- 描述背景:
描述背景:
注:搭建prometheus-operator
集群配置: 初始集群环境kubeadm 1.16.1
| ip | 自定义域名 | 主机名 |
|---|---|---|
| 192.168.3.8 | master.k8s.io | k8s-vip |
| 192.168.3.10 | master01.k8s.io | k8s-master-01 |
| 192.168.3.5 | master02.k8s.io | k8s-master-02 |
| 192.168.3.12 | master03.k8s.io | k8s-master-03 |
| 192.168.3.6 | node01.k8s.io | k8s-node-01 |
| 192.168.3.2 | node02.k8s.io | k8s-node-02 |
| 192.168.3.4 | node03.k8s.io | k8s-node-03 |
安装prometheus-operator
先说下自己的流程:
- 克隆prometheus-operator仓库
- 按照官方quickstart进行安装
- treafik代理prometheus grafana alertmanager
- 添加 kubeControllerManager kubeScheduler监控
- 监控集群etcd服务
- 开启服务自动发现,配置可持续存储,修改prometheus Storage Retention参数设置数据保留时间
- grafana添加监控模板,持久化
- 微信报警
克隆prometheus-operator仓库
注:新版本升级后和旧版本文件结构有些不一样 可以参照github仓库文档quickstart.
git clone https://github.com/coreos/kube-prometheus
cd kube-prometheus
###创建命名空间和crd.保证可用后建立相关资源
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
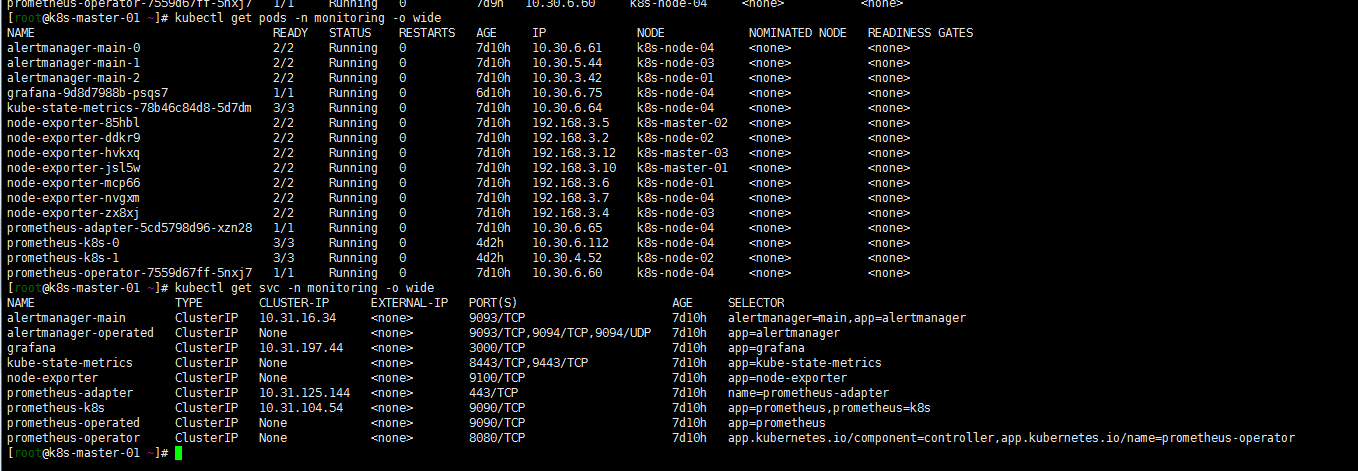
kubectl get pods -n monitoring
[root@k8s-master-01 work]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
grafana-58dc7468d7-6v86k 1/1 Running 0 9m
kube-state-metrics-78b46c84d8-ns7hk 2/3 ImagePullBackOff 0 9m
node-exporter-4pr77 2/2 Running 0 9m
node-exporter-6jhz5 2/2 Running 0 9m
node-exporter-8xv8v 2/2 Running 0 9m
node-exporter-ngt9r 2/2 Running 0 9m
node-exporter-nlff4 2/2 Running 0 9m
node-exporter-pw554 2/2 Running 0 9m
node-exporter-rwpfj 2/2 Running 0 9m
node-exporter-thz4j 2/2 Running 0 9m
prometheus-adapter-5cd5798d96-2jnjl 0/1 ImagePullBackOff 0 9m
prometheus-operator-99dccdc56-zr6fw 0/1 ImagePullBackOff 0 9m11s
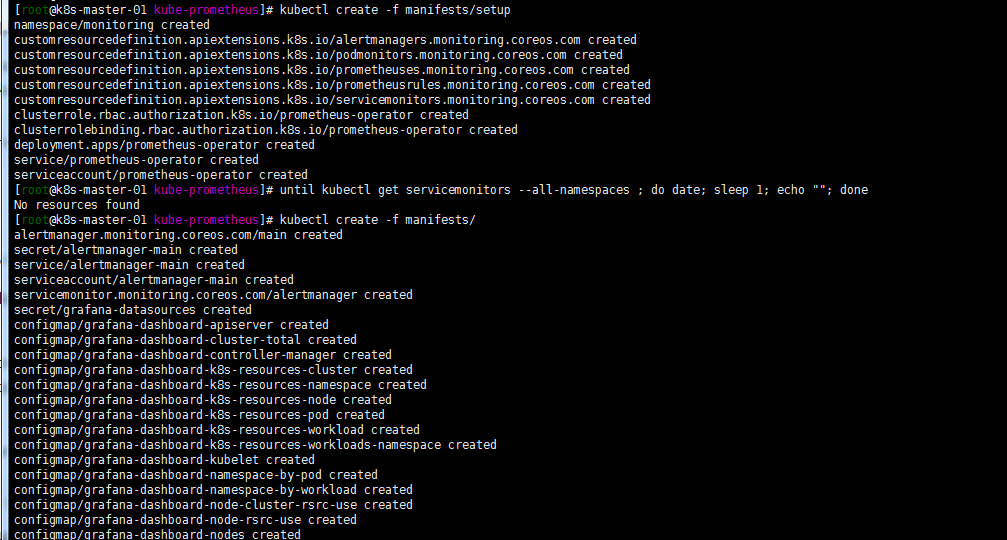
注意:会出现有些镜像下载不下来的问题,可墙外服务器下载镜像修改tag上传到harbor,修改yaml文件中镜像为对应harbor tag解决。最终如下图:
treafik代理prometheus grafana alertmanager
monitoring下创建http证书(ssl证书目录下执行)
kubectl create secret tls all-saynaihe-com --key=2_sainaihe.com.key --cert=1_saynaihe.com_bundle.crt -n monitoring
cat <<EOF > monitoring.com.yaml
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
namespace: monitoring
name: alertmanager-main-https
spec:
entryPoints:
- websecure
tls:
secretName: all-saynaihe-com
routes:
- match: Host(`alertmanager.saynaihe.com`)
kind: Rule
services:
- name: alertmanager-main
port: 9093
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
namespace: monitoring
name: grafana-https
spec:
entryPoints:
- websecure
tls:
secretName: all-saynaihe-com
routes:
- match: Host(`monitoring.saynaihe.com`)
kind: Rule
services:
- name: grafana
port: 3000
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
namespace: monitoring
name: prometheus
spec:
entryPoints:
- websecure
tls:
secretName: all-saynaihe-com
routes:
- match: Host(`prometheus.saynaihe.com`)
kind: Rule
services:
- name: prometheus-k8s
port: 9090
---
EOF
kubectl apply -f monitoring.com.yaml
登录https://monitoring.saynaihe.com/
https://prometheus.saynaihe.com/
https://alertmanager.saynaihe.com/
查看,如下图:

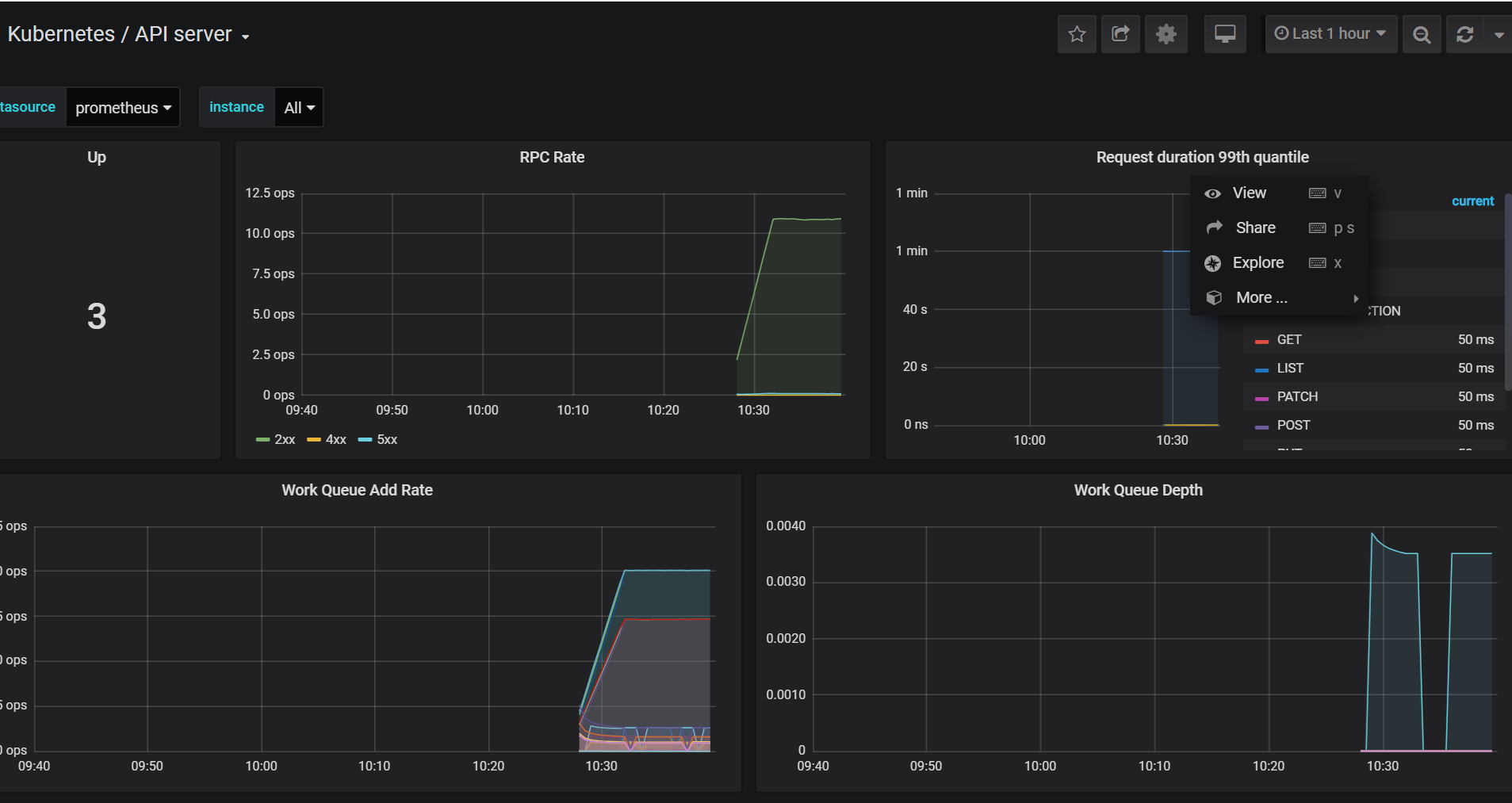
添加 kubeControllerManager kubeScheduler监控
在https://prometheus.saynaihe.com/targets中可以看到, kubeControllerManager kubeScheduler没有能正常监控。
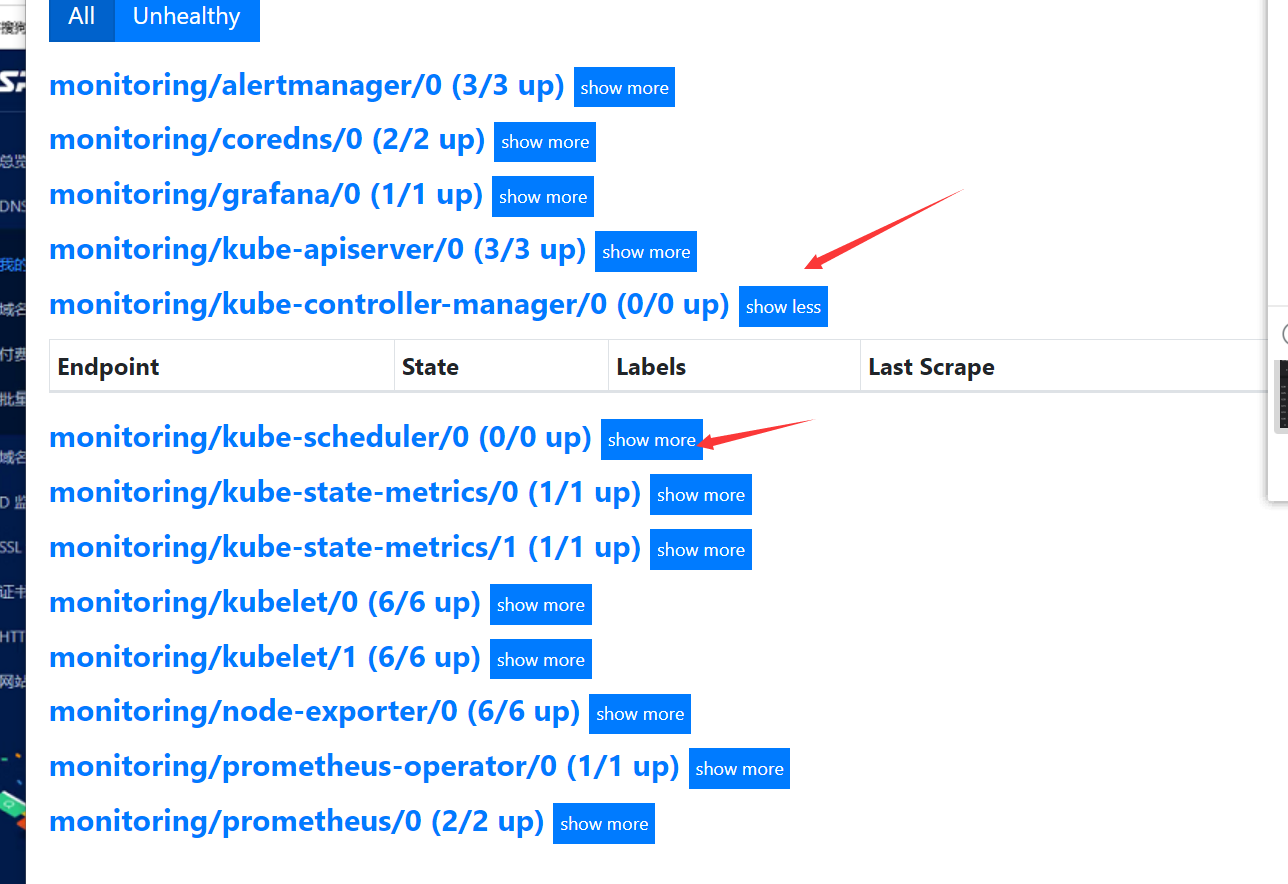
可参照https://www.qikqiak.com/post/first-use-prometheus-operator/ 阳明大佬的文档:
cat <<EOF > prometheus-kubeControllerManagerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
EOF
kubectl apply -f prometheus-kubeControllerManagerService.yaml
cat <<EOF > prometheus-kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
EOF
kubectl apply -f prometheus-kubeSchedulerService.yaml
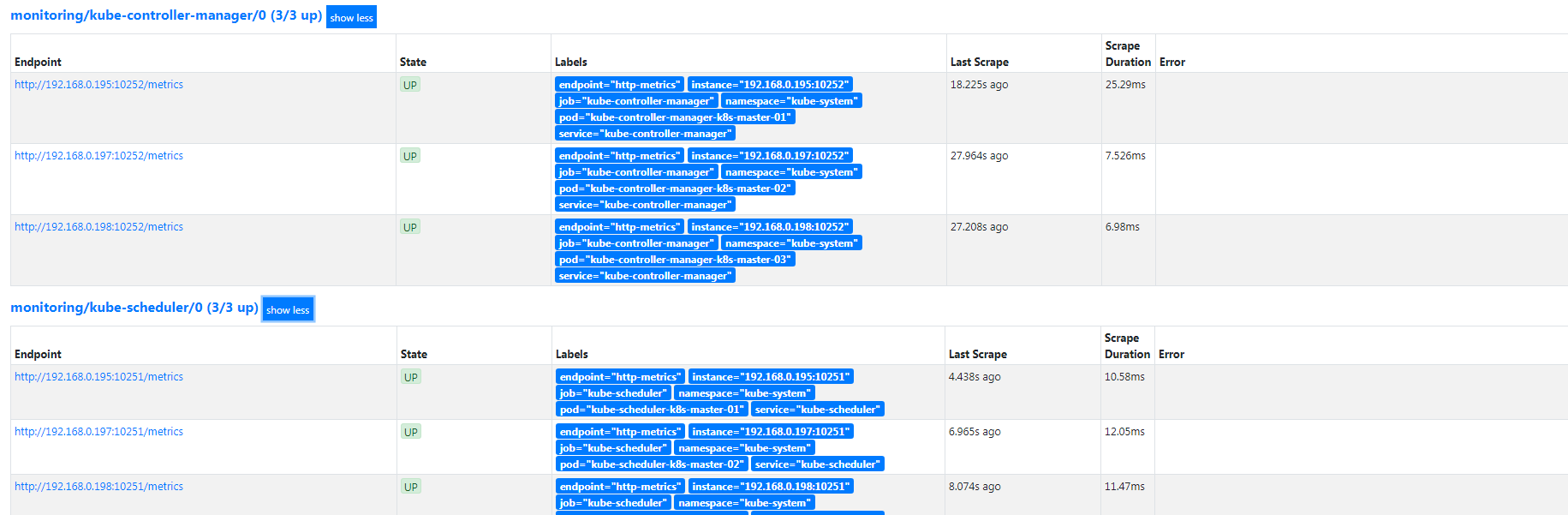
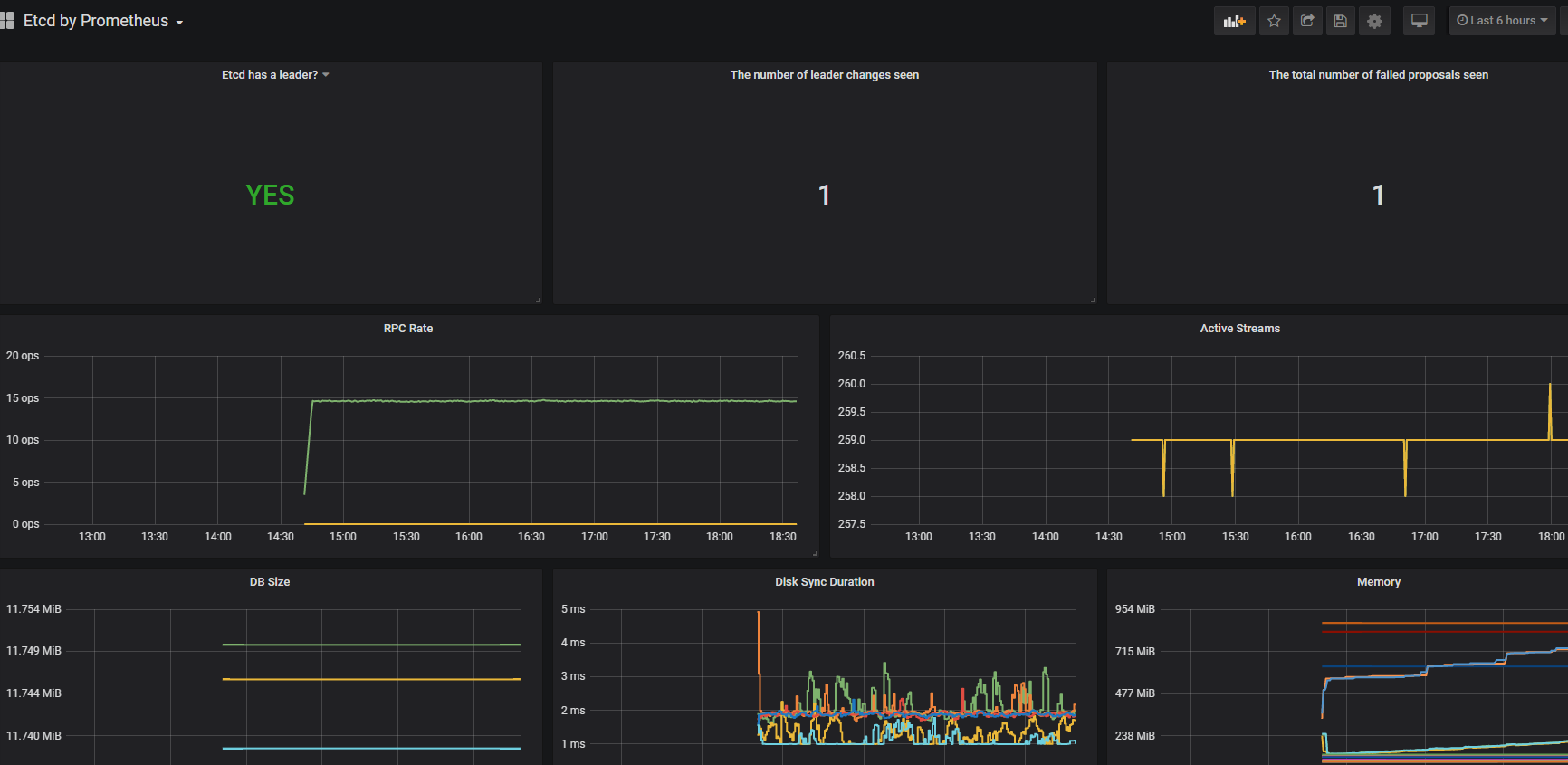
监控集群etcd服务
kubernetes 安装etcd一般常用的是两种 外部搭建etcd和 容器化运行etc两种的方式都写了下。也特别说下既然都用了kubernetes了 都上了容器了 没有必要去外部搭建etd集群。尤其是后期集群升级,etcd的版本 各种的 会有些恶心,安装kubernetes集群还是安装官方的指导的安装比较好,个人觉得很多教程让二进制安装和kubeadm安装还外挂etcd集群的方式很爽反感。除非有良好系统的基础不建议那么的玩了。
kubadm安装集成etcd方式下操作:
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt
cat <<EOF > prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: port
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
EOF
kubectl apply -f prometheus-serviceMonitorEtcd.yaml
kubadm安装挂载外部安装etcd方式下操作:
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/etcd/ssl/ca.pem --from-file=/etc/etcd/ssl/server.pem --from-file=/etc/etcd/ssl/server-key.pem
cat <<EOF > prometheus-serviceMonitorEtcd.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 192.168.0.195
nodeName: etcd1
- ip: 192.168.0.197
nodeName: etcd2
- ip: 192.168.0.198
nodeName: etcd3
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.pem
certFile: /etc/prometheus/secrets/etcd-certs/server.pem
keyFile: /etc/prometheus/secrets/etcd-certs/server-key.pem
#use insecureSkipVerify only if you cannot use a Subject Alternative Name
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
EOF
kubectl apply -f prometheus-serviceMonitorEtcd.yaml
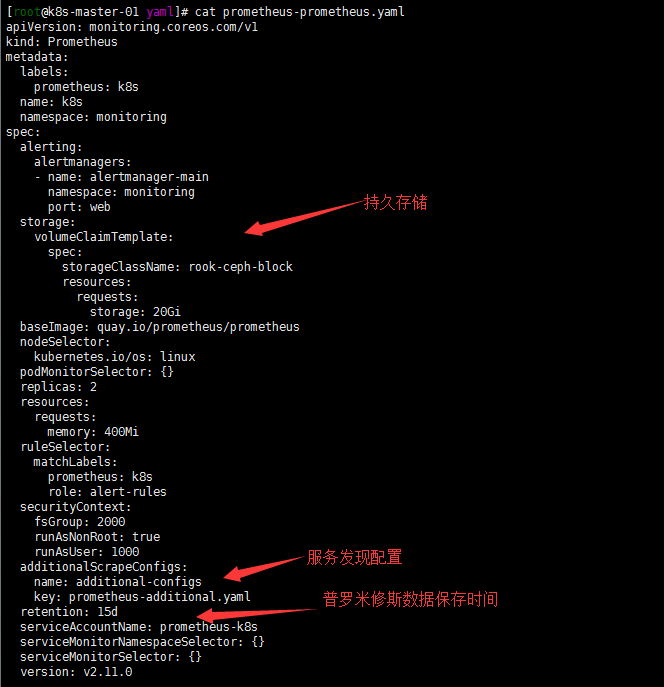
开启服务自动发现,配置可持续存储,修改prometheus Storage Retention参数设置数据保留时间
参照https://www.qikqiak.com/post/prometheus-operator-advance/,自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明,然后通过这个文件创建一个对应的 Secret 对象。由于配置可持续存储和修改retention参数都在同一个配置文件就都写在一起了
cat <<EOF > prometheus-additional.yaml
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
EOF
$ kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
secret "additional-configs" created
#修改crd文件,
cat <<EOF > prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
storage:
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
resources:
requests:
storage: 20Gi
baseImage: quay.io/prometheus/prometheus
nodeSelector:
kubernetes.io/os: linux
podMonitorSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml
serviceAccountName: prometheus-k8s
retention: 15d
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.11.0
EOF
kubectl apply -f prometheus-prometheus.yaml
由于RABC权限问题,Prometheus Dashboard 的配置页面下面我们可以看到已经有了对应的的配置信息了,但是我们切换到 targets 页面下面却并没有发现对应的监控任务
cat <<EOF > prometheus-clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
EOF
kubectl apply -f rometheus-clusterRole.yaml
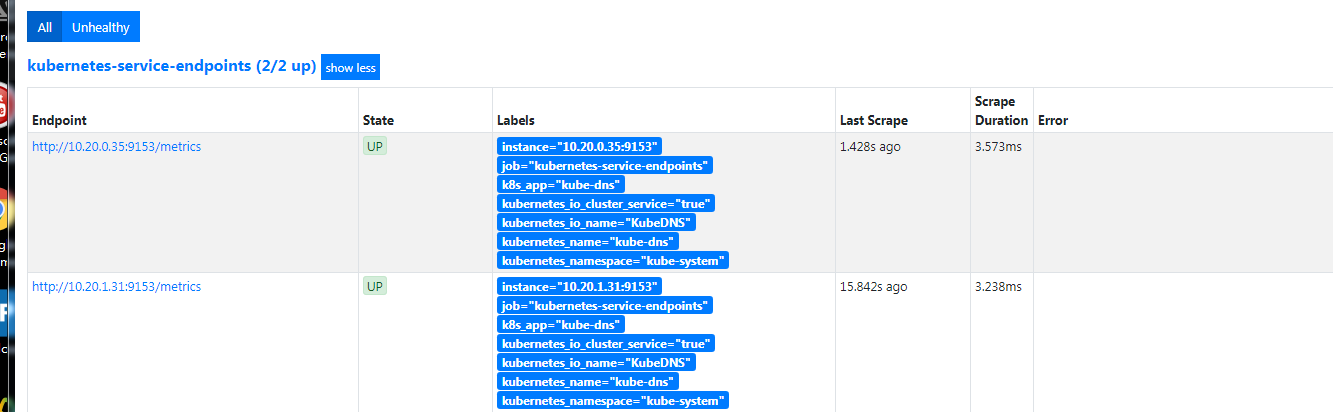
grafana添加监控模板,持久化
持久化
cat <<EOF > grafana-pv.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitoring
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
EOF
kubectl apply -f grafana-pv.yaml
修改grafana-deployment.yaml,如下图:
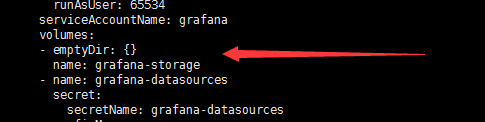
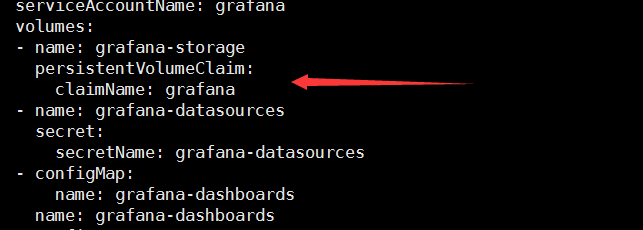
kubectl apply -f grafana-deployment.yaml
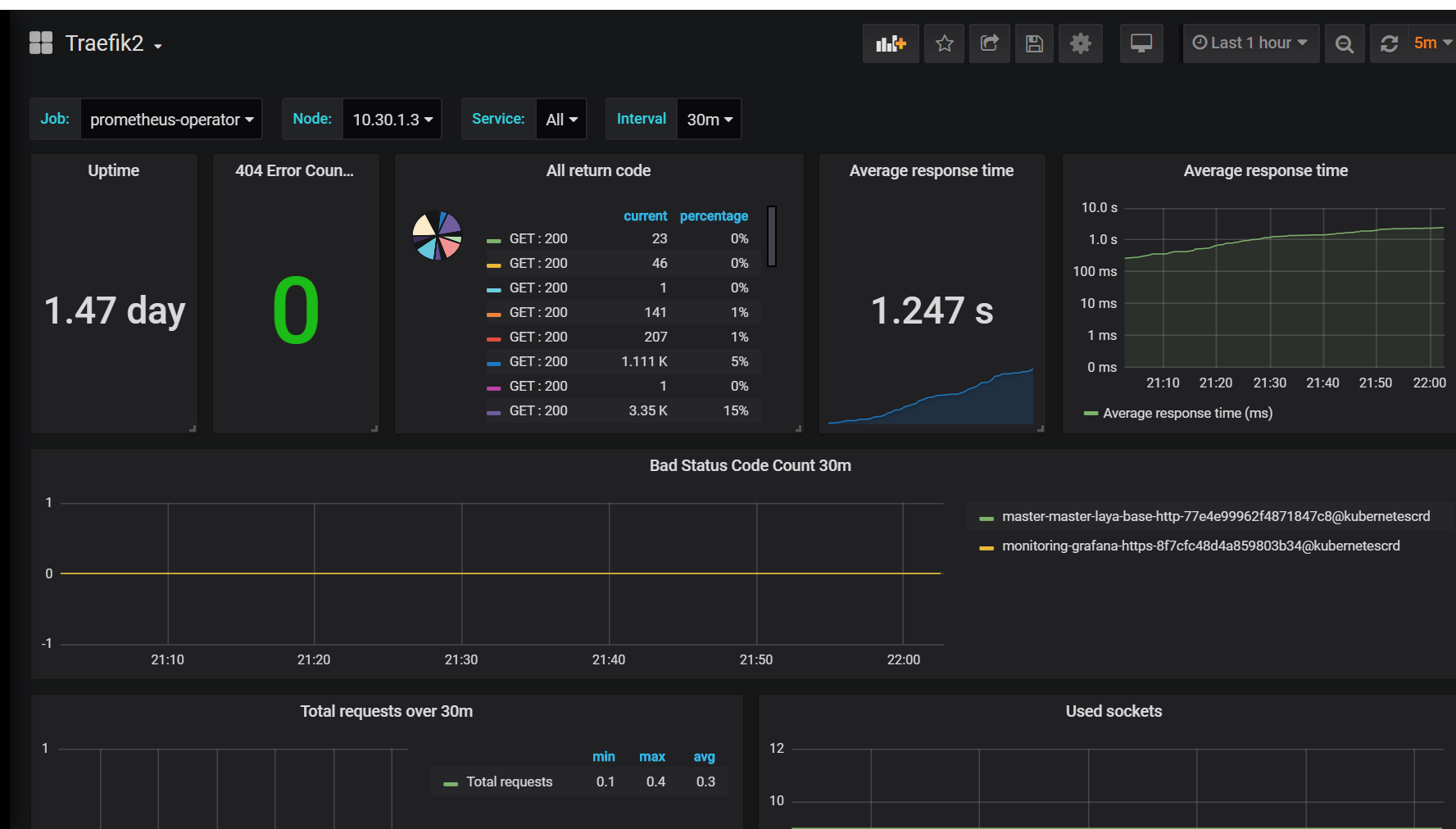
grafana添加模板,只添加了treafik2 和etcd模板
登录https://monitoring.saynaihe.com/dashboards import模板号10906 3070.
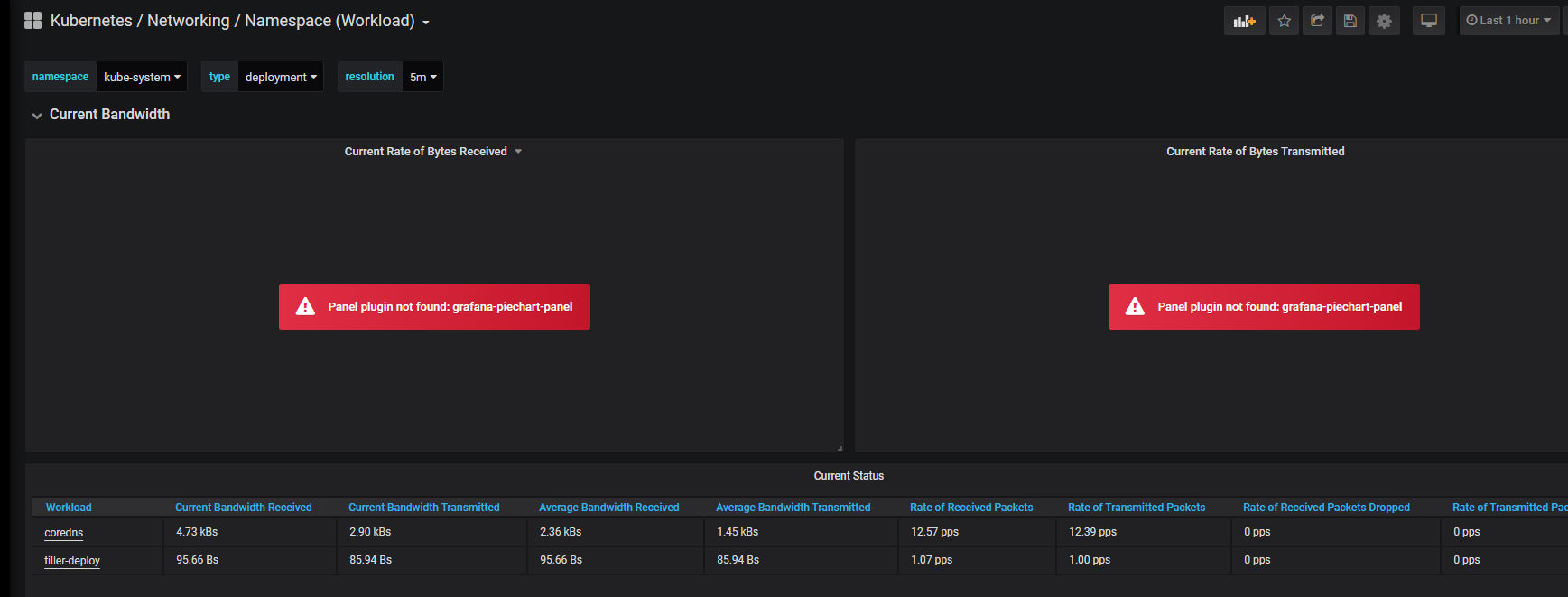
打开dashboard,有的模板会出现Panel plugin not found: grafana-piechart-panel 。
解决方法:重新构建grafana镜像,/usr/share/grafana/bin/grafana-cli plugins install grafana-piechart-panel安装缺失插件
微信报警
将对应参数修改为自己微信企业号相对应参数
cat <<EOF > alertmanager.yaml
global:
resolve_timeout: 2m
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
route:
group_by: ['alert']
group_wait: 10s
group_interval: 1m
repeat_interval: 1h
receiver: wechat
receivers:
- name: 'wechat'
wechat_configs:
- api_secret: 'xxxx'
send_resolved: true
to_user: '@all'
to_party: 'xxx'
agent_id: 'xxx'
corp_id: 'xxxx'
templates:
- '/etc/config/alert/wechat.tmpl'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
EOF
cat <<EOF > wechat.tpl
☸ Alerts Firing ✖️ ‼️ :
☎️ 触发警报 ☔ ☠️ :
☞名称空间:
☞主机:
☞job:
->涉及容器名称:
->Pod名称:
告警级别:
告警详情:
触发时间⏱:
警报链接:
✍️ 备注详情❄️:
-------------------->END<--------------------
☸ Alerts Resolved ✔️:
☎️ 触发警报 ☫ :
♥️ 名称空间 ✝️ :
♥️ ->涉及容器名称:
♥️ ->Pod名称☸:
♥️ 告警级别:
♥️ 告警详情:
♥️ 触发时间 ⏱ :
♥️ 恢复时间 ⏲ :
♥️ 备注详情:
-------------------->END<--------------------
EOF
kubectl delete secret alertmanager-main -n monitoring
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --from-file=wechat.tmpl -n monitoring
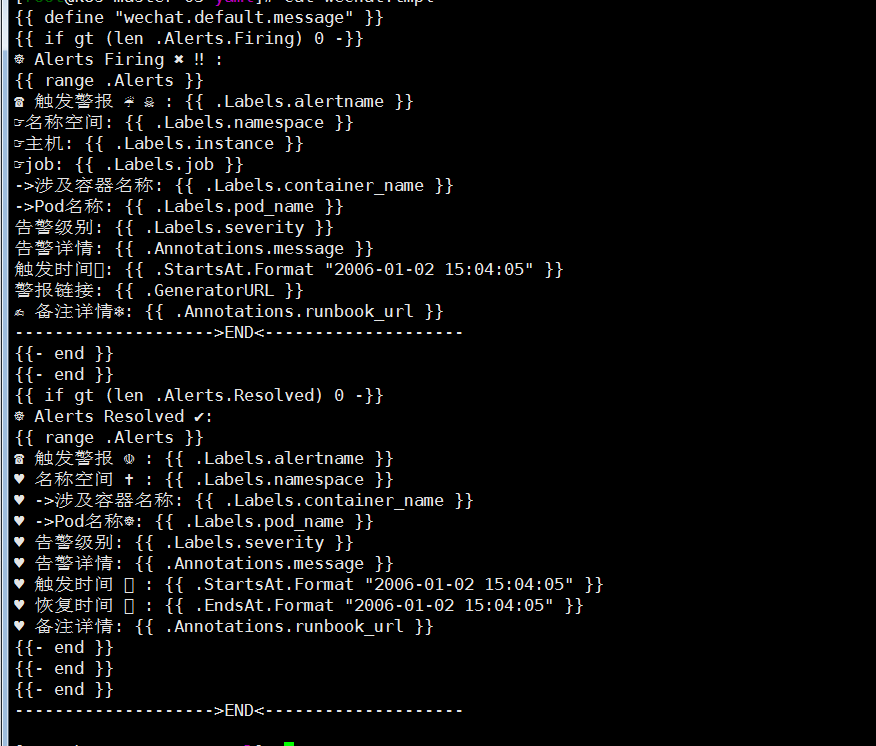
wechat.tpl模板可以根据自己需求自己定制,我这里就找了个网上的例子,格式不太会玩,貌似看不到,如下图

基本完成。具体的修改可参考个人实际。