果开启webhook

IMG build
[zhangpeng@zhangpeng kube-oprator1]$ make install [zhangpeng@zhangpeng kube-oprator1]$ make docker-build docker-push IMG=ccr.ccs.tencentyun.com/layatools/zpredis:v5
 Dockerfile中增加一下配置:
Dockerfile中增加一下配置:COPY helper/ helper/ 继续执行构建上传镜像:
继续执行构建上传镜像:[zhangpeng@zhangpeng kube-oprator1]$ make docker-build docker-push IMG=ccr.ccs.tencentyun.com/layatools/zpredis:v5
发布
正常流程:
[zhangpeng@zhangpeng kube-oprator1]$ make deploy IMG=ccr.ccs.tencentyun.com/layatools/zpredis:v5由于 我的环境问题还要拆解一下命令:
[zhangpeng@zhangpeng kube-oprator1]$ cd config/manager && kustomize edit set image controller=ccr.ccs.tencentyun.com/layatools/zpredis:v5 [zhangpeng@zhangpeng manager]$ cd ../../ [zhangpeng@zhangpeng kube-oprator1]$ kustomize build config/default | kubectl apply -f -
权限
[zhangpeng@zhangpeng kube-oprator1]$ kubectl get pods -n kube-oprator1-system NAME READY STATUS RESTARTS AGE kube-oprator1-controller-manager-84c7dcf9fc-xxnk8 2/2 Running [zhangpeng@zhangpeng kube-oprator1]$ kubectl logs -f kube-oprator1-controller-manager-84c7dcf9fc-xxnk8 -n kube-oprator1-system 恩 权限不够 临时搞一个clusterrolebinding :
恩 权限不够 临时搞一个clusterrolebinding :[zhangpeng@zhangpeng kube-oprator1]$ kubectl get sa kube-oprator1-controller-manager -n kube-oprator1-system -o yaml apiVersion: v1 kind: ServiceAccount metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"name":"kube-oprator1-controller-manager","namespace":"kube-oprator1-system"}} creationTimestamp: "2022-06-30T10:53:04Z" name: kube-oprator1-controller-manager namespace: kube-oprator1-system resourceVersion: "1917" uid: 46634b00-0c32-4862-8afb-17bb9d2181d0 secrets: - name: kube-oprator1-controller-manager-token-x2c9f [zhangpeng@zhangpeng kube-oprator1]$ kubectl create clusterrolebinding kube-oprator1-system --clusterrole cluster-admin --serviceaccount=kube-oprator1-system:kube-oprator1-controller-manager clusterrolebinding.rbac.authorization.k8s.io/kube-oprator1-system created delete pod等其启动:
delete pod等其启动:[zhangpeng@zhangpeng kube-oprator1]$ kubectl delete pods kube-oprator1-controller-manager-84c7dcf9fc-xxnk8 -n kube-oprator1-system pod "kube-oprator1-controller-manager-84c7dcf9fc-xxnk8" deleted [zhangpeng@zhangpeng kube-oprator1]$ kubectl get pods -n kube-oprator1-system NAME READY STATUS RESTARTS AGE kube-oprator1-controller-manager-84c7dcf9fc-fbzsl 1/2 Running 0 4s [zhangpeng@zhangpeng kube-oprator1]$ kubectl logs -f kube-oprator1-controller-manager-84c7dcf9fc-fbzsl -n kube-oprator1-system修改副本3为2:



 基本完成,不过深究一下,pod删除了重建是不是也可以增加一下记录?
基本完成,不过深究一下,pod删除了重建是不是也可以增加一下记录?总结:
参考一下github地址或者文章: https://github.com/ls-2018/k8s-kustomize 关于Event修改main.go参照:https://github.com/767829413/learn-to-apply/blob/3621065003918070635880c3348f1d72bf6ead88/docs/Kubernetes/kubernetes-secondary-development.md 文章可以参考:https://www.cnblogs.com/cosmos-wong/p/15894689.html https://podsbook.com/posts/kubernetes/operator/#%E5%9F%BA%E7%A1%80%E6%A6%82%E5%BF%B5这个文章也不错! finalizers参照:https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/ 至于关于redis operator的文章以及github地址来说除了https://podsbook.com/posts/kubernetes/operator 还有finalizers官方文档,都应该是沈叔的课程k8s基础速学3:Operator、Prometheus、日志收集中的内容来的! 接下来准备写一下自己的operator……
-
2021-07-20-Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)
背景:
持续升级过程:Kubernetes 1.16.15升级到1.17.17,Kubernetes 1.17.17升级到1.18.20,Kubernetes 1.18.20升级到1.19.12
集群配置:
主机名 系统 ip k8s-vip slb 10.0.0.37 k8s-master-01 centos7 10.0.0.41 k8s-master-02 centos7 10.0.0.34 k8s-master-03 centos7 10.0.0.26 k8s-node-01 centos7 10.0.0.36 k8s-node-02 centos7 10.0.0.83 k8s-node-03 centos7 10.0.0.40 k8s-node-04 centos7 10.0.0.49 k8s-node-05 centos7 10.0.0.45 k8s-node-06 centos7 10.0.0.18 1. 参考官方文档
参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
2. 确认可升级版本与升级方案
yum list --showduplicates kubeadm --disableexcludes=kubernetes通过以上命令查询到1.20当前最新版本是1.20.9-0版本。master有三个节点还是按照个人习惯先升级k8s-master-03节点
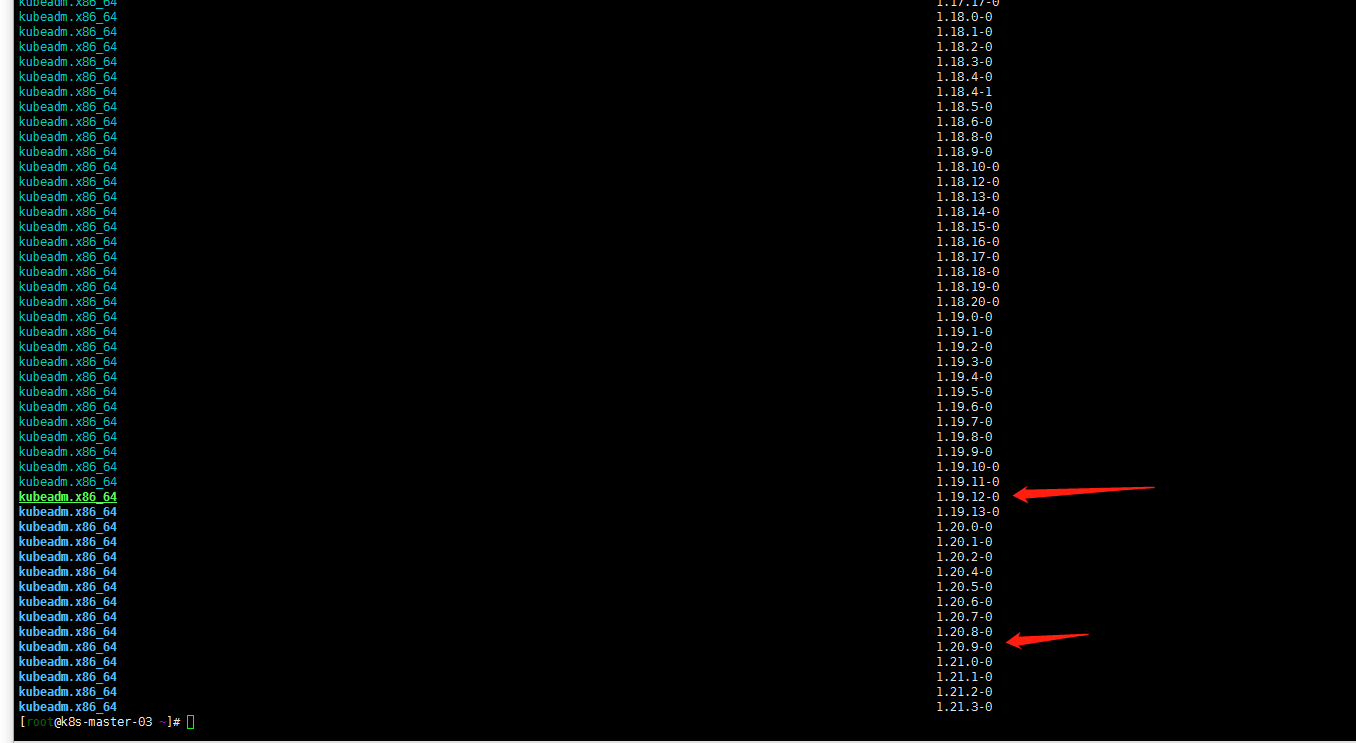
3. 升级k8s-master-03节点控制平面
依然k8s-master-03执行:
1. yum升级kubernetes插件
yum install kubeadm-1.20.9-0 kubelet-1.20.9-0 kubectl-1.20.9-0 --disableexcludes=kubernetes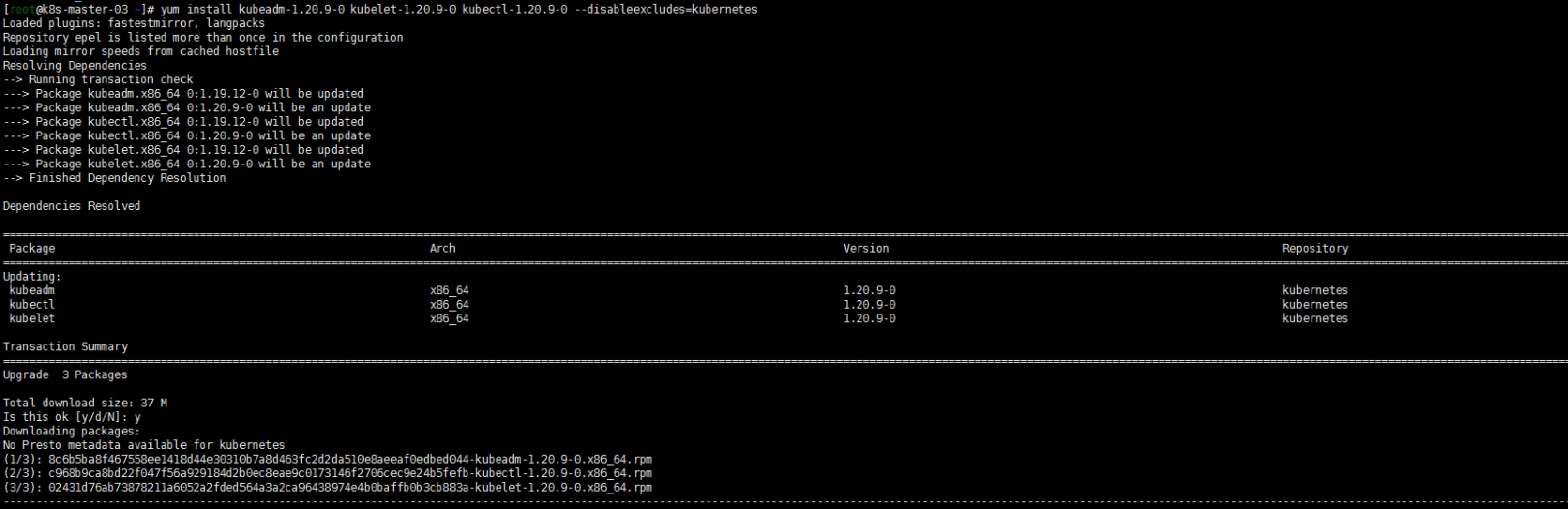
2. 腾空节点检查集群是否可以升级
依然算是温习drain命令:
kubectl drain k8s-master-03 --ignore-daemonsets sudo kubeadm upgrade plan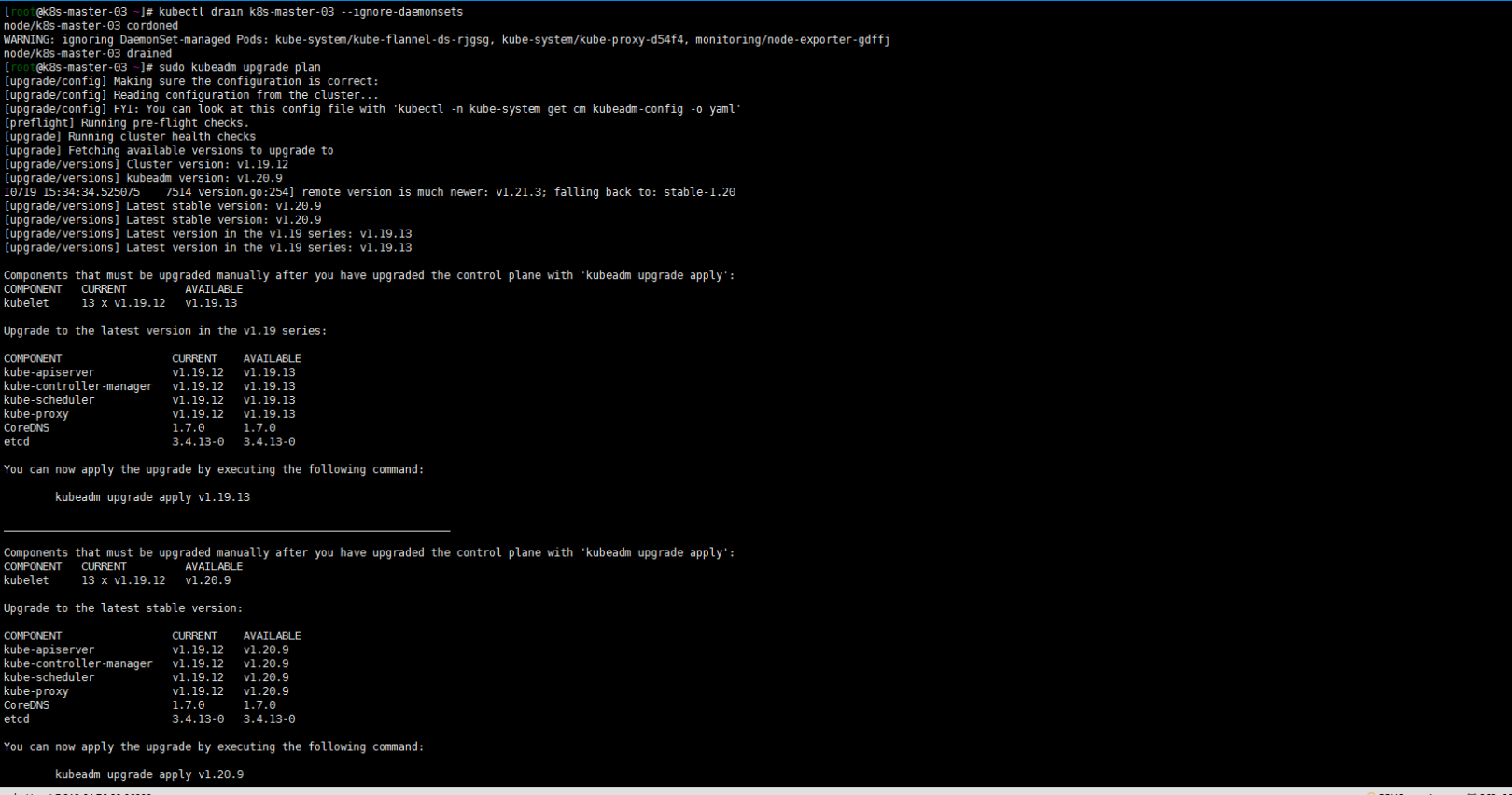
3. 升级版本到1.20.9
kubeadm upgrade apply 1.20.9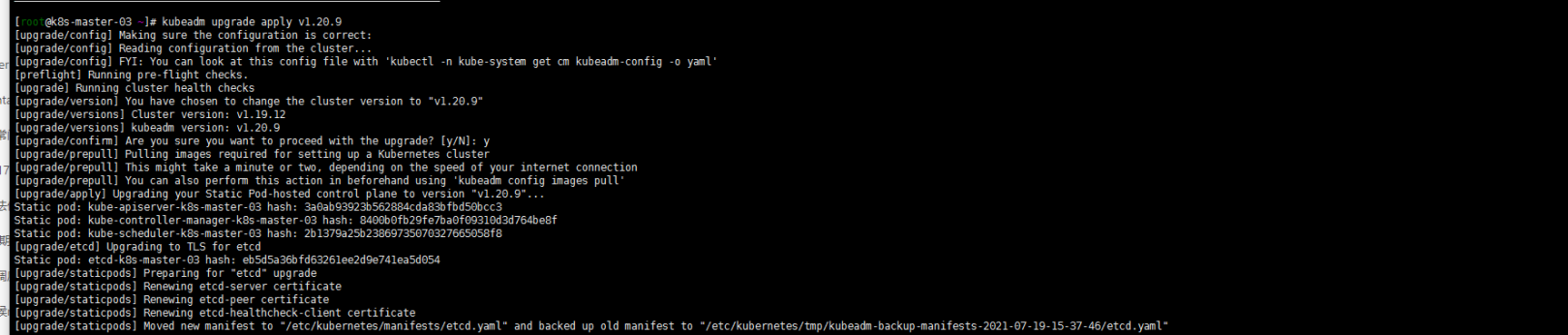
[root@k8s-master-03 ~]# sudo systemctl daemon-reload [root@k8s-master-03 ~]# sudo systemctl restart kubelet [root@k8s-master-03 ~]# kubectl uncordon k8s-master-03 node/k8s-master-03 uncordoned [root@k8s-master-03 ~]# kubectl get nodes [root@k8s-master-03 ~]# kubectl get pods -n kube-system
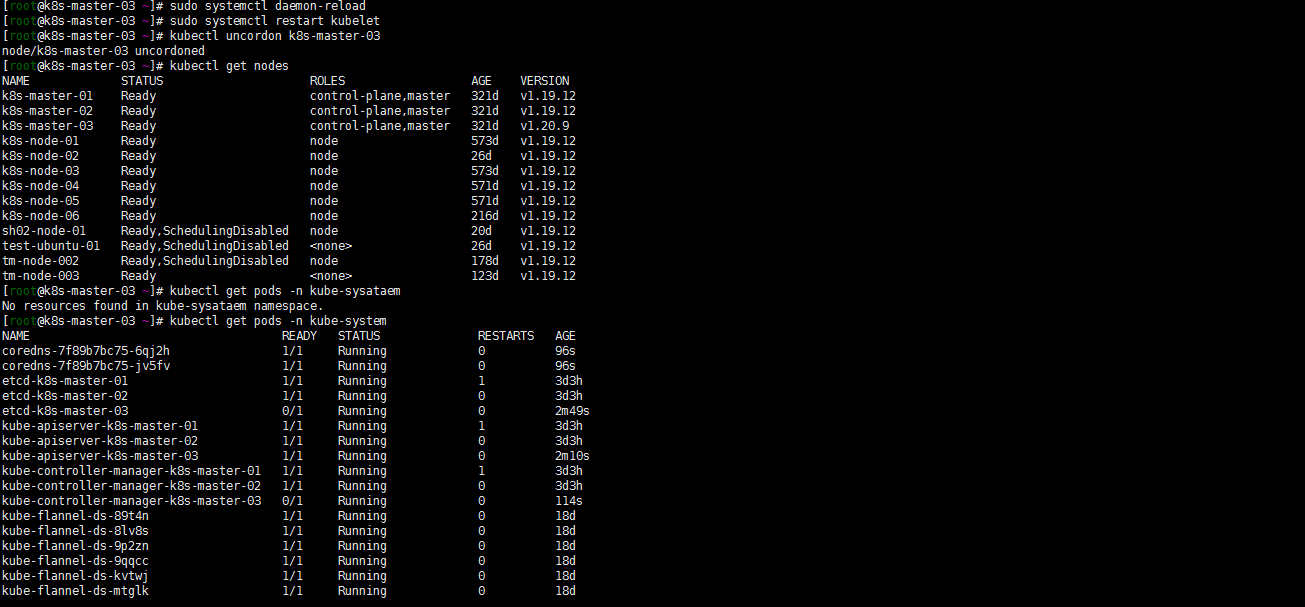
4. 升级其他控制平面(k8s-master-01 k8s-master-02)
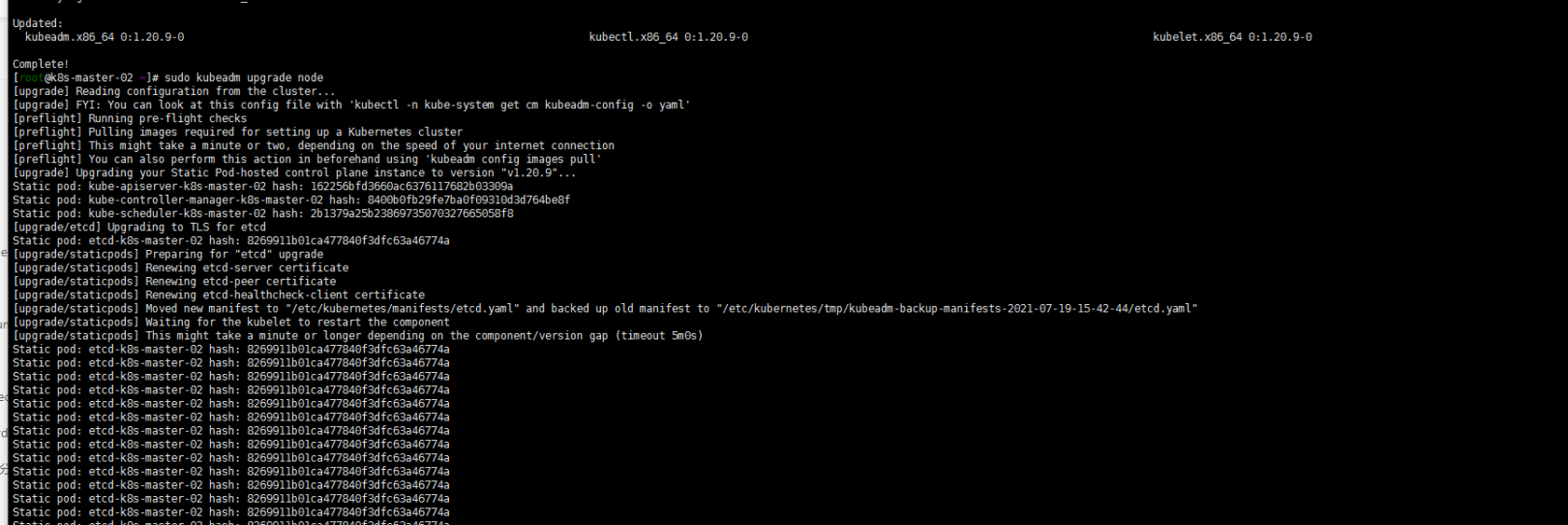
yum install kubeadm-1.20.9-0 kubelet-1.20.9-0 kubectl-1.20.9-0 --disableexcludes=kubernetes sudo kubeadm upgrade node sudo systemctl daemon-reload sudo systemctl restart kubelet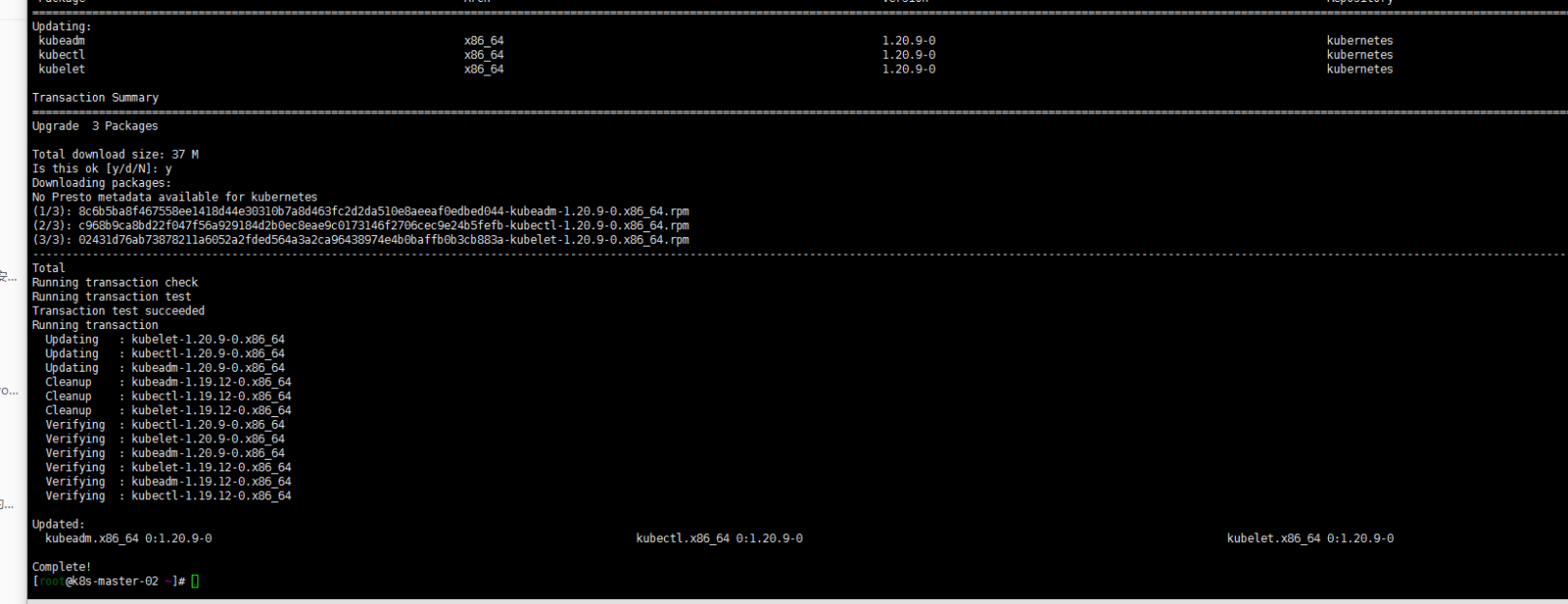
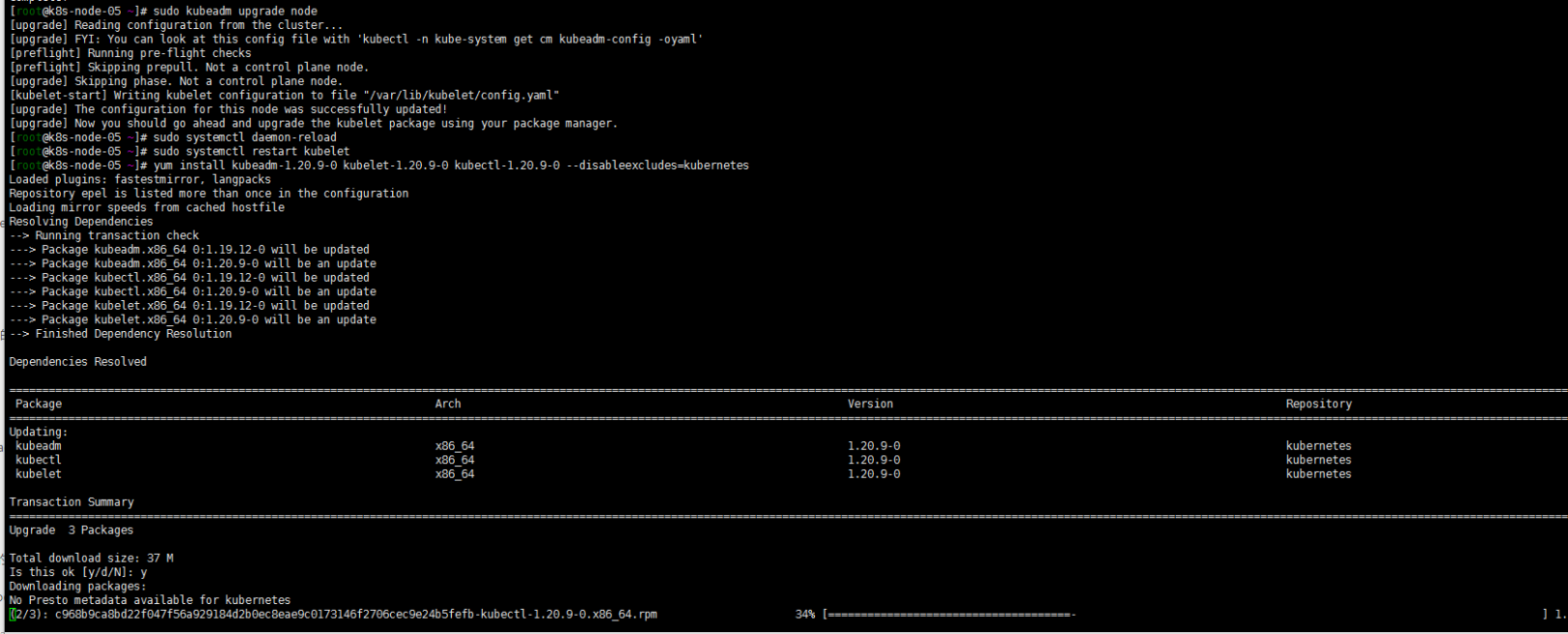
5. work节点的升级
yum install kubeadm-1.20.9-0 kubelet-1.20.9-0 kubectl-1.20.9-0 --disableexcludes=kubernetes sudo kubeadm upgrade node sudo systemctl daemon-reload sudo systemctl restart kubelet注: 个人都没有腾空节点,看个人需求了
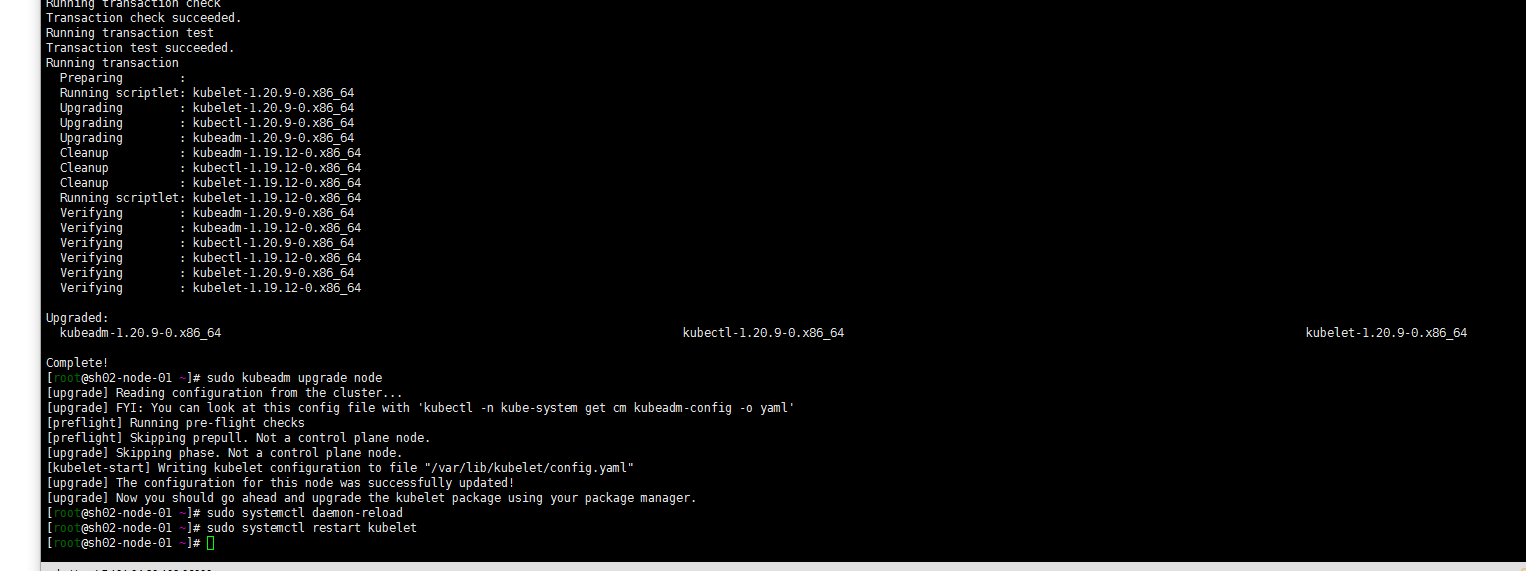
6. 验证升级
kubectl get nodes
7. 其他——v1.20.0中禁用了selfLink
由于我的Prometheus oprator是0.4的分支,就准备卸载重新安装了。版本差距太大了。现在也不想搞什么分支用了直接用主线版本了:
基本过程参照:Kubernetes 1.20.5 安装Prometheus-Oprator。基本过程都没有问题,讲一个有问题的地方:
我的kubernetes1.16升级上来的这个集群storageclass是用的nfs:
kubectl get sc
最后一
kubectl get pods -n monitoring kubectl logs -f prometheus-operator-84dc795dc8-lkl5r -n monitoring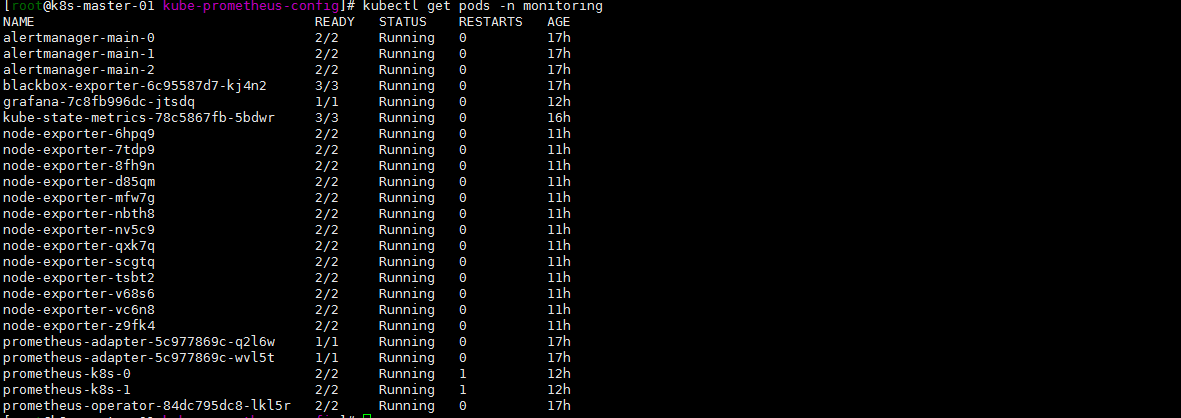
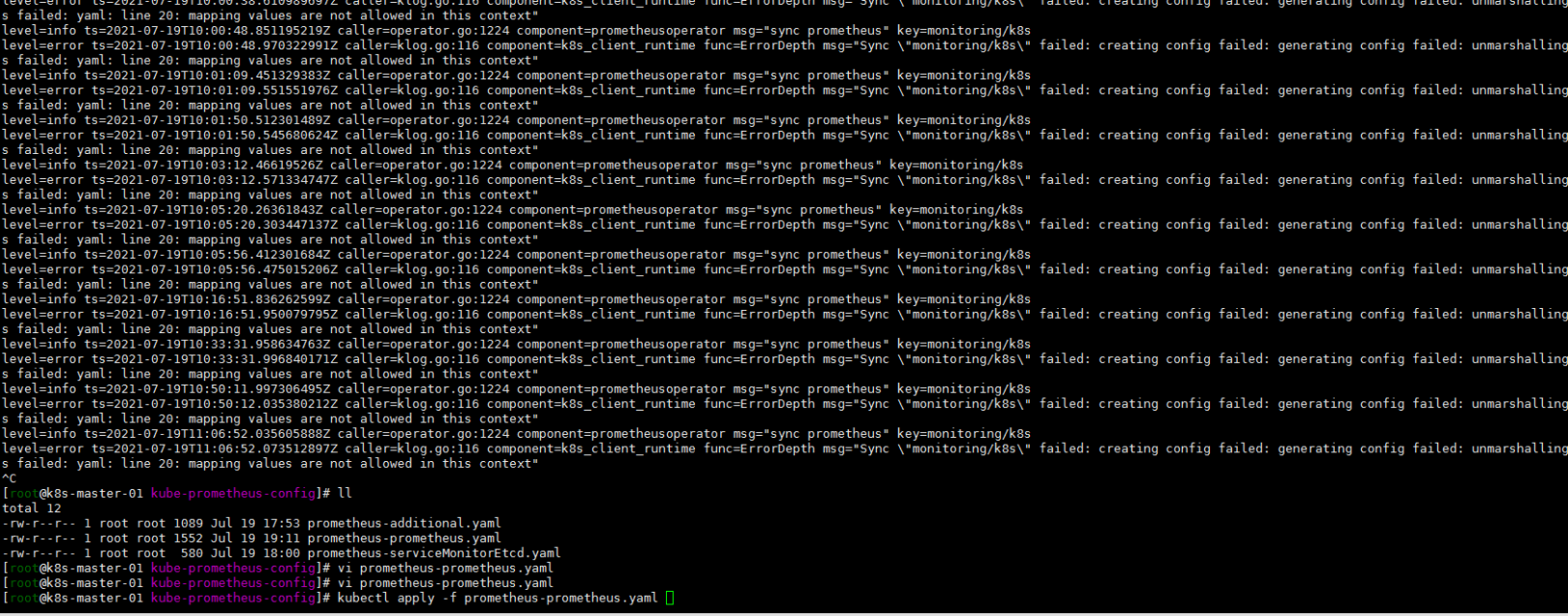
看关键词吧:
additional 貌似是自动发现的配置?
首先将prometheus-prometheus.yaml文件中的自动发现的配置注释掉。嗯服务还是没有起来,再看一眼日志:
kubectl logs -f prometheus-operator-84dc795dc8-lkl5r -n monitoring没有什么新的输出,但是看一眼pv,pvc没有创建。去看一下nfs的pod日志:
kubectl get pods -n nfs kubectl logs -f nfs-client-provisioner-6cb4f54cbc-wqqw9 -n nfs
class “managed-nfs-storage”: unexpected error getting claim reference: selfLink was empty, can’t make reference
百度selfLink参照:https://www.orchome.com/10024
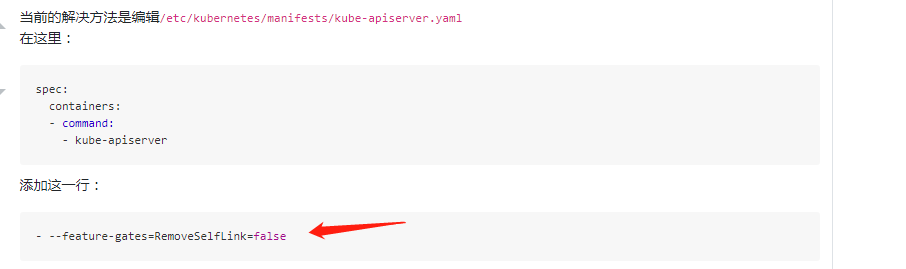
修改三个master节点的kube-apiserver.yaml
然后pv,pvc创建成功 Prometheus 服务启动成功。然后再回过头来看一眼我的additional自动发现配置:
我在Kubernetes 1.20.5 安装Prometheus-Oprator
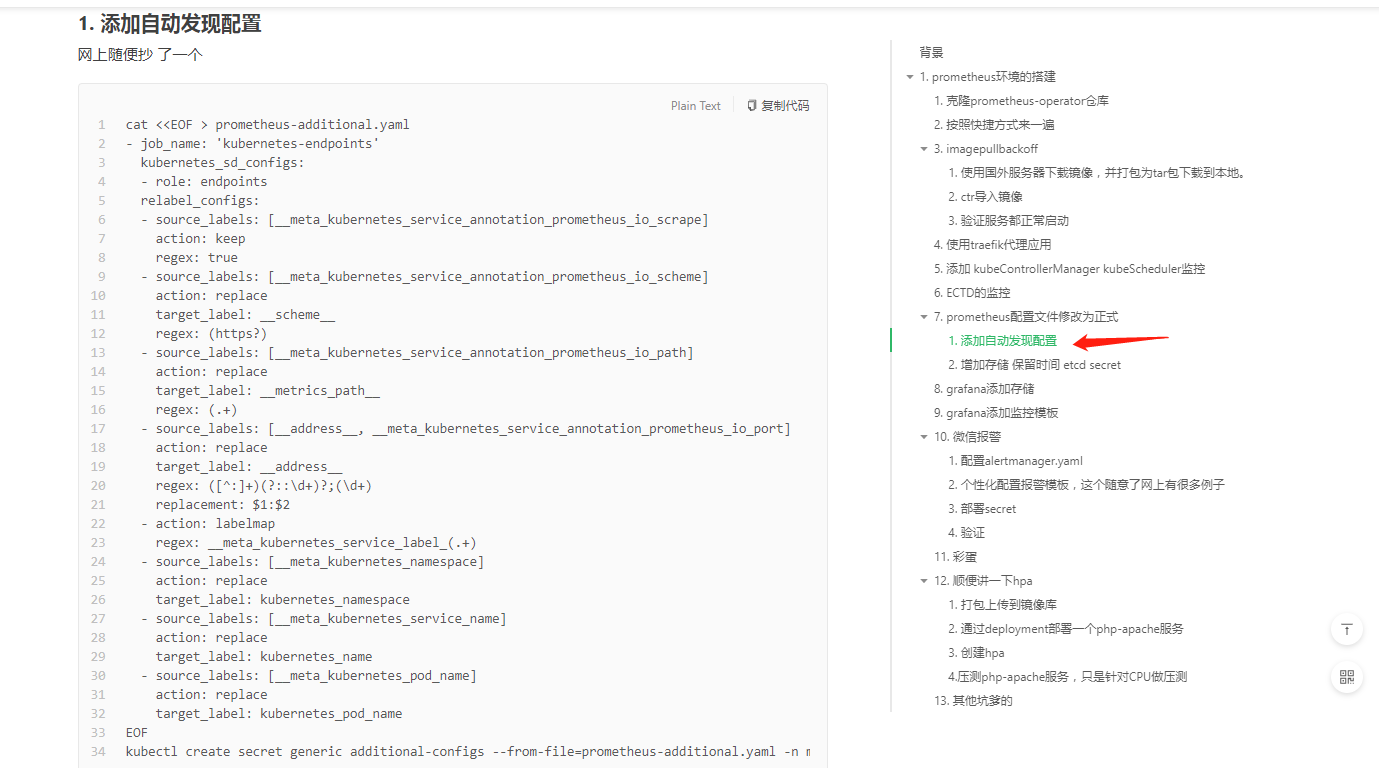
拿我的老版本的这个文件试试?:
cat <<EOF > prometheus-additional.yaml - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name EOFkubectl delete secret additional-configs -n monitoring kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring再看日志启动起来了。初步先怀疑我配置文件中的prometheus-additional.yaml 有问题。当然了这是个人问题了。强调的主要是master节点kube-apiserver.yaml文件的修改添加:
- --feature-gates=RemoveSelfLink=false
-
2021-07-19-Kubernetes 1.18.20升级到1.19.12
背景:
升级是一件持续的事情:Kubernetes 1.16.15升级到1.17.17,Kubernetes 1.17.17升级到1.18.20
集群配置:
主机名 系统 ip k8s-vip slb 10.0.0.37 k8s-master-01 centos7 10.0.0.41 k8s-master-02 centos7 10.0.0.34 k8s-master-03 centos7 10.0.0.26 k8s-node-01 centos7 10.0.0.36 k8s-node-02 centos7 10.0.0.83 k8s-node-03 centos7 10.0.0.40 k8s-node-04 centos7 10.0.0.49 k8s-node-05 centos7 10.0.0.45 k8s-node-06 centos7 10.0.0.18 1. 参考官方文档
参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
2. 确认可升级版本与升级方案
yum list --showduplicates kubeadm --disableexcludes=kubernetes通过以上命令查询到1.19当前最新版本是1.19.12-0版本。master有三个节点还是按照个人习惯先升级k8s-master-03节点
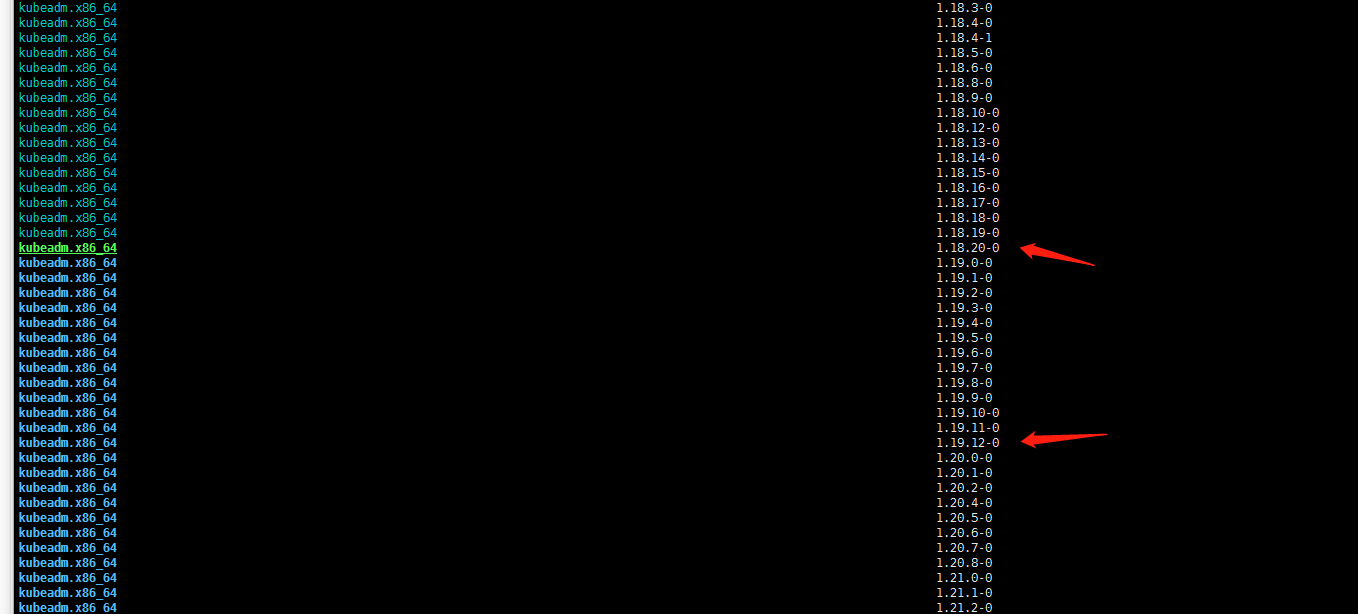
3. 升级k8s-master-03节点控制平面
依然k8s-master-03执行:
1. yum升级kubernetes插件
yum install kubeadm-1.19.12-0 kubelet-1.19.12-0 kubectl-1.19.12-0 --disableexcludes=kubernetes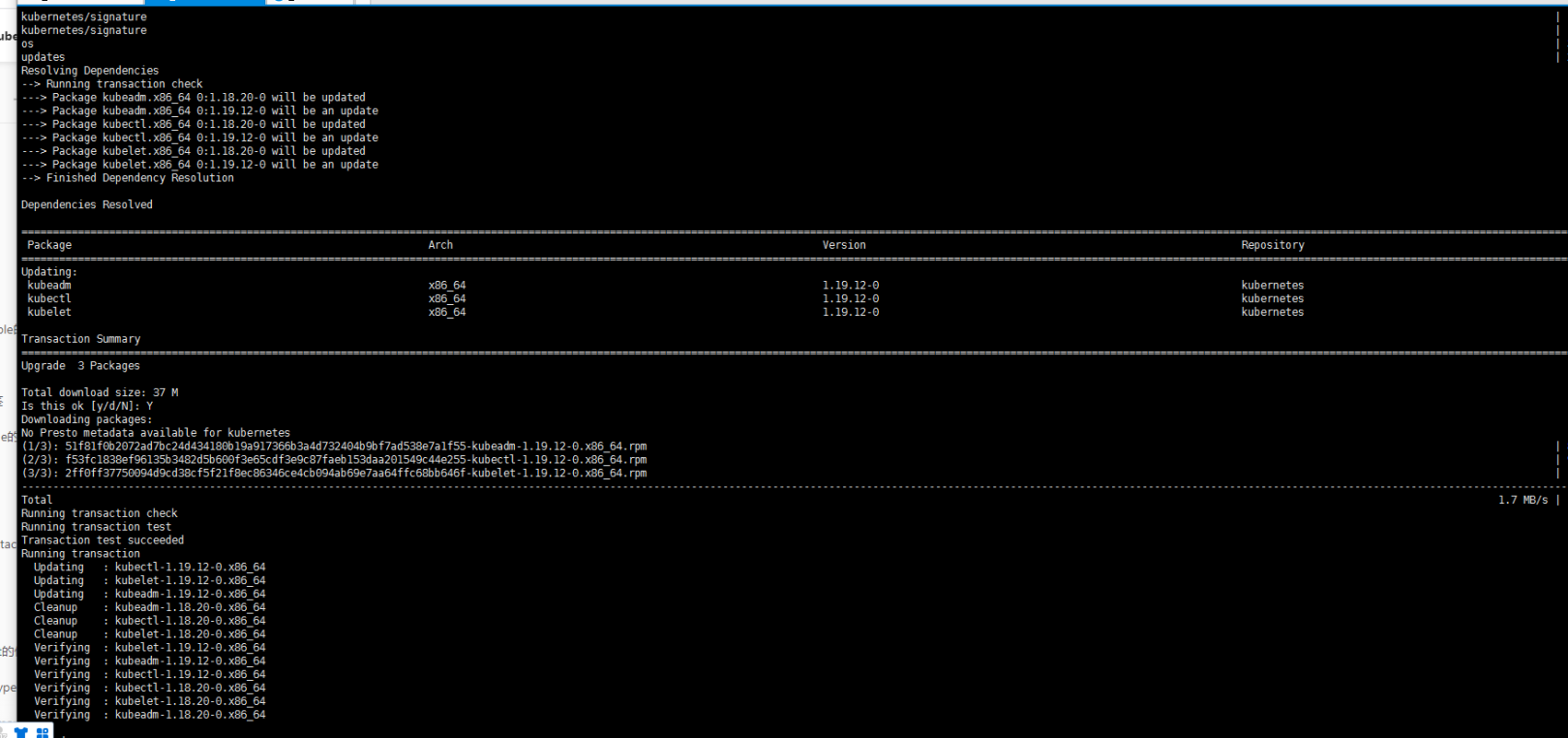
2. 腾空节点检查集群是否可以升级
依然算是温习drain命令:
kubectl drain k8s-master-03 --ignore-daemonsets sudo kubeadm upgrade plan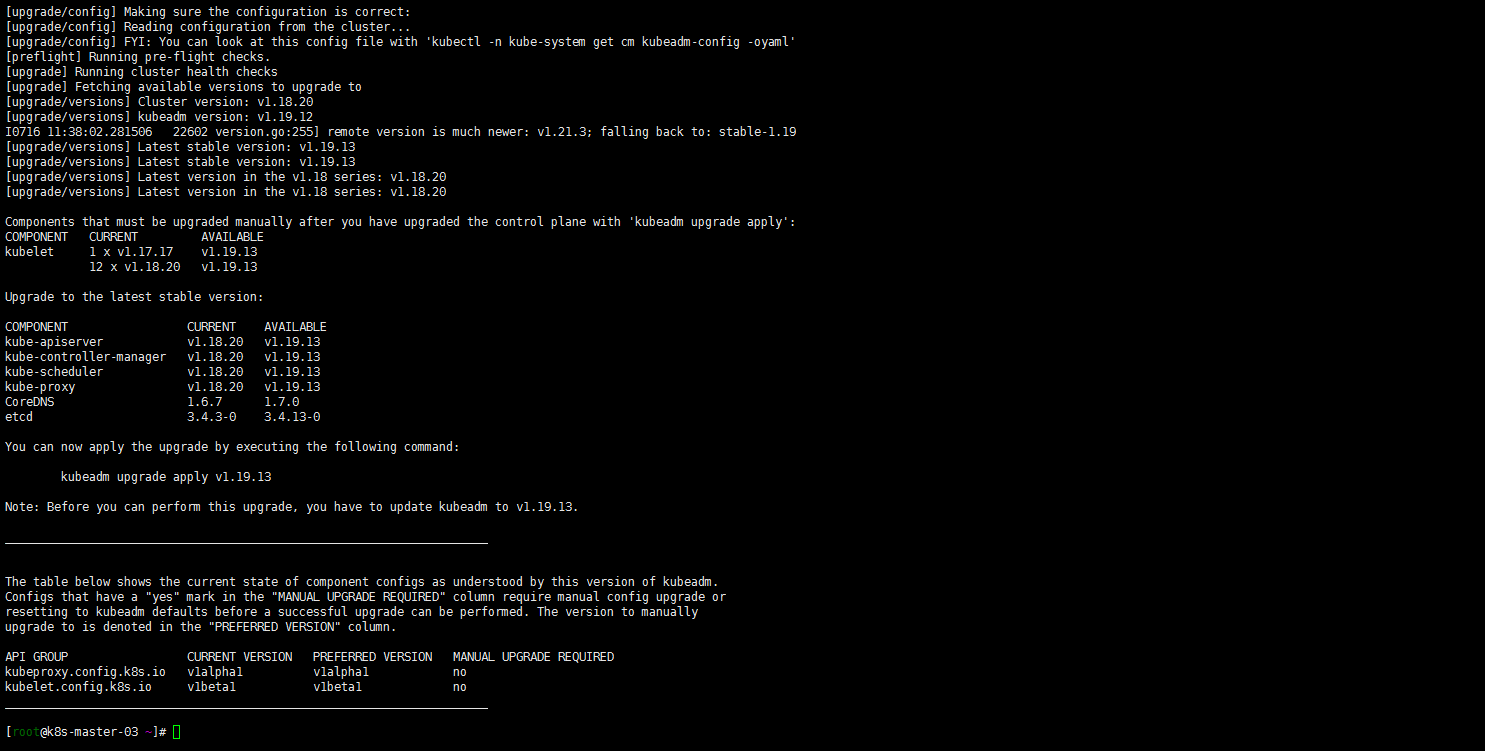
3. 升级版本到1.19.12
kubeadm upgrade apply 1.19.12注意:特意强调一下work节点的版本也都是1.18.20了,没有出现夸更多版本的状况了
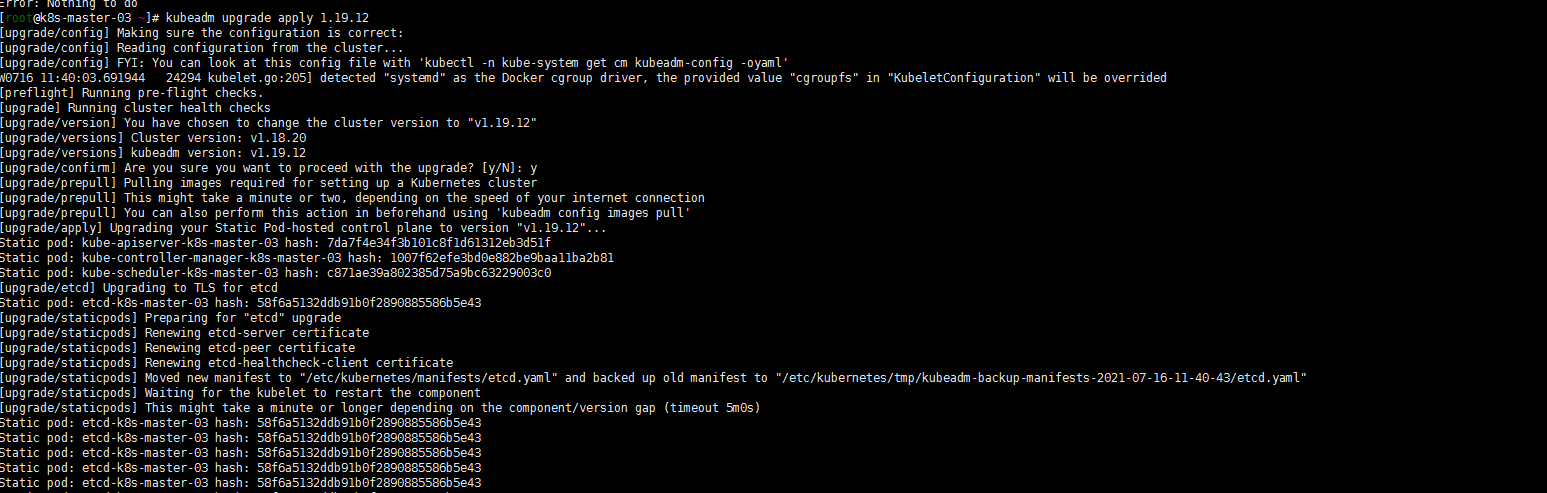
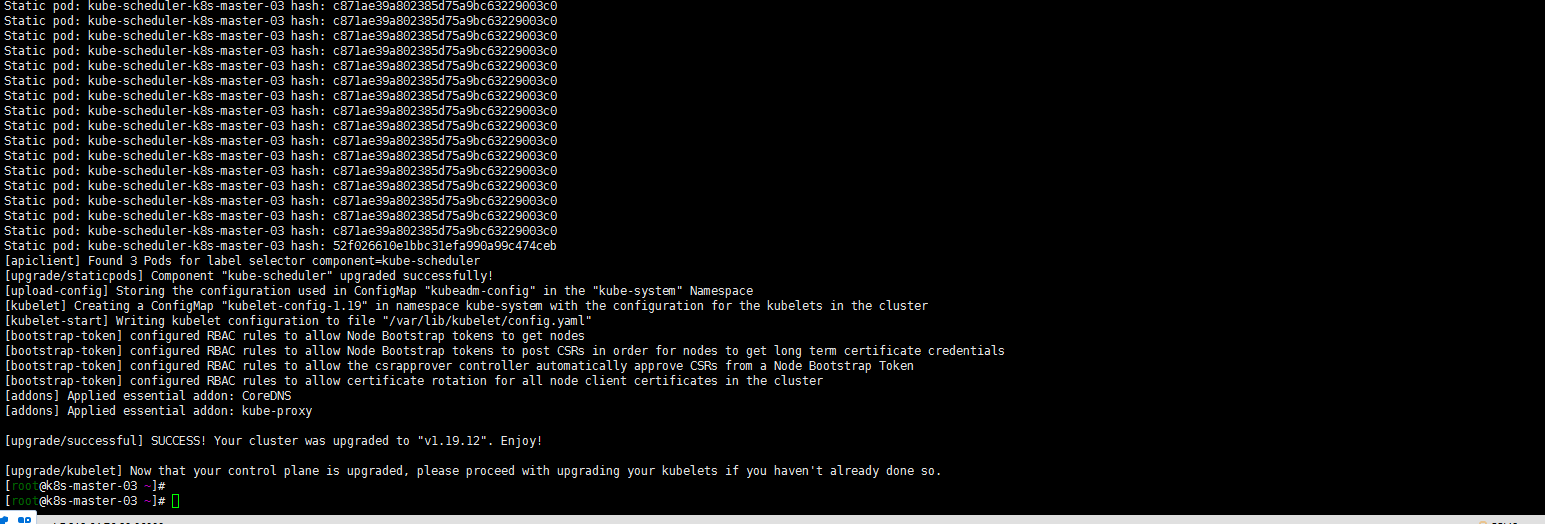
[root@k8s-master-03 ~]# sudo systemctl daemon-reload [root@k8s-master-03 ~]# sudo systemctl restart kubelet [root@k8s-master-03 ~]# kubectl uncordon k8s-master-03 node/k8s-master-03 uncordoned
4. 升级其他控制平面(k8s-master-01 k8s-master-02)
sudo yum install kubeadm-1.19.12-0 kubelet-1.19.12-0 kubectl-1.19.12-0 --disableexcludes=kubernetes sudo kubeadm upgrade node sudo systemctl daemon-reload sudo systemctl restart kubelet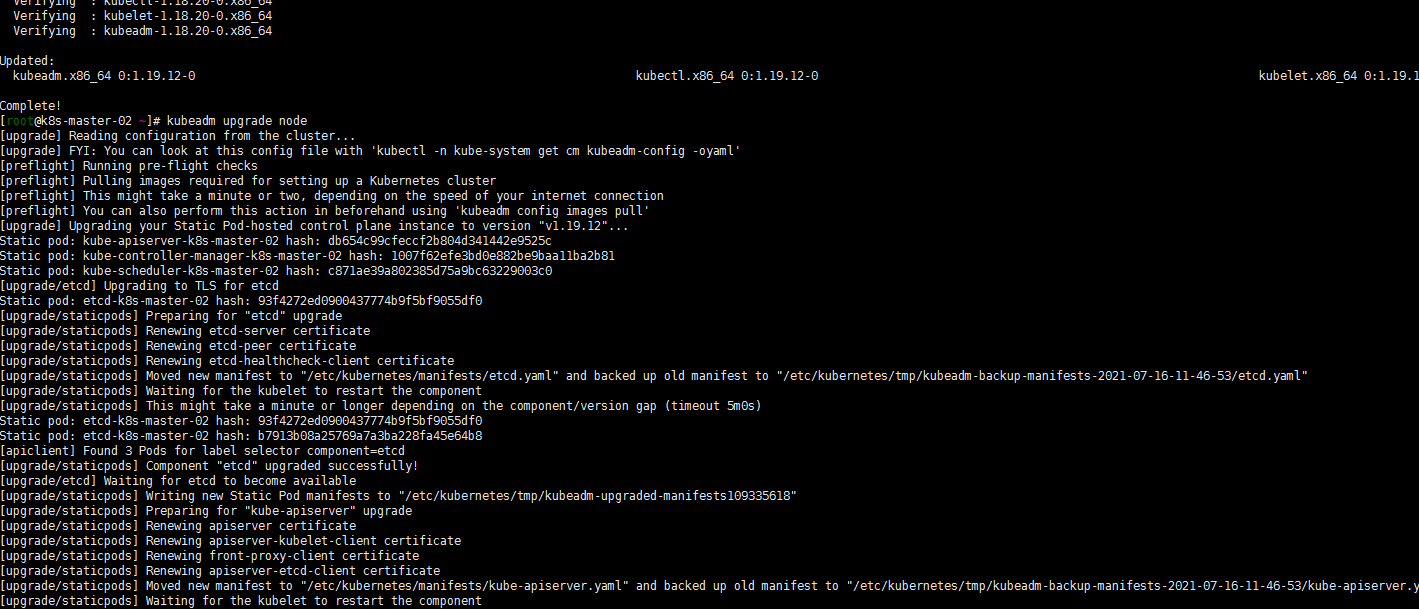
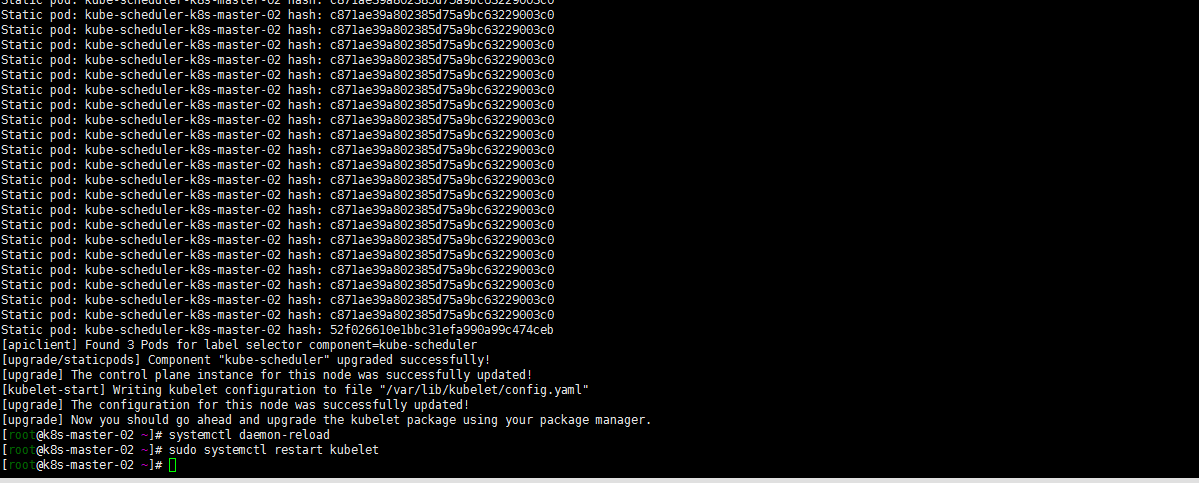
5. work节点的升级
sudo yum install kubeadm-1.19.12-0 kubelet-1.19.12-0 kubectl-1.19.12-0 --disableexcludes=kubernetes sudo kubeadm upgrade node sudo systemctl daemon-reload sudo systemctl restart kubelet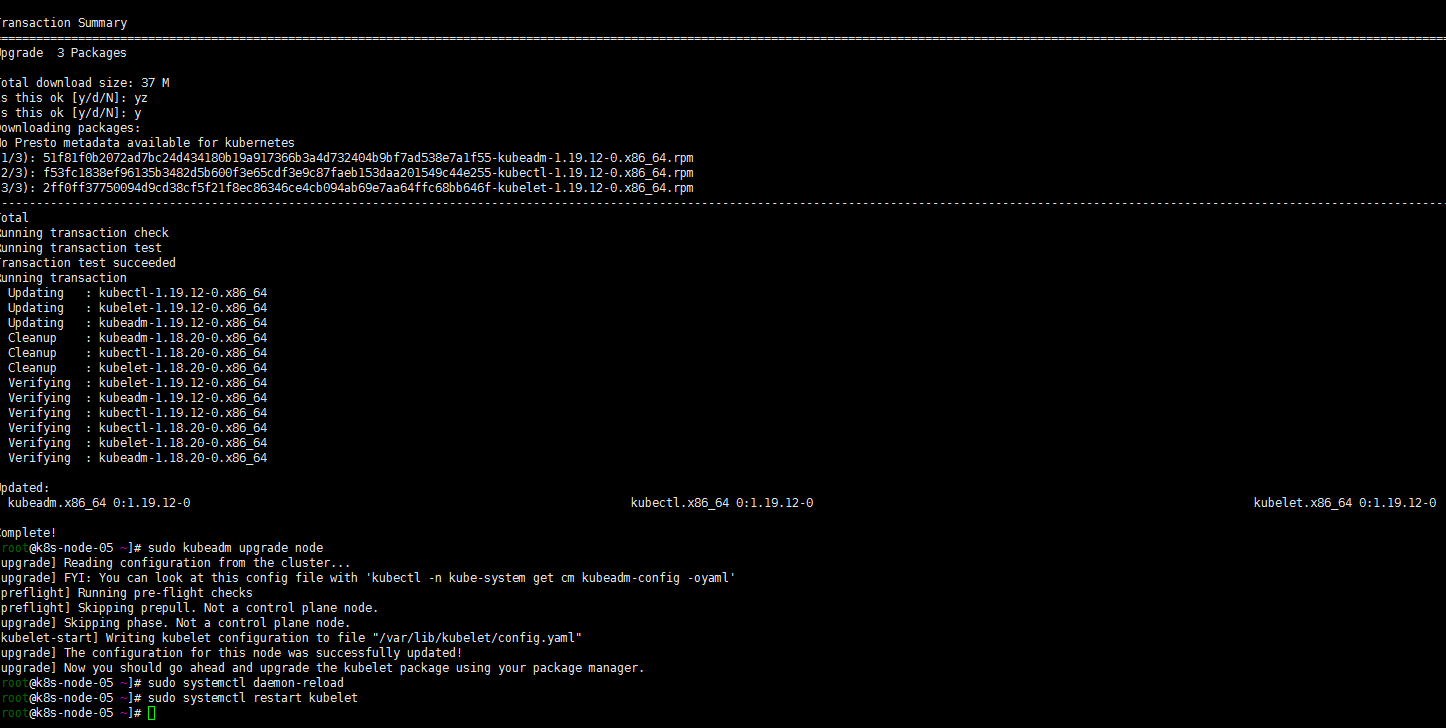
6. 验证升级
kubectl get nodes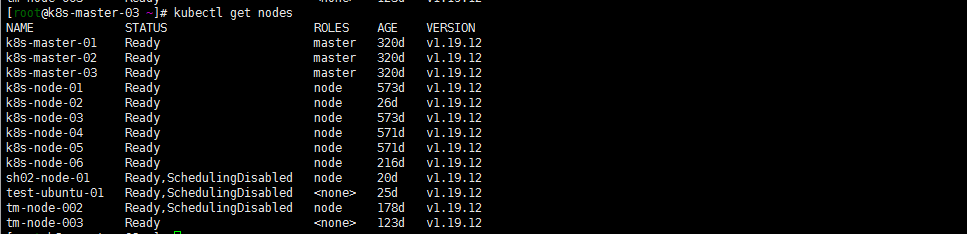
7. 其他
查看一眼kube-system下插件的日志,确认插件是否正常
kubectl logs -f kube-controller-manager-k8s-master-01 -n kube-system
目测是没有问题的就不管了….嗯Prometheus的问题还是留着。本来也准备安装主线版本了。过去的准备卸载了.如出现cluseterrole问题可参照:Kubernetes 1.16.15升级到1.17.17
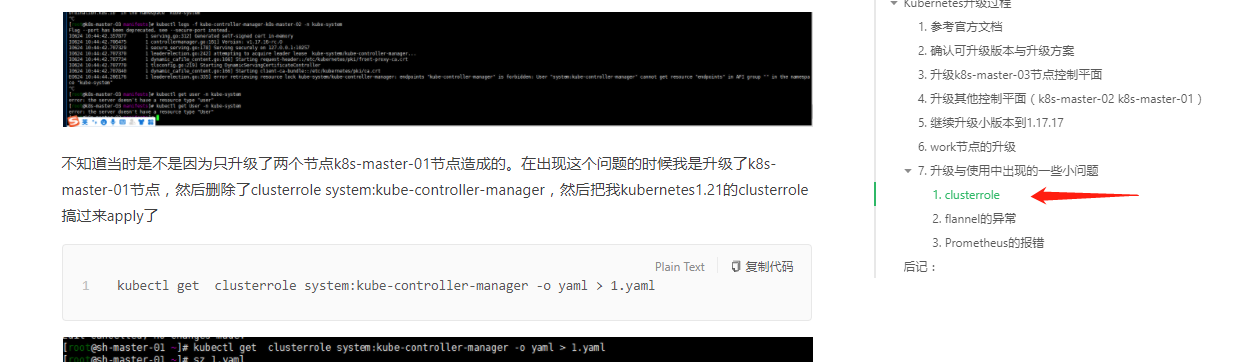

-
2021-07-17-Kubernetes 1.17.17升级到1.18.20
背景:
参照:https://www.yuque.com/duiniwukenaihe/ehb02i/kdvrku 完成了1.16.15到1.17.17 的升级,现在升级到1.18版本
集群配置
主机名 系统 ip k8s-vip slb 10.0.0.37 k8s-master-01 centos7 10.0.0.41 k8s-master-02 centos7 10.0.0.34 k8s-master-03 centos7 10.0.0.26 k8s-node-01 centos7 10.0.0.36 k8s-node-02 centos7 10.0.0.83 k8s-node-03 centos7 10.0.0.40 k8s-node-04 centos7 10.0.0.49 k8s-node-05 centos7 10.0.0.45 k8s-node-06 centos7 10.0.0.18 1. 参考官方文档
参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
https://v1-17.docs.kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
kubeadm 创建的 Kubernetes 集群从 1.16.x 版本升级到 1.17.x 版本,以及从版本 1.17.x 升级到 1.17.y ,其中 y > x。现在继续将版本升级到1.18。从1.16升级到1.17有点理解错误:1.16.15我以为只能先升级到1.17.15。仔细看了下文档是没有这说法的。我就准备从1.17.17升级到1.18的最新版本了!

2. 确认可升级版本与升级方案
yum list --showduplicates kubeadm --disableexcludes=kubernetes通过以上命令查询到1.18当前最新版本是1.18.20-0版本。master有三个节点还是按照个人习惯先升级k8s-master-03节点
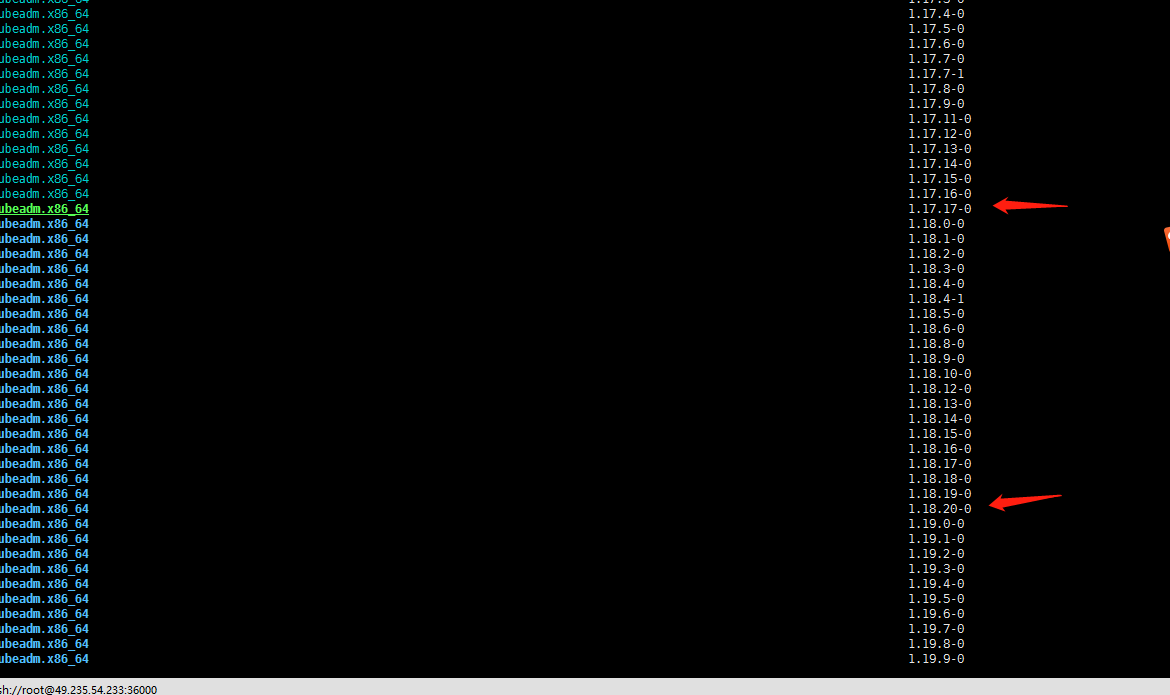
3. 升级k8s-master-03节点控制平面
依然k8s-master-03执行:
1. yum升级kubernetes插件
yum install kubeadm-1.18.20-0 kubelet-1.18.20-0 kubectl-1.18.20-0 --disableexcludes=kubernetes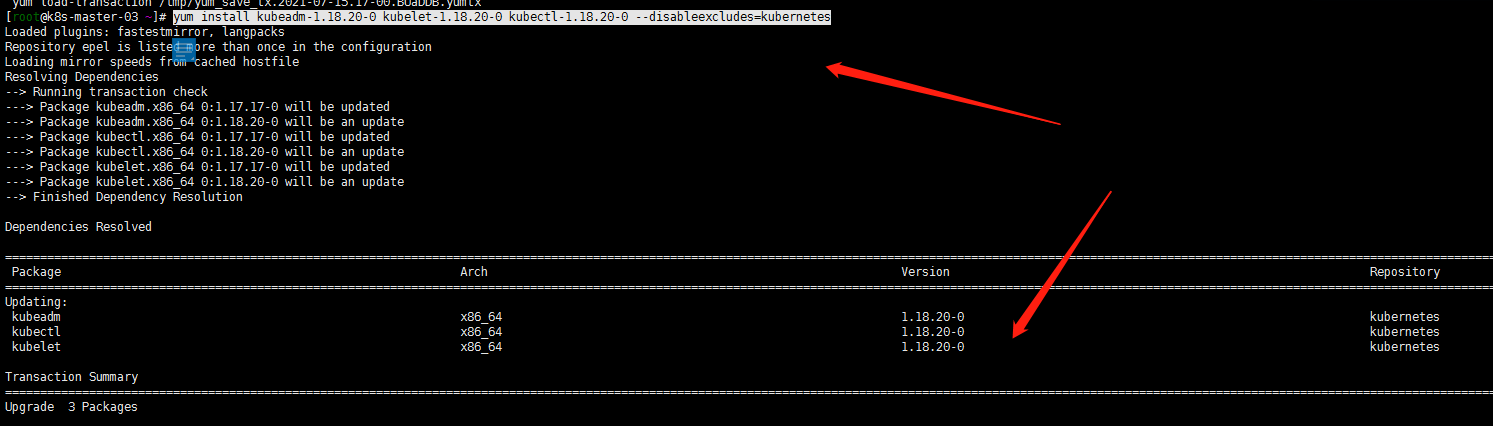
2. 腾空节点检查集群是否可以升级
特意整一下腾空(1.16.15升级到1.17.17的时候没有整。就当温习一下drain命令了)
kubectl drain k8s-master-03 --ignore-daemonsets sudo kubeadm upgrade plan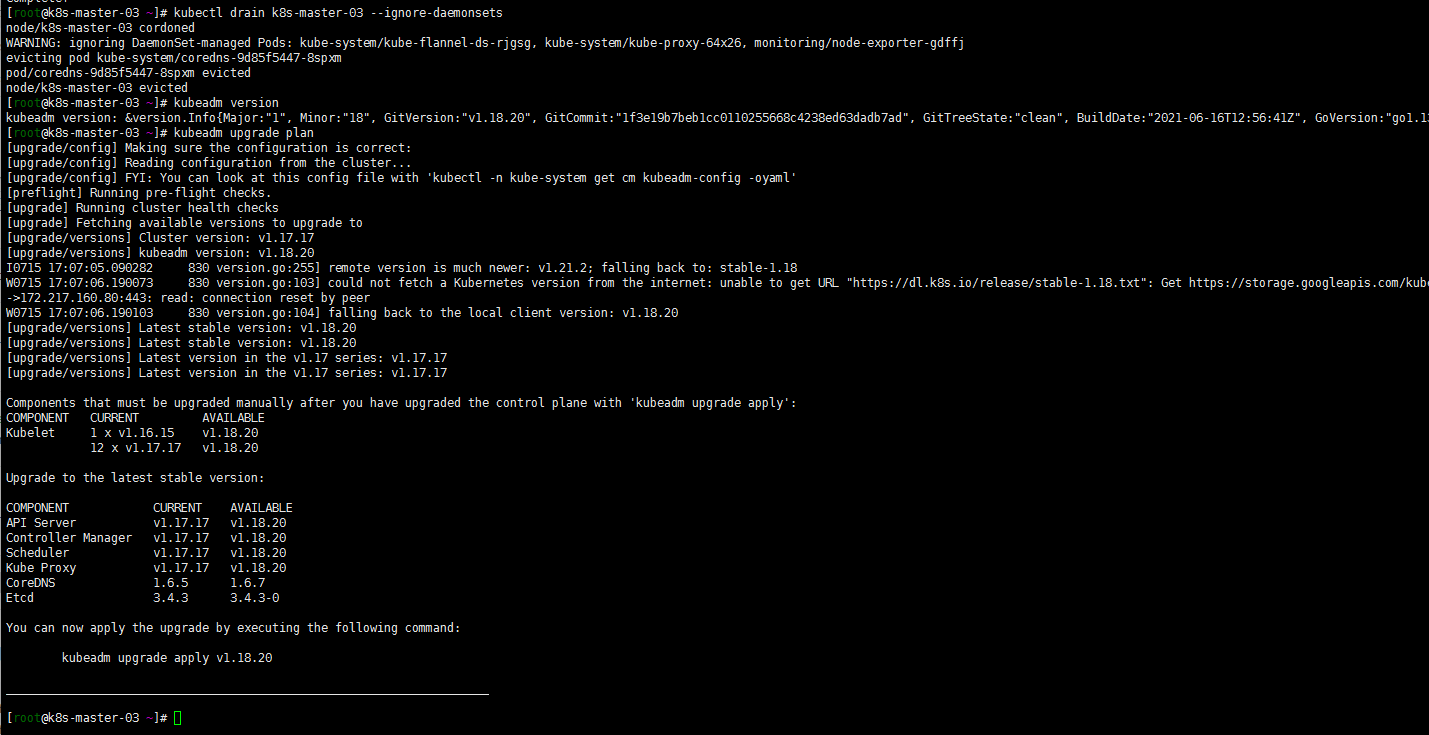
3. 升级版本到1.18.20
1. 小插曲
嗯操作升级到1.18.20版本
kubeadm upgrade apply 1.18.20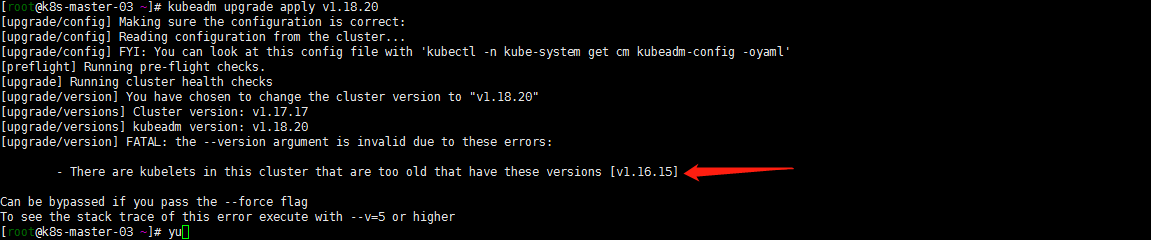
嗯有一个work节点没有升级版本依然是1.16.15版本哈哈哈提示一下。master节点应该是向下兼容一个版本的。先把test-ubuntu-01节点升级到1.17.17
[root@k8s-master-01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-01 Ready master 317d v1.17.17 k8s-master-02 Ready master 317d v1.17.17 k8s-master-03 Ready,SchedulingDisabled master 317d v1.17.17 k8s-node-01 Ready node 569d v1.17.17 k8s-node-02 Ready node 22d v1.17.17 k8s-node-03 Ready node 569d v1.17.17 k8s-node-04 Ready node 567d v1.17.17 k8s-node-05 Ready node 567d v1.17.17 k8s-node-06 Ready node 212d v1.17.17 sh02-node-01 Ready node 16d v1.17.17 test-ubuntu-01 Ready,SchedulingDisabled <none> 22d v1.16.15 tm-node-002 Ready,SchedulingDisabled node 174d v1.17.17 tm-node-003 Ready <none> 119d v1.17.17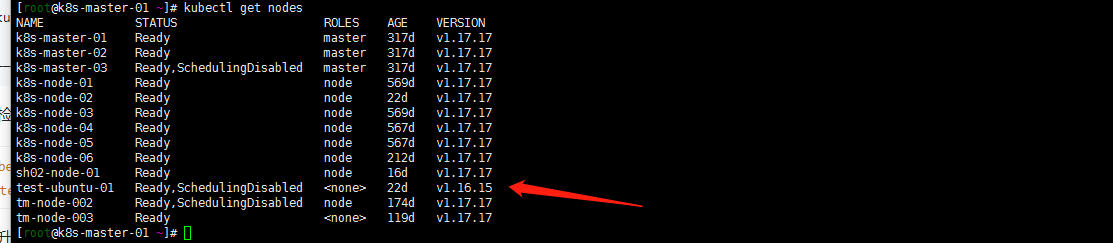
先升级下test-ubuntu-01节点如下(此操作在test-ubuntu-01节点执行):
sudo apt-get install -y kubelet=1.17.17-00 kubectl=1.17.17-00 kubeadm=1.17.17-00 sudo kubeadm upgrade node sudo systemctl daemon-reload sudo systemctl restart kubelet登陆任一master节点确认版本都为1.17.17版本(正常在k8s-master-03节点看就行了,我xshell开了好几个窗口就那01节点看了):
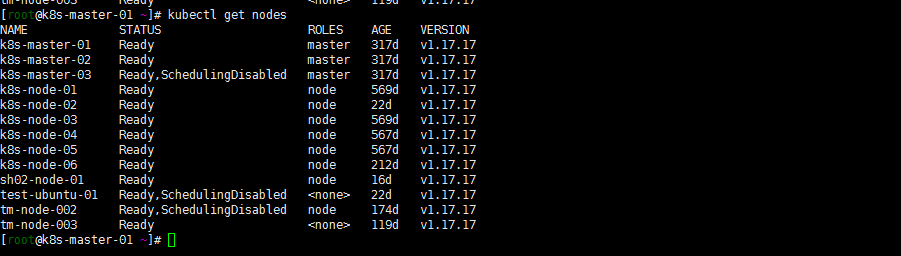
2. 升级到1.18.20
k8s-master-03节点继续执行升级:
kubeadm upgrade apply v1.18.20
3. 重启kubelet 取消节点保护
[root@k8s-master-03 ~]# sudo systemctl daemon-reload [root@k8s-master-03 ~]# sudo systemctl restart kubelet [root@k8s-master-03 ~]# kubectl uncordon k8s-master-03 node/k8s-master-03 uncordoned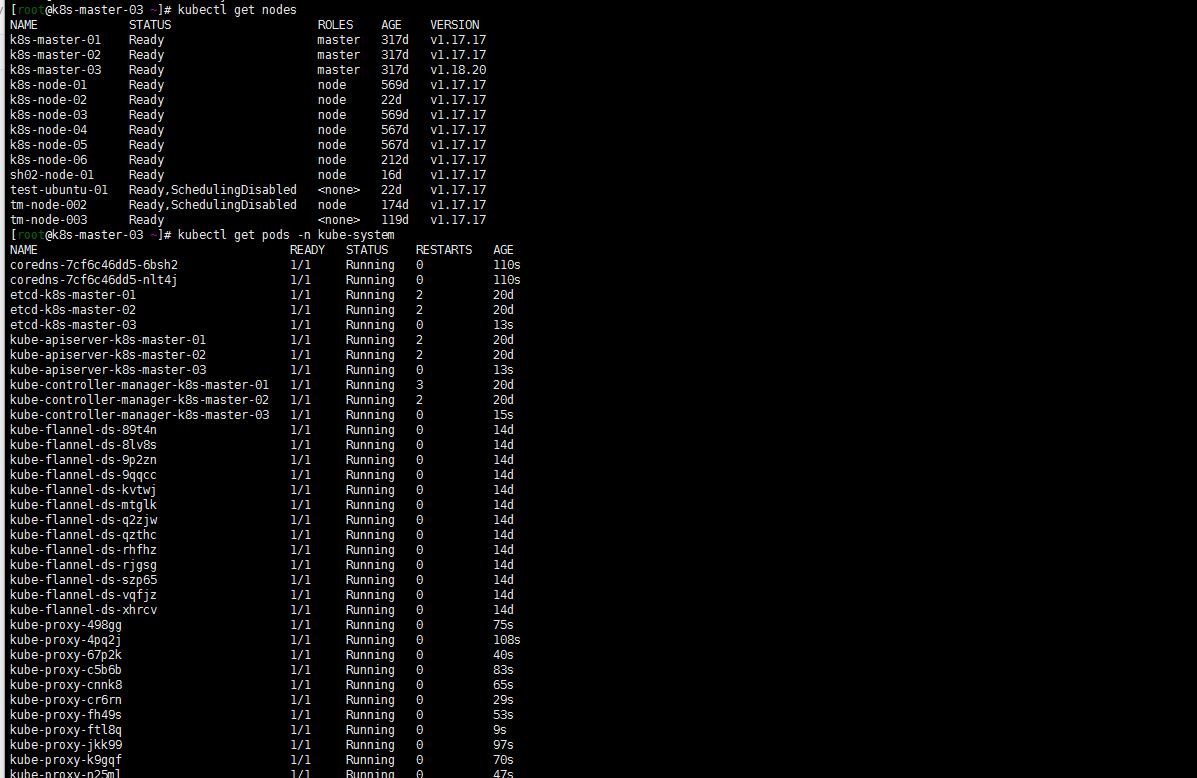
4. 升级其他控制平面(k8s-master-01 k8s-master-02)
k8s-master-01 k8s-master-02节点都执行以下操作(这里就没有清空节点了,看个人需求):
yum install kubeadm-1.18.20-0 kubelet-1.18.20-0 kubectl-1.18.20-0 --disableexcludes=kubernetes kubeadm upgrade node systemctl daemon-reload sudo systemctl restart kubelet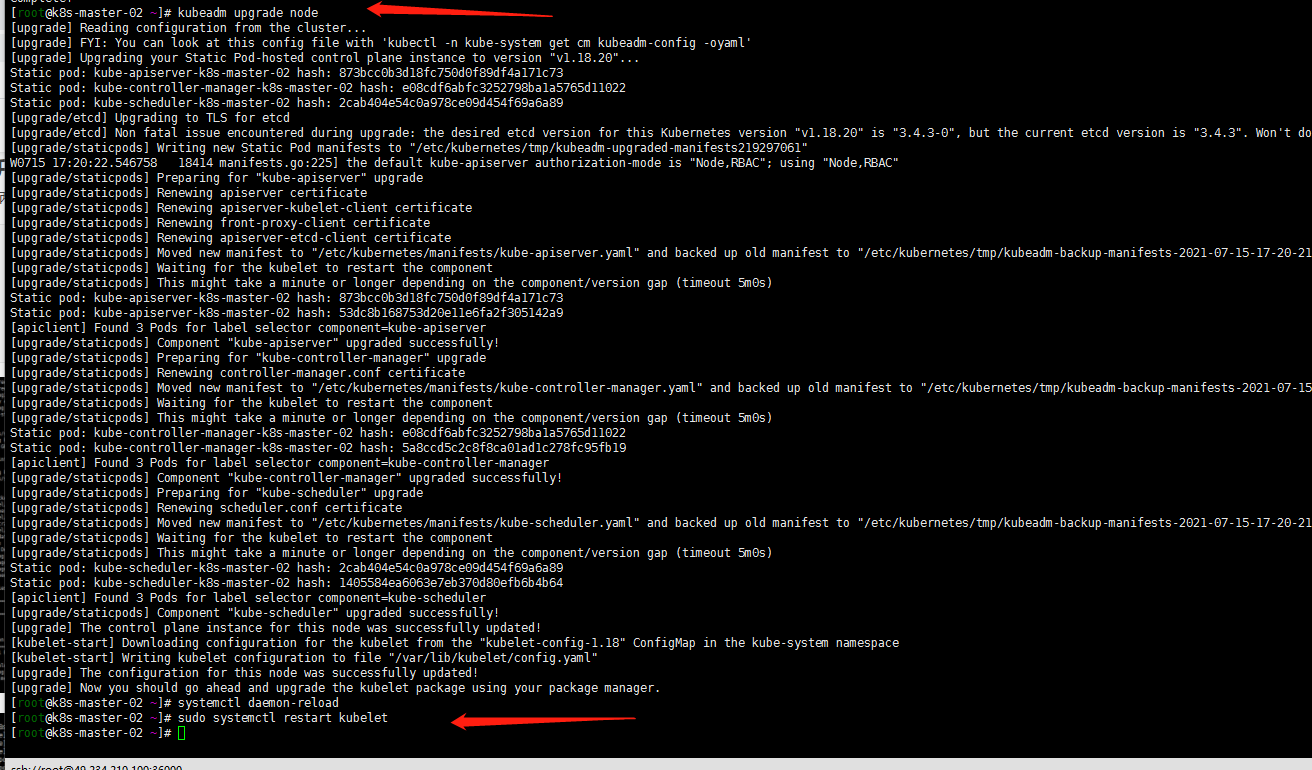
5. work节点的升级
没有执行清空节点(当然了 例行升级的话还是最后执行以下清空节点),直接升级了,如下:
yum install kubeadm-1.18.20-0 kubelet-1.18.20-0 kubectl-1.18.20-0 --disableexcludes=kubernetes kubeadm upgrade node systemctl daemon-reload sudo systemctl restart kubelet6. 验证升级
kubectl get nodes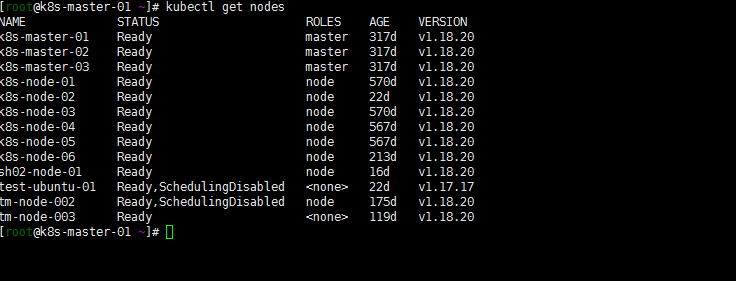
注意:test-ubuntu-01忽略。
目测是升级成功的,看一下kube-system下的几个系统组件发现:ontroller-manager的clusterrole system:kube-controller-manager的权限又有问题了?

同1.16.15升级1.17.17一样:
kubectl get clusterrole system:kube-controller-manager -o yaml > 1.yaml kubectl delete clusterrole system:kube-controller-managercat <<EOF > kube-controller-manager.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2021-03-22T11:29:59Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:kube-controller-manager resourceVersion: "92" uid: 7480dabb-ec0d-4169-bdbd-418d178e2751 rules: - apiGroups: - "" - events.k8s.io resources: - events verbs: - create - patch - update - apiGroups: - coordination.k8s.io resources: - leases verbs: - create - apiGroups: - coordination.k8s.io resourceNames: - kube-controller-manager resources: - leases verbs: - get - update - apiGroups: - "" resources: - endpoints verbs: - create - apiGroups: - "" resourceNames: - kube-controller-manager resources: - endpoints verbs: - get - update - apiGroups: - "" resources: - secrets - serviceaccounts verbs: - create - apiGroups: - "" resources: - secrets verbs: - delete - apiGroups: - "" resources: - configmaps - namespaces - secrets - serviceaccounts verbs: - get - apiGroups: - "" resources: - secrets - serviceaccounts verbs: - update - apiGroups: - authentication.k8s.io resources: - tokenreviews verbs: - create - apiGroups: - authorization.k8s.io resources: - subjectaccessreviews verbs: - create - apiGroups: - '*' resources: - '*' verbs: - list - watch - apiGroups: - "" resources: - serviceaccounts/token verbs: - create EOF kubectl apply -f kube-controller-manager.yaml目测是可以了…………………..截图过程都找不到了,昨天晚上写的东西没有保存停电了……
这里的flannel没有什么问题 就不用看了 Prometheus依然是有问题的……我就先忽略了。因为我还准备升级集群版本…升级版本后再搞Prometheus了
-
2021-07-16-TKE1.20.6搭建elasticsearch on kubernetes
背景:
昨天刚开通了TKE1.20.6版本,想体验下elasticsearch 环境搭建到集群上,基本参照Kuberentes 1.20.5搭建eck。当然了版本还是有区别的当时安装的时候eck版本是1.5。现在貌似是1.6了?参见官方文档:https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-deploy-eck.html
1. 在kubernete集群中部署ECK
1. 安装自定义资源定义和操作员及其RBAC规则:
kubectl apply -f https://download.elastic.co/downloads/eck/1.6.0/all-in-one.yaml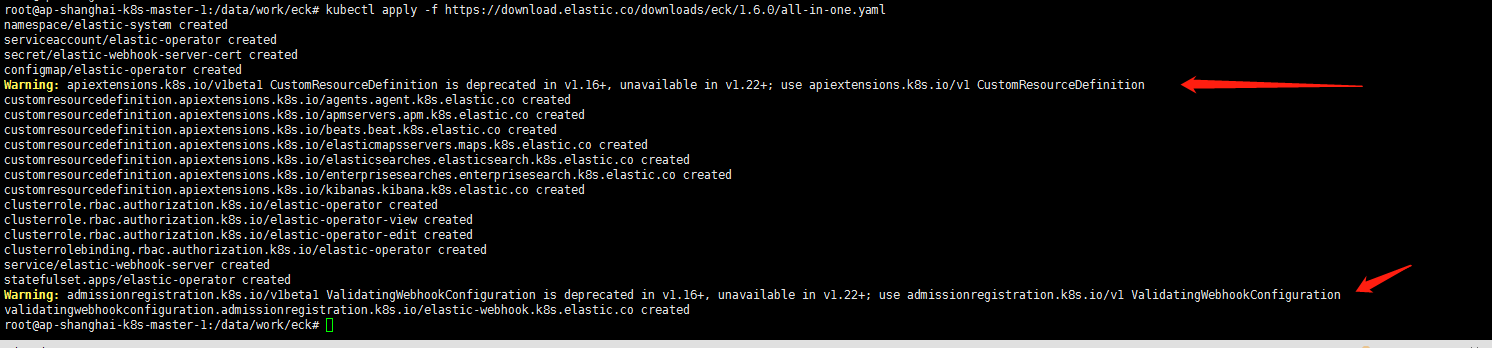
2. 监视操作日志:
kubectl -n elastic-system logs -f statefulset.apps/elastic-operator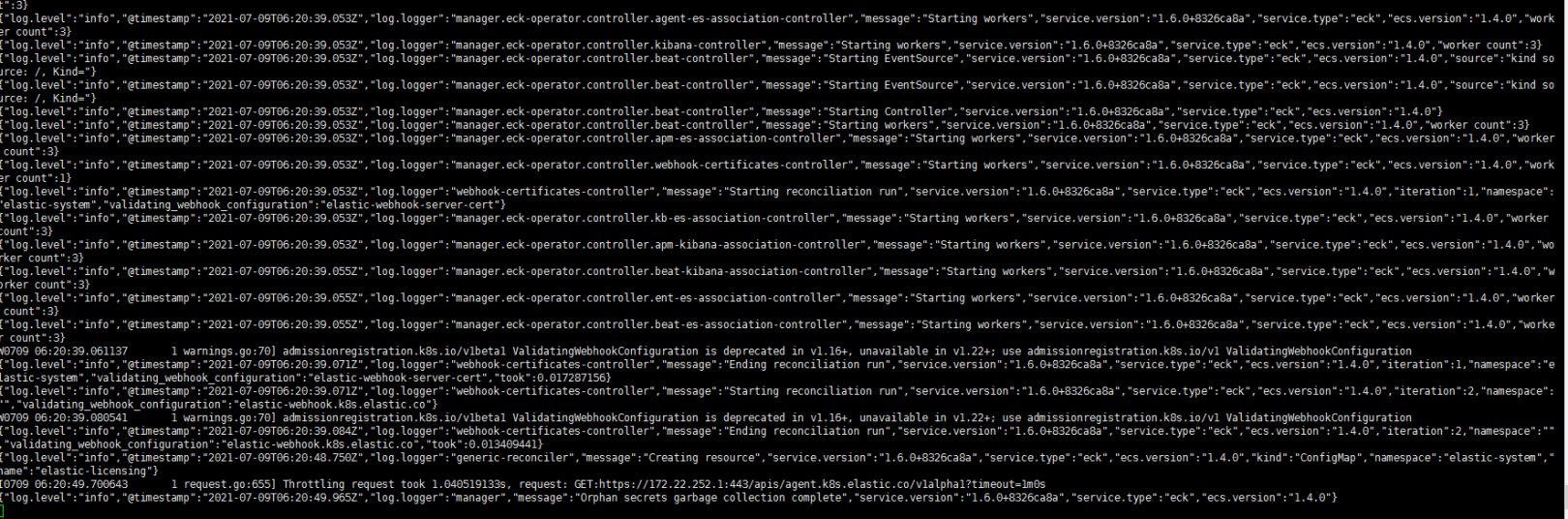
2. 部署elasticsearch集群
1. 定制化elasticsearch 镜像
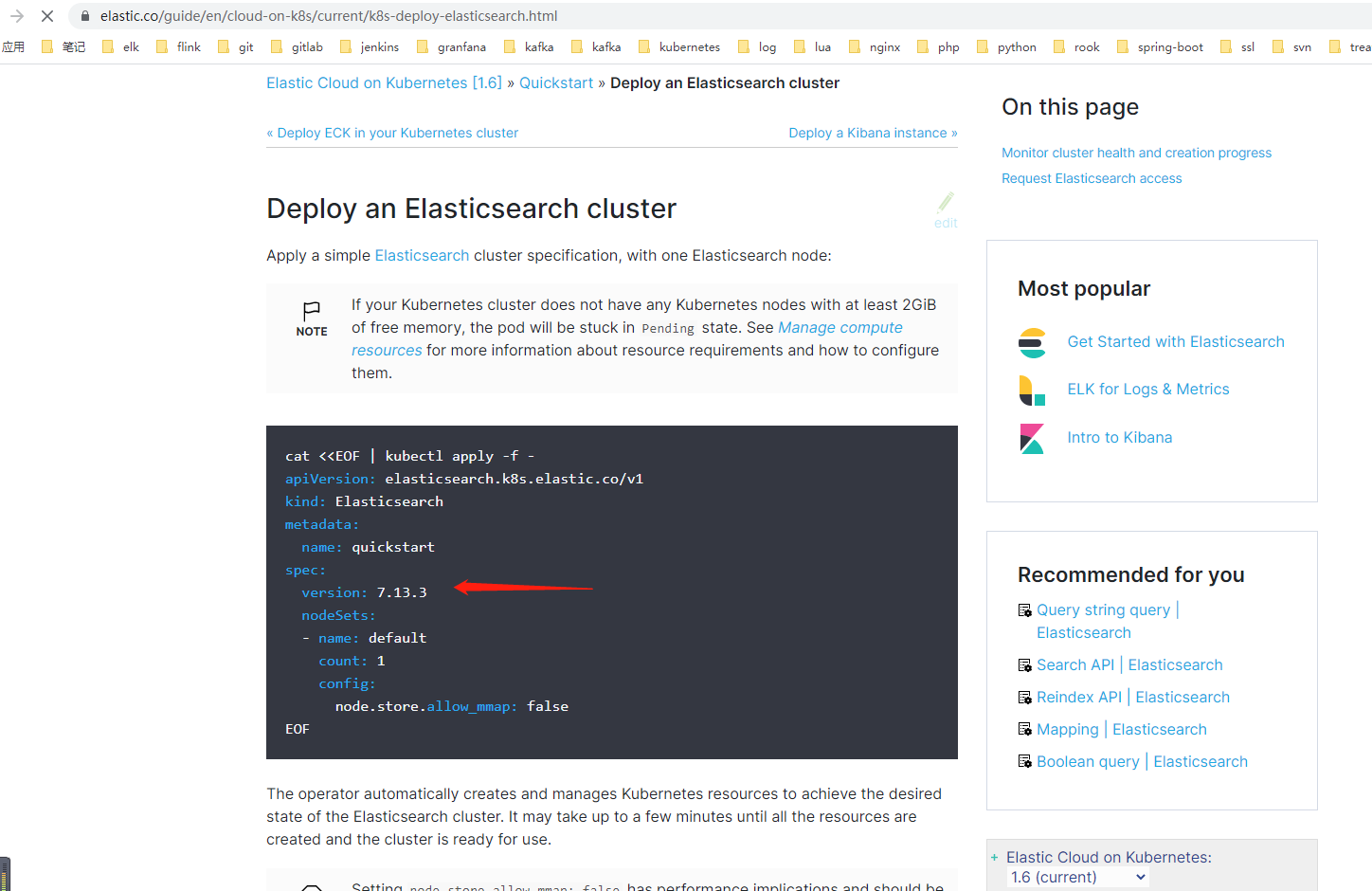
最新的版本 7.13.3了image标签 定制化一下:
FROM docker.elastic.co/elasticsearch/elasticsearch:7.13.3 ARG ACCESS_KEY=XXXXXXXXX ARG SECRET_KEY=XXXXXXX ARG ENDPOINT=cos.ap-shanghai.myqcloud.com ARG ES_VERSION=7.13.3 ARG PACKAGES="net-tools lsof" ENV allow_insecure_settings 'true' RUN rm -rf /etc/localtime && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime RUN echo 'Asia/Shanghai' > /etc/timezone RUN if [ -n "${PACKAGES}" ]; then yum install -y $PACKAGES && yum clean all && rm -rf /var/cache/yum; fi RUN \ /usr/share/elasticsearch/bin/elasticsearch-plugin install --batch repository-s3 && \ /usr/share/elasticsearch/bin/elasticsearch-keystore create && \ echo "XXXXXX" | /usr/share/elasticsearch/bin/elasticsearch-keystore add --stdin s3.client.default.access_key && \ echo "XXXXXX" | /usr/share/elasticsearch/bin/elasticsearch-keystore add --stdin s3.client.default.secret_key2. 打包镜像并上传到腾讯云镜像仓库,也可以是其他私有仓库
docker build -t ccr.ccs.tencentyun.com/xxxx/elasticsearch:7.13.3 . docker push ccr.ccs.tencentyun.com/xxxx/elasticsearch:7.13.3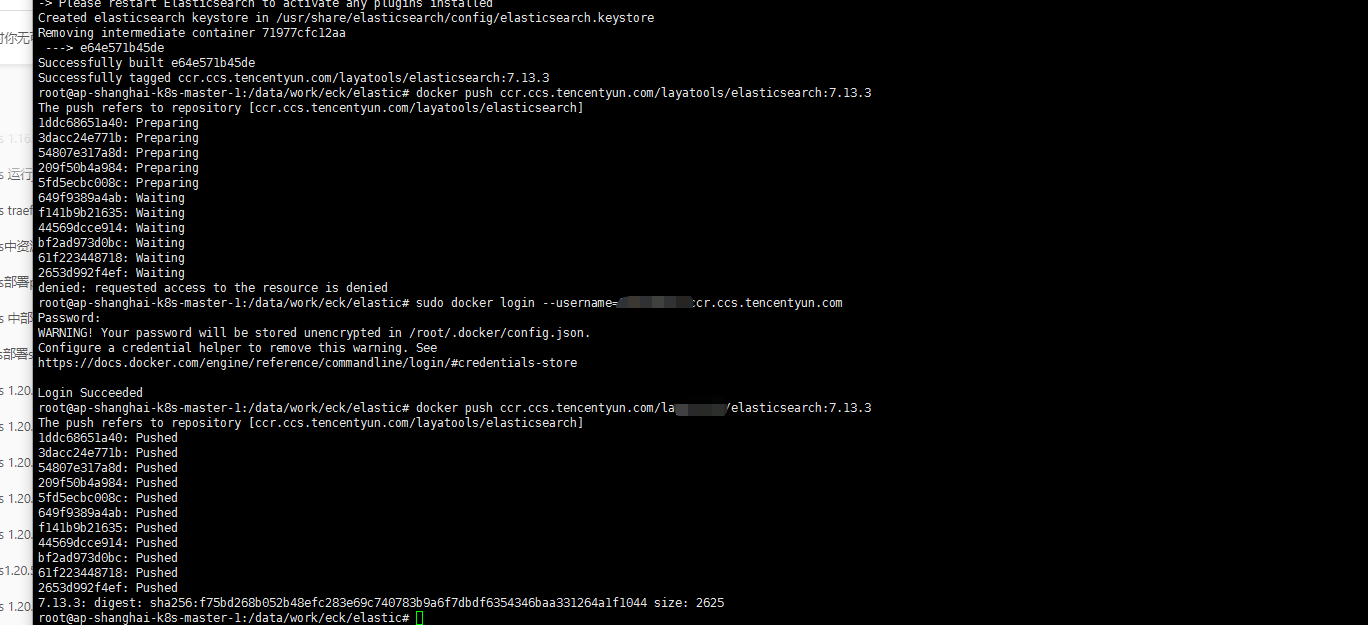
2. 创建elasticsearch部署yaml文件,部署elasticsearch集群
修改了自己打包 image tag ,使用了腾讯云cbs csi块存储。并定义了部署的namespace,创建了namespace logging.
1. 创建部署elasticsearch应用的命名空间
kubectl create ns logging先下发下仓库秘钥:
cat <<EOF > elastic.yaml apiVersion: elasticsearch.k8s.elastic.co/v1 kind: Elasticsearch metadata: name: elastic namespace: logging spec: version: 7.12.0 image: ccr.ccs.tencentyun.com/XXXX/elasticsearch:7.12.0 http: tls: selfSignedCertificate: disabled: true nodeSets: - name: laya count: 3 podTemplate: spec: containers: - name: elasticsearch env: - name: ES_JAVA_OPTS value: -Xms2g -Xmx2g resources: requests: memory: 4Gi cpu: 0.5 limits: memory: 4Gi cpu: 2 imagePullSecrets: - name: qcloudregistrykey config: node.master: true node.data: true node.ingest: true node.store.allow_mmap: false volumeClaimTemplates: - metadata: name: elasticsearch-data spec: accessModes: - ReadWriteOnce storageClassName: cbs-csi resources: requests: storage: 200Gi EOF注意:一定记得加上仓库秘钥如果是私有仓库
imagePullSecrets: - name: qcloudregistrykey2. 部署yaml文件并查看应用部署状态
kubectl apply -f elastic.yaml kubectl get elasticsearch -n logging kubectl get elasticsearch -n logging kubectl -n logging get pods --selector='elasticsearch.k8s.elastic.co/cluster-name=elastic'
3. 获取elasticsearch凭据
kubectl -n logging get secret elastic-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode; echo
4. 直接安装kibana了
修改了时区,和elasticsearch镜像一样都修改到了东八区,并将语言设置成了中文,关于selfSignedCertificate原因参照https://www.elastic.co/guide/en/cloud-on-k8s/1.4/k8s-kibana-http-configuration.html。
cat <<EOF > kibana.yaml apiVersion: kibana.k8s.elastic.co/v1 kind: Kibana metadata: name: elastic namespace: logging spec: version: 7.13.3 image: docker.elastic.co/kibana/kibana:7.13.3 count: 1 elasticsearchRef: name: elastic http: tls: selfSignedCertificate: disabled: true podTemplate: spec: containers: - name: kibana env: - name: I18N_LOCALE value: zh-CN resources: requests: memory: 1Gi limits: memory: 2Gi volumeMounts: - name: timezone-volume mountPath: /etc/localtime readOnly: true volumes: - name: timezone-volume hostPath: path: /usr/share/zoneinfo/Asia/Shanghai EOF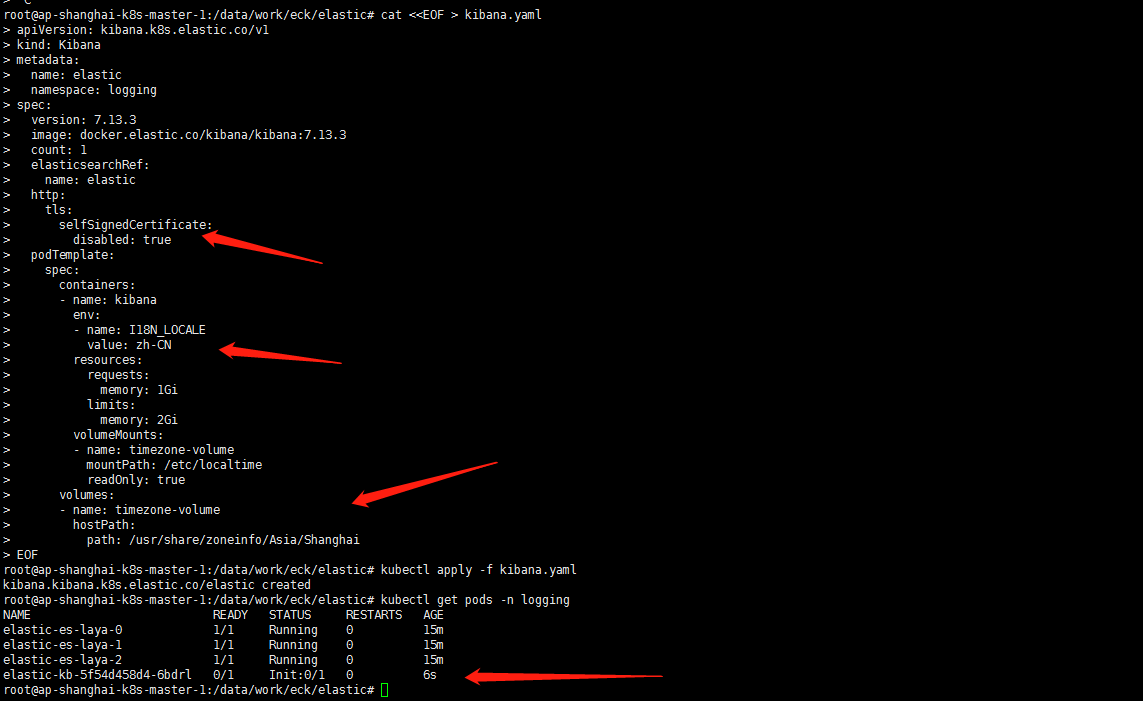
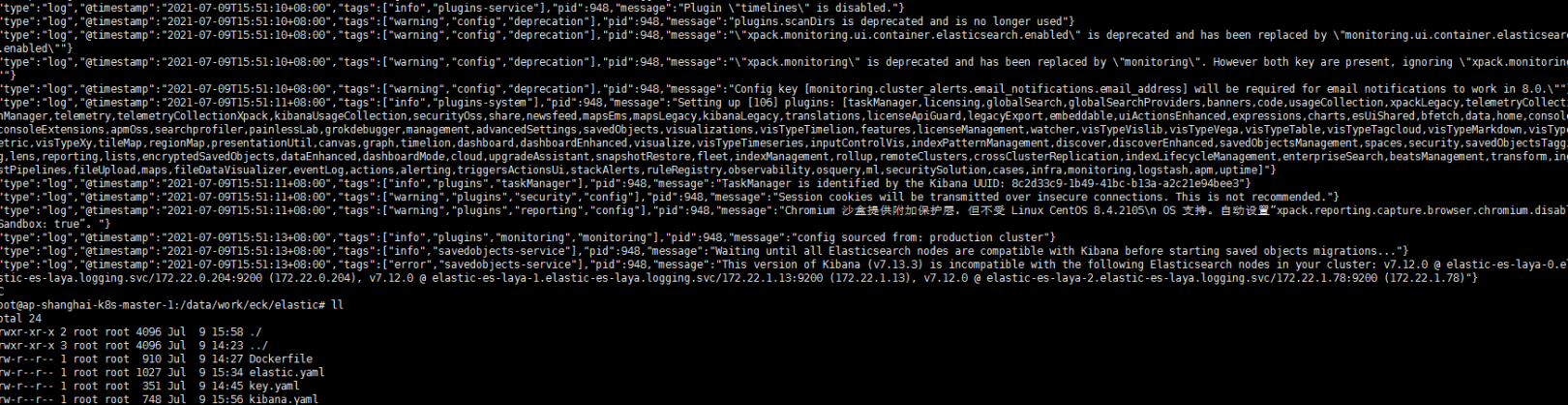
注意: 嗯 kibana一直没有起来 发现我打elasticsearch镜像的时候忘了改elasticsearch的基础镜像,还是用了7.12好吧 修改一下。一定强调一下版本的一致性(镜像哪里我修改了,怕小伙伴跟我重新做一次,这里就强调一下)
重新部署更是刺激 看tke后台有重新部署选项:
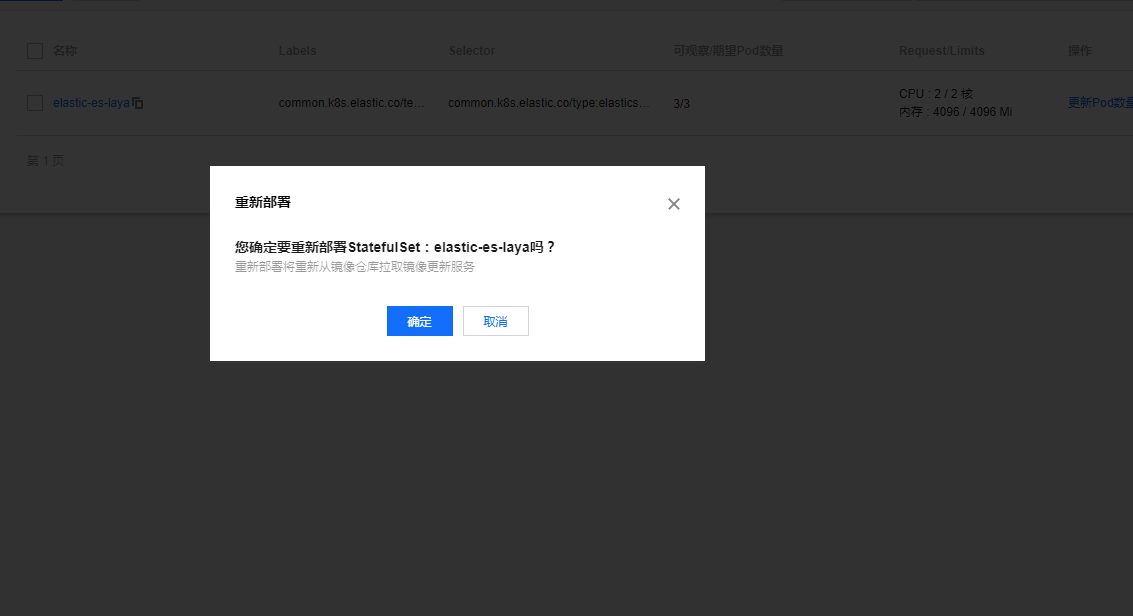
但是貌似没有生效还是老老实实的吧
imagePullPolicy: Always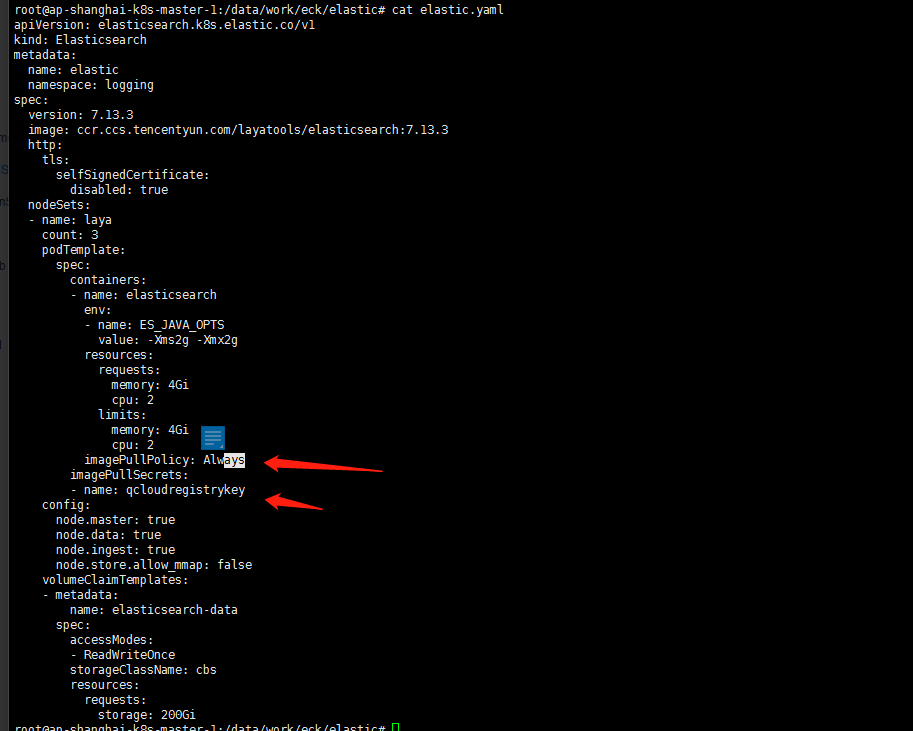
5. 对外映射kibana 服务
cat <<EOF> kibana-ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: kibana-http namespace: logging annotations: kubernetes.io/ingress.class: traefik traefik.ingress.kubernetes.io/router.entrypoints: web spec: rules: - host: kibana.layabox.com http: paths: - pathType: Prefix path: / backend: service: name: elastic-kb-http port: number: 5601 EOF
-
2021-07-15-Kubernets traefik代理ws wss应用
背景:
团队要发布一组应用,springboot开发的ws应用。然后需要对外。支持ws wss协议。jenkins写完pipeline发布任务。记得过去没有上容器的时候都是用的腾讯云的cls 挂证书映射cvm端口。我现在的网络环境是这样的:Kubernetes 1.20.5 安装traefik在腾讯云下的实践(当然了本次的环境是跑在tke1.20.6上面的,都是按照上面实例搭建的—除了我新建了一个namespace traefik,并将traefik应用都安装在了这个命名空间内!这样做的原因是tke的kebe-system下的pod太多了!我有强迫症)
部署与分析过程:
1. 关于我的应用:
应用的部署方式是statefulset,如下:
cat <<EOF > xxx-gateway.yaml apiVersion: apps/v1 kind: StatefulSet metadata: name: xxx-gateway spec: serviceName: xxx-gateway replicas: 1 selector: matchLabels: app: xxx-gateway template: metadata: labels: app: xxx-gateway spec: containers: - name: xxx-gateway image: ccr.ccs.tencentyun.com/xxx-master/xxx-gateway:202107151002 env: - name: SPRING_PROFILES_ACTIVE value: "official" - name: SPRING_APPLICATION_JSON valueFrom: configMapKeyRef: name: spring-config key: dev-config.json ports: - containerPort: 8443 resources: requests: memory: "512M" cpu: "500m" limits: memory: "512M" cpu: "500m" imagePullSecrets: - name: tencent --- apiVersion: v1 kind: Service metadata: name: xxx-gateway labels: app: xxx-gateway spec: ports: - port: 8443 selector: app: xxx-gateway clusterIP: None EOFkubectl apply -f xxx-gateway.yaml -n official偷个懒直接copy了一个其他应用的 ingress yaml修改了一下,如下:
cat <<EOF > gateway-0-ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: layaverse-gateway-0-http namespace: official annotations: kubernetes.io/ingress.class: traefik traefik.ingress.kubernetes.io/router.entrypoints: web spec: rules: - host: xxx-gateway-0.xxx.com http: paths: - pathType: Prefix path: / backend: service: name: xxx-gateway port: number: 8443 EOF部署ingress
kubectl apply -f gateway-0-ingress.yaml查看ingress部署状况
kubectl get ingress -n official
嗯 然后测试一下wss(wss我直接用443端口了。证书挂载slb层的–这是我理解的!具体的参照我traefik的配置),这里强调一下wscat这个工具。反正看了下我们的后端小伙伴测试ws应用都是用的在线的ws工具:
就这样的。然后正巧看到wscat就安装了一下:
sudo apt install npm sudo npm install -g wscat wscat -c wss://xxx-gateway-0.xxx.com:443/ws
嗯哼 基本上可以确认是应用对外成功了?
当然了以上只是我顺利的假想!
实际上是代理后连接后端的ws服务依然有各种问题(开始我怀疑是traefik的问题),还是连不上!我粗暴的把xxx-gateway 的暴露方式修改为NodePort 然后挂载到了slb层(在scl直接添加了ssl证书),测试了一下是可以的就直接用了。先让应用跑起来,然后再研究一下怎么处理。
2. 关于ws和http:
先不去管那么多,先整明白实现我的traefik如何实现代理ws呢?

图中内容摘自:https://blog.csdn.net/fmm_sunshine/article/details/77918477
3. 排查下是谁的锅
1. 搭建一个简单的ws应用
后端的代码既然搞不懂,那我就找一个简单的ws的服务然后用traefik代理测试一下!
dockerhub搜得一个nodejs 的websocket镜像:https://hub.docker.com/r/ksdn117/web-socket-test
部署一下:
cat <<EOF > web-socket-test.yaml apiVersion: apps/v1 kind: StatefulSet metadata: name: web-socket-test spec: serviceName: web-socket-test replicas: 1 selector: matchLabels: app: web-socket-test template: metadata: labels: app: web-socket-test spec: containers: - name: web-socket-test image: ksdn117/web-socket-test ports: - containerPort: 8010 name: web - containerPort: 8443 name: ssl resources: requests: memory: "512M" cpu: "500m" limits: memory: "512M" cpu: "500m" --- apiVersion: v1 kind: Service metadata: name: web-socket-test labels: app: web-socket-test spec: type: NodePort ports: - port: 8010 targetPort: 8010 protocol: TCP name: web - port: 8443 targetPort: 8443 name: ssl protocol: TCP selector: app: web-socket-test EOF注: 我这里的配置文件加了type:NodePort
kubectl apply -f web-socket-test.yaml kubectl get pods kubectl get svc
2.内部wscat测试ws服务是否联通
先内部连接container pod ip测试一下服务:

wscat --connect ws://172.22.0.230:8010kubectl logs -f web-socket-test-0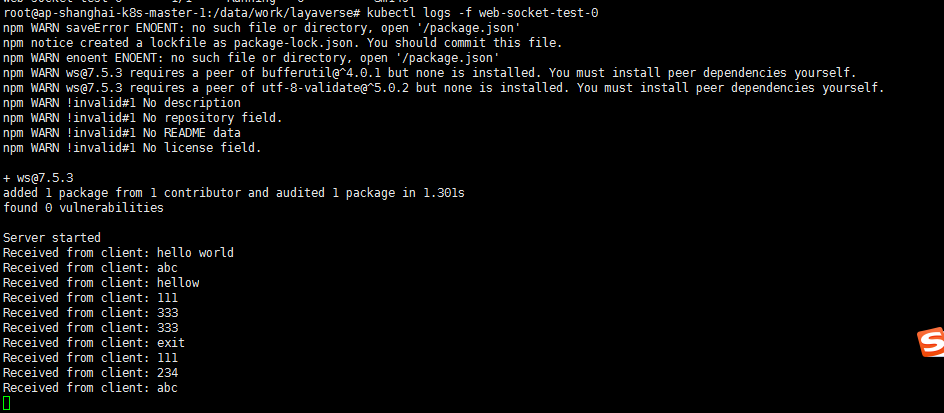
3.traefik对外代理ws应用并测试
traefik正常的对外暴露服务可以用ingress的方式还有ingressroute我都去尝试一下:
1. ingressroute方式
cat <<EOF > web-socket-ingressroute.yaml apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: web-socket-test-http namespaces: default spec: entryPoints: - web routes: - match: Host(`web-socket-test.xxx.com`) kind: Rule services: - name: web-socket-test port: 8010 EOF kubectl apply -f web-socket-ingressroute.yaml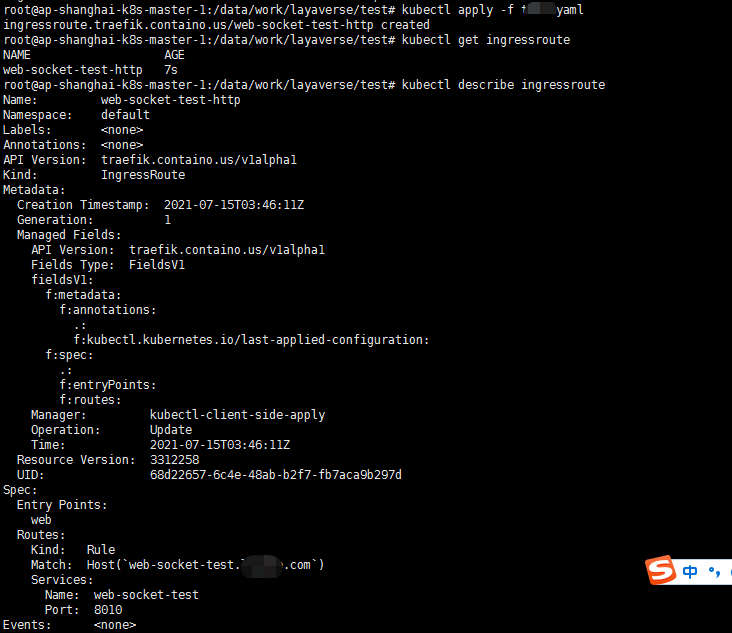
wscat连接测试一下:

这样测来是没有问题的?
删除ingress
kubectl delete -f web-socket-ingressroute.yaml2. ingress方式
整一下ingress的方式:
cat <<EOF > web-socket-ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: web-socket-test namespace: default annotations: kubernetes.io/ingress.class: traefik traefik.ingress.kubernetes.io/router.entrypoints: web spec: rules: - host: web-socket-test.layame.com http: paths: - pathType: Prefix path: / backend: service: name: web-socket-test port: number: 8010 EOF kubectl apply -f web-socket-ingress.yaml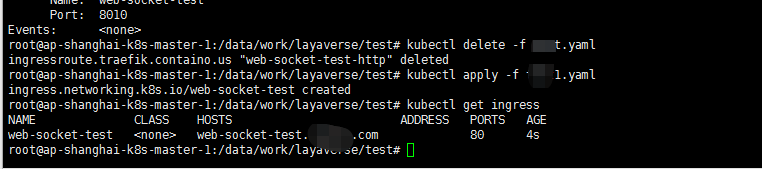
wscat --connect wss://web-socket-test.xxx.com:443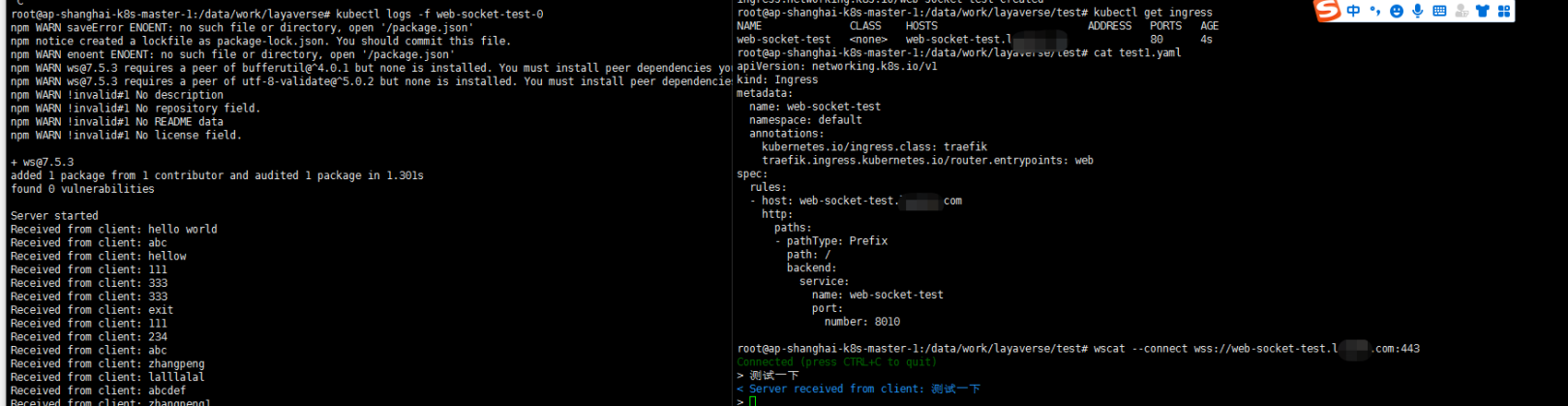
甩锅基本完成起码不是我的基础设施应的问题…..让后端小伙伴测试一下看下是哪里有问题了。从我代理层来说是没有问题的!
关于其他:
当然了看一些博客还有要加passHostHeader: true的配置的
1. ingressroute:
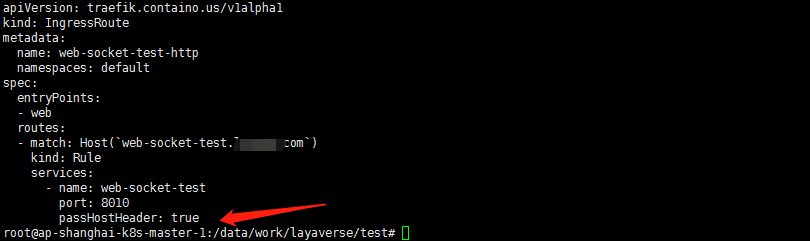
2. ingress
ingress:traefik.ingress.kubernetes.io/service.passhostheader: "true"
如果有问题 可以尝试一下上面的方式!
-
2021-07-09-TKE1.20.6初探
背景:
前几天刚刚测试了一把tke1.18.4:腾讯云TKE1.18初体验 ,今天一看后台有了1.20.6的版本了。满怀欣喜的想升级一下tke集群的。但是仔细一看不支持升级。问了一下tke的小伙伴,要下个月才能支持版本升级。这点让人体验狠不好。新版本发出了。老版本缺不能升级?让老用户感觉到很是被抛弃的感觉。不知道其他用户是怎么感觉的,反正我是有这样感觉的。闲话少说,搭建一个新的tke1.20.6的版本体验下有那些不同吧!
创建tke1.20.6集群
1. 创建集群
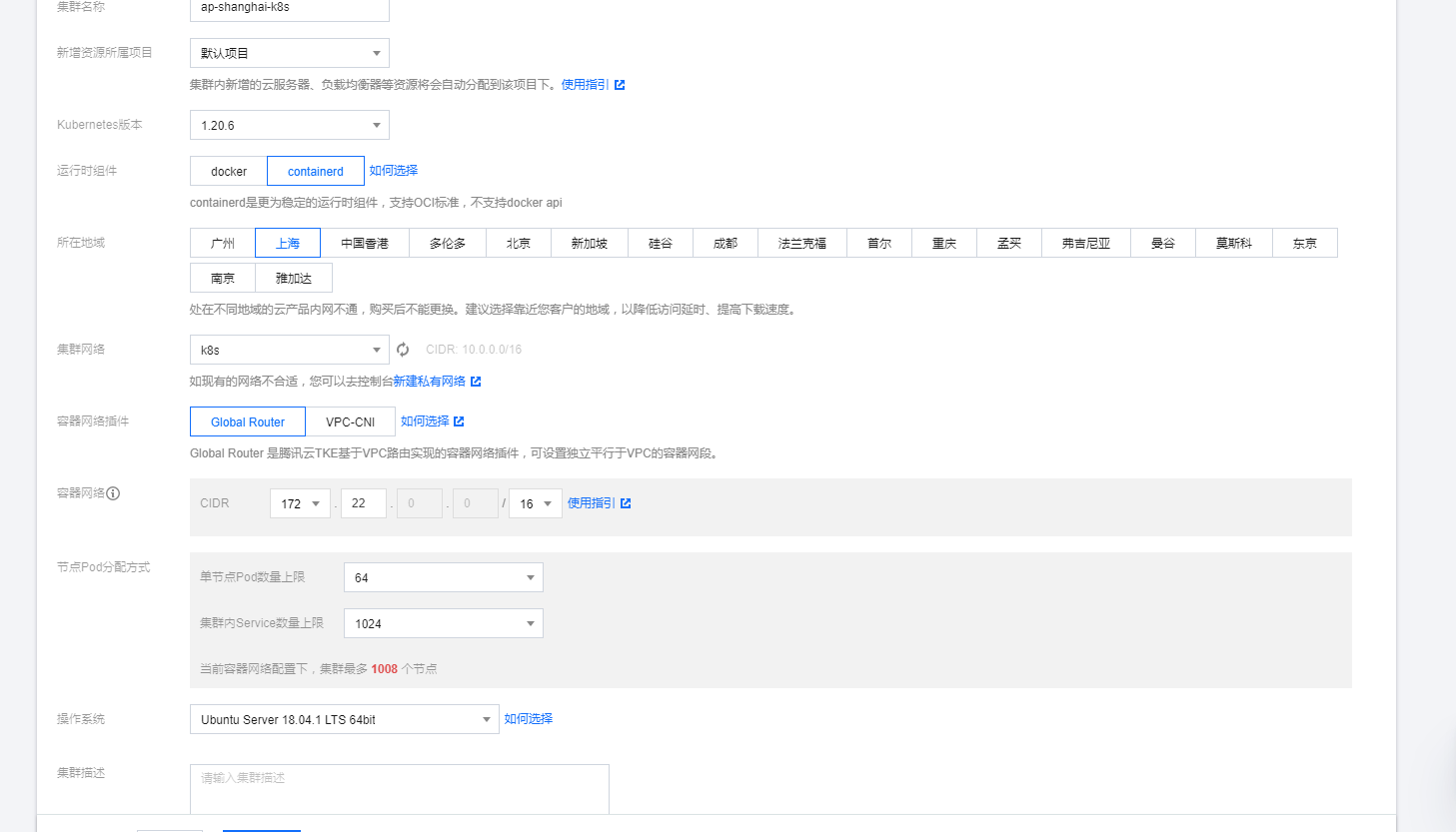
依旧同1.18.4一样,当然了还是特别强调下容器的网络CIDR一定不要与其他集群或者vpc网络重合,当然了 vpc-cni有时间我也想体验一下
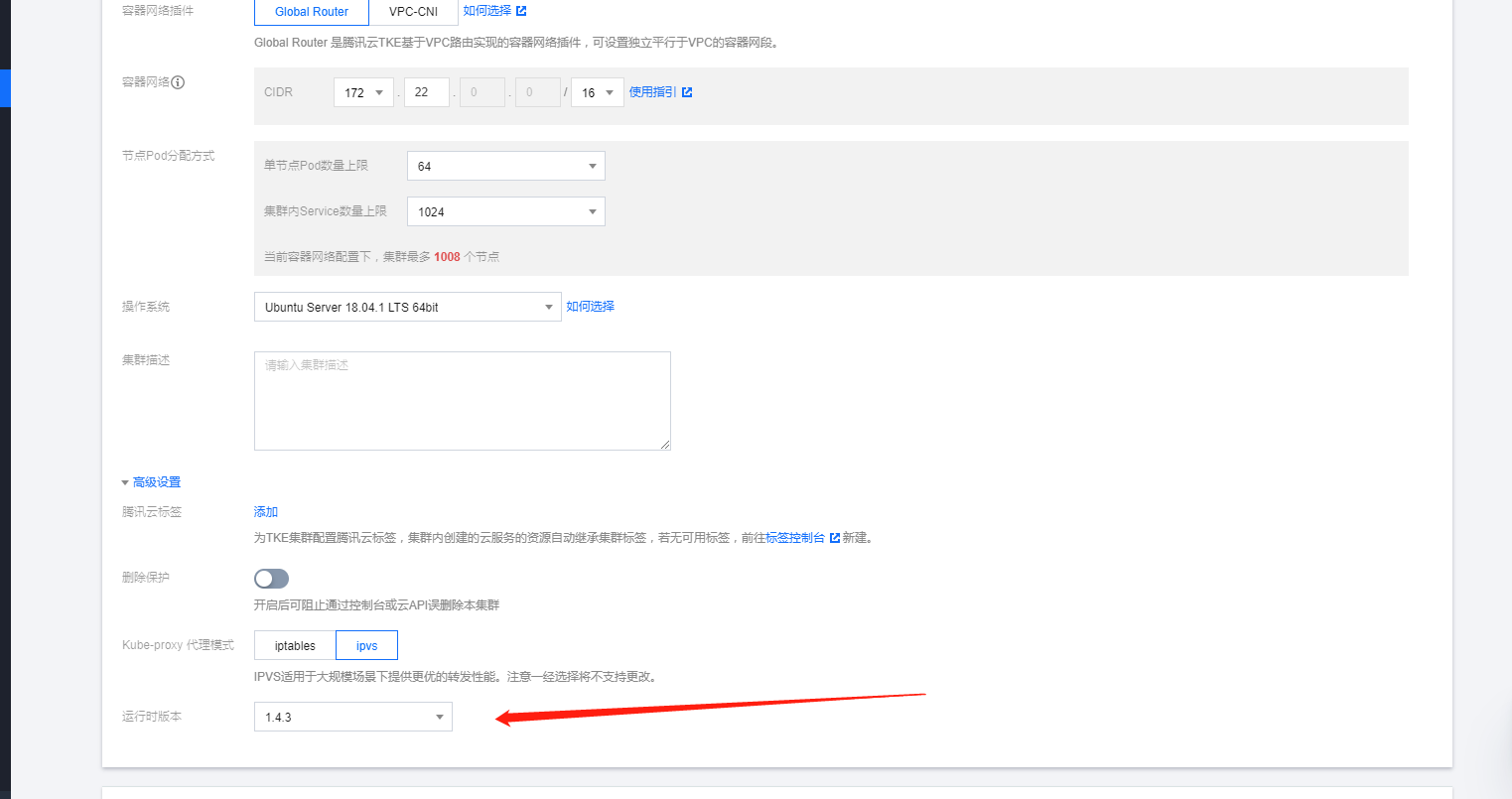
系统依然选择了ubuntu1.18.4,高级设置kube-proxy选择了ipvs的代理方式
2. 节点命名个性化
下一步选择master 节点我选择了现有的三台服务器,work节点没有先加入选择了暂时不添加
服务器的配置发现了一个新鲜的不一样,不知道是过去就有没有注意还是新添加的了,竟然可以自定义主机名了?过去的tke集群都是以ip方式显示的看着很不喜欢

参照文档:https://cloud.tencent.com/document/product/457/32189,主机名竟然可以自定义了?很是开心

我将主机名自定义为ap-shanghai-k8s-master-{R:01}(其实我想要个0开头的 01 02 03这样的)
3. 安全组的报错
组件配置我就没有选择貌似就只有默认的cbs组件了,然后点完成的时候就出现了下面的报错:
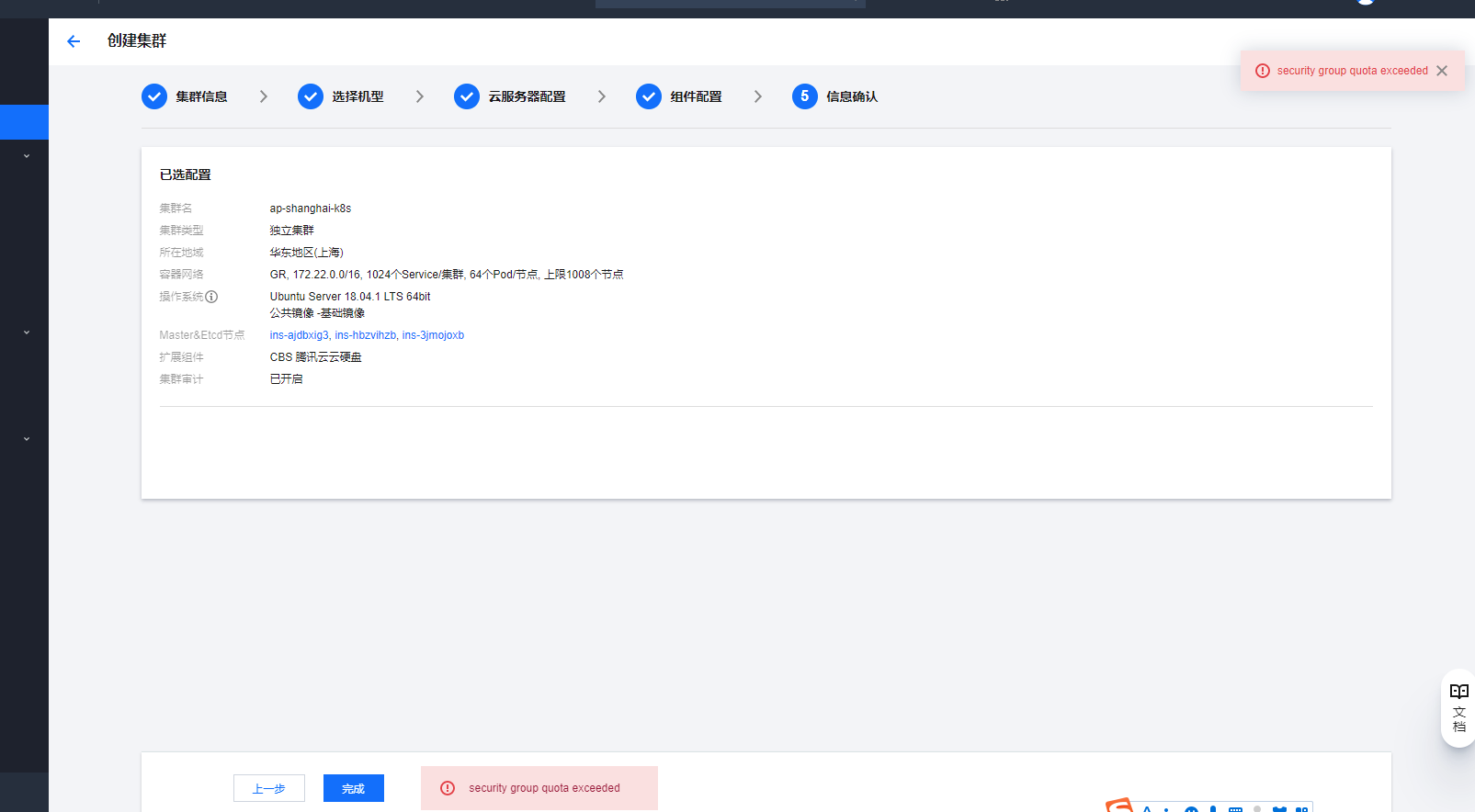
security group quota exceeded 怀疑是安全组的问题,我就把3台master &etcd的节点加入到了tke1.18的集群(其实这样也不完整,仔细看了一眼那个安全组是172.19.0.0/16的放行,我这个cidr应该是172.22.0.0/16)。依然不行….为了下tke的小伙伴:嗯 我的安全组满了,看了一眼我的安全组规则有70条,貌似满了?不管了先删掉了几条无用的安全组。重新点完成 OK了。发现原来tke是自己会创建安全组的!
等待master初始化完成如下:
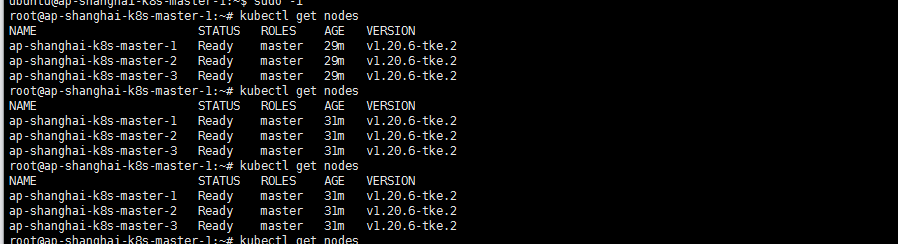
看着舒服多了总算不是再以ip为命名规则了!。但是我还是想加01 02的命名规则哎,怎可以搞一下呢?
4. 添加work节点
再加入三台work工作节点:
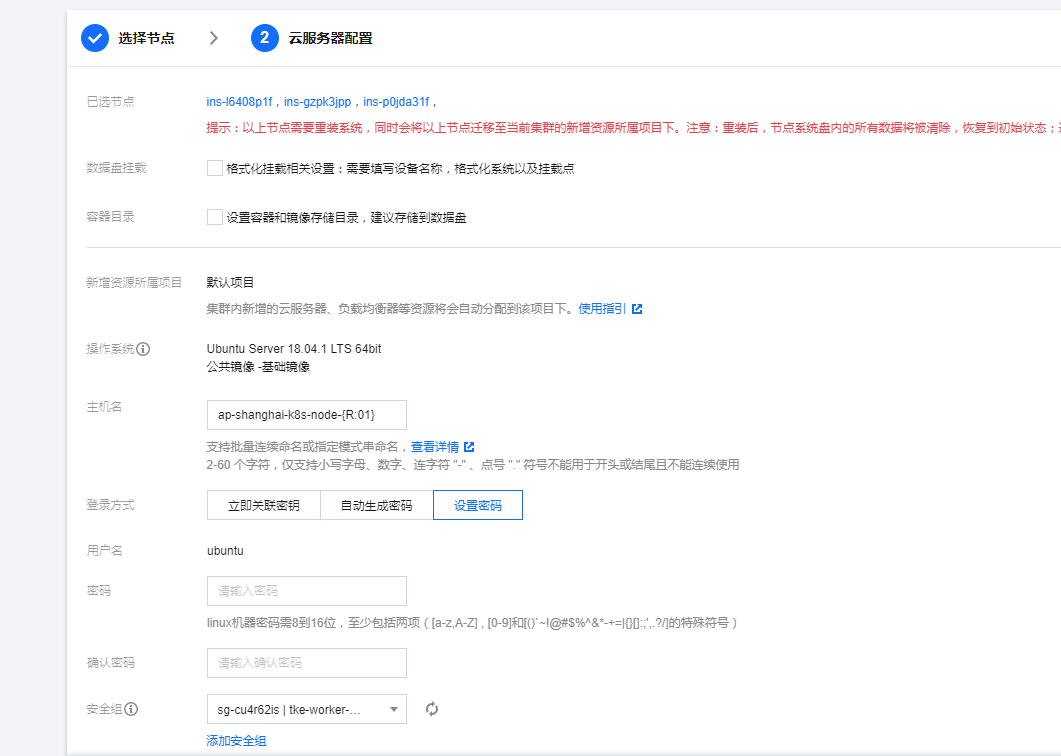
也修改了一下主机名自定义了一下:ap-shanghai-k8s-node-{R:01}.等待完成
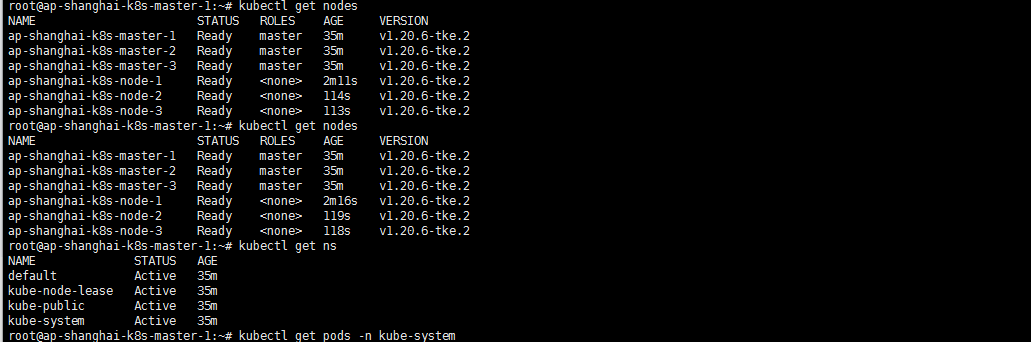
舒服多了 master的总算可以在前了看着舒服多了
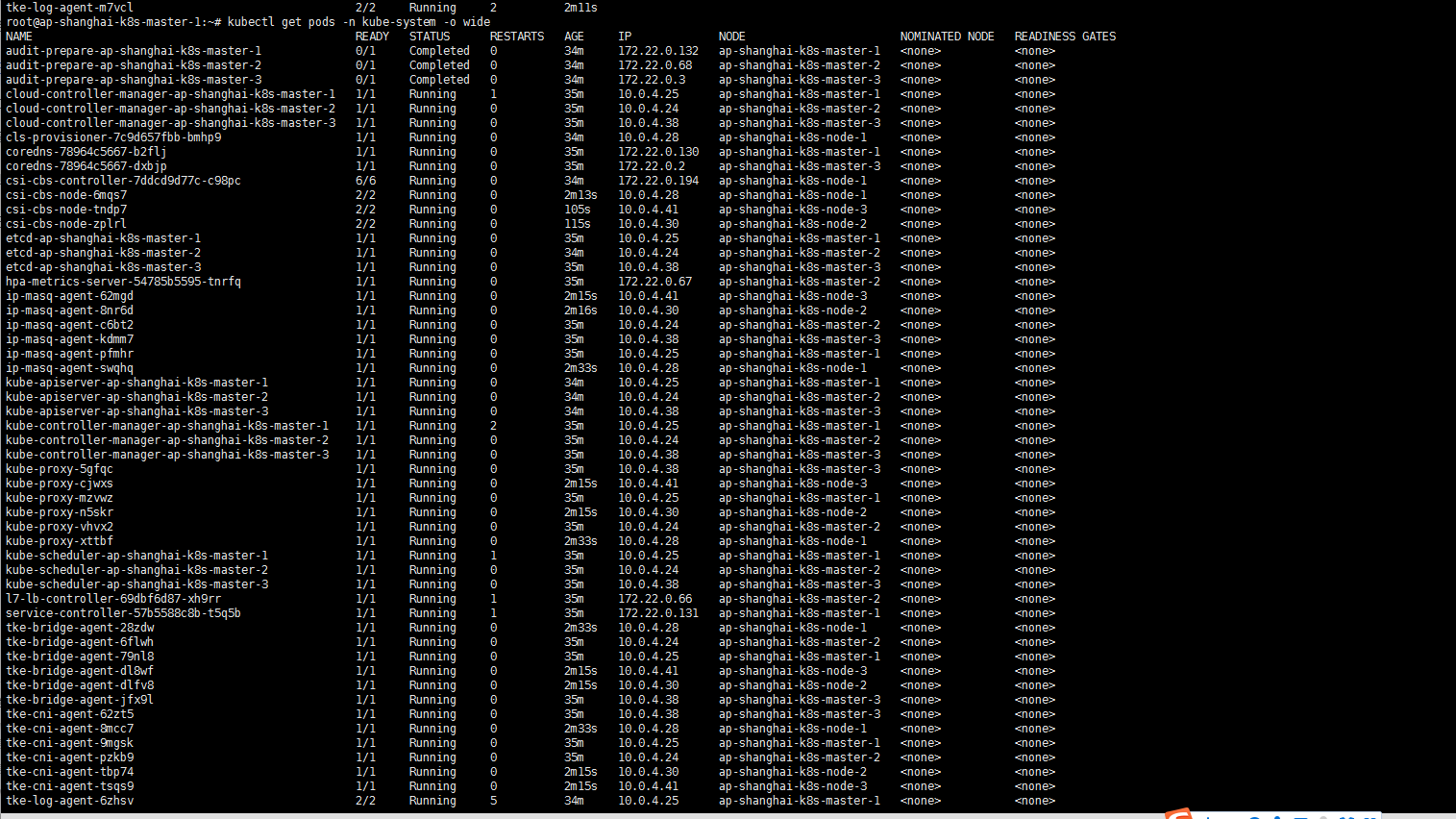
看了一眼这初始服务可真多啊,有点烦……
5. 安装几个插件:
这两个貌似是2选一的,关键插件安装都只能同时安装一个
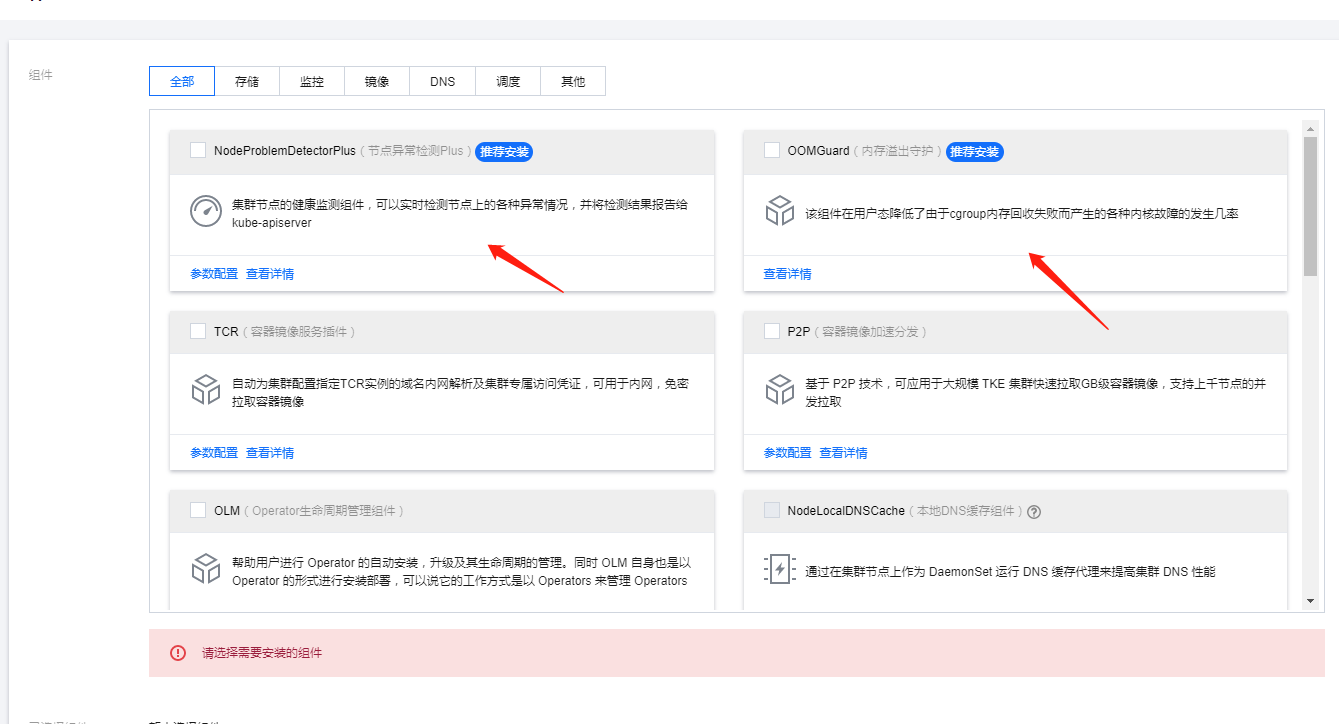
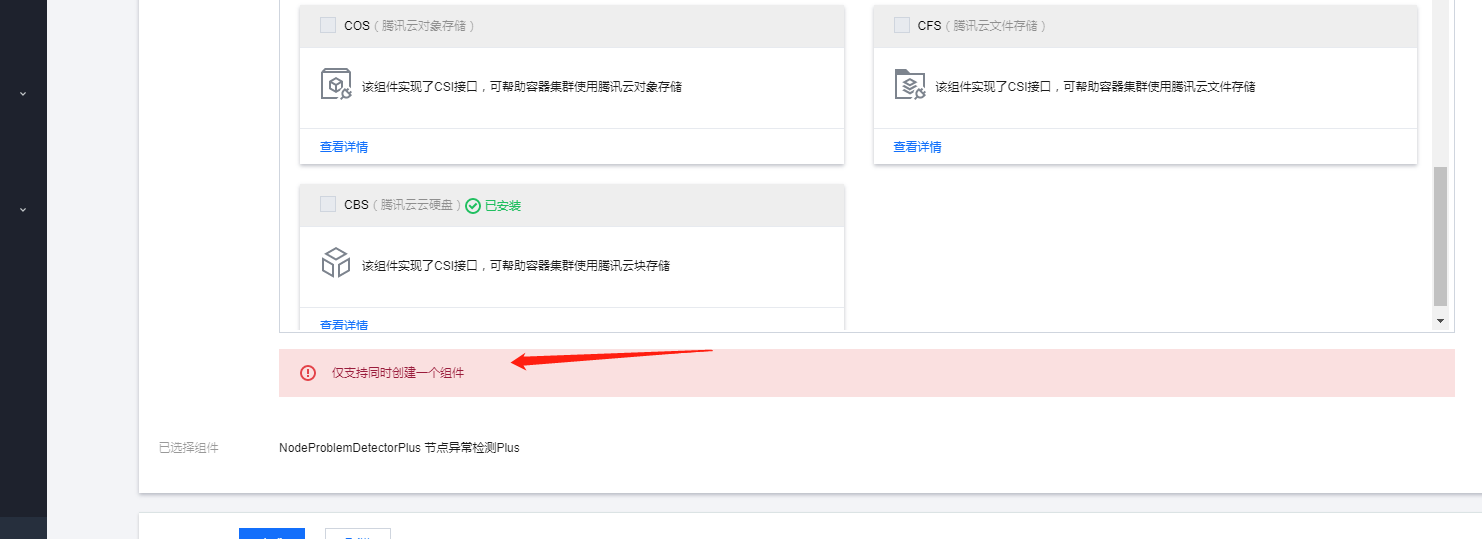
最终安装了如下:
谈一下体验感受:
- 节点名称可以自定义了对tke的用户体验来说是一个进步。当然了还有我想命名方式为01 02 03的这种命名方式可不可以支持呢?我就想占位。
- tke与腾讯云其他产品间的结合还是不流畅,如我碰到的安全组问题。可不可以在用户创建集群过程中让用户看到安全组的配置?让我自动或者选择自动生成?让用户知道有那么一个步骤呢?
- 插件的安装也很诡异:为什么我不能同时进行多个任务?我想同时安装多个插件。每次点一个确认等待。来回切页面很是麻烦。
- 当然了最让老用户失望的是你开通了1.20.6版本。为什么不同时上线1.18.4版本的升级呢?这对老用户是一种冷落,对于我来说这是最不满意的地方。希望能将更新版本和发布新版本同时上线。用户可以选择不更新,但是可以更新是对老用户的重视。
- 当然了 还有我从1.18开始就关心的:独立部署集群master节点的添加删除功能。
- 准备迁移一下elastic on kubernetes集群跑一下看看。当然了还有其他服务。(但是这个版本升级滞后于新版本发布,还有master节点增加删除不让我自己能控制,让我还是不想迁移)
-
2021-07-08-关于centos8+kubeadm1.20.5+cilium+hubble的安装过程中cilium的配置问题--特别强调
背景:
参见前文:centos8+kubeadm1.20.5+cilium+hubble环境搭建,并升级到了1.21版本(Kubernetes 1.20.5 upgrade 1.21.0)。今天无聊查看一下集群呢突然发现一个问题:
[root@sh-master-01 ~]# kubectl get pods -n default -o wide NAME READY STATUS RESTARTS AGE IP NODE csi-app 1/1 Running 11 106d 10.0.4.204 sh-work-01 nginx 1/1 Running 0 13d 10.0.4.60 sh-work-01 nginx-1-kkfvd 1/1 Running 0 13d 10.0.5.223 sh-work-02 nginx-1-klgpx 1/1 Running 0 13d 10.0.4.163 sh-work-01 nginx-1-s5mzp 1/1 Running 0 13d 10.0.3.208 sh-work-03 nginx-2-8cb2j 1/1 Running 0 13d 10.0.3.218 sh-work-03 nginx-2-l527j 1/1 Running 0 13d 10.0.5.245 sh-work-02 nginx-2-qnsrq 1/1 Running 0 13d 10.0.4.77 sh-work-01 php-apache-5b95f8f674-clzn5 1/1 Running 2 99d 10.0.3.64 sh-work-03 pod-flag 1/1 Running 316 13d 10.0.5.252 sh-work-02 pod-nodeaffinity 1/1 Running 0 13d 10.0.4.118 sh-work-01 pod-prefer 1/1 Running 0 13d 10.0.5.181 sh-work-02 pod-prefer1 1/1 Running 0 13d 10.0.3.54 sh-work-03 with-node-affinity 0/1 ImagePullBackOff 0 13d 10.0.4.126 sh-work-01 with-pod-affinity 0/1 ImagePullBackOff 0 13d 10.0.5.30 sh-work-02 with-pod-antiaffinity 1/1 Running 0 13d 10.0.4.159 sh-work-01主要是看ip一栏,这.,我记得我的 serviceSubnet: 172.254.0.0/16 , podSubnet: 172.3.0.0/16啊 是不是哪里搞错了了呢?
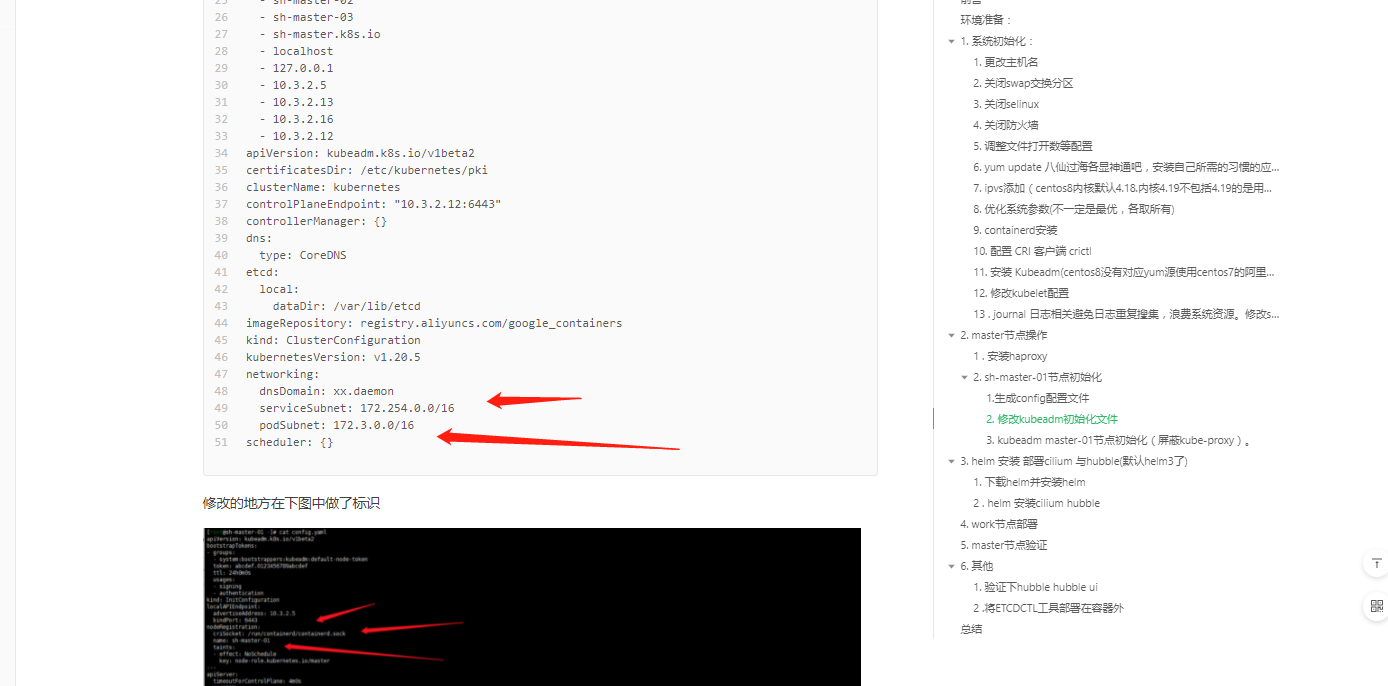
再看一眼service的网络状况:
[root@sh-master-01 ~]# kubectl get svc -n default -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR kubernetes ClusterIP 172.254.0.1 <none> 443/TCP 106d <none> php-apache ClusterIP 172.254.13.205 <none> 80/TCP 99d run=php-apache这个ip段是对的呢!怎么会事情呢?
复盘解决问题
1. 确认问题
cilium是oprator的方式安装的,找到oprator的pod:
kubectl get pods -n kube-system -o wide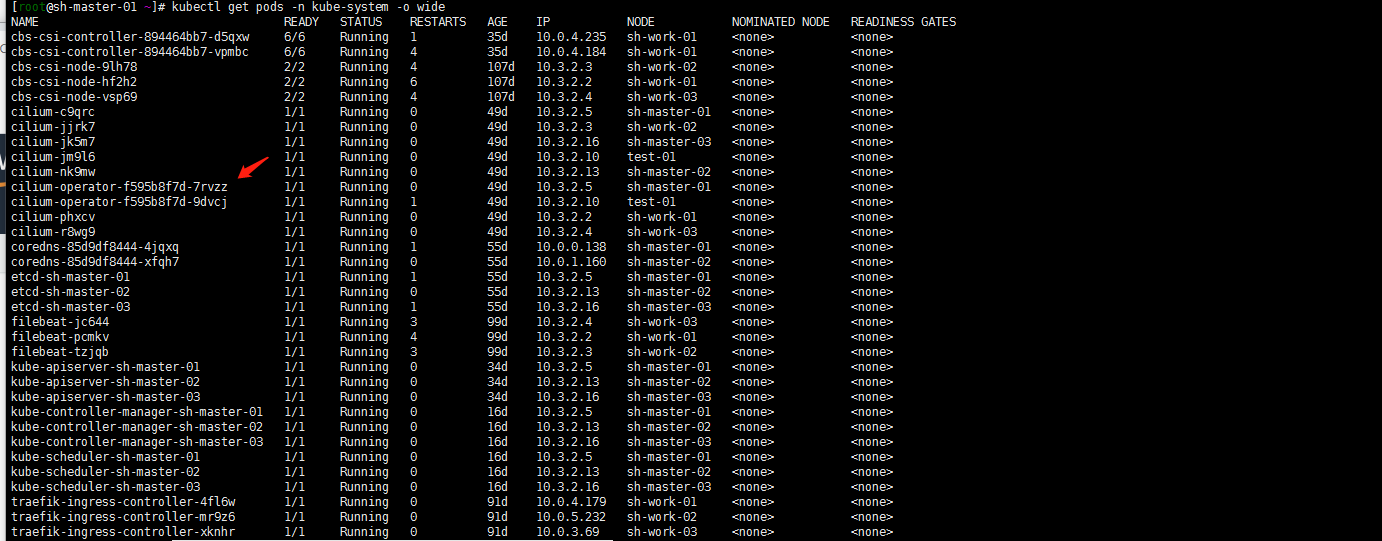
查看日志输出:
kubectl logs -f cilium-operator-f595b8f7d-7rvzz -n kube-system貌似找到了 下面箭头指向的这一段ipv4CIDRs是 10.0.0.0/8!
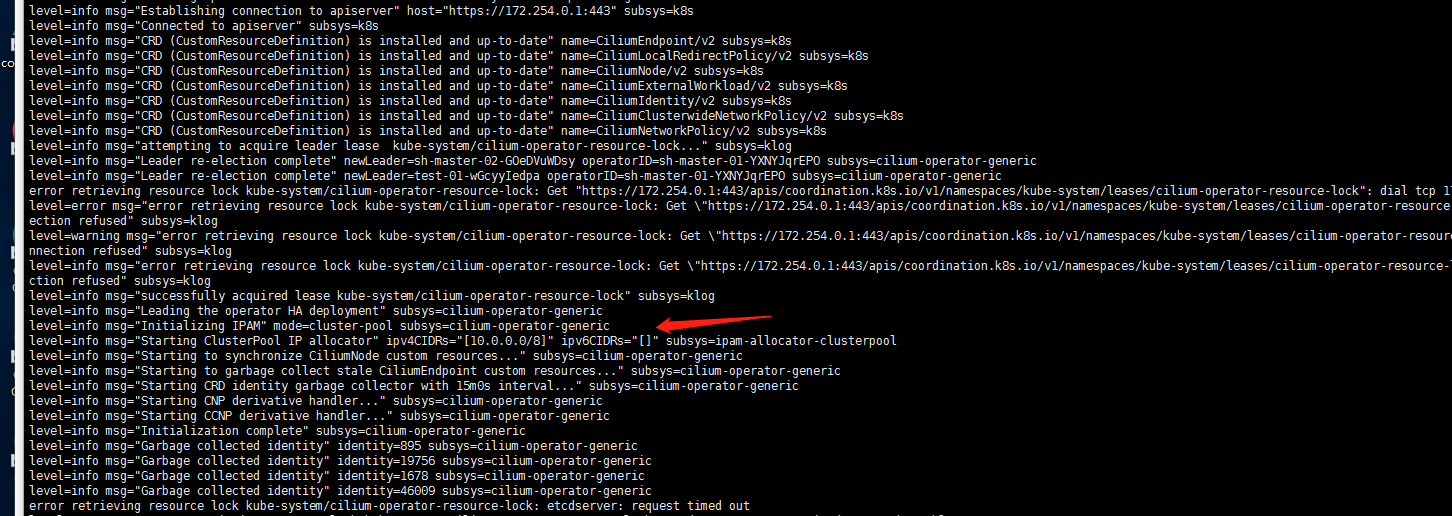
2. 阅读官方文档
搭建集群我是参考的肥宅爽文的博客:02-02.kubeadm + Cilium 搭建kubernetes集群。博客上面写的比较完整的cilium搭建集群的貌似我俩写的了:centos8+kubeadm1.20.5+cilium+hubble环境搭建。初步怀疑就是helm安装cilium的时候配置网络组件并没有走config.yaml中的配置。仔细看了一眼官方github仓库文件配置项:https://github.com/cilium/cilium/tree/v1.10.2/install/kubernetes/cilium。
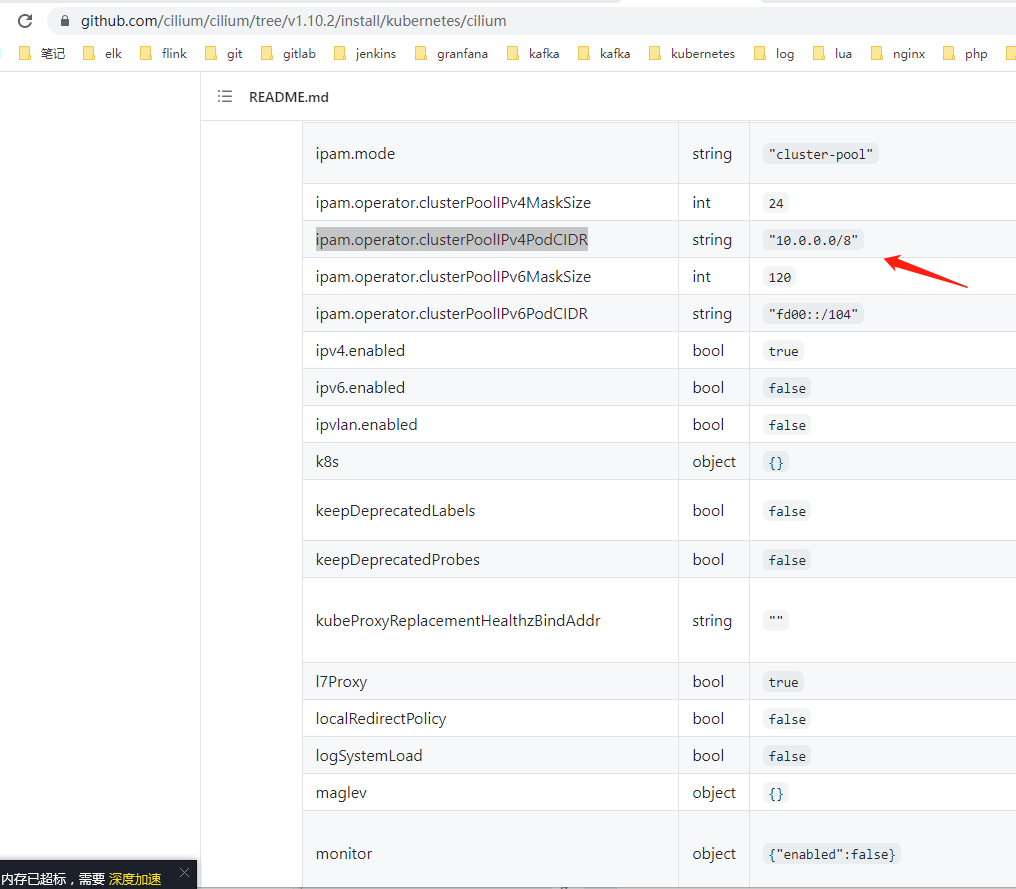
注:我的版本是1.9.7,正常的找自己对应版本的配置文件看呢。差距不大我就没有去切换分支看了…
对照官方文档:在helm安装的时候没有指定ipam.operator.clusterPoolIPv4PodCIDR参数!网上的很多文章也都是草草来的,并没有详细的对ipv4的cidr进行指定那pod网络都是默认的10.0.0.0/8的cidr!我的cvm vpc网络默认是10.0.0.0/8的大网络,这样下来ip地址应该是会有冲突的!
3.找一个正确的参考
谷歌搜索文档搜到亚马逊的一篇blog:https://aws.amazon.com/cn/blogs/containers/a-multi-cluster-shared-services-architecture-with-amazon-eks-using-cilium-clustermesh/
亚马逊的blog还是很好的。安装的过程很是详细可以参考一下:
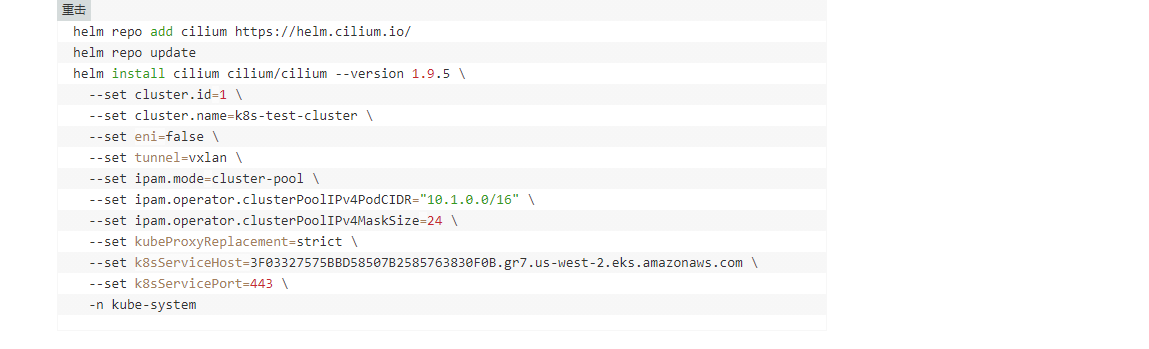
至于我的集群只能upgrade了…
helm upgrade cilium cilium/cilium --version 1.9.7 --namespace=kube-system --set ipam.operator.clusterPoolIPv4PodCIDR="172.3.0.0/16"目测应该是这样的特别强调一下,抄别人安装的时候还是要去看一下官方文档的详细参数定义!国内能搜到的这些cilium的 都大部分没有写podCIDR的配置的吧?参考别人博客的同时一定记得再仔细去看下官方文档参数!
-
2021-07-02-腾讯云TKE1.18初体验
背景:
作为腾讯云的老用户我大概是2018年开始使用腾讯云的tke服务的。当时是1.10,现在线上还有一个tke1.12的集群,鉴于早期更新迭代较慢。我选择了在腾讯云上面kubeadm的方式自建kubernetes集群的方式。参见:https://duiniwukenaihe.github.io/2019/09/02/k8s-install/。后面持续升级,现在是1.17.17版本。最近看腾讯云云原生公众号更新的内容都比较多,并且tke的版本到了1.18我选择了尝试一下tke的服务!
注:昨天开通搭建没有截图….今天就将就一下模拟演示吧!
tke开通体验:
注:我之前开通过tke服务注册账号,服务授权就忽略了!,关于这部分的内容可以参照官方文档:https://cloud.tencent.com/document/product/457/54231
1. 打开管理控制台:
https://console.cloud.tencent.com/tke2/cluster?rid=4
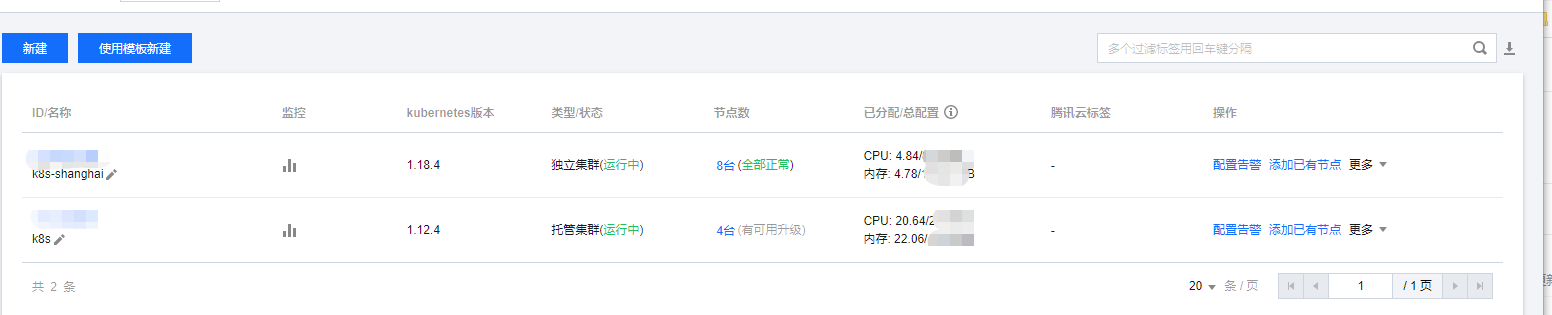
名为k8s的集群为老的集群。k8s-shanghai为昨天新建的tke1.18的新的集群。由于集群已经创建了。现在就只是截图重复一遍步骤,不去做新集群的开通了!
2. 新建集群
设置集群的名称,新增资源所属的项目,我这里就都是默认了。选择kubernetes的版本。当前最新版本是1.18.4。至于runtime运行时组件。我是直接用了containerd了。当然了docker也还算可以的在1.18的版本。地域我的服务器资源都部署在上海。然后选择集群的网络环境。容器网络的组件使用了默认的Global Router,VPC-CNI对于我来说还没有这样的需求
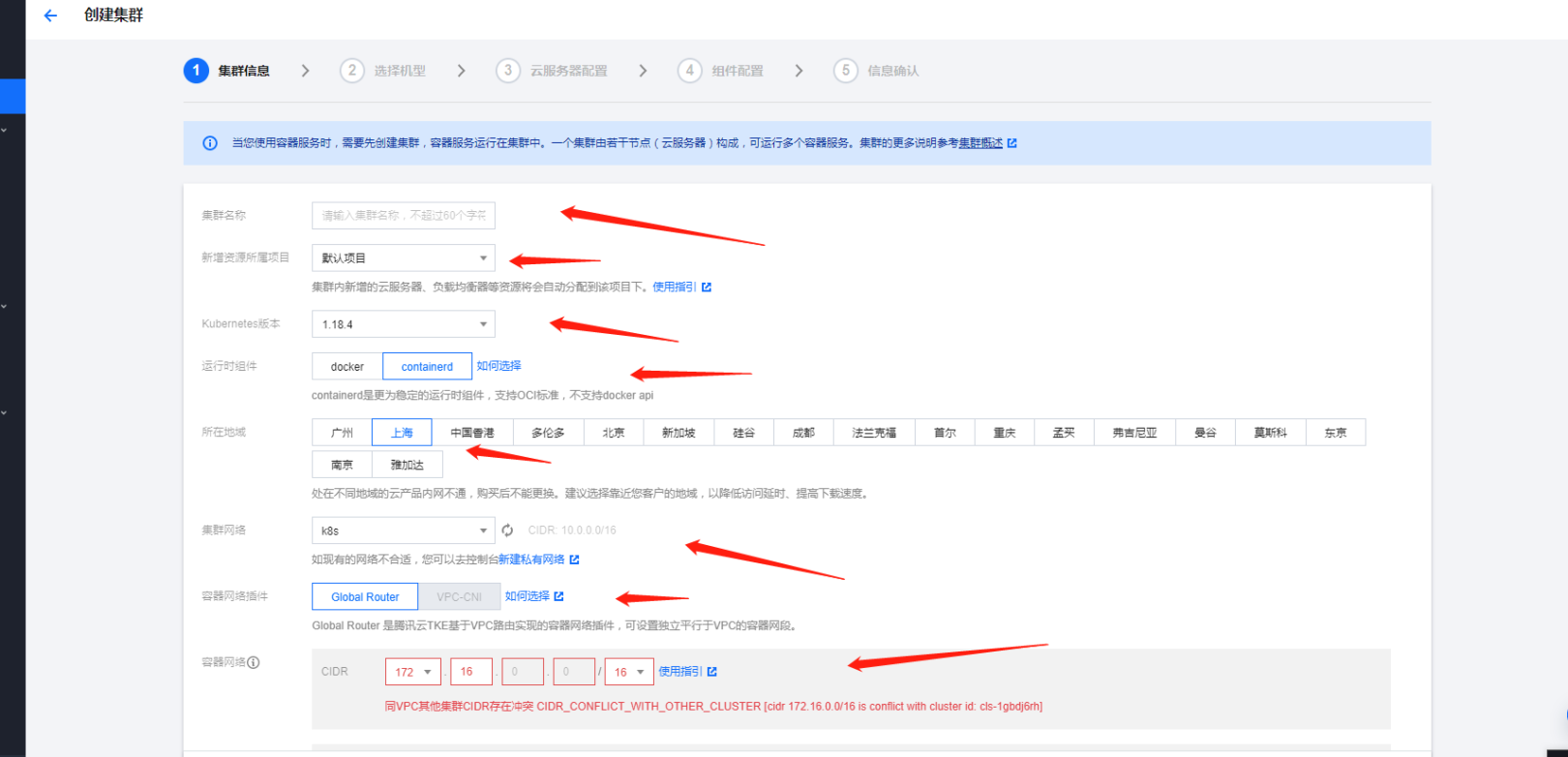
3. 特别强调说一下容器的网络:
我的cvm网络CIDR是10.0.0.0/16的网络。容器的网络是要跟集群网络分开的正常来说选择192.168或者 172.X.0.0.0/16。当然了也可以可变长子网掩码。自己玩的不是太好还是按照提示老老实实的了默认的提示X是
16,18,….,31。16用过了,18貌似也用了 我就选择了19。故容器网络的CIDR是172.19.0.0/16.节点的pod分配方式也可以满足我的要求!
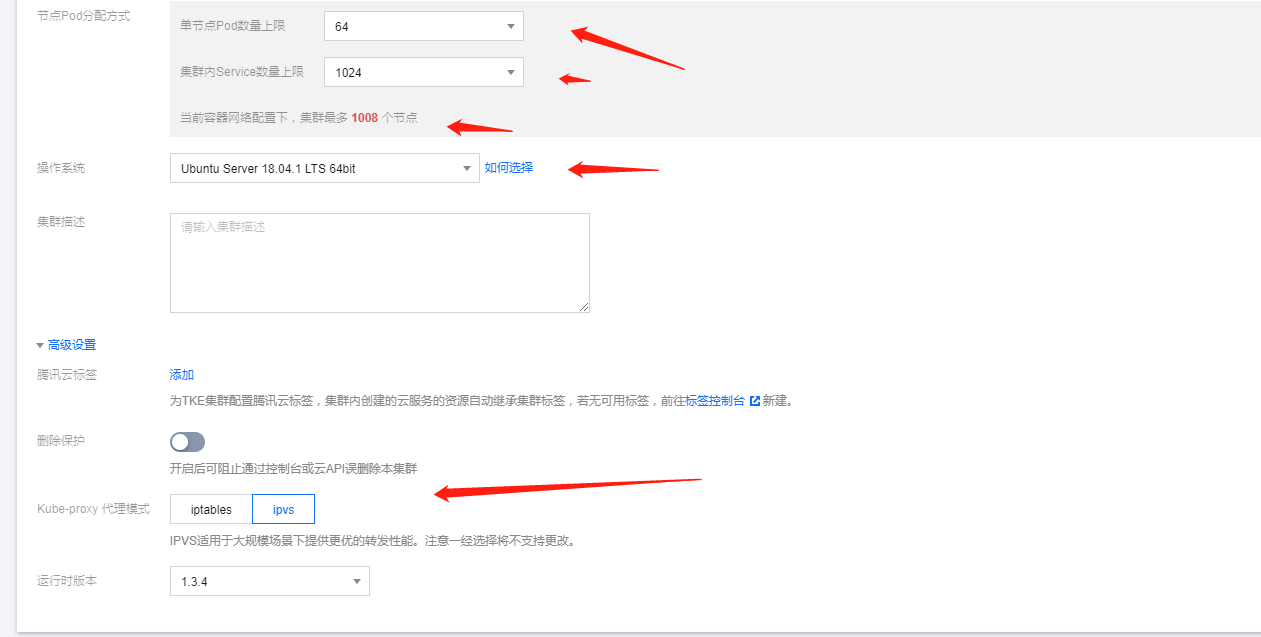
4. 操作系统与proxy选型
操作系统我都选择了ubuntu18.04。嗯也可以用腾讯云的tencent linux 或者centos.kube-proxy代理方式我选择了ipvs。当然了对应我们这样业务的量级两个proxy代理的方式差距并不是太大,也没有孰好孰坏一说,看自己需求了!
5. 新建或者将已有资源加入master work节点
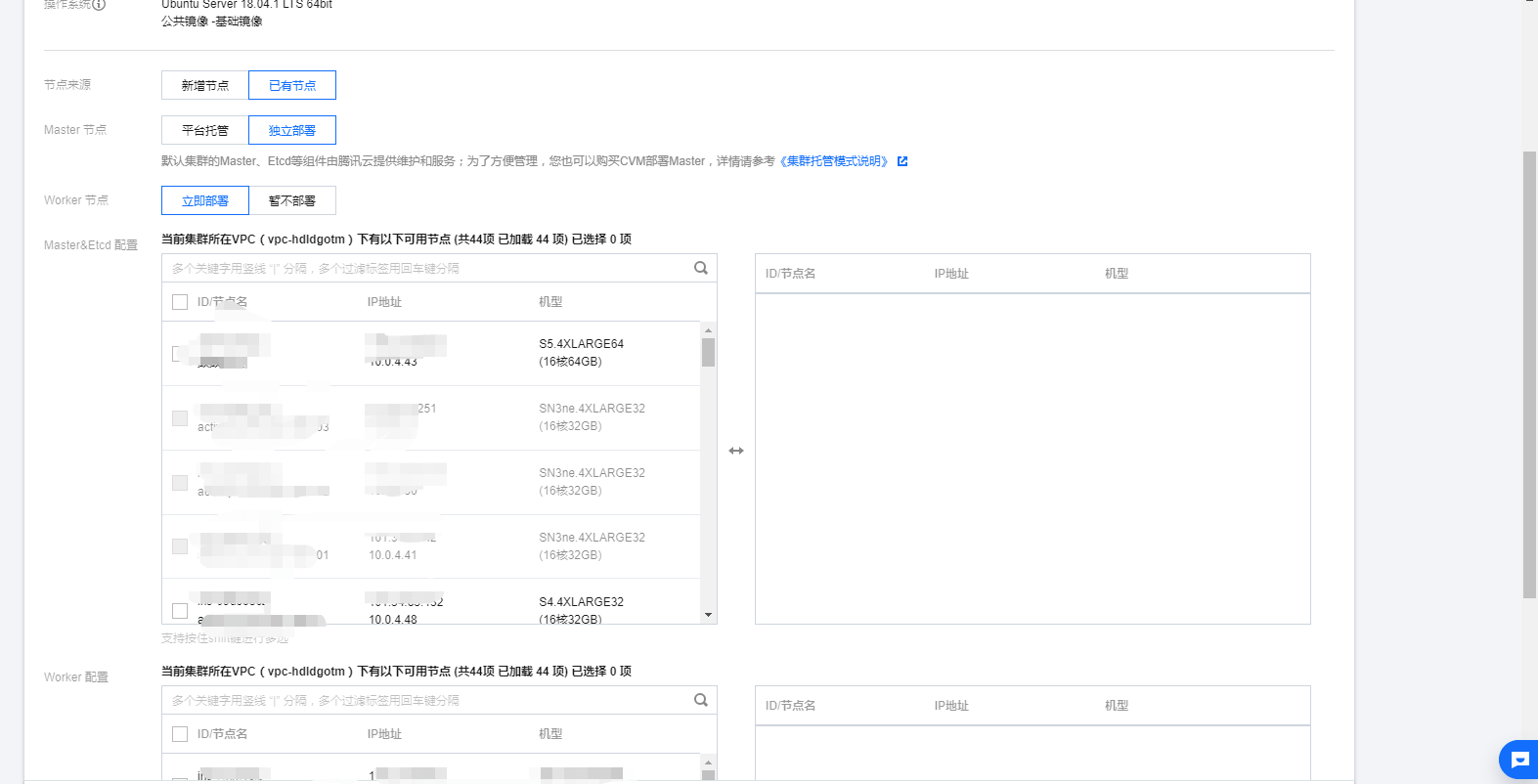
服务器的配置这里我是使用了已有的节点资源,master独立部署的方式。直接把我资源池中的cvm资源分配给了master和work。其中master节点是4核8G内存配置,work节点是16核心36G内存配置。
6. 添加增强的组件
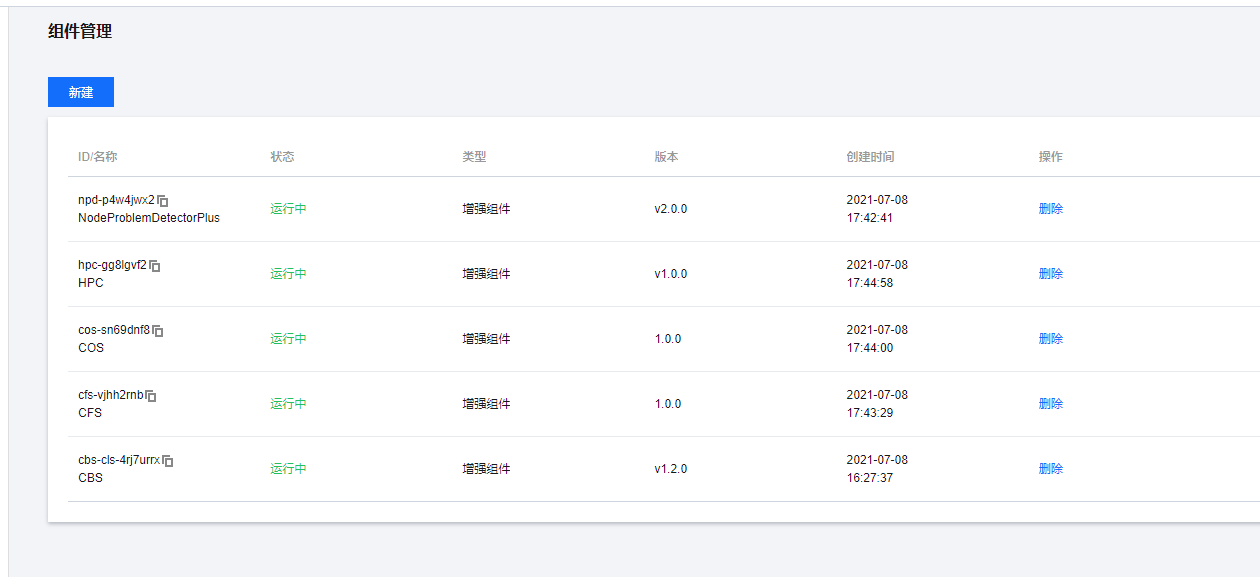
至于组件配置就看个人需求了。这边不方便截图了。我就在搭建完成的集群中理一下我随手安装的几个组件:
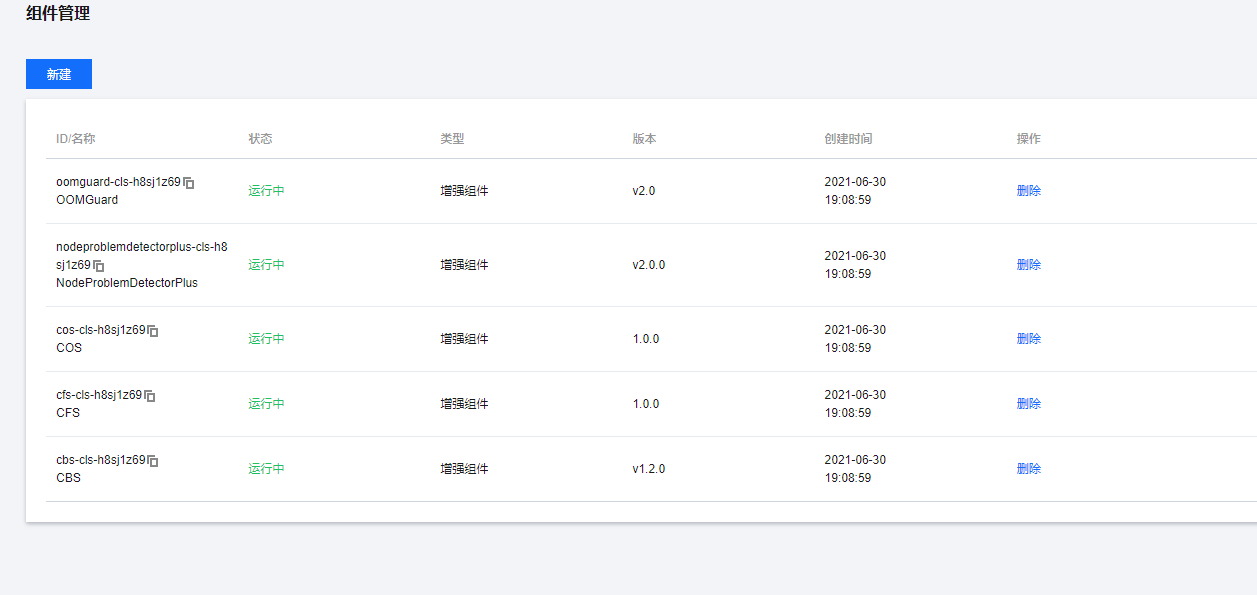
cbs cfs cos 存储组件是不可缺少的对我来说。
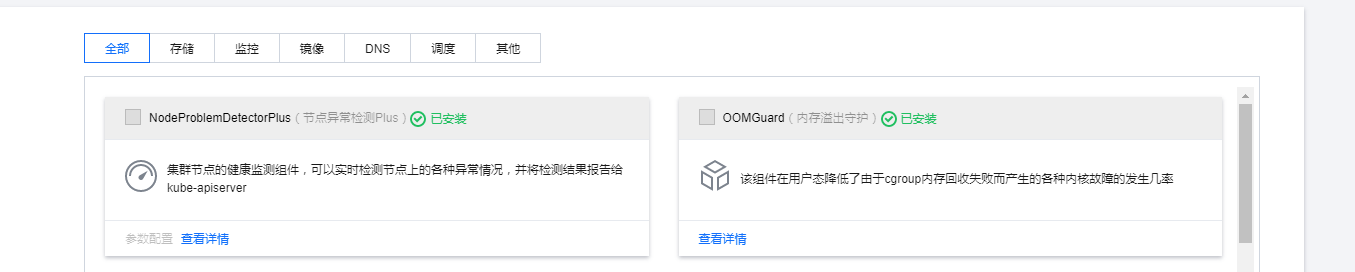
NodeProblemDetectorPlus OOMGuard看着很有用, 我也就安装上了。
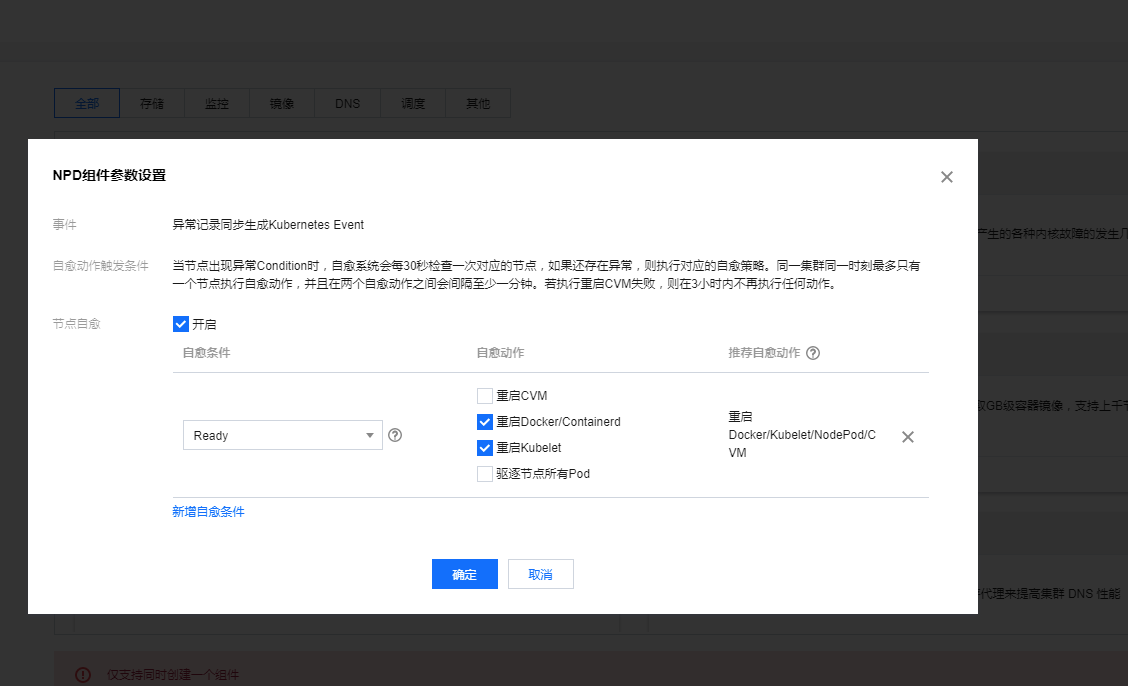
NodeProblemDetectorPlus参数设置我应该设置了一个异常重启kubelet的功能这边后台也无法查看配置参数有点不好玩了然后等待集群的初始化完成。嗯,服务器的密码可以自动生成也可以使用ssh-key或者自己手工输入的看自己需求了。
tke使用体验
1. 特别不爽的一点 kuberctl get node的排序
登陆任一一台master节点,第一件事情kubectl get nodes查看一下集群:
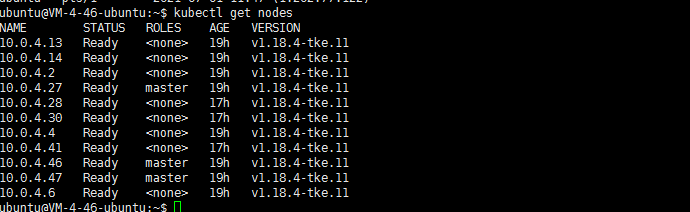
what?为什么排序拍的杂七乱八的….能不能ROLES master在前?如下图:
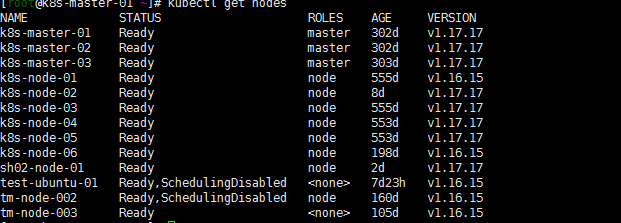
正常的排序不都这样吗?tke用ip方式显示主机名。但是master能不能排在前面?至于node节点的排序能不能有个排序的方式呢?排序这个东西提交了工单。客服回应说设计如此。幸好朋友圈有几个腾讯云的小伙伴,看我吐糟,帮拉了tke的一个群,反应了一下。然后tke的小伙伴记录了一下。
2. csi-cbs-controller插件的异常
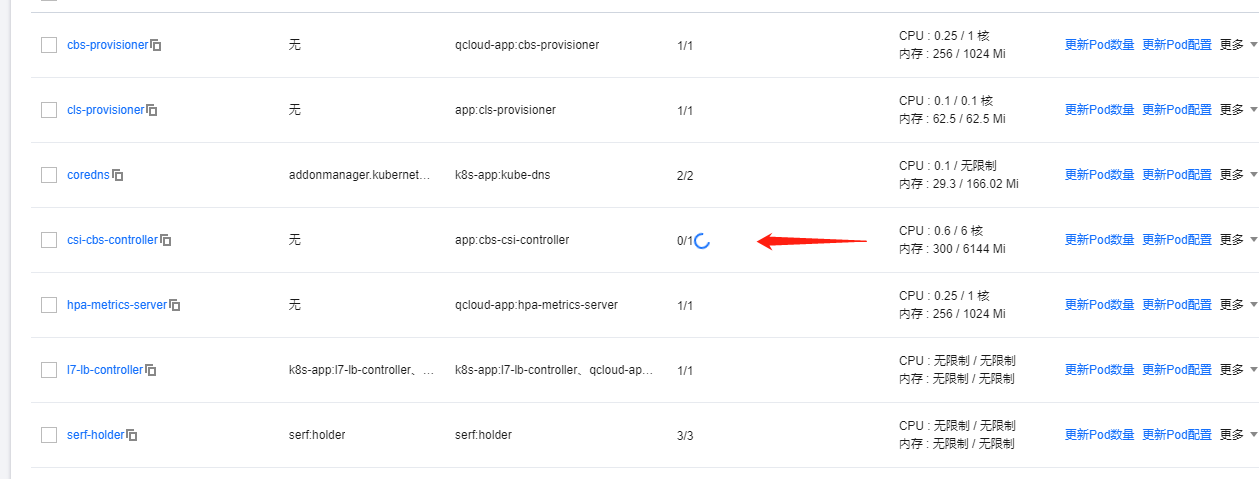
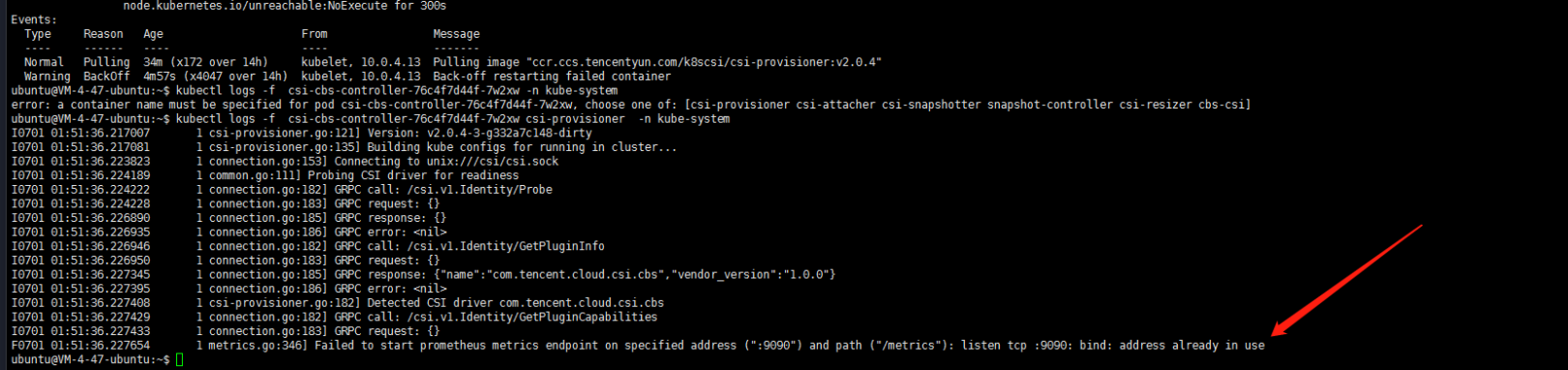
没有去细看,端口异常不知道跟哪个服务冲突了。客服最后也没有能告诉我是跟哪一个插件冲突了,后面恢复了。……主要是懒得看了。用集成服务。前提是稳定的。我个人觉得一定是可以开箱即用的。
3. 应用市场 prometheus-opraoter的错误
tke有一个应用市场,算是一个helm仓库吧。跑一个Prometheus-oprator的helm应用测试一下,然后又陷入了忧伤:
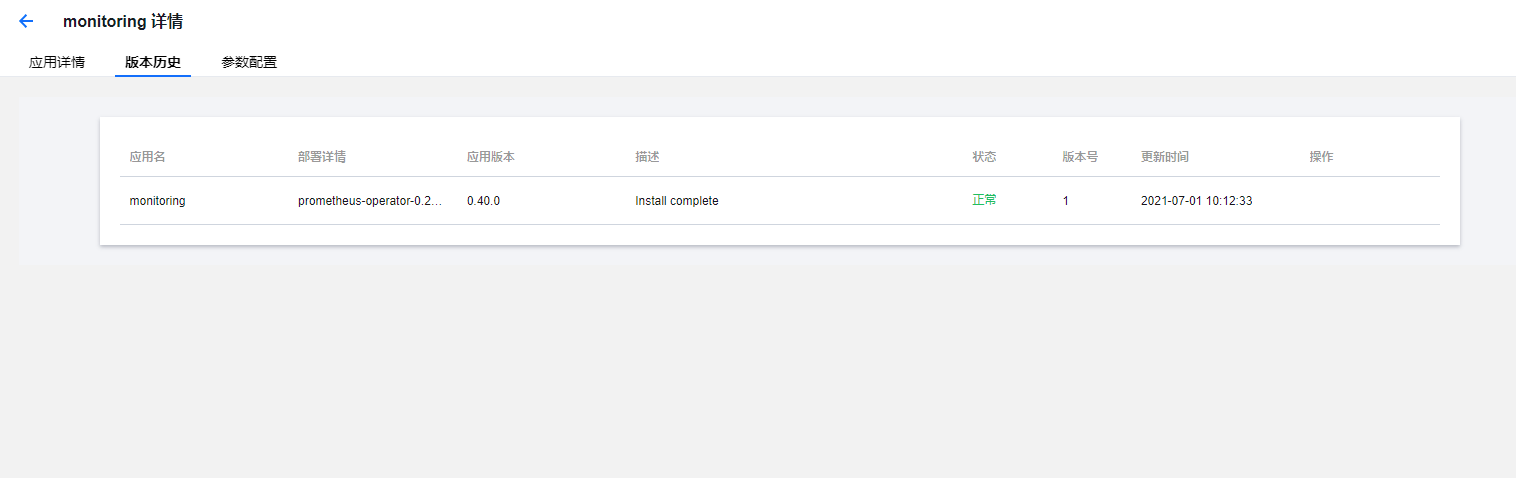
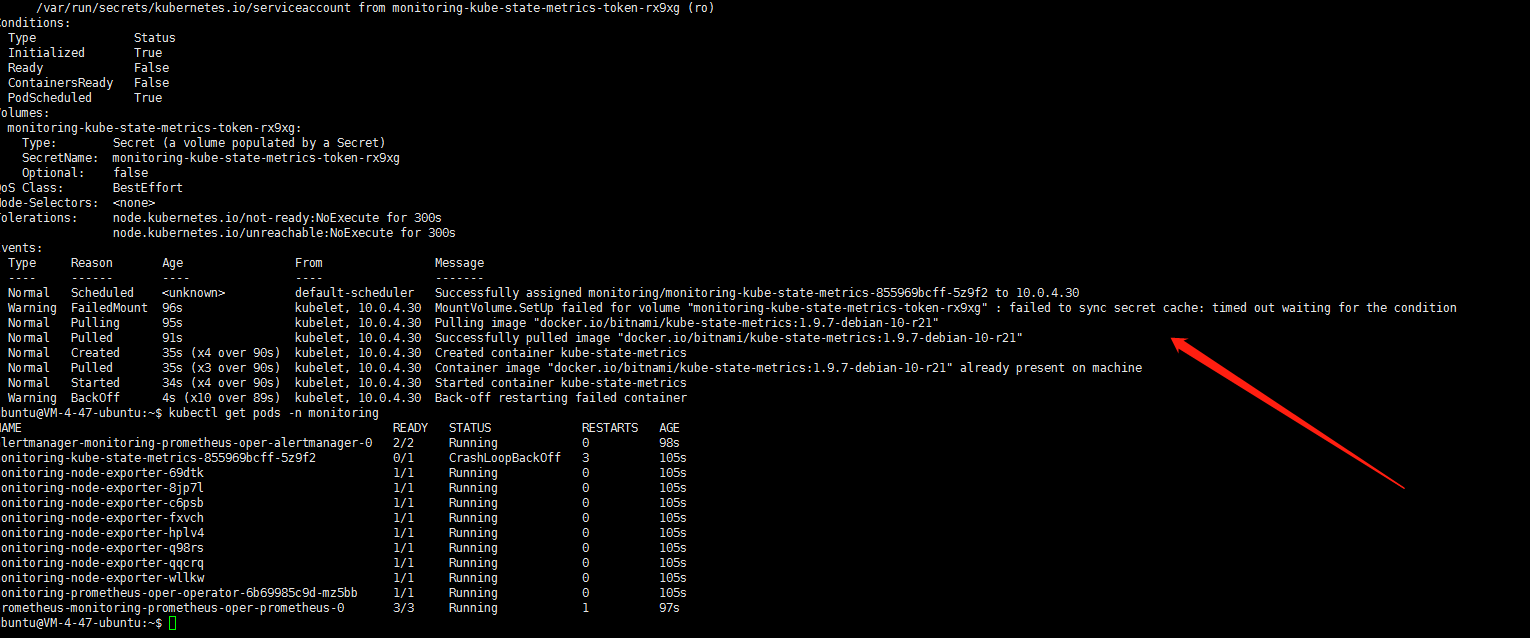
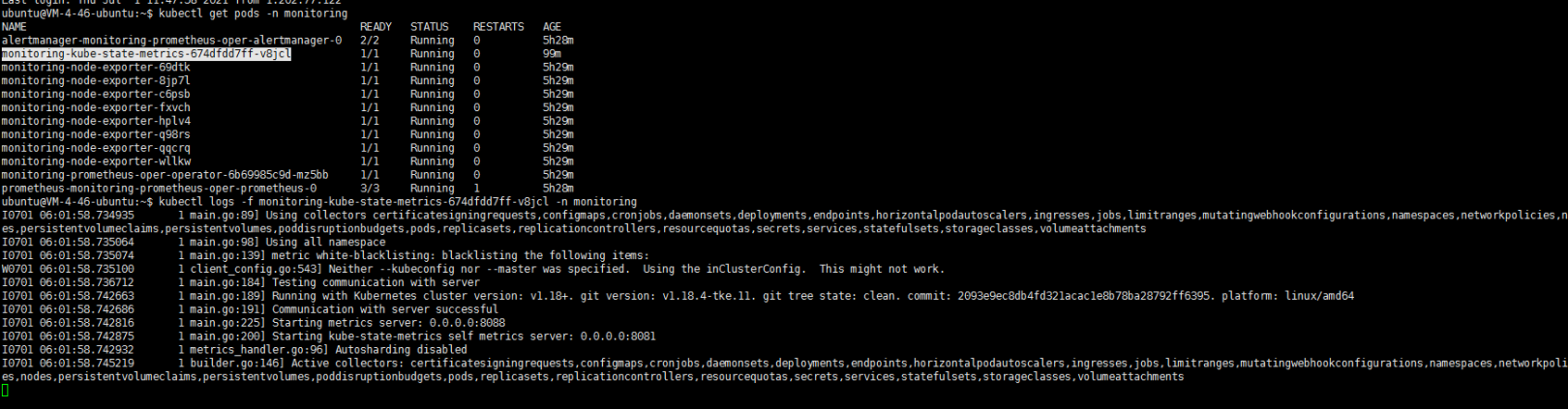
monitoring-kube-state-metrics服务无法启动。最后看了一下这个POD是使用hostNetwork模式的 需要使用主机端口,POD所在节点 这个端口是否被其他应用所占用?看了一眼此节点日志嗯 8080确实被占用了:一个名为launcher的服务占用了此端口:
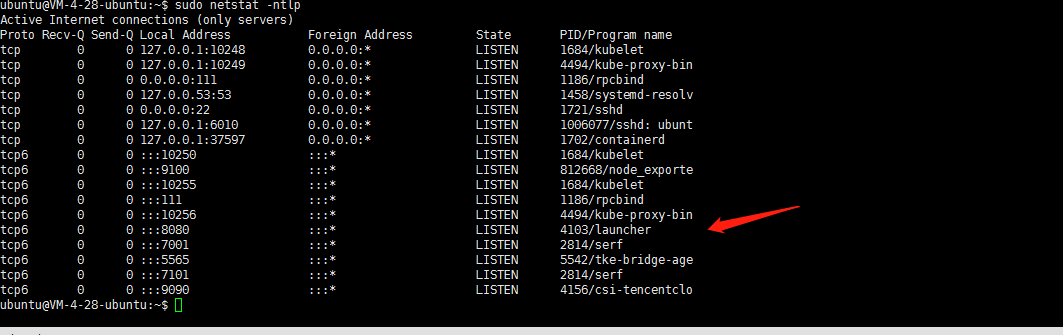
客服给的解决方案:

个人还是不太相信。因为我没有安装任何应用只安装了增强组件和存储组件。登陆其他work节点也确认一下发现每个节点都有一个launcher应用。怀疑这是一个系统组件
kubectl get pods --all-namespaces|grep launcher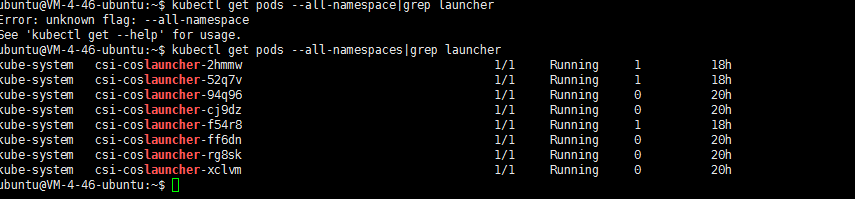
最后找客服确认了一下,如下:
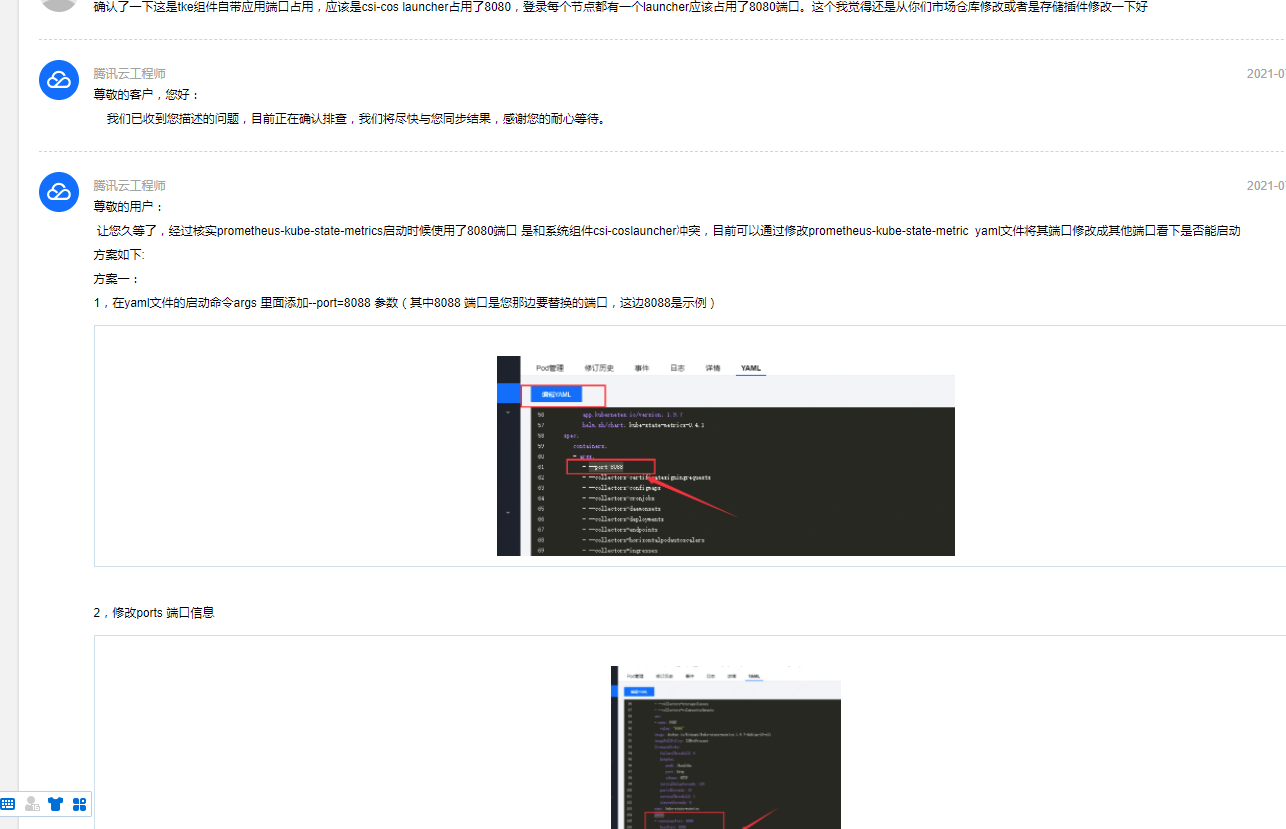
按照客服提示修改端口吧…….嗯总算起来了:
后记:
这是用tke1.18的第一印象。当然了tke的小伙伴还是很给力的,朋友帮拉了群。各种问题可以随时反馈,还是不错的。
这算是初体验吧,然后看看下一步体验一下部署其他应用,将服务clb代理。一步一步来吧。也希望tke能有更好的用户体验!
- 2022-08-09-Operator3-设计一个operator二-owns的使用
- 2022-07-11-Operator-2从pod开始简单operator
- 2021-07-20-Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)
- 2021-07-19-Kubernetes 1.18.20升级到1.19.12
- 2021-07-17-Kubernetes 1.17.17升级到1.18.20
- 2021-07-16-TKE1.20.6搭建elasticsearch on kubernetes
- 2021-07-15-Kubernets traefik代理ws wss应用
- 2021-07-09-TKE1.20.6初探
- 2021-07-08-关于centos8+kubeadm1.20.5+cilium+hubble的安装过程中cilium的配置问题--特别强调
- 2021-07-02-腾讯云TKE1.18初体验