前因后果:
1. 升级后的报警
Kubernetes 1.20.5 upgrade 1.21.0,升级完成突然发现Prometheus discover中两个服务down了,收到微信报警
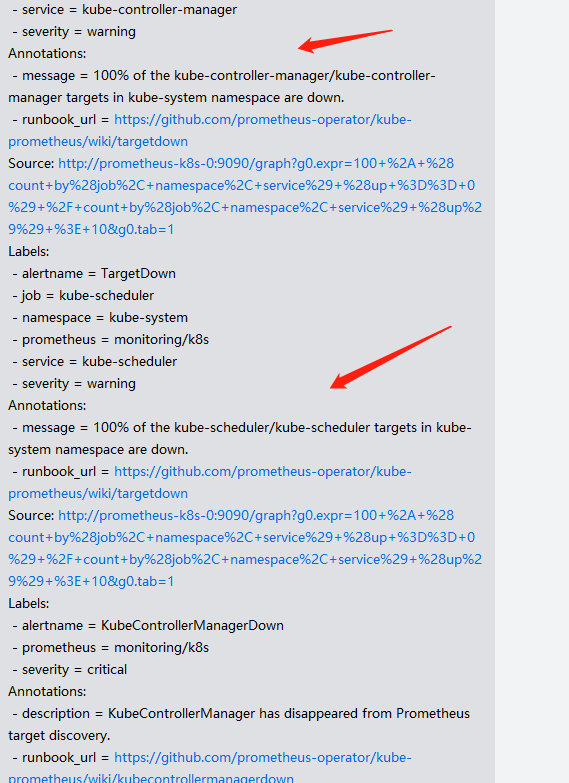
登陆Prometheus控制台一看controller-manager kube-scheduler服务确实是down:
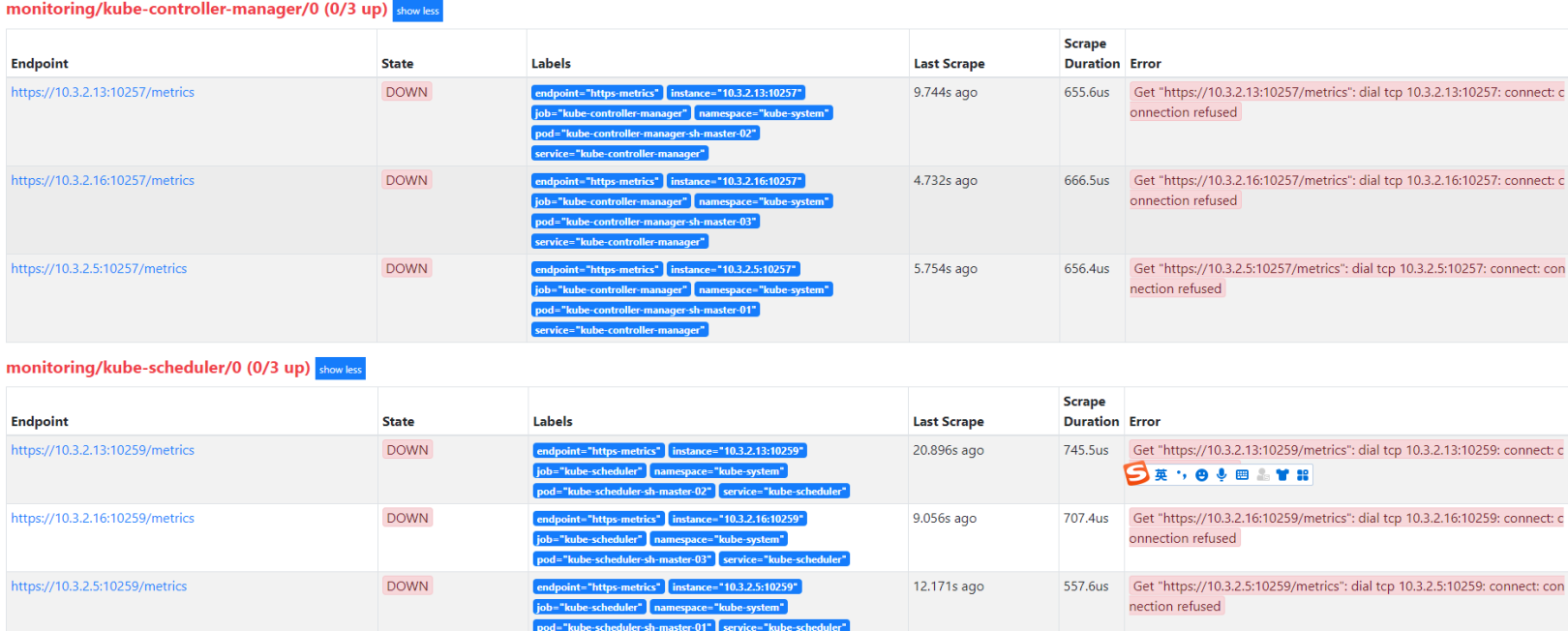
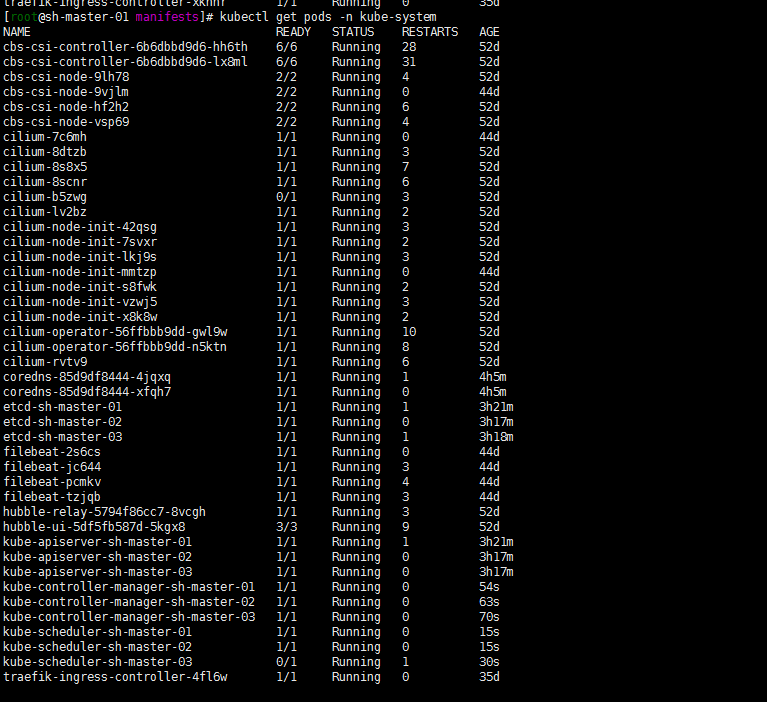
2. 查看服务状态确认相关服务是正常状态
登陆集群查看kubectl get pods -n kube-system服务都是正常的。当然了也可以kubectl logs -f $podname -n kube-system去查看一下相关pod的log日志进行确认一下。
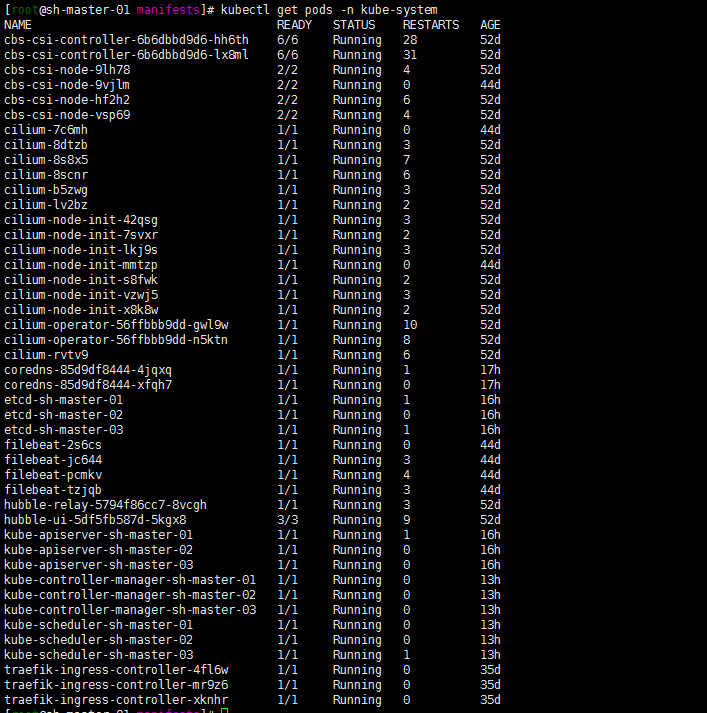
3. 定位原因
仔细一想是不是升级的时候controller-manager kube-scheduler服务的配置文件给升级了呢…记得在搭建Prometheus-oprator的时候手动修改过两个服务的配置文件what仔细一想也对…upgrade的时候 它难道把两个配置文件改了?
4. 修改kube-controller-manage kube-scheduler配置文件
继续参照:Kubernetes 1.20.5 安装Prometheus-Oprator中1.5 查看controller-manager kube-scheduler服务的配置:
注:配置文件路径为:/etc/kubernetes/manifests
cat cat kube-controller-manager.yaml 发现–bind-address=127.0.0.1了 恢复了初始的设置,在安装Prometheus-oprator的时候将其修改为0.0.0.0的同理修改。
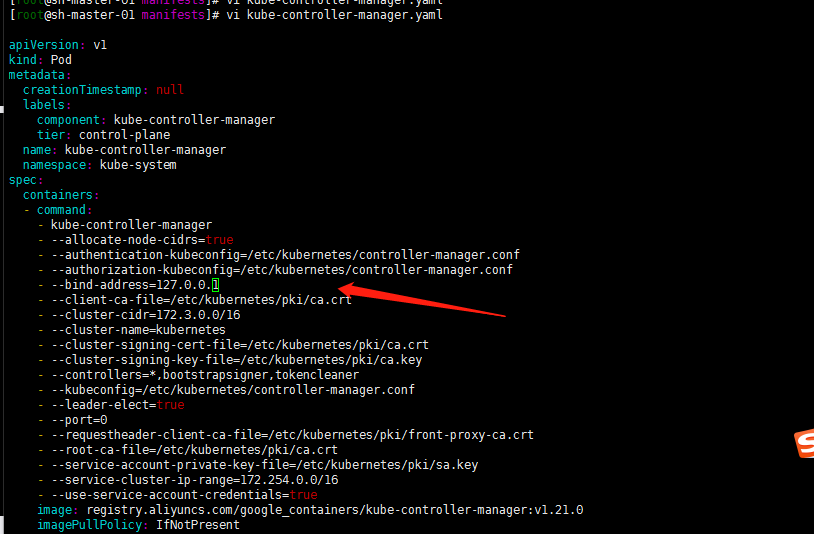
修改scheduler配置文件–bind-address=0.0.0.0
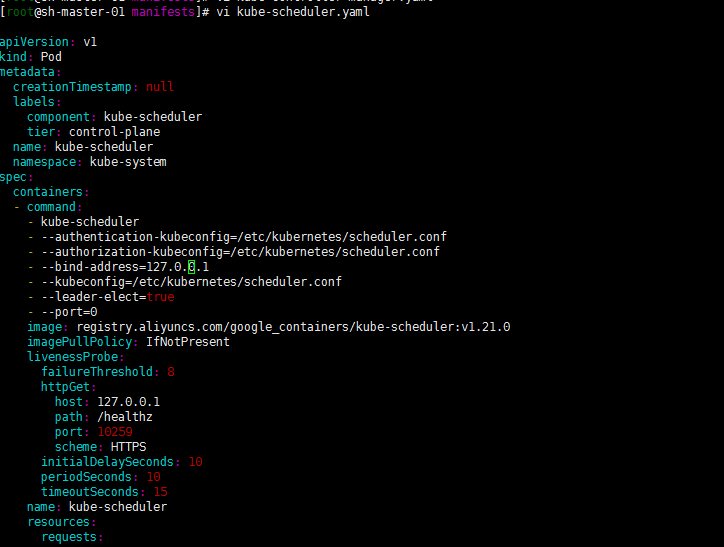
注: 修改配置文件是针对所有master节点配置文件的。
5. 重启kubelet服务
重启 三个master节点kubelet服务:
注:我记得应该修改了相关的配置服务 控制平面的相关pods是会重启的吧?重启kubelet只是个人确保一下啊正常……
systemctl restart kubelet
等待服务跑起来running……
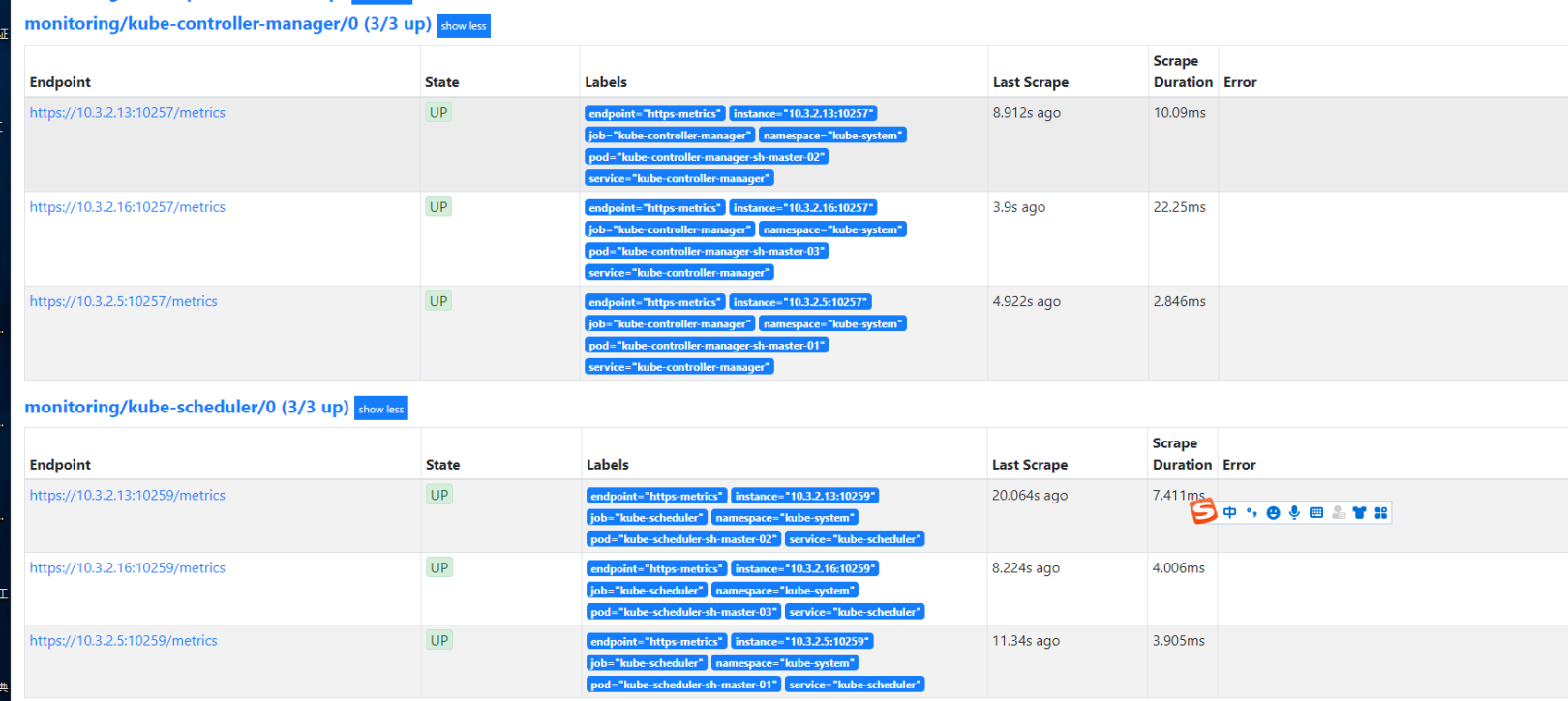
6. 确认Prometheus控制台status状态up
登陆Prometheus web控制台确认监控恢复正常状态:
问题复盘:
- 必须认同升级是必然的过程。保证集群的健康安装需要保证集群的不断updata,当然并不一定是最新的。
- 相关服务的安装修改需要熟练牢记。就像Prometheus-oprator中controller-manager kube-scheduler服务一样,起码能明确记得修改过两个相关配置文件。确认服务正常后,可以去很明确的查看定位配置文件的修改。
- 监控还是很有必要的,不管你是轻视还是重视。很大程度上面可以避免更多的失误,作为一个衡量指标