背景:
持续升级过程:Kubernetes 1.16.15升级到1.17.17,Kubernetes 1.17.17升级到1.18.20,Kubernetes 1.18.20升级到1.19.12
集群配置:
| 主机名 | 系统 | ip |
|---|---|---|
| k8s-vip | slb | 10.0.0.37 |
| k8s-master-01 | centos7 | 10.0.0.41 |
| k8s-master-02 | centos7 | 10.0.0.34 |
| k8s-master-03 | centos7 | 10.0.0.26 |
| k8s-node-01 | centos7 | 10.0.0.36 |
| k8s-node-02 | centos7 | 10.0.0.83 |
| k8s-node-03 | centos7 | 10.0.0.40 |
| k8s-node-04 | centos7 | 10.0.0.49 |
| k8s-node-05 | centos7 | 10.0.0.45 |
| k8s-node-06 | centos7 | 10.0.0.18 |
1. 参考官方文档
参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
2. 确认可升级版本与升级方案
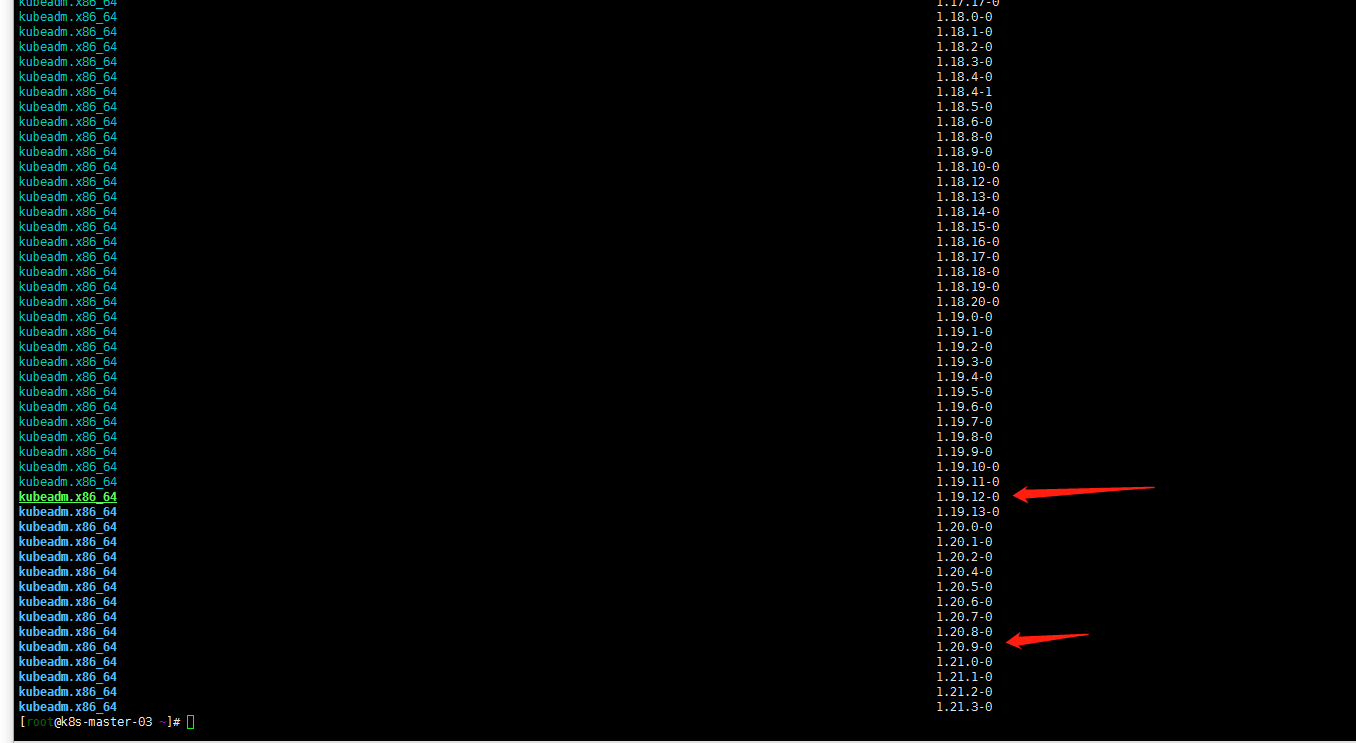
yum list --showduplicates kubeadm --disableexcludes=kubernetes
通过以上命令查询到1.20当前最新版本是1.20.9-0版本。master有三个节点还是按照个人习惯先升级k8s-master-03节点
3. 升级k8s-master-03节点控制平面
依然k8s-master-03执行:
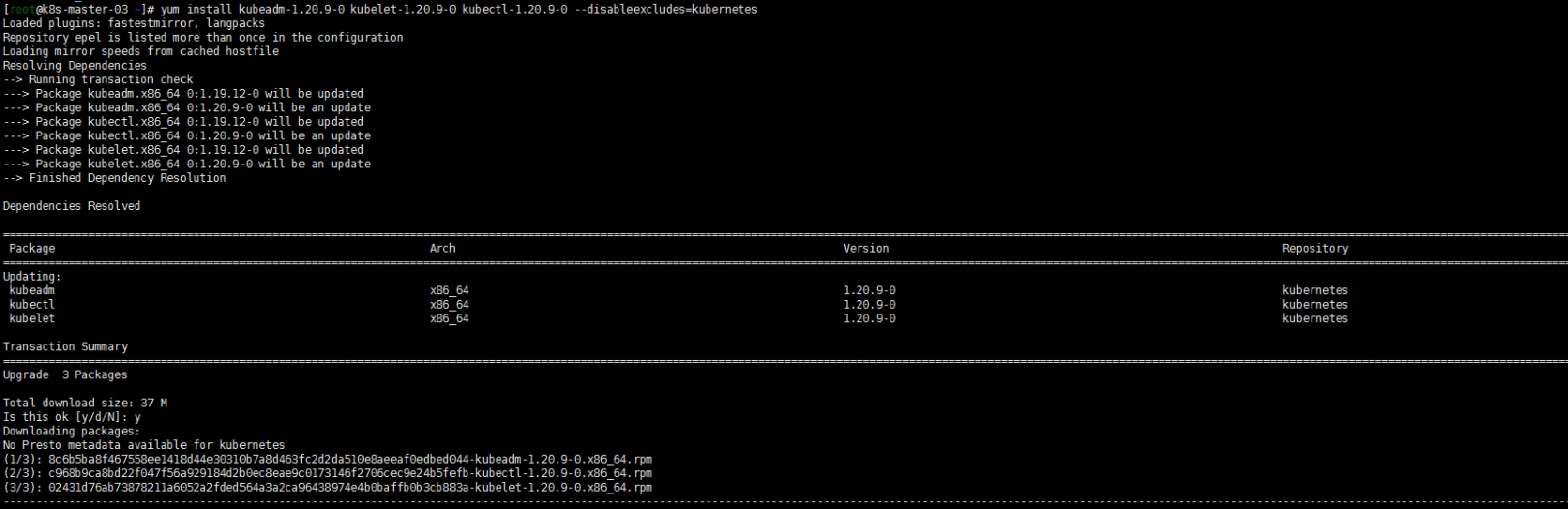
1. yum升级kubernetes插件
yum install kubeadm-1.20.9-0 kubelet-1.20.9-0 kubectl-1.20.9-0 --disableexcludes=kubernetes
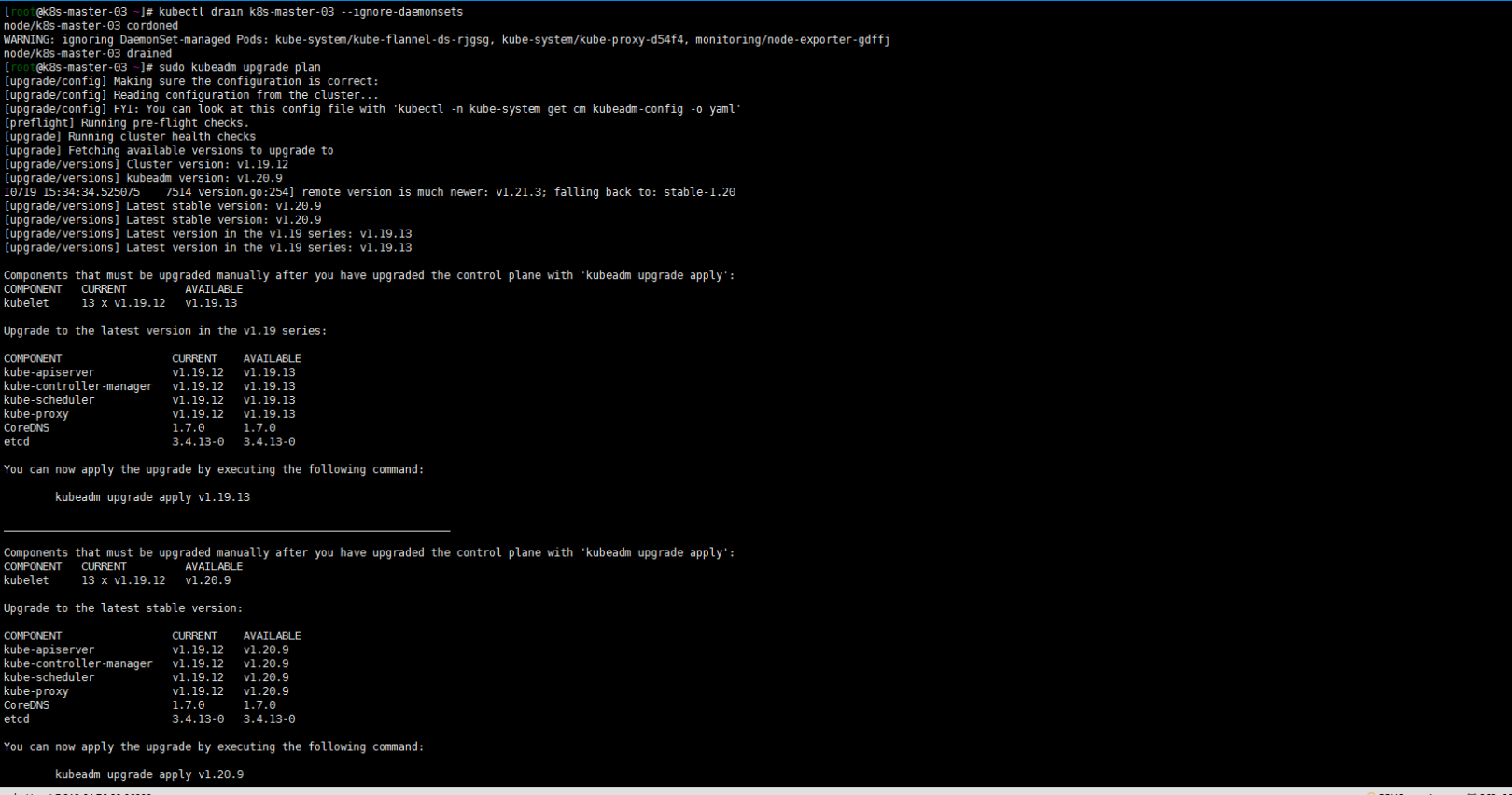
2. 腾空节点检查集群是否可以升级
依然算是温习drain命令:
kubectl drain k8s-master-03 --ignore-daemonsets
sudo kubeadm upgrade plan
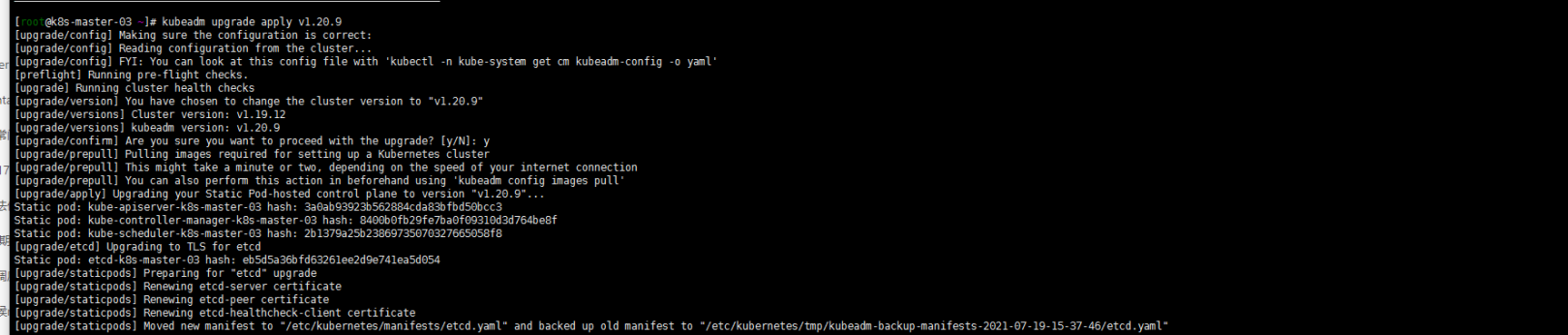
3. 升级版本到1.20.9
kubeadm upgrade apply 1.20.9
[root@k8s-master-03 ~]# sudo systemctl daemon-reload
[root@k8s-master-03 ~]# sudo systemctl restart kubelet
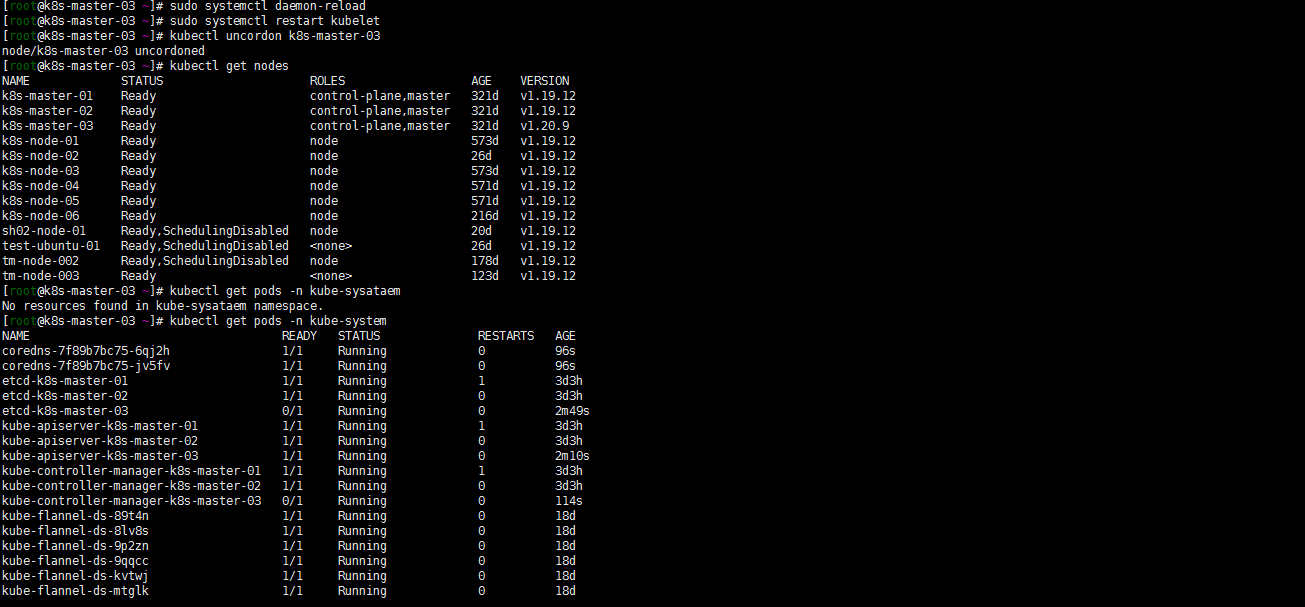
[root@k8s-master-03 ~]# kubectl uncordon k8s-master-03
node/k8s-master-03 uncordoned
[root@k8s-master-03 ~]# kubectl get nodes
[root@k8s-master-03 ~]# kubectl get pods -n kube-system

4. 升级其他控制平面(k8s-master-01 k8s-master-02)
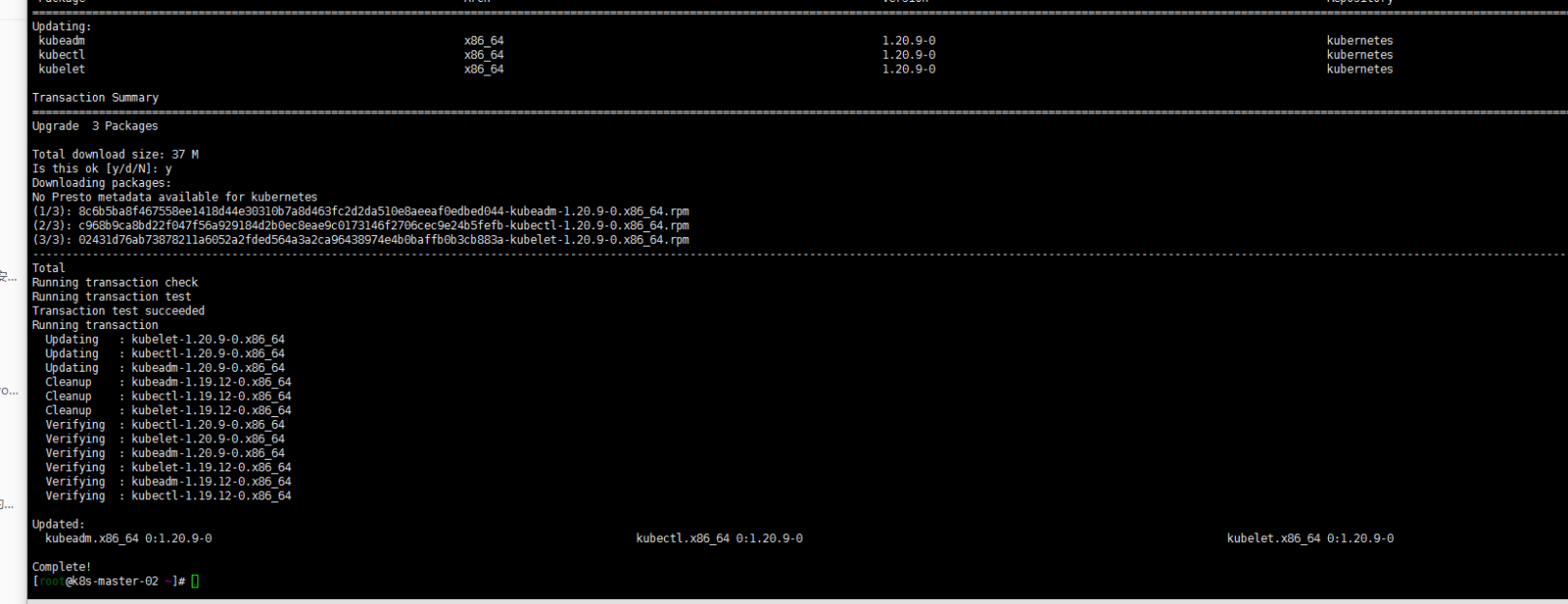
yum install kubeadm-1.20.9-0 kubelet-1.20.9-0 kubectl-1.20.9-0 --disableexcludes=kubernetes
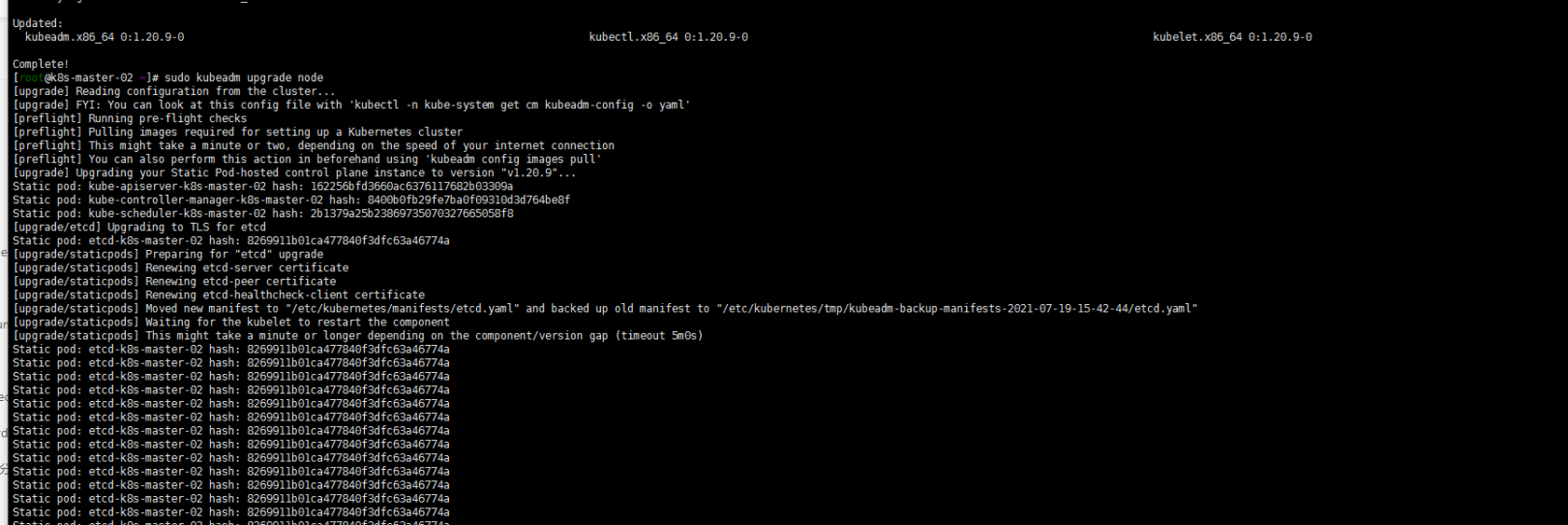
sudo kubeadm upgrade node
sudo systemctl daemon-reload
sudo systemctl restart kubelet
5. work节点的升级
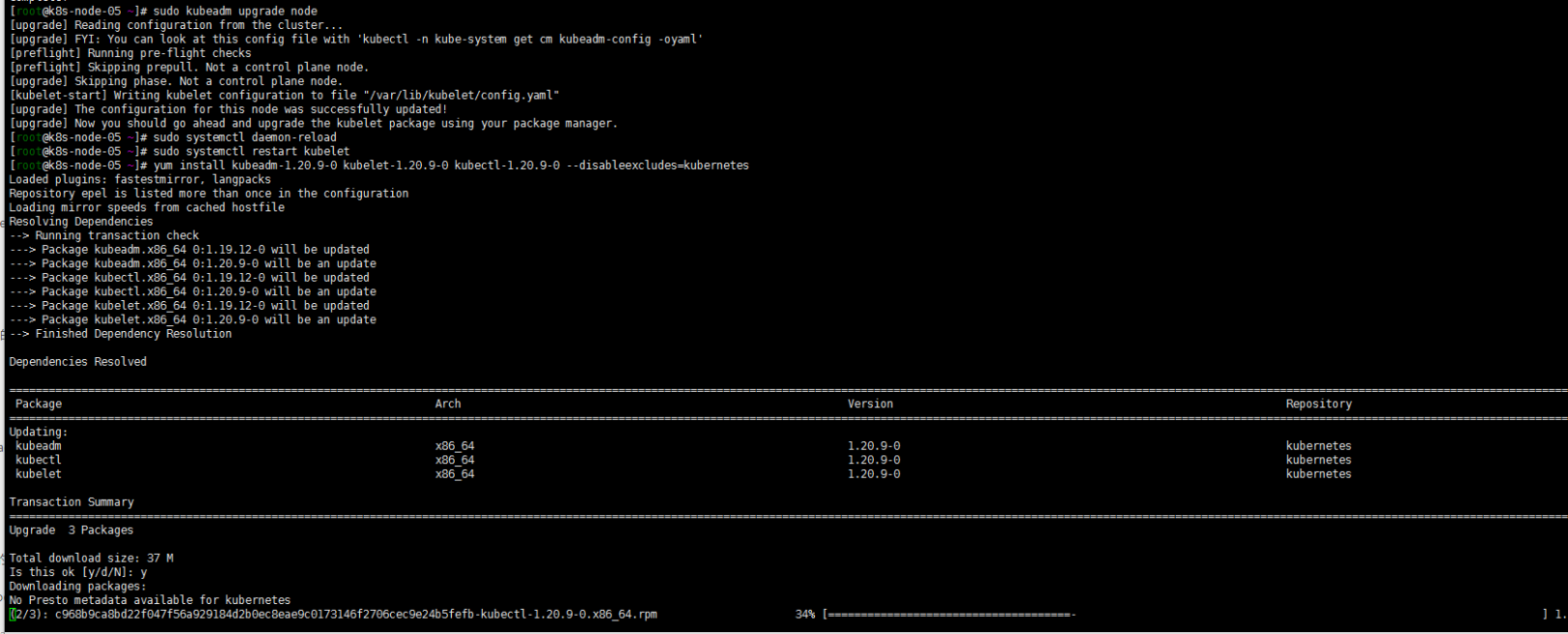
yum install kubeadm-1.20.9-0 kubelet-1.20.9-0 kubectl-1.20.9-0 --disableexcludes=kubernetes
sudo kubeadm upgrade node
sudo systemctl daemon-reload
sudo systemctl restart kubelet
注: 个人都没有腾空节点,看个人需求了
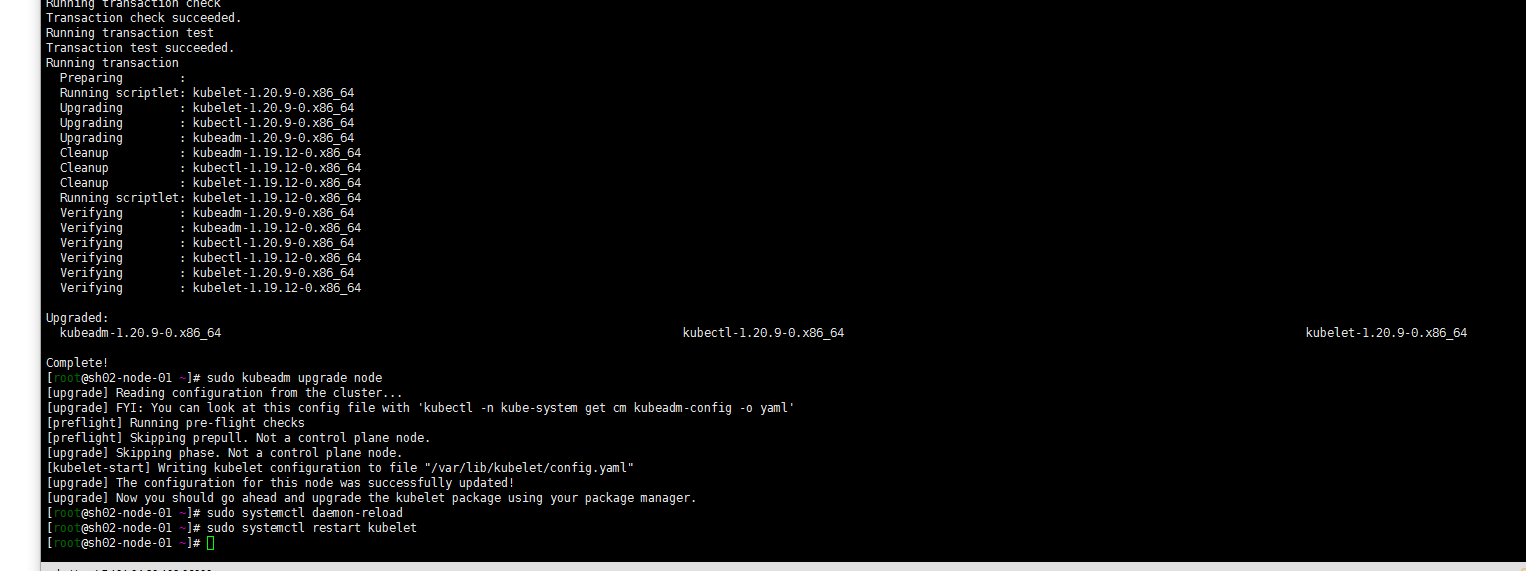
6. 验证升级
kubectl get nodes

7. 其他——v1.20.0中禁用了selfLink
由于我的Prometheus oprator是0.4的分支,就准备卸载重新安装了。版本差距太大了。现在也不想搞什么分支用了直接用主线版本了:
基本过程参照:Kubernetes 1.20.5 安装Prometheus-Oprator。基本过程都没有问题,讲一个有问题的地方:
我的kubernetes1.16升级上来的这个集群storageclass是用的nfs:
kubectl get sc

最后一
kubectl get pods -n monitoring
kubectl logs -f prometheus-operator-84dc795dc8-lkl5r -n monitoring
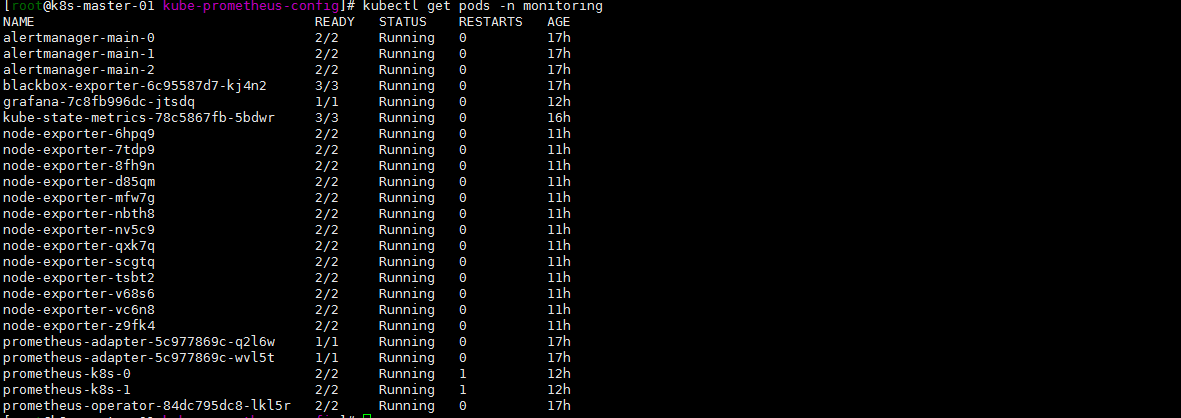
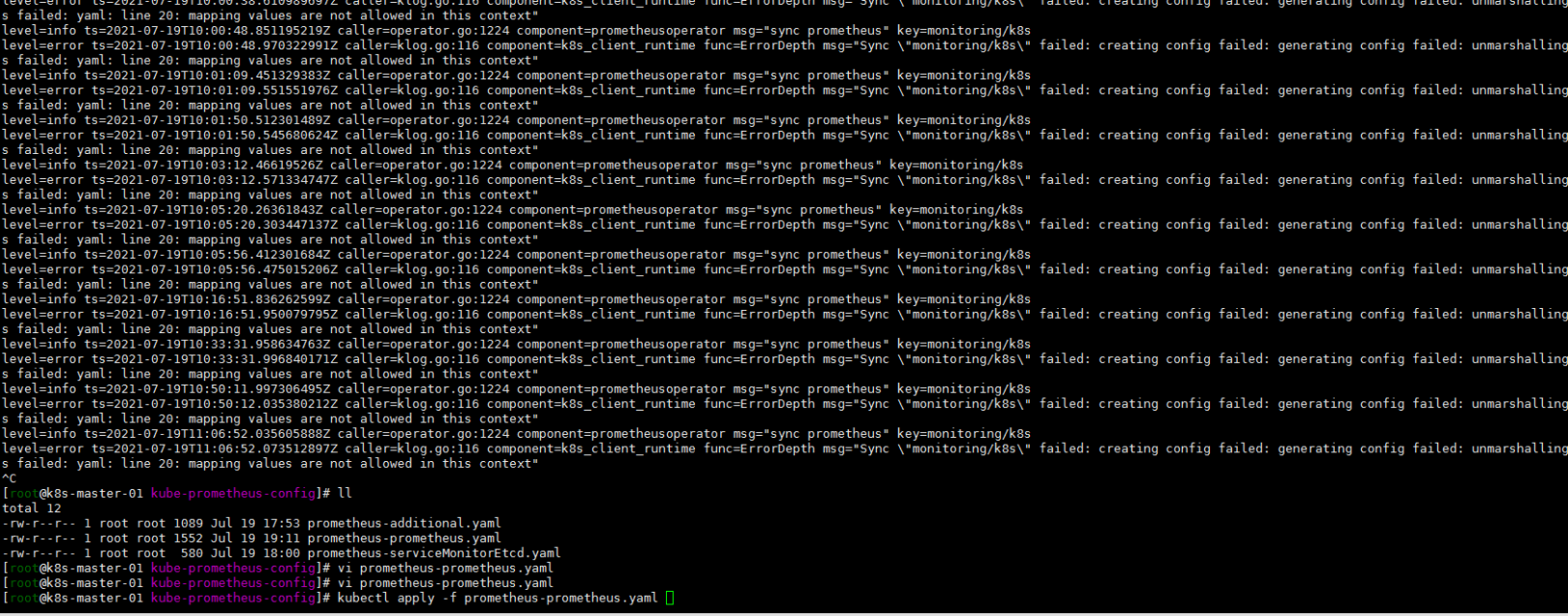
看关键词吧:
additional 貌似是自动发现的配置?
首先将prometheus-prometheus.yaml文件中的自动发现的配置注释掉。嗯服务还是没有起来,再看一眼日志:
kubectl logs -f prometheus-operator-84dc795dc8-lkl5r -n monitoring
没有什么新的输出,但是看一眼pv,pvc没有创建。去看一下nfs的pod日志:
kubectl get pods -n nfs
kubectl logs -f nfs-client-provisioner-6cb4f54cbc-wqqw9 -n nfs

class “managed-nfs-storage”: unexpected error getting claim reference: selfLink was empty, can’t make reference
百度selfLink参照:https://www.orchome.com/10024
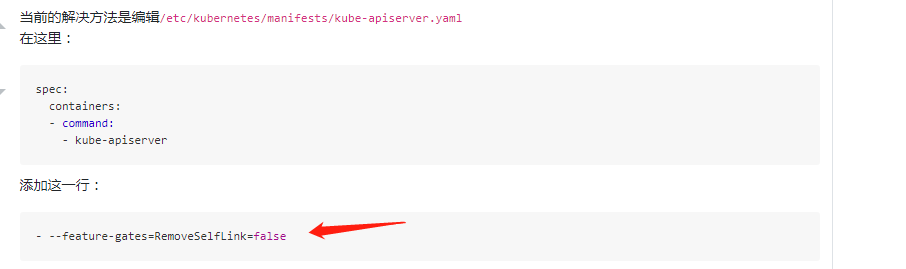
修改三个master节点的kube-apiserver.yaml
然后pv,pvc创建成功 Prometheus 服务启动成功。然后再回过头来看一眼我的additional自动发现配置:
我在Kubernetes 1.20.5 安装Prometheus-Oprator
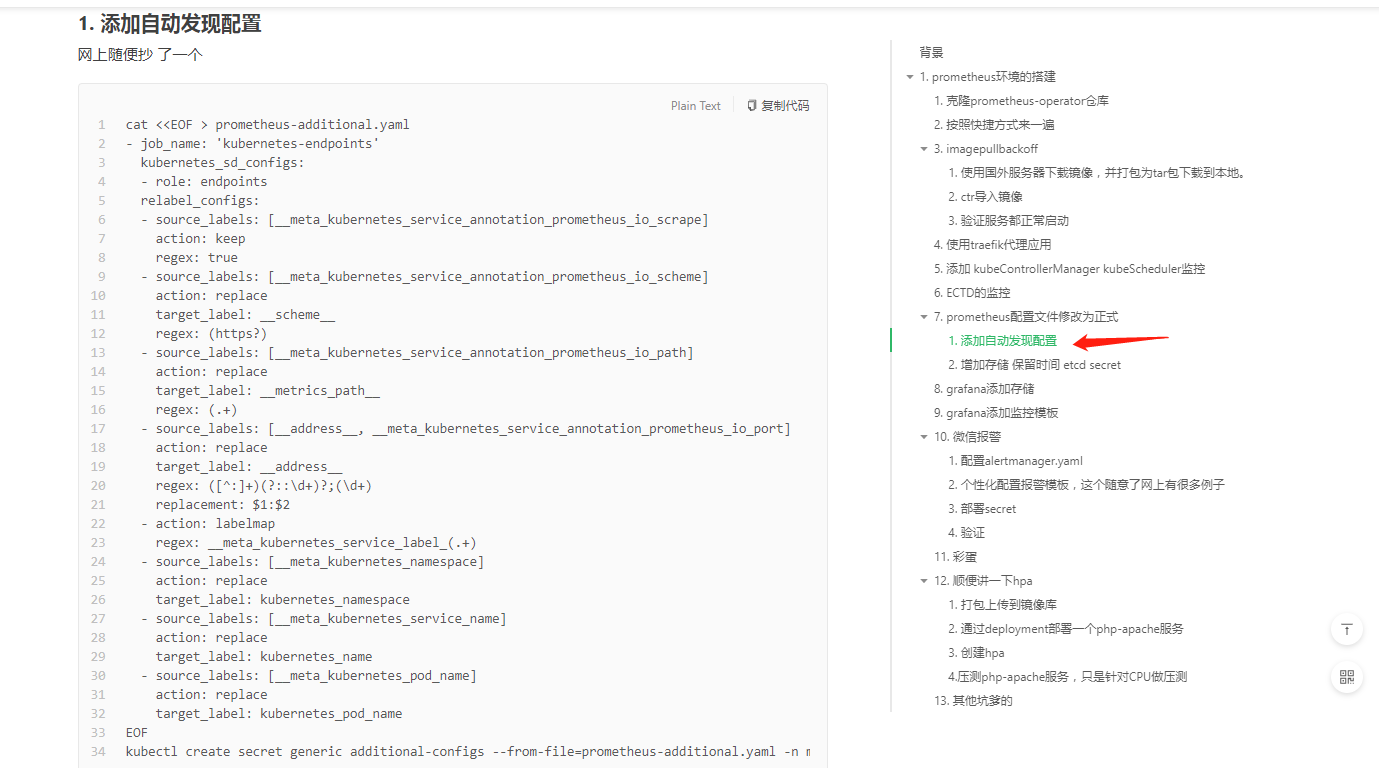
拿我的老版本的这个文件试试?:
cat <<EOF > prometheus-additional.yaml
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
EOF
kubectl delete secret additional-configs -n monitoring
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
再看日志启动起来了。初步先怀疑我配置文件中的prometheus-additional.yaml 有问题。当然了这是个人问题了。强调的主要是master节点kube-apiserver.yaml文件的修改添加:
- --feature-gates=RemoveSelfLink=false